project report of social networking web sites
Download as DOCX, PDF21 likes65,058 views

The document describes an algorithm created by the author's uncle to efficiently represent data and minimize memory usage. It explains how the Huffman coding algorithm works to assign variable-length binary codes to characters based on their frequency, allowing more common characters to have shorter codes and less common characters to have longer codes. This results in compressed data that takes up less space on average than fixed-length character encodings. The author provides an example Java implementation of the Huffman algorithm to help students with homework assignments.
![Project Report
On
File (Text/Video) Compression And
Decompression
Submitted as a partial fulfillment of the requirements for the award of the
degree of
Bachelors of Technology
In
Computer Science & Engineering
Submitted By:
Dileep kumar seth
(Roll No. 0802810022)
Mohit Pant
(Roll NO 0802810040)
Under The Guidance of
Mr. Hariom Sharma
(Assistant Professor)
DEPARTMENT OF COMPUTER SCEINCE AND ENGINEERING
Ideal Institute of Technology Ghaziabad [U.P.]
(Approved by AICTE and affiliated to Gautama Budh Technical University Lucknow
U.P.)
July, 2012
i](https://image.slidesharecdn.com/finalpr-120507110612-phpapp01/85/project-report-of-social-networking-web-sites-1-320.jpg)




























![}
} else {
super.processWindowEvent(e);
}
}
}
GUI CONSTANT
package eve;
public interface EveGuiConstants {
String[] algorithmNamesArray = { "Huffman
Compression","GZip Compression",};
String[] extensionArray = { ".huf",".gz",};
final int COMP_HUFFMAN = 0;
final int COMP_SHANNONFANO = 1;
final int COMP_GZIP = 2;
final int COMP_COSMO = 3;
final int COMP_JBC = 4;
final int COMP_RLE = 5;
final int COMP_LZW = 6;
final int COMPRESS = 32;
final int DECOMPRESS = 33;
}
WORKING DIOLOG
package eve;
import java.io.*;
import java.awt.*;
import java.awt.event.*;
import javax.swing.*;
import javax.swing.border.*;
//compression algorithms
import eve.CHuffmanCompressor.*;
import eve.CGZipCompressor.*;
xxxi](https://image.slidesharecdn.com/finalpr-120507110612-phpapp01/85/project-report-of-social-networking-web-sites-31-320.jpg)








![return line + "n" + gSummary + line;
}else return "";
}
}
ENCODER
package eve.CHuffmanCompressor;
import java.io.*;
import eve.FileBitIO.CFileBitWriter;
public class CHuffmanEncoder implements huffmanSignature{
private String fileName,outputFilename;
private HuffmanNode root = null;
private long[] freq = new long[MAXCHARS];
private String[] hCodes = new String[MAXCHARS];
private int distinctChars = 0;
private long fileLen=0,outputFilelen;
private FileInputStream fin;
private BufferedInputStream in;
private String gSummary;
void resetFrequency(){
for(int i=0;i<MAXCHARS;i++)
freq[i] = 0;
distinctChars = 0;
fileLen=0;
gSummary ="";
}
public CHuffmanEncoder(){
loadFile("","");
}
public CHuffmanEncoder(String txt){
loadFile(txt);
}
public CHuffmanEncoder(String txt,String txt2){
loadFile(txt,txt2);
}
public void loadFile(String txt){
fileName = txt;
outputFilename = txt + strExtension;
resetFrequency();
}
xl](https://image.slidesharecdn.com/finalpr-120507110612-phpapp01/85/project-report-of-social-networking-web-sites-40-320.jpg)
![public void loadFile(String txt,String txt2){
fileName = txt;
outputFilename = txt2;
resetFrequency();
}
public boolean encodeFile() throws Exception{
if(fileName.length() == 0) return false;
try{
fin = new FileInputStream(fileName);
in = new BufferedInputStream(fin);
}catch(Exception e){ throw e; }
//Frequency Analysis
try
{
fileLen = in.available();
if(fileLen == 0) throw new Exception("File is Empty!");
gSummary += ("Original File Size : "+ fileLen + "n");
long i=0;
in.mark((int)fileLen);
distinctChars = 0;
while (i < fileLen)
{
int ch = in.read();
i++;
if(freq[ch] == 0) distinctChars++;
freq[ch]++;
}
in.reset();
}
catch(IOException e)
{
throw e;
//return false;
}
gSummary += ("Distinct Chars " + distinctChars + "n");
/*
System.out.println("distinct Chars " + distinctChars);
//debug
for(int i=0;i<MAXCHARS;i++){
if(freq[i] > 0)
System.out.println(i + ")" + (char)i + " : " + freq[i]);
}
*/
xli](https://image.slidesharecdn.com/finalpr-120507110612-phpapp01/85/project-report-of-social-networking-web-sites-41-320.jpg)
![CPriorityQueue cpq = new CPriorityQueue (distinctChars+1);
int count = 0 ;
for(int i=0;i<MAXCHARS;i++){
if(freq[i] > 0){
count ++;
//System.out.println("ch = " + (char)i + " : freq = " + freq[i]);
HuffmanNode np = new HuffmanNode(freq[i],(char)i,null,null);
cpq.Enqueue(np);
}
}
//cpq.displayQ();
HuffmanNode low1,low2;
while(cpq.totalNodes() > 1){
low1 = cpq.Dequeue();
low2 = cpq.Dequeue();
if(low1 == null || low2 == null) { throw new Exception("PQueue Error!"); }
HuffmanNode intermediate = new
HuffmanNode((low1.freq+low2.freq),(char)0,low1,low2);
if(intermediate == null) { throw new Exception("Not Enough Memory!"); }
cpq.Enqueue(intermediate);
}
//cpq.displayQ();
//root = new HuffmanNode();
root = cpq.Dequeue();
buildHuffmanCodes(root,"");
for(int i=0;i<MAXCHARS;i++) hCodes[i] = "";
getHuffmanCodes(root);
/*
//debug
for(int i=0;i<MAXCHARS;i++){
if(hCodes[i] != ""){
System.out.println(i + " : " + hCodes[i]);
}
}
*/
CFileBitWriter hFile = new CFileBitWriter(outputFilename);
hFile.putString(hSignature);
String buf;
buf = leftPadder(Long.toString(fileLen,2),32); //fileLen
hFile.putBits(buf);
xlii](https://image.slidesharecdn.com/finalpr-120507110612-phpapp01/85/project-report-of-social-networking-web-sites-42-320.jpg)
![buf = leftPadder(Integer.toString(distinctChars-1,2),8); //No of
Encoded Chars
hFile.putBits(buf);
for(int i=0;i<MAXCHARS;i++){
if(hCodes[i].length() != 0){
buf = leftPadder(Integer.toString(i,2),8);
hFile.putBits(buf);
buf =
leftPadder(Integer.toString(hCodes[i].length(),2),5);
hFile.putBits(buf);
hFile.putBits(hCodes[i]);
}
}
long lcount = 0;
