Presto in Treasure Data (presented at db tech showcase Sapporo 2015)
11 likes2,499 views

Presto is a distributed SQL query engine designed for low latency and high performance without disk I/O, supporting ANSI SQL for ad-hoc querying. The document discusses its architecture, pros and cons, limitations, and provides examples of query plans and usage with various connectors, including those for Cassandra, Hive, and MySQL. Key limitations include challenges with large joins, lack of fault tolerance, and absence of native ODBC support.










![Query plan
Output[nationkey, _col1] => [nationkey:bigint, count:bigint]
- _col1 := count
Exchange[GATHER] => nationkey:bigint, count:bigint
Aggregate(FINAL)[nationkey] => [nationkey:bigint, count:bigint]
- count := "count"("count_15")
Exchange[REPARTITION] => nationkey:bigint, count_15:bigint
Aggregate(PARTIAL)[nationkey] => [nationkey:bigint, count_15:bigint]
- count_15 := "count"("expr")
Project => [nationkey:bigint, expr:bigint]
- expr := 1
InnerJoin[("custkey" = "custkey_0")] =>
[custkey:bigint, custkey_0:bigint, nationkey:bigint]
Project => [custkey:bigint]
Filter[("orderpriority" = '1-URGENT')] =>
[custkey:bigint, orderpriority:varchar]
TableScan[tpch:tpch:orders:sf0.01, original constraint=
('1-URGENT' = "orderpriority")] => [custkey:bigint, orderpriority:varchar]
- custkey := tpch:custkey:1
- orderpriority := tpch:orderpriority:5
Exchange[REPLICATE] => custkey_0:bigint, nationkey:bigint
TableScan[tpch:tpch:customer:sf0.01, original constraint=true] =>
[custkey_0:bigint, nationkey:bigint]
- custkey_0 := tpch:custkey:0
- nationkey := tpch:nationkey:3
select
c.nationkey,
count(1)
from orders o
join customer c
on o.custkey = c.custkey
where
o.orderpriority = '1-URGENT'
group by c.nationkey](https://image.slidesharecdn.com/prestointreasuredatadbtechshowcasehokkaido-150911082615-lva1-app6891/85/Presto-in-Treasure-Data-presented-at-db-tech-showcase-Sapporo-2015-11-320.jpg)

![Query plan
Output[nationkey, _col1] => [nationkey:bigint, count:bigint]
- _col1 := count
Exchange[GATHER] => nationkey:bigint, count:bigint
Aggregate(FINAL)[nationkey] => [nationkey:bigint, count:bigint]
- count := "count"("count_15")
Exchange[REPARTITION] => nationkey:bigint, count_15:bigint
Aggregate(PARTIAL)[nationkey] => [nationkey:bigint, count_15:bigint]
- count_15 := "count"("expr")
Project => [nationkey:bigint, expr:bigint]
- expr := 1
InnerJoin[("custkey" = "custkey_0")] =>
[custkey:bigint, custkey_0:bigint, nationkey:bigint]
Project => [custkey:bigint]
Filter[("orderpriority" = '1-URGENT')] =>
[custkey:bigint, orderpriority:varchar]
TableScan[tpch:tpch:orders:sf0.01, original constraint=
('1-URGENT' = "orderpriority")] => [custkey:bigint, orderpriority:varchar]
- custkey := tpch:custkey:1
- orderpriority := tpch:orderpriority:5
Exchange[REPLICATE] => custkey_0:bigint, nationkey:bigint
TableScan[tpch:tpch:customer:sf0.01, original constraint=true] =>
[custkey_0:bigint, nationkey:bigint]
- custkey_0 := tpch:custkey:0
- nationkey := tpch:nationkey:3
select
c.nationkey,
count(1)
from orders o
join customer c
on o.custkey = c.custkey
where
o.orderpriority = '1-URGENT'
group by c.nationkey](https://image.slidesharecdn.com/prestointreasuredatadbtechshowcasehokkaido-150911082615-lva1-app6891/85/Presto-in-Treasure-Data-presented-at-db-tech-showcase-Sapporo-2015-13-320.jpg)
![Query plan
Output[nationkey, _col1] => [nationkey:bigint, count:bigint]
- _col1 := count
Exchange[GATHER] => nationkey:bigint, count:bigint
Aggregate(FINAL)[nationkey] => [nationkey:bigint, count:bigint]
- count := "count"("count_15")
Exchange[REPARTITION] => nationkey:bigint, count_15:bigint
Aggregate(PARTIAL)[nationkey] => [nationkey:bigint, count_15:bigint]
- count_15 := "count"("expr")
Project => [nationkey:bigint, expr:bigint]
- expr := 1
InnerJoin[("custkey" = "custkey_0")] =>
[custkey:bigint, custkey_0:bigint, nationkey:bigint]
Project => [custkey:bigint]
Filter[("orderpriority" = '1-URGENT')] =>
[custkey:bigint, orderpriority:varchar]
TableScan[tpch:tpch:orders:sf0.01, original constraint=
('1-URGENT' = "orderpriority")] => [custkey:bigint, orderpriority:varchar]
- custkey := tpch:custkey:1
- orderpriority := tpch:orderpriority:5
Exchange[REPLICATE] => custkey_0:bigint, nationkey:bigint
TableScan[tpch:tpch:customer:sf0.01, original constraint=true] =>
[custkey_0:bigint, nationkey:bigint]
- custkey_0 := tpch:custkey:0
- nationkey := tpch:nationkey:3
select
c.nationkey,
count(1)
from orders o
join customer c
on o.custkey = c.custkey
where
o.orderpriority = '1-URGENT'
group by c.nationkey
Stage 3](https://image.slidesharecdn.com/prestointreasuredatadbtechshowcasehokkaido-150911082615-lva1-app6891/85/Presto-in-Treasure-Data-presented-at-db-tech-showcase-Sapporo-2015-14-320.jpg)
![Query plan
