Presentation: Boost Hadoop and Spark with in-memory technologies by Akmal Chaudhri at Big Data Spain 2017
1 like1,318 views

Apache Ignite is an in-memory platform that can accelerate Hadoop and Spark workloads by storing data in memory. It provides a distributed in-memory file system (IGNITE) that can be used as a secondary storage layer for Hadoop. For Spark, Ignite allows sharing RDDs across jobs by storing them in an Ignite cache, avoiding the need to write to disk between jobs. The IgniteContext class provides the main entry point for integrating Spark and Ignite, allowing Spark jobs to read from and write RDD data directly to Ignite caches.














![Write code example
Big Data Spain 2017
valconf= new SparkConf().setAppNam e("SparkIgniteW riter")
valsc = new SparkContext(conf)
valic = new IgniteContext(sc,
"exam ples/config/spark/exam ple-shared-rdd.xm l")
valsharedRD D :IgniteRD D [Int,Int]= ic.from Cache("sharedRD D ")
sharedRD D .savePairs(sc.parallelize(1 to 100000,10)
.m ap(i= > (i,i)))](https://image.slidesharecdn.com/akmal-171205105326/85/Presentation-Boost-Hadoop-and-Spark-with-in-memory-technologies-by-Akmal-Chaudhri-at-Big-Data-Spain-2017-16-320.jpg)

![Read code example
Big Data Spain 2017
valconf= new SparkConf().setAppNam e("SparkIgniteReader")
valsc = new SparkContext(conf)
valic = new IgniteContext(sc,
"exam ples/config/spark/exam ple-shared-rdd.xm l")
valsharedRD D :IgniteRD D [Int,Int]= ic.from Cache("sharedRD D ")
valgreaterThanFiftyThousand = sharedRD D .filter(_._2 > 50000)
println("The countis "+ greaterThanFiftyThousand.count())](https://image.slidesharecdn.com/akmal-171205105326/85/Presentation-Boost-Hadoop-and-Spark-with-in-memory-technologies-by-Akmal-Chaudhri-at-Big-Data-Spain-2017-18-320.jpg)


Presentation: Boost Hadoop and Spark with in-memory technologies by Akmal Chaudhri at Big Data Spain 2017
- 2. Akmal Chaudhri, GridGain Systems Boost Hadoop and Spark with in-memory technologies
- 3. Agenda • Introduction to Apache Ignite • Hadoop Acceleration • Spark Acceleration • Demos • Q&A Big Data Spain 2017
- 4. Apache Ignite in one slide • Memory-centric platform – that is strongly consistent – and highly-available – with powerful SQL – key-value and processing APIs • Designed for – Performance – Scalability Big Data Spain 2017
- 5. Apache Ignite • Data source agnostic • Fully fledged compute engine and durable storage • OLAP and OLTP • Fully ACID transactions across memory and disk • In-memory SQL support • Early ML libraries • Growing community Big Data Spain 2017
- 6. Hadoop Acceleration • In-memory Hadoop Execution • Alternative job tracker – Faster MapReduce • Built on Ignite File System (IGFS) • Secondary File System – Read-through and Write-through Big Data Spain 2017
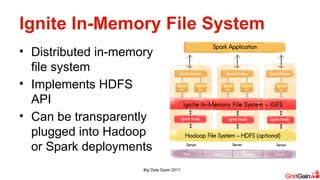
- 7. Ignite In-Memory File System • Distributed in-memory file system • Implements HDFS API • Can be transparently plugged into Hadoop or Spark deployments Big Data Spain 2017
- 8. MapReduce Big Data Spain 2017
- 9. MapReduce • Parallelize processing of data in HDFS • Eliminate Hadoop JobTracker and TaskTracker overhead • Low-Latency distributed processing • Minimal configuration change Big Data Spain 2017
- 10. Spark Acceleration • Long running applications – Passing state between jobs • Disk File System – Convert RDDs to disk files and back • Share RDDs in-memory – Native Spark API – Native Spark transformations Big Data Spain 2017
- 11. Ignite for Spark • Spark RDD abstraction • Shared in-memory view on data across different Spark jobs, workers or applications • Implemented as a view over a distributed Ignite cache Big Data Spain 2017
- 12. IgniteContext • Main entry-point to Spark-Ignite integration • SparkContext plus either one of – IgniteConfiguration() – Path to XML configuration file • Optional Boolean client argument – true => Shared deployment – false => Embedded deployment Big Data Spain 2017
- 13. IgniteContext examples Big Data Spain 2017 valigniteContext= new IgniteContext(sparkContext, ()= > new IgniteConfiguration()) valigniteContext= new IgniteContext(sparkContext, "exam ples/config/spark/exam ple-shared-rdd.xm l")
- 14. IgniteRDD • Implementation of Spark RDD representing a live view of an Ignite cache • Mutable (unlike native RDDs) – All changes in Ignite cache will be visible to RDD users immediately • Provides partitioning information to Spark executor • Provides affinity information to Spark so that RDD computations can use data locality Big Data Spain 2017
- 15. Write to Ignite • Ignite caches operate on key-value pairs • Spark tuple RDD for key-value pairs and savePairs method – RDD partitioning, store values in parallel if possible • Value-only RDD and saveValues method – IgniteRDD generates a unique affinity-local key for each value stored into the cache Big Data Spain 2017
- 16. Write code example Big Data Spain 2017 valconf= new SparkConf().setAppNam e("SparkIgniteW riter") valsc = new SparkContext(conf) valic = new IgniteContext(sc, "exam ples/config/spark/exam ple-shared-rdd.xm l") valsharedRD D :IgniteRD D [Int,Int]= ic.from Cache("sharedRD D ") sharedRD D .savePairs(sc.parallelize(1 to 100000,10) .m ap(i= > (i,i)))
- 17. Read from Ignite • IgniteRDD is a live view of an Ignite cache – No need to explicitly load data to Spark application from Ignite – All RDD methods are available to use right away after an instance of IgniteRDD is created Big Data Spain 2017
- 18. Read code example Big Data Spain 2017 valconf= new SparkConf().setAppNam e("SparkIgniteReader") valsc = new SparkContext(conf) valic = new IgniteContext(sc, "exam ples/config/spark/exam ple-shared-rdd.xm l") valsharedRD D :IgniteRD D [Int,Int]= ic.from Cache("sharedRD D ") valgreaterThanFiftyThousand = sharedRD D .filter(_._2 > 50000) println("The countis "+ greaterThanFiftyThousand.count())
- 19. Demos Big Data Spain 2017
- 20. Any Questions? Thank you for joining us. Follow the conversation. http://ignite.apache.org Big Data Spain 2017