while(lcount < fileLen){
int ch = in.read();
hFile.putBits(hCodes[(int)ch]);
lcount++;
}
hFile.closeFile();
outputFilelen = new File(outputFilename).length();
float cratio = (float)(((outputFilelen)*100)/(float)fileLen);
gSummary += ("Compressed File Size : " + outputFilelen + "n");
gSummary += ("Compression Ratio : " + cratio + "%" + "n");
return true;
}
void buildHuffmanCodes(HuffmanNode parentNode,String parentCode){
parentNode.huffCode = parentCode;
if(parentNode.left != null)
buildHuffmanCodes(parentNode.left,parentCode + "0");
if(parentNode.right != null)
buildHuffmanCodes(parentNode.right,parentCode + "1");
}
void getHuffmanCodes(HuffmanNode parentNode){
if(parentNode == null) return;
int asciiCode = (int)parentNode.ch;
if(parentNode.left == null || parentNode.right == null)
hCodes[asciiCode] = parentNode.huffCode;
if(parentNode.left != null ) getHuffmanCodes(parentNode.left);
if(parentNode.right != null ) getHuffmanCodes(parentNode.right);
xliii](https://image.slidesharecdn.com/finalpr-120507110612-phpapp01/85/project-report-of-social-networking-web-sites-43-320.jpg)

![gSummary = "";
}
String stripExtension(String ff,String ext){
ff = ff.toLowerCase();
if(ff.endsWith(ext.toLowerCase())){
return ff.substring(0,ff.length()-ext.length());
}
return ff + ".dat";
}
public void loadFile(String txt,String txt2){
fileName = txt;
outputFilename = txt2;
gSummary = "";
}
public boolean decodeFile()throws Exception{
try{
fileLen = new File(fileName).length();
GZIPInputStream gzipInputStream = new GZIPInputStream(new
FileInputStream(fileName));
// Open the output file
OutputStream out = new FileOutputStream(outputFilename);
// Transfer bytes from the compressed file to the output
file
byte[] buf = new byte[1024];
int len;
while ((len = gzipInputStream.read(buf)) > 0) {
out.write(buf, 0, len);
}
// Close the file and stream
gzipInputStream.close();
out.close();
outputFilelen = new File(outputFilename).length();
gSummary += ("Compressed File Size : "+ fileLen +
"n");
gSummary += ("Original File Size : "+ outputFilelen
+ "n");
}catch(Exception e){throw e;}
xlv](https://image.slidesharecdn.com/finalpr-120507110612-phpapp01/85/project-report-of-social-networking-web-sites-45-320.jpg)

![if(fileLen == 0 ) throw new Exception("Source File Empty!");
gSummary += "Original Size : " + fileLen + "n";
byte[] buf = new byte[1024];
int len;
while ((len = in.read(buf)) > 0) {
out.write(buf, 0, len);
}
in.close();
out.finish();
out.close();
outputFilelen = new File(outputFilename).length();
float cratio = (float)(((outputFilelen)*100)/(float)fileLen);
gSummary += ("Compressed File Size : " + outputFilelen + "n");
gSummary += ("Compression Ratio : " + cratio + "%" + "n");
}catch(Exception e){throw e; }
return true;
}
public String getSummary(){
return gSummary;
}
}
FILE BIT IO
FILE BIT READER
package eve.FileBitIO;
import java.io.*;
//File Bit Reader - Read Files BitWise
public class CFileBitReader {
private String fileName;
private File inputFile;
private FileInputStream fin;
private BufferedInputStream in;
xlvii](https://image.slidesharecdn.com/finalpr-120507110612-phpapp01/85/project-report-of-social-networking-web-sites-47-320.jpg)


























project report of social networking web sites
- 1. Project Report On File (Text/Video) Compression And Decompression Submitted as a partial fulfillment of the requirements for the award of the degree of Bachelors of Technology In Computer Science & Engineering Submitted By: Dileep kumar seth (Roll No. 0802810022) Mohit Pant (Roll NO 0802810040) Under The Guidance of Mr. Hariom Sharma (Assistant Professor) DEPARTMENT OF COMPUTER SCEINCE AND ENGINEERING Ideal Institute of Technology Ghaziabad [U.P.] (Approved by AICTE and affiliated to Gautama Budh Technical University Lucknow U.P.) July, 2012 i
- 2. Certificate This is to certify that this project entitled “File compression (Text/video) / decompression” submitted by Mohit Pant(0802810040), Dileep Kr. Seth (0802810022) students of Computer Science and Engineering Department, Ideal Institute of Technology , Ghaziabad in the partial fulfillment of the requirement for the award of Bachelors of Technology (Computer Science & Engineering) Degree of UPTU, Lucknow, is a record of students own study carried under my supervision & guidance. This report has not been submitted to any other university or institution for the award of any degree. Name of Project Guide Mr. Hari Om Sharma Designation Project Co-ordinator ii
- 3. Acknowledgement Any task in the world cannot be accomplished on a sole basis. It directly or indirectly needs the overt or covert support of their acquaintances, beloved ones or their faculty heads. We have culminated our project with the aid of not only our friends but the assistance provided by our faculties cannot be neglected. Thus we would like to give a sincere thank to my institute “Ideal Institute of Technology, Ghaziabad” for providing me the platform in which we have put my raw knowledge of concepts to an implementation level. The availabilities of laboratories with skilled technicians made our job easier. The facility of internet provided us with the ease which helped us to reach the implementation level fast. We would like to honor our director Dr. G. P. Govil, Director, IIT-Ghaziabad, for the incredible support he gave us. He fostered and encouraged us to pursue it to finish it to the rising stars. His motivation acted as a strength for us. Our acknowledgement cannot be complete without mentioning this name who have not only supported us but also showered his experience drops on our project which makes it embellishing and a full fledged technology. Being a project guide, Mr. Hari Om Sharma was not centralized by vesting all the power of project to himself. In spite of this he delegated his knowledge to us which helped us to learn a lot. A special thanks to all faculty members who were keen to respond our queries. Support of our colleagues cannot be snubbed. Last but not least we would like to thank our parents for supporting us to complete our presentation report in all ways. iii