Output[nationkey, _col1] => [nationkey:bigint, count:bigint]
- _col1 := count
Exchange[GATHER] => nationkey:bigint, count:bigint
Aggregate(FINAL)[nationkey] => [nationkey:bigint, count:bigint]
- count := "count"("count_15")
Exchange[REPARTITION] => nationkey:bigint, count_15:bigint
Aggregate(PARTIAL)[nationkey] => [nationkey:bigint, count_15:bigint]
- count_15 := "count"("expr")
Project => [nationkey:bigint, expr:bigint]
- expr := 1
InnerJoin[("custkey" = "custkey_0")] =>
[custkey:bigint, custkey_0:bigint, nationkey:bigint]
Project => [custkey:bigint]
Filter[("orderpriority" = '1-URGENT')] =>
[custkey:bigint, orderpriority:varchar]
TableScan[tpch:tpch:orders:sf0.01, original constraint=
('1-URGENT' = "orderpriority")] => [custkey:bigint, orderpriority:varchar]
- custkey := tpch:custkey:1
- orderpriority := tpch:orderpriority:5
Exchange[REPLICATE] => custkey_0:bigint, nationkey:bigint
TableScan[tpch:tpch:customer:sf0.01, original constraint=true] =>
[custkey_0:bigint, nationkey:bigint]
- custkey_0 := tpch:custkey:0
- nationkey := tpch:nationkey:3
select
c.nationkey,
count(1)
from orders o
join customer c
on o.custkey = c.custkey
where
o.orderpriority = '1-URGENT'
group by c.nationkey
Stage 3
Stage 2](https://image.slidesharecdn.com/prestointreasuredatadbtechshowcasehokkaido-150911082615-lva1-app6891/85/Presto-in-Treasure-Data-presented-at-db-tech-showcase-Sapporo-2015-15-320.jpg)
![Query plan
Output[nationkey, _col1] => [nationkey:bigint, count:bigint]
- _col1 := count
Exchange[GATHER] => nationkey:bigint, count:bigint
Aggregate(FINAL)[nationkey] => [nationkey:bigint, count:bigint]
- count := "count"("count_15")
Exchange[REPARTITION] => nationkey:bigint, count_15:bigint
Aggregate(PARTIAL)[nationkey] => [nationkey:bigint, count_15:bigint]
- count_15 := "count"("expr")
Project => [nationkey:bigint, expr:bigint]
- expr := 1
InnerJoin[("custkey" = "custkey_0")] =>
[custkey:bigint, custkey_0:bigint, nationkey:bigint]
Project => [custkey:bigint]
Filter[("orderpriority" = '1-URGENT')] =>
[custkey:bigint, orderpriority:varchar]
TableScan[tpch:tpch:orders:sf0.01, original constraint=
('1-URGENT' = "orderpriority")] => [custkey:bigint, orderpriority:varchar]
- custkey := tpch:custkey:1
- orderpriority := tpch:orderpriority:5
Exchange[REPLICATE] => custkey_0:bigint, nationkey:bigint
TableScan[tpch:tpch:customer:sf0.01, original constraint=true] =>
[custkey_0:bigint, nationkey:bigint]
- custkey_0 := tpch:custkey:0
- nationkey := tpch:nationkey:3
select
c.nationkey,
count(1)
from orders o
join customer c
on o.custkey = c.custkey
where
o.orderpriority = '1-URGENT'
group by c.nationkey
Stage 3
Stage 2
Stage 1](https://image.slidesharecdn.com/prestointreasuredatadbtechshowcasehokkaido-150911082615-lva1-app6891/85/Presto-in-Treasure-Data-presented-at-db-tech-showcase-Sapporo-2015-16-320.jpg)
![Query plan
Output[nationkey, _col1] => [nationkey:bigint, count:bigint]
- _col1 := count
Exchange[GATHER] => nationkey:bigint, count:bigint
Aggregate(FINAL)[nationkey] => [nationkey:bigint, count:bigint]
- count := "count"("count_15")
Exchange[REPARTITION] => nationkey:bigint, count_15:bigint
Aggregate(PARTIAL)[nationkey] => [nationkey:bigint, count_15:bigint]
- count_15 := "count"("expr")
Project => [nationkey:bigint, expr:bigint]
- expr := 1
InnerJoin[("custkey" = "custkey_0")] =>
[custkey:bigint, custkey_0:bigint, nationkey:bigint]
Project => [custkey:bigint]
Filter[("orderpriority" = '1-URGENT')] =>
[custkey:bigint, orderpriority:varchar]
TableScan[tpch:tpch:orders:sf0.01, original constraint=
('1-URGENT' = "orderpriority")] => [custkey:bigint, orderpriority:varchar]
- custkey := tpch:custkey:1
- orderpriority := tpch:orderpriority:5
Exchange[REPLICATE] => custkey_0:bigint, nationkey:bigint
TableScan[tpch:tpch:customer:sf0.01, original constraint=true] =>
[custkey_0:bigint, nationkey:bigint]
- custkey_0 := tpch:custkey:0
- nationkey := tpch:nationkey:3
select
c.nationkey,
count(1)
from orders o
join customer c
on o.custkey = c.custkey
where
o.orderpriority = '1-URGENT'
group by c.nationkey
Stage 3
Stage 2
Stage 1
Stage 0](https://image.slidesharecdn.com/prestointreasuredatadbtechshowcasehokkaido-150911082615-lva1-app6891/85/Presto-in-Treasure-Data-presented-at-db-tech-showcase-Sapporo-2015-17-320.jpg)






















































Presto in Treasure Data (presented at db tech showcase Sapporo 2015)
- 1. Presto in Treasure Data (Updated) Mitsunori Komatsu
- 2. • Mitsunori Komatsu, Software engineer @ Treasure Data. • Presto, Hive, PlazmaDB, td-android-sdk, td-ios-sdk, Mobile SDK backend, embedded-sdk • github:komamitsu, msgpack-java committer, Presto contributor, etc… About me
- 3. Today’s talk • What's Presto? • Pros & Cons • Architecture • Recent updates • Who uses Presto? • How do we use Presto?
