
![To Recap: The “Comparison Paper” by DeWitt, Stonebraker, et al. [1] claims: Data movement is fast for Hadoop MR but slow for Vertica and DBMS-X Queries are fast on Vertica and DBMS-X and slow on Hadoop MR Conclusion: Hadoop MR bad, Vertica good](https://image.slidesharecdn.com/bunch-595d-presentation-w10-100208003453-phpapp02/85/Presentation-on-Large-Scale-Data-Management-2-320.jpg)

![Update In Jan. 2010’s CACM, DeWitt and Stonebraker [2] update their point of view: Hadoop MR and relational DBs complement each other Use Hadoop MR for “complex” or “quick-and-dirty” analyses. Use relational DBs for everything else.](https://image.slidesharecdn.com/bunch-595d-presentation-w10-100208003453-phpapp02/85/Presentation-on-Large-Scale-Data-Management-4-320.jpg)
![Another Update Dean and Ghemawat also respond in Jan. 2010’s CACM [3]: Problems are with H MR, not MR itself MR does not need to read all the input data Can use BigTable / HBase to get a subset of the input data for processing](https://image.slidesharecdn.com/bunch-595d-presentation-w10-100208003453-phpapp02/85/Presentation-on-Large-Scale-Data-Management-5-320.jpg)


![Conclusion DeWitt and Stonebraker’s arguments are valid against Hadoop MR but not against MR itself Dean’s rebuttal clearly shows that Google MR overcomes DeWitt’s objections to it No native support for PB Serialization in Hadoop MR [4] (hybrid approach possible)](https://image.slidesharecdn.com/bunch-595d-presentation-w10-100208003453-phpapp02/85/Presentation-on-Large-Scale-Data-Management-8-320.jpg)



![Live Migration of Virtual Machines [5] Authored by Christopher Clark, Keir Fraser, Steven Hand, Jacob Gorm Hansen, Eric Jul, Christian Limpach, Ian Pratt, and Andrew Warfield (Cambridge and University of Copenhagen) Published in NSDI 2005](https://image.slidesharecdn.com/bunch-595d-presentation-w10-100208003453-phpapp02/85/Presentation-on-Large-Scale-Data-Management-12-320.jpg)
















![Live Migration of Virtual Machine Based on Full System Trace and Replay [6] Authored by Haikun Liu, Hai Jin, Xiaofei Liao, Liting Hu, and Chen Yu (Huazhong University) Published in HPDC 2009](https://image.slidesharecdn.com/bunch-595d-presentation-w10-100208003453-phpapp02/85/Presentation-on-Large-Scale-Data-Management-30-320.jpg)
