- 4. Abstract Social network sites (SNSs) are increasingly attracting the attention of academic and industry researchers intrigued by their affordances and reach. This special theme section of the Journal of Computer-Mediated Communication brings together scholarship on these emergent phenomena. In this introductory article, we describe features of SNSs and propose a comprehensive definition. We then present one perspective on the history of such sites, discussing key changes and developments. After briefly summarizing existing scholarship concerning SNSs, we discuss the articles in this special section and conclude with considerations for future research. iv
- 5. Table of Contents CHAPTER NO TITLE PAGE NO. 1. INTRODUCTION 1.1 KEY FEATURES 2. PURPOSE 2.1 EXISTING SYSTEM 2.2 PROPOSED SYSTEM 3. SYSTEM DESCRIPTION 3.1 TECHNOLOGIES USED 3.1.1 JAVA 3.2 TOOLS USED 3.2.1 My eclipse 3.2.2 Oracle 11g 3.2.3 Adobe Dreamwear 4. MODULE DESCRIPTION 4.1 Create Account 4.2 Access Your Account 4.3 View Your profile 4.4 Share Ideas 4.5 Search friends,send messages and edit account 5. SOFTWARE REQUIREMENT SPECIFICATION 5.1 REQUIREMENT ELICITAION 5.2 REQUIREMENT SPECIFICATION 5.3 IDENTIFICATION OF NEEDS 5.4 PRELIMINARY INVESTIGATION v
- 6. 5.5 SOFTWARE ENGINEERING PARADIGM 6 ANALYSIS 6.1 FEASIBILITY STUDY 6.1.1 TECHNICAL FEASIBILITY 6.1.2 ECONOMIC FEASIBILITY 6.1.3 BEHAVIORAL FEASIBILITY 6.2 PRODUCT FUNCTION 6.3 USER CHARACTERISTICS 7 SYSTEM DESIGN 7.4 SOFTWARE DESIGN 7.4.1 CODING FRAME DESIGN GUI CONSTANT WORKING DIOLOG 7.4.2 SOFTWARE INTEGRATION & VERIFICATION 7.4.3 SYSTEM VERIFICATION 7.4.4 OPERATION & MAINTAINENCE 7.5 DESIGN STRATERGY 7.5.1 BOTTOM-UP 7.9.2 OBJECT ORIENTED DESIGN 7.6 DATA FLOW DIAGRAM 7.6.1 CONTEXT LEVEL DIAGRAM 7.6.2 LEVEL 1 DFD 7.7 USE CASE DIAGRAM 7.11 FLOW CHART 8 TESTING 9 SCREEN SHOTS 10 CONCLUSION 11 APPENDIX – REFERENCES vi
- 7. CHAPTER 1 INTRODUCTION Since their introduction, social network sites (SNSs) such as MySpace, Facebook, Cyworld, and Bebo have attracted millions of users, many of whom have integrated these sites into their daily practices. As of this writing, there are hundreds of SNSs, with various technological affordances, supporting a wide range of interests and practices. While their key technological features are fairly consistent, the cultures that emerge around SNSs are varied. Most sites support the maintenance of pre-existing social networks, but others help strangers connect based on shared interests, political views, or activities. Some sites cater to diverse audiences, while others attract people based on common language or shared racial, sexual, religious, or nationality-based identities. Sites also vary in the extent to which they incorporate new information and communication tools, such as mobile connectivity, blogging, and photo/video-sharing. Scholars from disparate fields have examined SNSs in order to understand the practices, implications, culture, and meaning of the sites, as well as users' engagement with them. This special theme section of the Journal of Computer-Mediated Communication brings together a unique collection of articles that analyze a wide spectrum of social network sites using various methodological techniques, theoretical traditions, and analytic approaches. By collecting these articles in this issue, our goal is to showcase some of the interdisciplinary scholarship around these sites. The purpose of this introduction is to provide a conceptual, historical, and scholarly context for the articles in this collection. We begin by defining what constitutes a social network site and then present one perspective on the historical development of SNSs, drawing from personal interviews and public accounts of sites and their changes over time. Following this, we review recent scholarship on SNSs and attempt vii
- 8. to contextualize and highlight key works. We conclude with a description of the articles included in this special section and suggestions for future research. . CHAPTER 3 PURPOSE A social networking service is an online service, platform, or site that focuses on facilitating the building of social networks or social relations among people who, for example, share interests, activities, backgrounds, or real-life connections. A social network service consists of a representation of each user (often a profile), his/her social links, and a variety of additional services. Most social network services are web-based and provide means for users to interact over the Internet, such as e- mail and instant messaging. Online community services are sometimes considered as a social network service, though in a broader sense, social network service usually means an individual-centered service whereas online community services are group- centered. Social networking sites allow users to share ideas, activities, events, and interests within their individual networks. Social networking sites are not only for you to communicate or interact with other people globally but, this is also one effective way for business promotion. A lot of business minded people these days are now doing business online and use these social networking sites to respond to customer queries. It isn't just a social media site used to socialize with your friends but also, represents a huge pool of information from day to dayliving. viii
- 9. CHAPTER 4 SYSTEM DESCRIPTION 3.1 TECHNOLOGIES USED: JAVA : Programming Interface 3.1.1 JAVA Java is a small, simple, safe, object oriented, interpreted or dynamically optimized, byte coded, architectural, garbage collected, multithreaded programming language with a strongly typed exception-handling for writing distributed and dynamically extensible programs. Java is an object oriented programming language. Java is a high-level, third generation language like C, FORTRAN, Small talk, Pearl and many others. You can use java to write computer applications that crunch numbers, process words, play ix