- 5. Fast • Distributed SQL query engine (MPP) • Low latency and good performance • No disk IO • Pipelined execution (not Map Reduce) • Compile a query plan down to byte code • Off heap memory • Suitable for ad-hoc query
- 6. Pluggable • Pluggable backends (“connectors”) • Cassandra / Hive / JMX / Kafka / MySQL / PostgreSQL / System / TPCH • We can add a new connector by extending SPI • Treasure Data has been developed a connector to access our storage
- 7. What kind of SQL • Supports ANSI SQL (Not HiveQL) • Easy to use Presto compared to HiveQL • Structural type: Map, Array, JSON, Row • Window functions • Approximate queries • http://blinkdb.org/
- 8. Limitations • Fails with huge JOIN or DISTINCT • In memory only (broadcast / distributed JOIN) • No grace / hybrid hash join • No fault tolerance • Coordinator is SPOF • No “cost based” optimization • No authentication / authorization • No native ODBC => Prestogres
- 9. Limitations • Fails with huge JOIN or DISTINCT • In memory only (broadcast / distributed JOIN) • No grace / hybrid hash join • No fault tolerance • Coordinator is SPOF • No “cost based” optimization • No authentication / authorization • No native ODBC => Prestogres https://highlyscalable.wordpress.com/2013/08/20/in-stream-big-data-processing/
- 10. Architectural overview https://prestodb.io/overview.html With Hive connector
- 11. Query plan Output[nationkey, _col1] => [nationkey:bigint, count:bigint] - _col1 := count Exchange[GATHER] => nationkey:bigint, count:bigint Aggregate(FINAL)[nationkey] => [nationkey:bigint, count:bigint] - count := "count"("count_15") Exchange[REPARTITION] => nationkey:bigint, count_15:bigint Aggregate(PARTIAL)[nationkey] => [nationkey:bigint, count_15:bigint] - count_15 := "count"("expr") Project => [nationkey:bigint, expr:bigint] - expr := 1 InnerJoin[("custkey" = "custkey_0")] => [custkey:bigint, custkey_0:bigint, nationkey:bigint] Project => [custkey:bigint] Filter[("orderpriority" = '1-URGENT')] => [custkey:bigint, orderpriority:varchar] TableScan[tpch:tpch:orders:sf0.01, original constraint= ('1-URGENT' = "orderpriority")] => [custkey:bigint, orderpriority:varchar] - custkey := tpch:custkey:1 - orderpriority := tpch:orderpriority:5 Exchange[REPLICATE] => custkey_0:bigint, nationkey:bigint TableScan[tpch:tpch:customer:sf0.01, original constraint=true] => [custkey_0:bigint, nationkey:bigint] - custkey_0 := tpch:custkey:0 - nationkey := tpch:nationkey:3 select c.nationkey, count(1) from orders o join customer c on o.custkey = c.custkey where o.orderpriority = '1-URGENT' group by c.nationkey
- 12. Stage 1 Stage 2 Stage 0 Query, stage, task and split Query Task 0.0 Split Task 1.0 Split Task 1.1 Task 1.2 Split Split Split Task 2.0 Split Task 2.1 Task 2.2 Split Split Split Split Split Split Split Split For example… TableScan (FROM) Aggregation (GROUP BY) Output @worker#2 @worker#3 @worker#0
- 13. Query plan Output[nationkey, _col1] => [nationkey:bigint, count:bigint] - _col1 := count Exchange[GATHER] => nationkey:bigint, count:bigint Aggregate(FINAL)[nationkey] => [nationkey:bigint, count:bigint] - count := "count"("count_15") Exchange[REPARTITION] => nationkey:bigint, count_15:bigint Aggregate(PARTIAL)[nationkey] => [nationkey:bigint, count_15:bigint] - count_15 := "count"("expr") Project => [nationkey:bigint, expr:bigint] - expr := 1 InnerJoin[("custkey" = "custkey_0")] => [custkey:bigint, custkey_0:bigint, nationkey:bigint] Project => [custkey:bigint] Filter[("orderpriority" = '1-URGENT')] => [custkey:bigint, orderpriority:varchar] TableScan[tpch:tpch:orders:sf0.01, original constraint= ('1-URGENT' = "orderpriority")] => [custkey:bigint, orderpriority:varchar] - custkey := tpch:custkey:1 - orderpriority := tpch:orderpriority:5 Exchange[REPLICATE] => custkey_0:bigint, nationkey:bigint TableScan[tpch:tpch:customer:sf0.01, original constraint=true] => [custkey_0:bigint, nationkey:bigint] - custkey_0 := tpch:custkey:0 - nationkey := tpch:nationkey:3 select c.nationkey, count(1) from orders o join customer c on o.custkey = c.custkey where o.orderpriority = '1-URGENT' group by c.nationkey
