Programming in Spark using PySpark
Download as PPTX, PDF3 likes6,279 views

The document outlines the fundamentals of programming with Apache Spark using PySpark, covering session objectives, RDDs, transformations and actions, and visualizing big data. It details the structure of Spark programs which include driver and worker nodes, the creation and manipulation of RDDs, and the usage of shared variables like broadcast and accumulators. Additionally, it discusses the deployment of Spark in cloud environments like Azure and provides resources for further learning.














![pySpark Shared Variables
• Broadcast Variables
» Efficiently send large, read-only value to all workers
» Saved at workers for use in one or more Spark operations
» Like sending a large, read-only lookup table to all the nodes
At the driver: broadcastVar = sc.broadcast([1, 2, 3])
At a worker: broadcastVar.value](https://image.slidesharecdn.com/programminginsparkusingpyspark-public-170217010224/85/Programming-in-Spark-using-PySpark-16-320.jpg)
![• Accumulators
» Aggregate values from workers back to driver
» Only driver can access value of accumulator
» For tasks, accumulators are write-only
» Use to count errors seen in RDD across workers
>>> accum = sc.accumulator(0)
>>> rdd = sc.parallelize([1, 2, 3, 4])
>>> def f(x):
>>> global accum
>>> accum += x
>>> rdd.foreach(f)
>>> accum.value
Value: 10](https://image.slidesharecdn.com/programminginsparkusingpyspark-public-170217010224/85/Programming-in-Spark-using-PySpark-17-320.jpg)