- 10. games, store data or do any of the thousands of other things computer software can do. Special programs called applets that can be downloaded from the internet and played safely within a web browser. Java a supports this application and the follow features make it one of the best programming languages. It is simple and object oriented. It helps to create user friendly interfaces. It is very dynamic. TOOLS USED: NETBEANS 7.0 Current versions Net Beans IDE 6.0 introduced support for developing IDE modules and rich client applications based on the Net Beans platform, a Java Swing GUI builder (formerly known as "Project Matisse"), improved CVS support, Web Logic 9 and JBoss 4 support, and many editor enhancements. Net Beans 6 is available in official repositories of major Linux distributions. Net Beans IDE 6.5, released in November 2008, extended the existing Java EE features (including Java Persistence support, EJB 3 and JAX-WS). Additionally, the Net Beans Enterprise Pack supports development of Java EE 5 enterprise applications, including SOA visual design tools, XML schema tools, web services orchestration (for BPEL), and UML modeling. The Net Beans IDE Bundle for C/C++ supports C/C++ and FORTRAN development. Net Beans IDE 6.8 is the first IDE to provide complete support of Java EE 6 and the Glass Fish Enterprise Server v3. Developers hosting their open-source projects on kenai.com additionally benefit from instant messaging and issue tracking integration and navigation right in the IDE, support for web application x
- 11. development with PHP 5.3 and the Symfony framework, and improved code completion, layouting, hints and navigation in JavaFX projects. Net Beans IDE 6.9, released in June 2010, added support for OSGi, Spring Framework 3.0, Java EE dependency injection (JSR-299), Z end Framework for PHP, and easier code navigation (such as "Is Overridden/Implemented" annotations), formatting, hints, and refactoring across several languages. NetBeans IDE 7.0 was released in April 2011. On August 1, 2011, the NetBeans Team released NetBeans IDE 7.0.1, which has full support for the official release of the Java SE 7 platform. CHAPTER 5 xi
- 12. MODULE DESCRIPTION There are four modules in this project: 4.1 Compression This module helps us to compress a file or folder. The compressed file will have a extension that has been given at the development time. We can send the compressed file over the internet so that users having this software can decompress it. 4.2 Decompression This is the reverse process of file compression. Here we can decompress the compressed file and get the original file. 4.3 View files in the compressed file Here we can view the list of files inside our compressed file. We can view the files before decompressing and decide to decompress or not. 4.4 Set icon and extension This is additional feature in our project. We can set our own extension to the compressed file. More than that we can specify the style of icon for the compressed file. Users will also be given a option to change the icon as per their preference. Algorithm Description . To avoid a college assignment The domain name of this website is from my uncle’s algorithm. In nerd circles, his algorithm is pretty well known. Often college computer science textbooks will refer to the algorithm as an example when teaching programming techniques. I wanted to keep the domain name in the family so I had to pay some domain squatter for the rights to it. Back in the early 1950’s, one of my uncle’s professors challenged him to come up with an algorithm that would calculate the most efficient way to represent data, minimizing the amount of memory required to store that information. It is a simple question, but one without an obvious solution. In fact, my uncle took the challenge from his professor to get out of taking the final. He wasn’t told that no one had solved the problem yet. xii
- 13. I’ve written a simple program to demonstrate Huffman Coding in Java. Because I have this web site, several times a year I receive a frantic e-mail from a college student stating, basically, “I have a homework assignment to code the Huffman Algorithm and it is due next week. I am too lazy or clueless to do the work myself, so can you just send me the source code so I can pass it off as my own.” I don’t normally accommodate them, but perhaps this will help them do their own homework. A little of bit of background Computers store information in zeros and ones: binary “off”s and “on”s. The standard way of storing characters on a computer is to give each character a sequence of 8 bits (or “binary digits”) which can be 0’s or 1’s. This allows for 256 possible characters (because 2 to the 8th power is 256). For example, the letter “A” is given the unique code of 01000001. Unicode allocates 16 bits per character and it handles even non- Roman alphabets. It is simply easier for computers to handle characters when they all are the same size. The more bits you allow per character the more characters you can support in your alphabet. But when you make every character the same size, it can waste space. In written text, all characters are not created equal. The letter “e” is pretty common in English text, but rarely does one see a “Z.” But since it is possible to encounter both in text, each has to be assigned a unique sequence of bits. But if “e” was a 7-bit sequence and “Z” was 9 bits then, on average, a message would be slightly smaller than otherwise because there would be more short sequences than long sequences. You could compound the savings by adjusting