- 14. Query plan Output[nationkey, _col1] => [nationkey:bigint, count:bigint] - _col1 := count Exchange[GATHER] => nationkey:bigint, count:bigint Aggregate(FINAL)[nationkey] => [nationkey:bigint, count:bigint] - count := "count"("count_15") Exchange[REPARTITION] => nationkey:bigint, count_15:bigint Aggregate(PARTIAL)[nationkey] => [nationkey:bigint, count_15:bigint] - count_15 := "count"("expr") Project => [nationkey:bigint, expr:bigint] - expr := 1 InnerJoin[("custkey" = "custkey_0")] => [custkey:bigint, custkey_0:bigint, nationkey:bigint] Project => [custkey:bigint] Filter[("orderpriority" = '1-URGENT')] => [custkey:bigint, orderpriority:varchar] TableScan[tpch:tpch:orders:sf0.01, original constraint= ('1-URGENT' = "orderpriority")] => [custkey:bigint, orderpriority:varchar] - custkey := tpch:custkey:1 - orderpriority := tpch:orderpriority:5 Exchange[REPLICATE] => custkey_0:bigint, nationkey:bigint TableScan[tpch:tpch:customer:sf0.01, original constraint=true] => [custkey_0:bigint, nationkey:bigint] - custkey_0 := tpch:custkey:0 - nationkey := tpch:nationkey:3 select c.nationkey, count(1) from orders o join customer c on o.custkey = c.custkey where o.orderpriority = '1-URGENT' group by c.nationkey Stage 3
- 15. Query plan Output[nationkey, _col1] => [nationkey:bigint, count:bigint] - _col1 := count Exchange[GATHER] => nationkey:bigint, count:bigint Aggregate(FINAL)[nationkey] => [nationkey:bigint, count:bigint] - count := "count"("count_15") Exchange[REPARTITION] => nationkey:bigint, count_15:bigint Aggregate(PARTIAL)[nationkey] => [nationkey:bigint, count_15:bigint] - count_15 := "count"("expr") Project => [nationkey:bigint, expr:bigint] - expr := 1 InnerJoin[("custkey" = "custkey_0")] => [custkey:bigint, custkey_0:bigint, nationkey:bigint] Project => [custkey:bigint] Filter[("orderpriority" = '1-URGENT')] => [custkey:bigint, orderpriority:varchar] TableScan[tpch:tpch:orders:sf0.01, original constraint= ('1-URGENT' = "orderpriority")] => [custkey:bigint, orderpriority:varchar] - custkey := tpch:custkey:1 - orderpriority := tpch:orderpriority:5 Exchange[REPLICATE] => custkey_0:bigint, nationkey:bigint TableScan[tpch:tpch:customer:sf0.01, original constraint=true] => [custkey_0:bigint, nationkey:bigint] - custkey_0 := tpch:custkey:0 - nationkey := tpch:nationkey:3 select c.nationkey, count(1) from orders o join customer c on o.custkey = c.custkey where o.orderpriority = '1-URGENT' group by c.nationkey Stage 3 Stage 2
- 16. Query plan Output[nationkey, _col1] => [nationkey:bigint, count:bigint] - _col1 := count Exchange[GATHER] => nationkey:bigint, count:bigint Aggregate(FINAL)[nationkey] => [nationkey:bigint, count:bigint] - count := "count"("count_15") Exchange[REPARTITION] => nationkey:bigint, count_15:bigint Aggregate(PARTIAL)[nationkey] => [nationkey:bigint, count_15:bigint] - count_15 := "count"("expr") Project => [nationkey:bigint, expr:bigint] - expr := 1 InnerJoin[("custkey" = "custkey_0")] => [custkey:bigint, custkey_0:bigint, nationkey:bigint] Project => [custkey:bigint] Filter[("orderpriority" = '1-URGENT')] => [custkey:bigint, orderpriority:varchar] TableScan[tpch:tpch:orders:sf0.01, original constraint= ('1-URGENT' = "orderpriority")] => [custkey:bigint, orderpriority:varchar] - custkey := tpch:custkey:1 - orderpriority := tpch:orderpriority:5 Exchange[REPLICATE] => custkey_0:bigint, nationkey:bigint TableScan[tpch:tpch:customer:sf0.01, original constraint=true] => [custkey_0:bigint, nationkey:bigint] - custkey_0 := tpch:custkey:0 - nationkey := tpch:nationkey:3 select c.nationkey, count(1) from orders o join customer c on o.custkey = c.custkey where o.orderpriority = '1-URGENT' group by c.nationkey Stage 3 Stage 2 Stage 1
