Processing Semantically-Ordered Streams in Financial Services
Download as PPTX, PDF1 like224 views

The document discusses the challenges of achieving in-order processing in stream processing frameworks like Flink and Beam, particularly in financial services which require precise event ordering. It explains the concept of 'sequenced streams' and outlines the differences between traditional event processing and the proposed sequencer architecture to ensure global event order. It calls for improvements in stream processing frameworks to explicitly maintain order from the source during processing, highlighting the importance of preserving order for applications in the financial industry.
















Processing Semantically-Ordered Streams in Financial Services
- 1. Processing Semantically-Ordered Streams in Financial Services Addressing the Lack of Ordering Guarantees in Stream Processing ATOMICWIRE.IO/FLINK-FORWARD-2022
- 2. 3 August 2022 © 2022 Atomic Wire Technology Limited Introduction 2 Patrick Lucas • Previously team lead and software engineer at Yelp. • Moved to Berlin in 2017 to join data Artisans (now Ververica). • An original team member developing Ververica Platform. • Co-founder at Atomic Wire, focusing on stream processing in financial services. Atomic Wire • Originally spun-out of a large Swiss investment bank. • 100% focused on the financial services vertical. • Currently building cloud-native post-trade services for Tier 1 banks. • A key challenge we’ve encountered is achieving in-order processing in Flink and Beam, especially when consuming sequenced streams.
- 3. 3 August 2022 © 2022 Atomic Wire Technology Limited Problem statement Today’s stream processing frameworks are fundamentally about analytics, using millisecond-resolution timestamps for bucketing events (e.g. into a time slice). In-order processing can be achieved, but it is awkward and slow. 3 Currently Provided by Stream Processors Primary Application Focus Typical Requirements in Financial Services Analytics: dividing, transforming, and recombining continuously arriving data Critical-path applications, workflows, observing state changes and lifecycles Guarantees Ordering within a topic / channel Global ordering across topics / channels Latency Sub-second (>100ms) Sub-millisecond (<10μs) Data Streams Real-Time / Batch Change Data Capture (CDC) 1 Sequenced Streams 2 Ordering Mechanism Time-Based (Event Time, Processing Time) Semantically-Ordered 1 CDC streams are typically ordered according to the sequence in which transactions are committed to a database. This is similar to the concept of a sequenced stream, insofar as the ordering of events in the commit log enables downstream applications to replicate state. However, a database does not guarantee the order in which transaction requests are committed. In fact, there are many reasons why transaction requests may be reordered - for example to optimise performance, or when rejected transactions are retried. This is somewhat different to the intent of a sequenced stream, where the order is intended to represent some notion of causality with respect to the order of events in some real-world business process. 2 A sequenced stream represents a set of events that have a total global order (see following slide).
- 4. 3 August 2022 © 2022 Atomic Wire Technology Limited What are “sequenced streams”? A sequenced stream represents a set of events that have a total global order, and where preserving causal / deterministic ordering really matters for correct in-order processing 4 App 1 SEQUENCER App 2 App n Unsequenced App Outputs External Inputs & Outputs (e.g. Client Orders, Market Data) Sequenced streams • A common architectural pattern with origins going back to Lamport scalar clocks: 2 ○ Every input is assigned a globally unique monotonic sequence number and timestamp by a central component known as a sequencer. ○ The stream is disseminated to all nodes / applications in the system, which only operate on these sequenced inputs and never on other external inputs that have not been sequenced. ○ All nodes can have a perfectly synchronised state by virtue of processing identical inputs in identical order. How is this different to Kafka? • The primary difference is that topic- or channel-based middleware do not maintain the relative ordering of messages across topics or channels. • You can think of a sequencer as an extremely fast single-topic broker with persistence and at-least-once delivery semantics. 1 P. Sanghvi, Proof Engineering: The Algorithmic Trading Platform, June 2021. 2 L. Lamport, Time, clocks, and the ordering of events in a distributed system, July 1978. THE SEQUENCED STREAM 1
- 5. 3 August 2022 © 2022 Atomic Wire Technology Limited What precisely does “in-order processing” mean? … and how can it be achieved in Flink? 5 In pseudocode: • This actually works in Flink with caveats if your data arrives already in order, but it’s not particularly satisfying with regard to the guarantees and API the framework provides—we’ll come back to this later. We want to (a) define a stateful callback that is invoked for each incoming event for a particular key, and (b) guarantee the callback is invoked on events in the correct order, however that order is defined
- 6. 3 August 2022 © 2022 Atomic Wire Technology Limited Achieving in-order processing with Flink Case study: Flink CEP 6 • Flink CEP (short for “complex event processing”) is a library for identifying patterns in streams of events, somewhat like a regular expression (e.g. this one or more times followed by that). • It clearly needs to be able to process events in order—but which order? • So, in Flink CEP, the ordering is their time-sequenced order, with processing driven by watermarks. • This is implemented using ProcessFunction, a low-level user function in Flink that gives you access to state and timers, which are needed to accomplish this. … in CEP the order in which elements are processed matters. To guarantee that elements are processed in the correct order when working in event time, an incoming element is initially put in a buffer where elements are sorted in ascending order based on their timestamp, and when a watermark arrives, all the elements in this buffer with timestamps smaller than that of the watermark are processed. This implies that elements between watermarks are processed in event-time order. “ ”
- 7. 3 August 2022 © 2022 Atomic Wire Technology Limited Achieving in-order processing with Flink Time-ordering in Flink CEP 7 t5 Stream (out of order) t1 t3 t4 t2 t5 First event Event timestamp Flink CEP 6 5 4 3 2 1 t1 5 t2 2 t3 4 t4 3 t5 1, 6 5 , 2 , 4 , 3 , 1 , 6 tn : event time x : event ID Processing in event time order Processed first
- 8. 3 August 2022 © 2022 Atomic Wire Technology Limited Achieving in-order processing with Flink Pseudocode example with ProcessFunction 1 2 3 4 5 • Receive events and store in MapState<Timestamp, List<Event>> • Set timer @ timestamp • When timestamp fires, read events and clear state • Sort them again by timestamp (for sub-millisecond resolution) • Invoke callback 1 2 3 4 5
- 9. 3 August 2022 © 2022 Atomic Wire Technology Limited Achieving in-order processing with Flink Problems using ProcessFunction 9 • A downside of this approach is that the order it processes in can only be expressed through the (millisecond-resolution) event timestamps. Order-preserving processing would obviate this expensive approach to reordering, and decouple the order of processing from the event timestamps i You have to trust that your timestamps actually represent the correct order. ii You need additional information on each event in case you ever have two events that occurred within the same millisecond. iii You are setting ~1 timer per input event, and each input event has to be stored in state, which is expensive.