![References [1] Pavlo et al., A Comparison of Approaches to Large-Scale Data Analysis , SIGMOD 2009 [2] Stonebraker et al., MapReduce and Parallel DBMSs: Friends or Foes? , CACM Jan. 2010 [3] Dean et al., MapReduce: A Flexible Data Processing Tool , CACM, Jan. 2010 [4] Add serialization support for Protocol Buffers , http://issues.apache.org/jira/browse/MAPREDUCE-377 [5] Clark et al., Live Migration of Virtual Machines , NSDI 2005 [6] Liu et al., Live Migration of Virtual Machine Based on Full System Trace and Replay, HPDC 2009](https://image.slidesharecdn.com/bunch-595d-presentation-w10-100208003453-phpapp02/85/Presentation-on-Large-Scale-Data-Management-48-320.jpg)
Presentation on Large Scale Data Management
- 1. Current Topics in MapReduce and Virtualization Presented by Chris Bunch at UCSB CS595D - Seminar on Large-Scale Data Management February 2, 2010 http://cs.ucsb.edu/~cgb
- 2. To Recap: The “Comparison Paper” by DeWitt, Stonebraker, et al. [1] claims: Data movement is fast for Hadoop MR but slow for Vertica and DBMS-X Queries are fast on Vertica and DBMS-X and slow on Hadoop MR Conclusion: Hadoop MR bad, Vertica good
- 3. Specifically Comparison paper claims Hadoop MR is slow because: H MR must always read the entire file MR cannot enforce a schema in the input data (parsing it becomes a bottleneck) Fault tolerance requires data shuffling between Map and Reduce
- 4. Update In Jan. 2010’s CACM, DeWitt and Stonebraker [2] update their point of view: Hadoop MR and relational DBs complement each other Use Hadoop MR for “complex” or “quick-and-dirty” analyses. Use relational DBs for everything else.
- 5. Another Update Dean and Ghemawat also respond in Jan. 2010’s CACM [3]: Problems are with H MR, not MR itself MR does not need to read all the input data Can use BigTable / HBase to get a subset of the input data for processing
- 6. Continuing MR input / output doesn’t need to be simple text files (use BigTable / HBase) MR input / output data can have schemas Can be stored as Protocol Buffers Parsing a string: 1731 ns / record Parsing a Protocol Buffer: 20 ns / record
- 7. Fundamentally: Bad Representation of Data: 137|http://www.somehost.com/index.html|602 Good Representation of Data: message Rankings { required string pageurl = 1 required int32 pagerank = 2 required int32 avgduration = 3 }
- 8. Conclusion DeWitt and Stonebraker’s arguments are valid against Hadoop MR but not against MR itself Dean’s rebuttal clearly shows that Google MR overcomes DeWitt’s objections to it No native support for PB Serialization in Hadoop MR [4] (hybrid approach possible)
- 9. Part 2: Virtualization Software layer for isolated execution of 1+ virtual guest system on real hardware (multicores) Improves hardware utilization, improves portability, other benefits Multiplexes hardware resources between guests
- 10. Virtualization Emulates ISA (captures privileged instructions) and devices, manages state Without OS modification: full virtualization With OS modification: paravirtualization Hardware support for virtualization (modern AMD / Intel processors)
- 11. Migrating VMs: Why? Load balancing Online maintenance Proactive fault tolerance Power management
- 12. Live Migration of Virtual Machines [5] Authored by Christopher Clark, Keir Fraser, Steven Hand, Jacob Gorm Hansen, Eric Jul, Christian Limpach, Ian Pratt, and Andrew Warfield (Cambridge and University of Copenhagen) Published in NSDI 2005
- 13. In a Nutshell Perform continuous migration while the system is running to ensure that when migration is needed, it can be done quickly. Recorded service downtimes as low as 60ms using Xen
- 14. Motivation Process-level migration is hard Small interface between OS and VMM makes VM migration much easier Goal is to minimize application downtime, total migration time, and ensure that migration does not impact active services
- 15. Memory Migration Techniques Push phase: Source sends memory pages to destination VM Stop-and-copy phase: Source stops, sends pages, starts destination Pull phase: Destination retrieves memory pages from source VM as needed This hybrid technique uses the first two
- 16. Migrating Local Resources To migrate network traffic, simply send an ARP reply with the new destination Does not always work Can also create destination VM with same MAC address Local disk storage problem not addressed For now, use NFS
- 17. The Algorithm
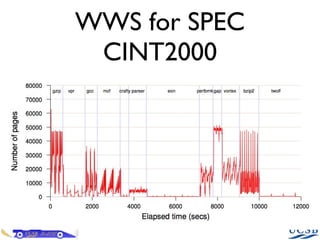
- 18. Writable Working Sets Modified pages need to be re-copied over Dubbed the “Writable Working Set” Measure this by reading the dirty bitmap every 50 ms Small WWS ⇔ easy to migrate Large WWS ⇔ hard to migrate
- 19. WWS for SPEC CINT2000
- 20. Implementation Issues Managed migration: Daemon in a separate VM copies pages from source to destination Requires modification to Xen so that daemon can read shadow page tables Can stop source for final copy easily