- 17. Query plan Output[nationkey, _col1] => [nationkey:bigint, count:bigint] - _col1 := count Exchange[GATHER] => nationkey:bigint, count:bigint Aggregate(FINAL)[nationkey] => [nationkey:bigint, count:bigint] - count := "count"("count_15") Exchange[REPARTITION] => nationkey:bigint, count_15:bigint Aggregate(PARTIAL)[nationkey] => [nationkey:bigint, count_15:bigint] - count_15 := "count"("expr") Project => [nationkey:bigint, expr:bigint] - expr := 1 InnerJoin[("custkey" = "custkey_0")] => [custkey:bigint, custkey_0:bigint, nationkey:bigint] Project => [custkey:bigint] Filter[("orderpriority" = '1-URGENT')] => [custkey:bigint, orderpriority:varchar] TableScan[tpch:tpch:orders:sf0.01, original constraint= ('1-URGENT' = "orderpriority")] => [custkey:bigint, orderpriority:varchar] - custkey := tpch:custkey:1 - orderpriority := tpch:orderpriority:5 Exchange[REPLICATE] => custkey_0:bigint, nationkey:bigint TableScan[tpch:tpch:customer:sf0.01, original constraint=true] => [custkey_0:bigint, nationkey:bigint] - custkey_0 := tpch:custkey:0 - nationkey := tpch:nationkey:3 select c.nationkey, count(1) from orders o join customer c on o.custkey = c.custkey where o.orderpriority = '1-URGENT' group by c.nationkey Stage 3 Stage 2 Stage 1 Stage 0
- 18. What each component does? Presto Cli Coordinator - Parse Query - Analyze Query - Create Query Plan - Execute Query - Contains Stages - Execute Stages - Contains Tasks - Issue Tasks Discovery Service Worker Worker - Execute Tasks - Convert Query to Java Bytecode (Operator) - Execute Operator Connector - MetaData - Table, Column… - SplitManager - Split, … Connector - RecordSetProvider - RecordSet - RecordCursor - Read Storage Connector Storage Worker Connector External Metadata?
- 19. Presto Cli Coordinator - Parse Query - Analyze Query - Create Query Plan - Execute Query - Contains Stages - Execute Stages - Contains Tasks - Issue Tasks Discovery Service Worker Worker - Execute Tasks - Convert Query to Java Bytecode (Operator) - Execute Operator Connector - MetaData - Table, Column… - SplitManager - Split, … Connector - RecordSetProvider - RecordSet - RecordCursor - Read Storage Connector Storage Worker Connector External Metadata? What each component does?
- 20. Presto Cli Coordinator - Parse Query - Analyze Query - Create Query Plan - Execute Query - Contains Stages - Execute Stages - Contains Tasks - Issue Tasks Discovery Service Worker Worker - Execute Tasks - Convert Query to Java Bytecode (Operator) - Execute Operator Connector - MetaData - Table, Column… - SplitManager - Split, … Connector - RecordSetProvider - RecordSet - RecordCursor - Read Storage Connector Storage Worker Connector External Metadata? What each component does?
- 21. Presto Cli Coordinator - Parse Query - Analyze Query - Create Query Plan - Execute Query - Contains Stages - Execute Stages - Contains Tasks - Issue Tasks Discovery Service Worker Worker - Execute Tasks - Convert Query to Java Bytecode (Operator) - Execute Operator Connector - MetaData - Table, Column… - SplitManager - Split, … Connector - RecordSetProvider - RecordSet - RecordCursor - Read Storage Connector Storage Worker Connector External Metadata? What each component does?
- 22. Presto Cli Coordinator - Parse Query - Analyze Query - Create Query Plan - Execute Query - Contains Stages - Execute Stages - Contains Tasks - Issue Tasks Discovery Service Worker Worker - Execute Tasks - Convert Query to Java Bytecode (Operator) - Execute Operator Connector - MetaData - Table, Column… - SplitManager - Split, … Connector - RecordSetProvider - RecordSet - RecordCursor - Read Storage Connector Storage Worker Connector External Metadata? What each component does?