the size of every character and by more than 1 bit. Even before computers, Samuel Morse took this into account when assigning letters to his code. The very common letter “E” is the short sequence of “·” and the uncommon letter “Q” is the longer sequence of “— — · —.” He came up with Morse code by looking at the natural distribution of letters in the English alphabet and guessing from there. Morse code isn’t perfect because some common letters have longer codes than less common ones. For example the letter “O,” which is a long “— — —,” is more common than the letter “I,” which is the shorter code “· ·.” If these two assignments where swapped, then it would be slightly quicker, on average, to transmit Morse code. Huffman Coding is a methodical way for determining how to best assign zeros and ones. It was one of the first algorithms for the computer age. By the way, Morse code is not really a binary code because it puts pauses between letters and words. If we were to put some bits between each letter to represent pauses, it wouldn’t result in the shortest messages possible. This adjusting of the codes is called compression and sometimes the computational effort in compressing data (for storage) and later uncompressing it (for use) is worth the trouble. The more space a text file takes up makes it slower to transmit from one computer to another. Other types of files, which have even more variability than the English language, compress even better than text. Uncompressed sound (.WAV) and image (.BMP) files are usually at least ten times as big as their compressed equivalents (.MP3 and .JPG respectively). Web pages would take ten times as long to download if we didn’t take advantage of data compression. Fax pages would take longer to transmit. You get the idea. All of these compressed formats take advantage of Huffman Coding. xiii
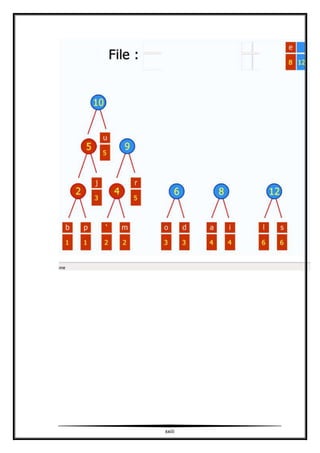
- 14. Again, the trick is to choose a short sequence of bits for representing common items (letters, sounds, colors, whatever) and a longer sequence for the items that are encountered less often. When you average everything out, a message will require less space if you come up with good encoding dictionary. Mixing art and computer science You cannot just start assigning letters to unique sequences of 0’s and 1’s because there is a possibility of ambiguity if you do not do it right. For example, the four most common letters of the English alphabet are “E,” “T,” “O,” and “A.” You cannot just assign 0 to “E,” 1 to “T,” 00 to “O,” 01 to “A,” because if you encounter “…01…” in a message, you could not tell if the original message contained “A” or the sequence “ET.” The code for a letter cannot be the same as the front part of a different letter. To avoid this ambiguity, we need a way of organizing the letters and their codes that prevents this. A good way of representing this information is something computer programmers call a binary tree. Alexander Calder is an American artist who builds mobiles and really likes the colors red and black. One of his larger works hangs from the East building atrium at the National Gallery, but he had made several similar to it. The mobile hangs from a single point in the middle of a pole. It slowly sways as the air circulates in the room. On each end of the pole you’ll see either a weighted paddle or a connection to the middle of another pole. Similarly, those lower poles have things hanging off of them too. At the lowest levels, all the poles have weights on their ends. Programmers would look at this mobile and think of a binary tree, a common structure for storing program data. This is because every mobile pole has exactly two ends. For the sake of this algorithm, one end of the pole is considered “0” while the end is “1.” The weights at the ends of the poles will have letters associated with them. If an inchworm were to travel from the top of the mobile to a letter, it would walk down multiple poles, sometimes encountering the “0” and sometimes the “1.” The sequence of binary digits to the letter ends up corresponding to the encoding of that letter. xiv
- 15. Let us build a mobile So how do we build that perfectly balanced mobile? The first step of Huffman Coding is to count the frequency of all the letters in the text. Sticking with mobile analogy, we need to create a bunch of loose paddles, each one painted with a letter in the alphabet. The weight of each paddle is proportional to the number of times that letter appears in the text. For example, if the letter “q” appears twice, then its paddle should weight two ounces and the “e” paddle would weigh 10 ounces if that many “e”s were present. Every paddle has a loop for hanging. For our example, lets assume that in our tiny file there were two “q”, three “w”s, six “s”s, and ten “e”s. Now lets prepare some poles. We’ll need one fewer poles than unique characters. For example, with 4 unique characters we’ll need 3 poles. One end of each pole is “0” and the other end is “1.” Each pole will have a hook on both ends for holding things and a loop in the middle for being hung itself. In my imaginary world, poles weigh nothing. Now let us line up all the paddles then find the two lightest of them and connect them to opposite ends of a pole. In the example below, ”q“ and ”w“ were the lightest (least frequent). From now on, we’ll consider those two paddles and their pole as one inseparable thing. The weight of the “q+w” object is the sum of the two individual paddles. Remember the pole itself weighs nothing. We’ll put down the object then we’ll repeat the process. The two lightest things in the room now may be an individual paddle or possibly a previously connected contraption. In the picture below, “q+w” (with a weight of 5) and “s” (with a weight of 6) were the next two lightest objects. Then we are left with a “q+w+s” (with a weight of 11) and “e” (with a weight of 10) as the last two groupings. We’ll attach those two together. We are attaching the poles from the bottom up. We’ve hooked up the two lightest things until we’ve got exactly one contraption that contains the weight of the entire text. So what do we do with this tree? Now let’s hang up the mobile and admire our handiwork. The heaviest paddles (like the frequent “e”) will have a tendency to be nearer to the top because they were added later while to the lightest paddles (the infrequent “q”) will be at the bottom because they were grabbed first and connect to pole after pole, and so forth. In other words, the path from the top to the common letters will be the shortest binary sequence. The path from the top to the rare letters at the bottom will be much longer. The code for xv