- 21. Implementation Issues Self migration: Source copies pages to destination No modification to source OS needed Stopping source for final copy is hard First stop everything except migrator program, then copy final dirty pages
- 22. Rate Limiting If the migration process uses too much bandwidth, it can hamper other processes Relies on administrator specifying a min and max bandwidth to use Seems like it could be determined programatically
- 23. Optimizations Don’t copy pages that are frequently dirtied Slow down write-heavy services Don’t do this to essential processes Free all unused cache pages when migration starts Can incur a greater cost if needed later
- 24. Evaluation Hardware: 2 Dell PE-2650 servers Dual Xen 2GHz CPUs (one disabled) 2GB memory, Gigabit ethernet Software: XenLinux 2.4.27 Disk attached via NAS
- 25. SPECweb99
- 26. Quake 3 Server
- 27. Memory Muncher
- 28. Future Work Intelligently choose the placement and movement of VMs in a cluster Expand this technique to work for VMs not on the same subnet Add support for migrating hard drives Suggest using mirrored disks for now
- 29. Conclusions This new technique allows us to migrate VMs with low downtime Works well on applications w/small WWS Optimizations may help other cases but could impact application performance Future work looks promising
- 30. Live Migration of Virtual Machine Based on Full System Trace and Replay [6] Authored by Haikun Liu, Hai Jin, Xiaofei Liao, Liting Hu, and Chen Yu (Huazhong University) Published in HPDC 2009
- 31. In a Nutshell Previous methods migrate VM but incur too much downtime and too much network bandwidth. Records up to 72.4% reduction in app downtime, up to 31.5% reduction in migration time, and up to 95.9% reduction in data needed to synchronize VM state
- 32. Motivation Pre-copy methods fail in three ways: Can’t do memory intensive operations Slowing down write-heavy processes is infeasible in real-world applications The algorithm doesn’t recover the CPU’s cache, resulting in cache and TLB misses and possible performance degradation
- 33. Goals Minimize application downtime Minimize total migration time Minimize total data transferred All are similar to goals from previous work
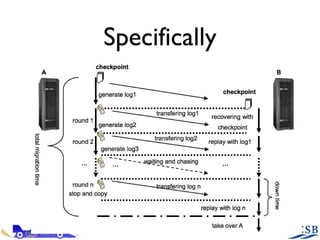
- 34. Basic Idea Synchronize the state of the two machines Second machine then will follow same state as the first unless a non-deterministic event occurs Remedy this by keeping a log of non-deterministic events (time, external input) and replaying them
- 35. Getting Around Limitations Checkpoint / replay scheme succeeds: Can do memory intensive operations Doesn’t slow down write-heavy processes Does recover the CPU’s cache, avoiding cache and TLB misses and avoiding possible performance degradation
- 36. Specifically
- 37. Implementation Details Logging and sending logs done by source Replay performed by target Also entails monitoring R log and initializing the migration
- 38. Implementation Details Checkpointing Pause source VM, change all pages to read-only, unpause VM Start copying pages and if writes come, redirect them to a Copy-On-Write buffer (COW) When done, merge pages and COW
- 39. Implementation Details File system access - must be SAN Reading / writing forbidden on target VM, redirected to log file (external input) Network redirection Same as before, uses ARP broadcasting
- 40. Experimental Setup Hardware: 2 AMD Athlon 3500+ CPUs 1 GB DDR RAM (VM only uses half) Gigabit Ethernet Software: UMLinux w/ RHEL AS3 Disk attached via NAS
- 43. Data Transferred
- 44. Lessons Looking at kernel-build: Has low non-determinism, so R log is small Total migration time is long because R replay ≈ R log Recall we want apps with the original condition, R replay >> R log , for best migration time
- 46. Summary: Pros Excels when R replay >> R log Incurs less application downtime than previous work Total migration time less than previously Migrates with less traffic than previously
- 47. Summary: Cons Works only on single processor systems Works only when ARP redirect works Performs poorly when R replay ≈ R log Still does not address regular hard drives Large size makes migration infeasible
- 48. References [1] Pavlo et al., A Comparison of Approaches to Large-Scale Data Analysis , SIGMOD 2009 [2] Stonebraker et al., MapReduce and Parallel DBMSs: Friends or Foes? , CACM Jan. 2010 [3] Dean et al., MapReduce: A Flexible Data Processing Tool , CACM, Jan. 2010 [4] Add serialization support for Protocol Buffers , http://issues.apache.org/jira/browse/MAPREDUCE-377 [5] Clark et al., Live Migration of Virtual Machines , NSDI 2005 [6] Liu et al., Live Migration of Virtual Machine Based on Full System Trace and Replay, HPDC 2009