- 23. Multi connectors Presto MySQL - test.users PostgreSQL - public.accesses - public.codes Raptor - default. user_codes create table raptor.default.user_codes as select c.text, u.name, count(1) as count from postgres.public.accesses a join mysql.test.users u on cast(a.user as bigint) = u.id join postgres.public.codes c on a.code = c.code where a.time < 1200000000
- 24. connector.name=mysql connection-url=jdbc:mysql://127.0.0.1:3306 connection-user=root - etc/catalog/mysql.properties connector.name=postgresql connection-url=jdbc:postgresql://127.0.0.1:5432/postgres connection-user=komamitsu - etc/catalog/postgres.properties connector.name=raptor metadata.db.type=h2 metadata.db.filename=var/data/db/MetaStore - etc/catalog/postgres.properties Multi connectors
- 25. : 2015-08-30T22:29:28.882+0900 DEBUG 20150830_132930_00032_btyir. 4.0-0-50 com.facebook.presto.plugin.jdbc.JdbcRecordCursor Executing: SELECT `id`, `name` FROM `test`.`users` : 2015-08-30T22:29:28.856+0900 DEBUG 20150830_132930_00032_btyir. 5.0-0-56 com.facebook.presto.plugin.jdbc.JdbcRecordCursor Executing: SELECT "text", "code" FROM “public"."codes" : 2015-08-30T22:30:09.294+0900 DEBUG 20150830_132930_00032_btyir. 3.0-2-70 com.facebook.presto.plugin.jdbc.JdbcRecordCursor Executing: SELECT "user", "code", "time" FROM "public"."accesses" WHERE (("time" < 1200000000)) : - log message Condition pushdown Join pushdown isn’t supported Multi connectors
- 26. Recent updates (0.108~0.117) New functions: normalize(), from_iso8601_timestamp(), from_iso8601_date(), to_iso8601() slice(), md5(), array_min(), array_max(), histogram() element_at(), url_encode(), url_decode() sha1(), sha256(), sha512() multimap_agg(), checksum() Teradata compatibility functions: index(), char2hexint(), to_char(), to_date(), to_timestamp()
- 27. Recent updates (0.108~0.117) Cluster Resource Management. - query.max-memory - query.max-memory-per-node - resources.reserved-system-memory “Big Query” option was removed Semi-joins are hash-partitioned if distributed_join is turned on. Add support for partial cast from JSON. For example, json can be cast to array<json>, map<varchar, json>, etc. Use JSON_PARSE() and JSON_FORMAT() instead of CAST Add query_max_run_time session property and query.max-run-time config. Queries are failed after the specified duration. optimizer.optimize-hash-generation and distributed-joins-enabled are both enabled by default now.
- 28. Recent updates (0.108~0.117) Cluster Resource Management. - query.max-memory - query.max-memory-per-node - resources.reserved-system-memory “Big Query” option was removed Semi-joins are hash-partitioned if distributed_join is turned on. Add support for partial cast from JSON. For example, json can be cast to array<json>, map<varchar, json>, etc. Use JSON_PARSE() and JSON_FORMAT() instead of CAST Add query_max_run_time session property and query.max-run-time config. Queries are failed after the specified duration. optimizer.optimize-hash-generation and distributed-joins-enabled are both enabled by default now. https://highlyscalable.wordpress.com/2013/08/20/in-stream-big-data-processing/
- 29. Who uses Presto? • Facebook http://www.slideshare.net/dain1/presto-meetup-2015
- 30. • Dropbox Who uses Presto?
- 31. • Airbnb Who uses Presto?
- 32. • Qubole • SaaS • Treasure Data • SaaS • Teradata • commercial support Who uses Presto? As a service…
- 33. Today’s talk • What's Presto? • How do we use Presto? • What’s Treasure Data? • System architecture • How we manage Presto
- 35. What’s Treasure Data? and more… • Collect, store and analyze data • With multi-tenancy • With a schema-less structure • On cloud, but mitigates the outage Founded in 2011 in the U.S. Over 85 employees
- 36. What’s Treasure Data? and more… Founded in 2011 in the U.S. Over 85 employees • Collect, store and analyze data • With multi-tenancy • With a schema-less structure • On cloud, but mitigates the outage
- 37. What’s Treasure Data? and more… Founded in 2011 in the U.S. Over 85 employees • Collect, store and analyze data • With multi-tenancy • With a schema-less structure • On cloud, but mitigates the outage
- 38. What’s Treasure Data? and more… Founded in 2011 in the U.S. Over 85 employees • Collect, store and analyze data • With multi-tenancy • With a schema-less structure • On cloud, but mitigates the outage
- 39. What’s Treasure Data? and more… Founded in 2011 in the U.S. Over 85 employees • Collect, store and analyze data • With multi-tenancy • With a schema-less structure • On cloud, but mitigates the outage
- 40. Time to Value Send query result Result Push Acquire Analyze Store Plazma DB Flexible, Scalable, Columnar Storage Web Log App Log Censor CRM ERP RDBMS Treasure Agent(Server) SDK(JS, Android, iOS, Unity) Streaming Collector Batch / Reliability Ad-hoc / Low latency KPI$ KPI Dashboard BI Tools Other Products RDBMS, Google Docs, AWS S3, FTP Server, etc. Metric Insights Tableau, Motion Board etc. POS REST API ODBC / JDBC SQL, Pig Bulk Uploader Embulk, TD Toolbelt SQL-based query @AWS or @IDCF Connectivity Economy & Flexibility Simple & Supported Collect! Store! Analyze!
- 41. Time to Value Send query result Result Push Acquire Analyze Store Plazma DB Flexible, Scalable, Columnar Storage Web Log App Log Censor CRM ERP RDBMS Treasure Agent(Server) SDK(JS, Android, iOS, Unity) Streaming Collector Batch / Reliability Ad-hoc / Low latency KPI$ KPI Dashboard BI Tools Other Products RDBMS, Google Docs, AWS S3, FTP Server, etc. Metric Insights Tableau, Motion Board etc. POS REST API ODBC / JDBC SQL, Pig Bulk Uploader Embulk, TD Toolbelt SQL-based query @AWS or @IDCF Connectivity Economy & Flexibility Simple & Supported Collect! Store! Analyze!