- 16. “e” is “0”, “s” is “10”, “w” is “111” and “q” is “110.” We have built a Huffman Coding tree. To finish compressing the file, we need to go back and re-read the file. This time, instead of just counting the characters, we’ll lookup, in our tree, each character encountered in the file and write its sequence of zeros and ones to a new file. Later, when we want to restore the original file, we’ll read the zeros and ones and use the tree to decode them back into characters. This implies that when we must have the tree around at the time we decompressing it. Commonly this is accomplished by writing the tree structure at the beginning of the compressed file. This will make the compressed file a little bigger, but it is a necessary evil. You have to have the secret decoder ring before you can pass notes in class. Other ways of squeezing data Since my uncle devised his coding algorithm, other compression schemes have come into being. Someone noticed that the distribution of characters may vary at different spots in the source, for example a lot of “a”s around the beginning of the file but later there might be a disproportionate number of “e”s. When that is the case, it is occasionally worth the effort to adjust how the Huffman tree hangs while running through the file. One could slice the file into smaller sections and have different trees for each section. This is called Adaptive Huffman Coding. Three other guys (Lempel, Ziv and Welch) realized that certain sequences of characters can be common, for example the letter “r” is often followed by the letter “e”, so we could treat the sequence “re” as just another letter when assigning codes. Sometimes it is not necessary to re-create the original source exactly. For example, with image files the human eye cannot detect every subtle pixel color difference. The JPEG (“Joint Photography Expert Group”) format “rounds” similar hues to the same value then applies the Huffman algorithm to the simplified image. The MP3 music format uses a similar technique for sound files. My uncle’s algorithm makes the world a smaller place. xvi
- 17. xvii
- 18. xviii
- 19. xix
- 20. xx
- 21. xxi
- 22. xxii
- 23. xxiii
- 24. xxiv
- 25. xxv
- 26. CHAPTER 6 ANALYSIS 6.1 FEASIBILITY STUDY Feasibility study is made to see if the project on completion will serve the purpose of the organization for the amount of work, effort and the time that spend on it. Feasibility study lets the developer foresee the future of the project and the usefulness. A feasibility study of a system proposal is according to its workability, which is the impact on the organization, ability to meet their user needs and effective use of resources. Thus when a new application is proposed it normally goes through a feasibility study before it is approved for development. The document provide the feasibility of the project that is being designed and lists various areas that were considered very carefully during the feasibility study of this project such as Technical, Economic and Operational feasibilities. The following are its features: 6.1.1 TECHNICAL FEASIBILITY The system must be evaluated from the technical point of view first. The assessment of this feasibility must be based on an outline design of the system requirement in the terms of input, output, programs and procedures. Having identified an outline system, the investigation must go on to suggest the type of equipment, required method developing the system, of running the system once it has been designed. Technical issues raised during the investigation are: Does the existing technology sufficient for the suggested one? Can the system expand if developed? The project should be developed such that the necessary functions and performance are achieved within the constraints. The project is developed within latest technology. Through the technology may become obsolete after some period of time, due to the fact that never version of same software supports older versions, the system may still be used. So there are minimal constraints involved with this project. The system has been developed using Java the project is technically feasible for development. We as Analysts have identified the existing computer systems (hardware & software) of the concerned department and have determined whether these technical resources xxvi