Programming in Spark using PySpark
- 1. Programming in Spark using PySpark Mostafa Elzoghbi Sr. Technical Evangelist – Microsoft @MostafaElzoghbi http://mostafa.rocks
- 2. Session Objectives & Takeaways • Programming Spark • Spark Program Structure • Working with RDDs • Transformations versus Actions • Lambda, Shared Variables (Broadcast vs accumulators) • Visualizing big data in Spark • Spark in the cloud (Azure) • Working with cluster types, notebooks, scaling.
- 3. Python Spark (pySpark) • We are using the Python programming interface to Spark (pySpark) • pySpark provides an easy-to-use programming abstraction and parallel runtime: “Here’s an operation, run it on all of the data” • RDDs are the key concept
- 4. Apache Spark Driver and Workers • A Spark program is two programs: • A driver program and a workers program • Worker programs run on cluster nodes or in local threads • RDDs (Resilient Distributed Datasets) are distributed
- 5. Spark Essentials: Master • The master parameter for a SparkContext determines which type and size of cluster to use
- 6. Spark Context • A Spark program first creates a SparkContext object » Tells Spark how and where to access a cluster » pySpark shell and Databricks cloud automatically create the sc variable » iPython and programs must use a constructor to create a new SparkContext • Use SparkContext to create RDDs
- 7. Resilient Distributed Datasets • The primary abstraction in Spark » Immutable once constructed » Track lineage information to efficiently recompute lost data » Enable operations on collection of elements in parallel • You construct RDDs » by parallelizing existing Python collections (lists) » by transforming an existing RDDs » from files in HDFS or any other storage system
- 8. RDDs • Spark revolves around the concept of a resilient distributed dataset (RDD), which is a fault-tolerant collection of elements that can be operated on in parallel. • Two types of operations: transformations and actions • Transformations are lazy (not computed immediately) • Transformed RDD is executed when action runs on it • Persist (cache) RDDs in memory or disk
- 10. Creating an RDD • Create RDDs from Python collections (lists) • From HDFS, text files, Hypertable, Amazon S3, Apache Hbase, SequenceFiles, any other Hadoop InputFormat, and directory or glob wildcard: /data/201404*
- 11. Working with RDDs • Create an RDD from a data source: <list> • Apply transformations to an RDD: map filter • Apply actions to an RDD: collect count
- 12. Spark Transformations • Create new datasets from an existing one • Use lazy evaluation: results not computed right away – • instead Spark remembers set of transformations applied to base dataset » Spark optimizes the required calculations » Spark recovers from failures and slow workers • Think of this as a recipe for creating result
- 13. Python lambda Functions • Small anonymous functions (not bound to a name) lambda a, b: a+b » returns the sum of its two arguments • Can use lambda functions wherever function objects are required • Restricted to a single expression
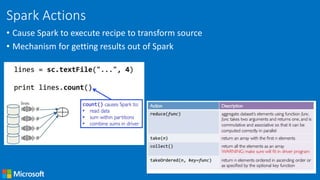
- 14. Spark Actions • Cause Spark to execute recipe to transform source • Mechanism for getting results out of Spark
- 15. Spark Program Lifecycle 1. Create RDDs from external data or parallelize a collection in your driver program 2. Lazily transform them into new RDDs 3. cache() some RDDs for reuse -- IMPORTANT 4. Perform actions to execute parallel 5. Computation and produce results
- 16. pySpark Shared Variables • Broadcast Variables » Efficiently send large, read-only value to all workers » Saved at workers for use in one or more Spark operations » Like sending a large, read-only lookup table to all the nodes At the driver: broadcastVar = sc.broadcast([1, 2, 3]) At a worker: broadcastVar.value
- 17. • Accumulators » Aggregate values from workers back to driver » Only driver can access value of accumulator » For tasks, accumulators are write-only » Use to count errors seen in RDD across workers >>> accum = sc.accumulator(0) >>> rdd = sc.parallelize([1, 2, 3, 4]) >>> def f(x): >>> global accum >>> accum += x >>> rdd.foreach(f) >>> accum.value Value: 10
- 18. Visualizing Big Data in the browser • Challenges: • Manipulating large data can take long time Memory: caching -> Scale clusters CPU: Parallelism -> Scale clusters • We have more data points than possible pixels > Summarize: Aggregation, Pivoting (more data than pixels) > Model (Clustering, Classification, D. Reduction, …etc) > Sample: approximate (faster) and exact sampling • Internal Tools: Matplotlib, GGPlot, D3, SVC, and more.
- 19. Spark Kernels and MAGIC keywords • PySpark kernel supports set of %%MAGIC keywords • It supports built-in IPython built-in magics, including %%sh. • Auto visualization • Magic keywords: • %%SQL % Spark SQL • %%lsmagic % List all supported magic keywords (Important) • %env % Set environment variable • %run % Execute python code • %who % List all variables of global scope • Run code from a different kernel in a notebook.
- 20. Spark in Azure Hadoop clusters in Azure are packaged under “HDInsight” service
- 21. Spark in Azure • Create clusters in few clicks • Apache Spark comes only in Linux OS. • Multiple HDP versions • Comes with preloaded: SSH, Hive, Oozie, DLS, Vnets. • Multiple Storage options: • Azure Storage • ADL store • External metadata store in SQL server database for Hive and Oozie. • All notebooks are stored in the storage account associated with Spark cluster • Zeppelin notebook is available on certain Spark versions but not all.
- 22. Programming Spark Apps in HDInsight • Supports four kernels in Jupyter in HDInsight Spark clusters in Azure
- 23. DEMO Spark Apps using Jupyter
- 24. References • Spark Programming Guide http://spark.apache.org/docs/latest/programming-guide.html • edx.org: Free Apache Spark courses • Visualizations for Databricks https://docs.cloud.databricks.com/docs/latest/databricks_guide/01%20 Databricks%20Overview/15%20Visualizations/0%20Visualizations%20Ov erview.html • SPARKHub by Databricks https://sparkhub.databricks.com/resources/
- 25. Thank you • Check out my blog big data articles: http://mostafa.rocks • Follow me on Twitter: @MostafaElzoghbi • Want some help in building cloud solutions? Contact me to know more.
Editor's Notes
- #2: Ref.: https://azure.microsoft.com/en-us/services/hdinsight/apache-spark/ Apache Spark leverages a common execution model for doing multiple tasks like ETL, batch queries, interactive queries, real-time streaming, machine learning, and graph processing on data stored in Azure Data Lake Store. This allows you to use Spark for Azure HDInsight to solve big data challenges in near real-time like fraud detection, click stream analysis, financial alerts, telemetry from connected sensors and devices (Internet of Things, IoT), social analytics, always-on ETL pipelines, and network monitoring.
- #3: A) Main concepts to cover for Data Science: Regression Classification -- FOCUS Clustering Recommendation B) Building programmable components in Azure ML experiments C) Working with Azure ML studio
- #5: Source: https://courses.edx.org/c4x/BerkeleyX/CS100.1x/asset/Week2Lec4.pdf Spark standalone running on two nodes with two workers: A client process submit an app to the master. The master instructs one of its workers to launch a driver. The worker spawns a driver JVM. The master instructs both works to launch executors for the app. The workers spawn executor JVMs. The driver and executors communicate independent of the cluster’s processes.
- #6: Running Spark: Standalone cluster: Spark standalone comes out of the box. Comes with it is own web UI (monitor and run apps/jobs) Contains of master and worker (also called slave) Mesos and Yarn are also supported in Spark. Yarn is the only cluster manager on which spark can access HDFS secured with Kerberos. Yarn is the new generation of Hadoop’s MapReduce execution engine and can run MapReduce, Spark and other types of programs.
- #16: For that reason, cache is said to 'break the lineage' as it creates a checkpoint that can be reused for further processing. Rule of thumb: Use cache when the lineage of your RDD branches out or when an RDD is used multiple times like in a loop.
- #17: Keep read-only variable cached on workers » Ship to each worker only once instead of with each task • Example: efficiently give every worker a large dataset • Usually distributed using efficient broadcast algorithms
- #19: Extensively used in statistics Spark offers native support for: • Approximate and exact sampling • Approximate and exact stratified sampling Approximate sampling is faster and is good enough in most cases
- #20: 1) Jupyter notebooks kernels with Apache Spark clusters in HDInsight https://docs.microsoft.com/en-us/azure/hdinsight/hdinsight-apache-spark-jupyter-notebook-kernels 2) Ipython built in magics https://ipython.org/ipython-doc/3/interactive/magics.html#cell-magics Source for tipcs and magic keywords: https://www.dataquest.io/blog/jupyter-notebook-tips-tricks-shortcuts/
- #21: Url: https://docs.microsoft.com/en-us/azure/hdinsight/hdinsight-apache-spark-jupyter-spark-sql
- #25: Url: https://docs.microsoft.com/en-us/azure/hdinsight/hdinsight-apache-spark-jupyter-spark-sql
- #26: Spark 2.0 announcements: https://databricks.com/blog/2016/07/26/introducing-apache-spark-2-0.html