- 42. Time to Value Send query result Result Push Acquire Analyze Store Plazma DB Flexible, Scalable, Columnar Storage Web Log App Log Censor CRM ERP RDBMS Treasure Agent(Server) SDK(JS, Android, iOS, Unity) Streaming Collector Batch / Reliability Ad-hoc / Low latency KPI$ KPI Dashboard BI Tools Other Products RDBMS, Google Docs, AWS S3, FTP Server, etc. Metric Insights Tableau, Motion Board etc. POS REST API ODBC / JDBC SQL, Pig Bulk Uploader Embulk, TD Toolbelt SQL-based query @AWS or @IDCF Connectivity Economy & Flexibility Simple & Supported Collect! Store! Analyze!
- 43. Time to Value Send query result Result Push Acquire Analyze Store Plazma DB Flexible, Scalable, Columnar Storage Web Log App Log Censor CRM ERP RDBMS Treasure Agent(Server) SDK(JS, Android, iOS, Unity) Streaming Collector Batch / Reliability Ad-hoc / Low latency KPI$ KPI Dashboard BI Tools Other Products RDBMS, Google Docs, AWS S3, FTP Server, etc. Metric Insights Tableau, Motion Board etc. POS REST API ODBC / JDBC SQL, Pig Bulk Uploader Embulk, TD Toolbelt SQL-based query @AWS or @IDCF Connectivity Economy & Flexibility Simple & Supported Collect! Store! Analyze!
- 44. Time to Value Send query result Result Push Acquire Analyze Store Plazma DB Flexible, Scalable, Columnar Storage Web Log App Log Censor CRM ERP RDBMS Treasure Agent(Server) SDK(JS, Android, iOS, Unity) Streaming Collector Batch / Reliability Ad-hoc / Low latency KPI$ KPI Dashboard BI Tools Other Products RDBMS, Google Docs, AWS S3, FTP Server, etc. Metric Insights Tableau, Motion Board etc. POS REST API ODBC / JDBC SQL, Pig Bulk Uploader Embulk, TD Toolbelt SQL-based query @AWS or @IDCF Connectivity Economy & Flexibility Simple & Supported Collect! Store! Analyze!
- 45. Time to Value Send query result Result Push Acquire Analyze Store Plazma DB Flexible, Scalable, Columnar Storage Web Log App Log Censor CRM ERP RDBMS Treasure Agent(Server) SDK(JS, Android, iOS, Unity) Streaming Collector Batch / Reliability Ad-hoc / Low latency KPI$ KPI Dashboard BI Tools Other Products RDBMS, Google Docs, AWS S3, FTP Server, etc. Metric Insights Tableau, Motion Board etc. POS REST API ODBC / JDBC SQL, Pig Bulk Uploader Embulk, TD Toolbelt SQL-based query @AWS or @IDCF Connectivity Economy & Flexibility Simple & Supported Collect! Store! Analyze!
- 46. Integrations?
- 47. Treasure Data in figures
- 48. Some of our customers
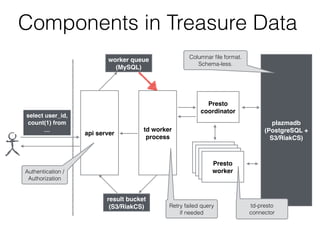
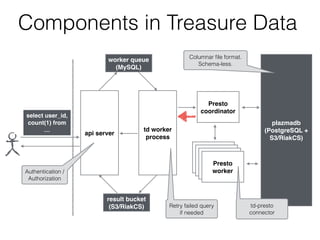
- 50. Components in Treasure Data worker queue (MySQL) api server td worker process plazmadb (PostgreSQL + S3/RiakCS) select user_id, count(1) from … Presto coordinator Presto worker Presto worker Presto worker Presto worker result bucket (S3/RiakCS) Retry failed query if needed Authentication / Authorization Columnar file format. Schema-less. td-presto connector
- 51. worker queue (MySQL) api server td worker process plazmadb (PostgreSQL + S3/RiakCS) select user_id, count(1) from … Presto coordinator Presto worker Presto worker Presto worker Presto worker Retry failed query if needed Authentication / Authorization Columnar file format. Schema-less. td-presto connector result bucket (S3/RiakCS) Components in Treasure Data
- 52. worker queue (MySQL) api server td worker process plazmadb (PostgreSQL + S3/RiakCS) select user_id, count(1) from … Presto coordinator Presto worker Presto worker Presto worker Presto worker Retry failed query if needed Authentication / Authorization Columnar file format. Schema-less. td-presto connector result bucket (S3/RiakCS) Components in Treasure Data
- 53. worker queue (MySQL) api server td worker process plazmadb (PostgreSQL + S3/RiakCS) select user_id, count(1) from … Presto coordinator Presto worker Presto worker Presto worker Presto worker Retry failed query if needed Authentication / Authorization Columnar file format. Schema-less. td-presto connector result bucket (S3/RiakCS) Components in Treasure Data
- 54. worker queue (MySQL) api server td worker process plazmadb (PostgreSQL + S3/RiakCS) select user_id, count(1) from … Presto coordinator Presto worker Presto worker Presto worker Presto worker Retry failed query if needed Authentication / Authorization Columnar file format. Schema-less. td-presto connector result bucket (S3/RiakCS) Components in Treasure Data
- 55. worker queue (MySQL) api server td worker process plazmadb (PostgreSQL + S3/RiakCS) select user_id, count(1) from … Presto coordinator Presto worker Presto worker Presto worker Presto worker Retry failed query if needed Authentication / Authorization Columnar file format. Schema-less. td-presto connector result bucket (S3/RiakCS) Components in Treasure Data
- 56. worker queue (MySQL) api server td worker process plazmadb (PostgreSQL + S3/RiakCS) select user_id, count(1) from … Presto coordinator Presto worker Presto worker Presto worker Presto worker Retry failed query if needed Authentication / Authorization Columnar file format. Schema-less. td-presto connector result bucket (S3/RiakCS) Components in Treasure Data