- 27. are sufficient for the proposed system or not. We have found out thus, that the project is technically very much feasible. The hardware and software requirements are: IDE: Net beans, My eclipse. Operating system: Any as Windows, Linux. 6.1.2 ECONOMIC FEASIBILITY The developing system must be justified by cost and benefit. Criteria to ensure that effort is concentrated on project, which will give best, return at the earliest. One of the factors, which affect the development of a new system, is the cost it would require. The following are some of the important financial questions asked during preliminary investigation: The costs conduct a full system investigation. The cost of the hardware and software. The benefits in the form of reduced costs or fewer costly errors. Since the system is developed as part of project work, there is no manual cost to spend for the proposed system. Also all the resources are already available, it give an indication of the system is economically possible for development. 6.1.3 BEHAVIORAL FEASIBILITY This includes the following questions: Is there sufficient support for the users? Will the proposed system cause harm? The project would be beneficial because it satisfies the objectives when developed and installed. All behavioral aspects are considered carefully and conclude that the project is behaviorally feasible. 6.2 PRODUCT FUNCTION: The Domain File Compression mainly include 4 modules • Compress A File Or Folder xxvii
- 28. • De-Compress the file or folder • View files in the compressed file • Facility to set icon and your own extension 6.3 USER CHARACTERISTICS: User: User can select any type of file for the purpose of compression or decompression, to send it over the network with greater speeds. End Users: 1.) He must know to how to operate the software. 2.) He must have basic knowledge of computer. xxviii
- 29. 7.8.1 CODING: Based on the software design document the work is aiming to set up the defined modules or units and actual coding is started. The system is first developed in smaller portions called units. They are able to stand alone from a functional aspect and are integrated later on to form the complete software package. FRAME DESIGN package eve; import java.awt.*; import java.awt.event.*; import javax.swing.*; import javax.swing.border.*; public class EveFrame extends JFrame{ private JTabbedPane tabbedPane = new JTabbedPane(); private EveComp panCompression; private EveAbout panAbout; private JLabel lblBanner; void centerWindow(){ Dimension screensize = Toolkit.getDefaultToolkit().getScreenSize(); setLocation((screensize.width / 2) - (getSize().width / 2), (screensize.height / 2) - (getSize().height / 2)); } EveFrame(){ setVisible(false); setTitle("FileZip - Compress Better, Compress Faster!"); setSize(425,390); centerWindow(); setLayout(new BorderLayout(5,5)); lblBanner = new JLabel("FileZip by Ajay,Abhishek & Devanshu",SwingConstants.CENTER); lblBanner.setSize(400,25); xxix
- 30. lblBanner.setFont(new Font("Monotype Corsiva",Font.BOLD & Font.ITALIC,42)); panCompression = new EveComp(this,false); panAbout = new EveAbout(this,false); tabbedPane.addTab("Compressor/Decompressor",panCompression); tabbedPane.addTab("About FileZip",panAbout); //The following line enables to use scrolling tabs. tabbedPane.setTabLayoutPolicy(JTabbedPane.SCROLL_TAB_LAYOUT); getContentPane().add(lblBanner,BorderLayout.NORTH ); getContentPane().add(tabbedPane,BorderLayout.CENTER); setResizable(false); setVisible(true); } protected void processWindowEvent(WindowEvent e) { if (e.getID() == WindowEvent.WINDOW_CLOSING) { //System.exit(0); //remove on release int exit = JOptionPane.showConfirmDialog(this, "Are you sure?","Confirm Exit?",JOptionPane.YES_NO_OPTION); if (exit == JOptionPane.YES_OPTION) { System.exit(0); xxx
- 31. } } else { super.processWindowEvent(e); } } } GUI CONSTANT package eve; public interface EveGuiConstants { String[] algorithmNamesArray = { "Huffman Compression","GZip Compression",}; String[] extensionArray = { ".huf",".gz",}; final int COMP_HUFFMAN = 0; final int COMP_SHANNONFANO = 1; final int COMP_GZIP = 2; final int COMP_COSMO = 3; final int COMP_JBC = 4; final int COMP_RLE = 5; final int COMP_LZW = 6; final int COMPRESS = 32; final int DECOMPRESS = 33; } WORKING DIOLOG package eve; import java.io.*; import java.awt.*; import java.awt.event.*; import javax.swing.*; import javax.swing.border.*; //compression algorithms import eve.CHuffmanCompressor.*; import eve.CGZipCompressor.*; xxxi
- 32. public class EveWorkingDlg extends JDialog implements ActionListener,EveGuiConstants{ private JFrame owner; private JProgressBar prgBar; private JButton btnCancel; private JLabel lblNote; private String gSummary = ""; private String iFilename,oFilename; private boolean bCompress = false; private int algoSelected; void centerWindow(){ Dimension screensize = Toolkit.getDefaultToolkit().getScreenSize(); setLocation((screensize.width / 2) - (getSize().width / 2), (screensize.height / 2) - (getSize().height / 2)); } EveWorkingDlg(JFrame parent){ super(parent,true); owner = parent; setDefaultCloseOperation(JDialog.DO_NOTHING_ON_CLOS E); addWindowListener(new WindowAdapter() { public void windowClosing(WindowEvent we) { //setTitle("Thwarted user attempt to close window."); } }); setSize(300,120); centerWindow(); buildDlg(); setResizable(false); btnCancel.addActionListener(this); //setVisible(true); } void buildConstraints(GridBagConstraints gbc, int gx, int gy, int gw, int gh, int wx, int wy) { gbc.fill = GridBagConstraints.HORIZONTAL; gbc.gridx = gx; gbc.gridy = gy; xxxii
- 33. gbc.gridwidth = gw; gbc.gridheight = gh; gbc.weightx = wx; gbc.weighty = wy; } void buildDlg(){ GridBagLayout gridbag = new GridBagLayout(); GridBagConstraints constraints = new GridBagConstraints(); constraints.anchor = GridBagConstraints.CENTER; setLayout(gridbag); prgBar = new JProgressBar(); prgBar.setSize(100,30); prgBar.setStringPainted(false); prgBar.setIndeterminate(true); btnCancel = new JButton("Cancel"); lblNote = new JLabel("hahah",JLabel.CENTER); constraints.insets = new Insets(3,3,3,3); buildConstraints(constraints,1,0,2,1,50,30); gridbag.setConstraints(lblNote ,constraints) ; add(lblNote); buildConstraints(constraints,0,1,4,1,100,40); gridbag.setConstraints(prgBar,constraints) ; add(prgBar); buildConstraints(constraints,1,2,2,1,50,30); constraints.fill = GridBagConstraints.NONE; gridbag.setConstraints(btnCancel ,constraints) ; add(btnCancel ); } void doWork(String inputFilename,String outputFilename,int mode,int algorithm){ String buf; File infile = new File(inputFilename); //chk if file exists if(!infile.exists()){ gSummary += "File Does not Exits!n"; return; } bCompress = (mode == COMPRESS); if(bCompress ) lblNote.setText("Compressing " + infile.getName()); else xxxiii