- 10. 3 August 2022 © 2022 Atomic Wire Technology Limited Circuit switching vs. packet switching Can we achieve in-order processing without Flink CEP-style time ordering? 10 Dataflow w/ Beam Packet Switching Bundle distribution (bundles can be reordered) Packets • A central broker distributes bundles of work to a pool of workers, and the bundles can be reordered arbitrarily between any two PTransforms. • In practice, sub-pipelines without a shuffle often get joined, called “fusion” in Dataflow or “chaining” in Flink, but while data doesn’t get reordered in those cases, it’s not guaranteed. Flink Circuit Switching Serial channels (messages are not reordered within a channel) Circuits • Fixed, preallocated network channels which mean data sharded in a particular way cannot be reordered as it flows from task to task. Task 1.1 Task 1.2 Task 1.1 Task 1.2 Broker Worker 2 Worker 1 Worker 3
- 11. 3 August 2022 © 2022 Atomic Wire Technology Limited What if my data is already in order? Processing data from order-preserving sources 11 What if our data source preserves ordering, and that original ordering is the precise order that we want to process in? Is this possible today? Flink Dataflow w/ Beam … implicitly possible today in Flink – due to “circuit switching”, events will not get reordered and user code callbacks will fire in the original order. … not possible today in Dataflow – due to “packet switching”, you can never rely on the ordering of your input data to be preserved. Behaviour is implicit due to an implementation detail of Flink, and is not a guarantee built into the public API layer. No guarantees.
- 12. 3 August 2022 © 2022 Atomic Wire Technology Limited Achieving in-order processing in Dataflow Back to CEP-style reordering 12 Experimenting with Beam on Dataflow • We ran experiments using both BagState and a single timer as well as MapState and a TimerMap • Certainly possible to get the expected reordering behavior, but far from ideal: ○ Dataflow reserves the right to reorder at every DoFn boundary. ○ So, it only works assuredly when performing all processing within the reordering code itself—or by assuming Dataflow will always fuse your reordering step with your processing step. ○ This is not good Beam application design, where all processing is meant to be expressed by chaining or composing PTransforms. Dealbreaker: Extremely high latency When testing with Google Pub/Sub as the source, we experienced delays of 15 to 75 seconds TL;DR – it is possible to implement essentially the same approach as Flink CEP in Beam, but it’s too slow for most use cases
- 13. 3 August 2022 © 2022 Atomic Wire Technology Limited Where do we go from here? How to improve stream processing frameworks for in-order processing 13 01 When using an order-preserving source like Pulsar or Kafka, there should be an explicit option to preserve the source ordering for processing and to configure the topic sharding key to use. 02 When the input data follows the sequenced stream pattern (using monotonically-increasing, gapless sequence IDs) there should be an explicit option to indicate this to the framework such that the expressed sequence can be reconstructed and preserved during processing within the streaming application. i Distributed processing ii Horizontal scaling iii Failure recovery iv State management .. … etc + We still want all the great features we get today from frameworks like Flink … … but the frameworks need an explicit option to preserve the order of processing within each key of a keyed stream.
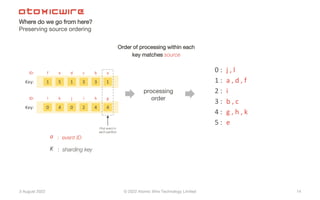
- 14. 3 August 2022 © 2022 Atomic Wire Technology Limited Where do we go from here? Preserving source ordering 14 1 5 1 3 3 f e d c b 0 : 1 : 2 : 3 : 4 : a : event ID K : sharding key processing order ID: Key: 1 a 0 4 0 2 4 l k j i h ID: Key: 4 g 5 : j , l a , d , f i b , c g , h , k e Order of processing within each key matches source First event in each partition
- 15. 3 August 2022 © 2022 Atomic Wire Technology Limited Where do we go from here? Processing sequenced streams 15 a b a b a 11 14 9 4 0 a : b : b a b a b 12 7 8 2 1 0 , 2 , 3 , 6 , 7 , 9 , 11 , 13 1 , 4 , 5 , 8 , 10 , 12 , 14 a b a b a 13 10 6 5 3 Processing held back to wait for out-of-order data n : sequence ID a : financial instrument Order of processing within each key matches sequence ID order
- 16. 3 August 2022 © 2022 Atomic Wire Technology Limited Call for input What do you think? How have you solved this? 16 A Is it possible to build in-order processing guarantees with Flink? B Or is the notion of time too ingrained to accomplish this without cutting all the way to the core engine? We’d like to hear your views on this and learn about your solutions or workaround to this problem.
- 17. We’re Hiring! Stream Processing for Financial Services ATOMICWIRE.IO/CONTACT