- 57. worker queue (MySQL) api server td worker process plazmadb (PostgreSQL + S3/RiakCS) select user_id, count(1) from … Presto coordinator Presto worker Presto worker Presto worker Presto worker Retry failed query if needed Authentication / Authorization Columnar file format. Schema-less. td-presto connector result bucket (S3/RiakCS) Components in Treasure Data
- 58. Schema on read time code method user_id 2015-06-01 10:07:11 200 GET 2015-06-01 10:10:12 “200” GET 2015-06-01 10:10:20 200 GET 2015-06-01 10:11:30 200 POST 2015-06-01 10:20:45 200 GET 2015-06-01 10:33:50 400 GET 206 2015-06-01 10:40:11 200 GET 852 2015-06-01 10:51:32 200 PUT 1223 2015-06-01 10:58:02 200 GET 5118 2015-06-01 11:02:11 404 GET 12 2015-06-01 11:14:27 200 GET 3447 access_logs table User added a new column “user_id” in imported data User can select this column with only adding it to the schema (w/o reconstruct the table) Schema on read
- 59. Columnar file format time code method user_id 2015-06-01 10:07:11 200 GET 2015-06-01 10:10:12 “200” GET 2015-06-01 10:10:20 200 GET 2015-06-01 10:11:30 200 POST 2015-06-01 10:20:45 200 GET 2015-06-01 10:33:50 400 GET 206 2015-06-01 10:40:11 200 GET 852 2015-06-01 10:51:32 200 PUT 1223 2015-06-01 10:58:02 200 GET 5118 2015-06-01 11:02:11 404 GET 12 2015-06-01 11:14:27 200 GET 3447 access_logs table time code method user_id Columnar file format This query accesses only code column select code, count(1) from tbl group by code
- 60. td-presto connector • MessagePack v07 • off heap • avoiding “TypeProfile” • Async IO with Jetty-client • Scheduling & Resource management
- 61. How we manage Presto • Blue-Green Deployment • Stress test tool • Monitoring with DataDog
- 62. Blue-Green Deployment worker queue (MySQL) api server td worker process plazmadb (PostgreSQL + S3/RiakCS) select user_id, count(1) from … Presto coordinator result bucket (S3) Presto coordinator Presto worker Presto worker Presto worker Presto worker Presto worker Presto worker Presto worker Presto worker production rc
- 63. Blue-Green Deployment worker queue (MySQL) api server td worker process plazmadb (PostgreSQL + S3/RiakCS) select user_id, count(1) from … Presto coordinator result bucket (S3) Presto coordinator Presto worker Presto worker Presto worker Presto worker Presto worker Presto worker Presto worker Presto worker production rcTest Test Test!
- 64. Blue-Green Deployment worker queue (MySQL) api server td worker process plazmadb (PostgreSQL + S3/RiakCS) select user_id, count(1) from … Presto coordinator result bucket (S3) Presto coordinator Presto worker Presto worker Presto worker Presto worker Presto worker Presto worker Presto worker Presto worker production!Release stable cluster No downtime
- 65. Stress test tool • Collect queries that has ever caused issues. • Add a new query with just adding this entry. • Issue the query, gets the result and implements a calculated digest automatically. • We can send all the queries including very heavy ones (around 6000 stages) to Presto - job_id: 28889999 - result: 227d16d801a9a43148c2b7149ce4657c - job_id: 28889999
- 66. Stress test tool • Collect queries that has ever caused issues. • Add a new query with just adding this entry. • Issue the query, gets the result and implements a calculated digest automatically. • We can send all the queries including very heavy ones (around 6000 stages) to Presto - job_id: 28889999 - result: 227d16d801a9a43148c2b7149ce4657c - job_id: 28889999
- 67. Stress test tool • Collect queries that has ever caused issues. • Add a new query with just adding this entry. • Issue the query, gets the result and implements a calculated digest automatically. • We can send all the queries including very heavy ones (around 6000 stages) to Presto - job_id: 28889999 - result: 227d16d801a9a43148c2b7149ce4657c - job_id: 28889999
- 68. Stress test tool • Collect queries that has ever caused issues. • Add a new query with just adding this entry. • Issue the query, gets the result and implements a calculated digest automatically. • We can send all the queries including very heavy ones (around 6000 stages) to Presto - job_id: 28889999 - result: 227d16d801a9a43148c2b7149ce4657c - job_id: 28889999
- 69. Monitoring with DataDog Presto coordinator Presto worker Presto worker Presto worker Presto worker Presto process td-agent in_presto_metrics/v1/jmx/mbean /v1/query /v1/node out_metricsense DataDog
- 70. Monitoring with DataDog Query stalled time - Most important for us. - It triggers alert calls to us… - It can be mainly increased by td-presto connector problems. Most of them are race condition issue.
- 71. How many queries processed More than 20000 queries / day
- 72. How many queries processed Most queries finish within 1min
- 73. Analytics Infrastructure, Simplified in the Cloud We’re hiring! https://jobs.lever.co/treasure-data