- 34. lblNote.setText("Decompressing " + infile.getName()); setTitle(lblNote.getText()); final int falgo = algorithm; iFilename = inputFilename; oFilename = outputFilename; gSummary = ""; //Create Thread for Compress/Decompress final Runnable closeRunner = new Runnable(){ public void run(){ setVisible(false); dispose(); } }; Runnable workingThread = new Runnable(){ public void run(){ try{ boolean success = false; switch(falgo){ case COMP_HUFFMAN : if(bCompress){ CHuffmanEncoder he = new CHuffmanEncoder(iFilename,oFilename); success = he.encodeFile(); gSummary += he.getSummary(); }else{ CHuffmanDecoder hde = new CHuffmanDecoder(iFilename,oFilename); success = hde.decodeFile(); gSummary += hde.getSummary(); } break; case COMP_GZIP : if(bCompress){ xxxiv
- 35. CGZipEncoder gze = new CGZipEncoder(iFilename,oFilename); success = gze.encodeFile(); gSummary += gze.getSummary(); }else{ CGZipDecoder gzde = new CGZipDecoder(iFilename,oFilename); success = gzde.decodeFile(); gSummary += gzde.getSummary(); } break; } }catch(Exception e){ gSummary += e.getMessage(); } try{ SwingUtilities.invokeAndWait(closeRunner ); }catch(Exception e){ gSummary += "n" + e.getMessage(); } } };//working thread Thread work = new Thread(workingThread); work.start(); setVisible(true); } public void actionPerformed(ActionEvent e) { //called only when cancel is pressed //Object obj = e.getSource(); dispose(); xxxv
- 36. } public String getSummary(){ if(gSummary.length() > 0){ String line = "----------------------------------------------"; return line + "n" + gSummary + line; }else return ""; } } HUFFMAN COMPRESSOR DECODER package eve; import java.io.*; import java.awt.*; import java.awt.event.*; import javax.swing.*; import javax.swing.border.*; //compression algorithms import eve.CHuffmanCompressor.*; import eve.CGZipCompressor.*; public class EveWorkingDlg extends JDialog implements ActionListener,EveGuiConstants{ private JFrame owner; private JProgressBar prgBar; private JButton btnCancel; private JLabel lblNote; private String gSummary = ""; private String iFilename,oFilename; private boolean bCompress = false; private int algoSelected; void centerWindow(){ Dimension screensize = Toolkit.getDefaultToolkit().getScreenSize(); setLocation((screensize.width / 2) - (getSize().width / 2), (screensize.height / 2) - (getSize().height / 2)); } EveWorkingDlg(JFrame parent){ super(parent,true); owner = parent; setDefaultCloseOperation(JDialog.DO_NOTHING_ON_CLOSE); addWindowListener(new WindowAdapter() { public void windowClosing(WindowEvent we) { xxxvi
- 37. //setTitle("Thwarted user attempt to close window."); } }); setSize(300,120); centerWindow(); buildDlg(); setResizable(false); btnCancel.addActionListener(this); //setVisible(true); } void buildConstraints(GridBagConstraints gbc, int gx, int gy, int gw, int gh, int wx, int wy) { gbc.fill = GridBagConstraints.HORIZONTAL; gbc.gridx = gx; gbc.gridy = gy; gbc.gridwidth = gw; gbc.gridheight = gh; gbc.weightx = wx; gbc.weighty = wy; } void buildDlg(){ GridBagLayout gridbag = new GridBagLayout(); GridBagConstraints constraints = new GridBagConstraints(); constraints.anchor = GridBagConstraints.CENTER; setLayout(gridbag); prgBar = new JProgressBar(); prgBar.setSize(100,30); prgBar.setStringPainted(false); prgBar.setIndeterminate(true); btnCancel = new JButton("Cancel"); lblNote = new JLabel("hahah",JLabel.CENTER); constraints.insets = new Insets(3,3,3,3); buildConstraints(constraints,1,0,2,1,50,30); gridbag.setConstraints(lblNote ,constraints) ; add(lblNote); buildConstraints(constraints,0,1,4,1,100,40); gridbag.setConstraints(prgBar,constraints) ; add(prgBar); buildConstraints(constraints,1,2,2,1,50,30); constraints.fill = GridBagConstraints.NONE; gridbag.setConstraints(btnCancel ,constraints) ; add(btnCancel ); xxxvii
- 38. } void doWork(String inputFilename,String outputFilename,int mode,int algorithm){ String buf; File infile = new File(inputFilename); //chk if file exists if(!infile.exists()){ gSummary += "File Does not Exits!n"; return; } bCompress = (mode == COMPRESS); if(bCompress ) lblNote.setText("Compressing " + infile.getName()); else lblNote.setText("Decompressing " + infile.getName()); setTitle(lblNote.getText()); final int falgo = algorithm; iFilename = inputFilename; oFilename = outputFilename; gSummary = ""; //Create Thread for Compress/Decompress final Runnable closeRunner = new Runnable(){ public void run(){ setVisible(false); dispose(); } }; Runnable workingThread = new Runnable(){ public void run(){ try{ boolean success = false; switch(falgo){ case COMP_HUFFMAN : if(bCompress){ CHuffmanEncoder he = new CHuffmanEncoder(iFilename,oFilename); success = he.encodeFile(); gSummary += he.getSummary(); }else{ CHuffmanDecoder hde = new CHuffmanDecoder(iFilename,oFilename); success = hde.decodeFile(); gSummary += hde.getSummary(); xxxviii
- 39. } break; case COMP_GZIP : if(bCompress){ CGZipEncoder gze = new CGZipEncoder(iFilename,oFilename); success = gze.encodeFile(); gSummary += gze.getSummary(); }else{ CGZipDecoder gzde = new CGZipDecoder(iFilename,oFilename); success = gzde.decodeFile(); gSummary += gzde.getSummary(); } break; } }catch(Exception e){ gSummary += e.getMessage(); } try{ SwingUtilities.invokeAndWait(closeRunner ); }catch(Exception e){ gSummary += "n" + e.getMessage(); } } };//working thread Thread work = new Thread(workingThread); work.start(); setVisible(true); } public void actionPerformed(ActionEvent e) { //called only when cancel is pressed //Object obj = e.getSource(); dispose(); } public String getSummary(){ if(gSummary.length() > 0){ String line = "----------------------------------------------"; xxxix
- 40. return line + "n" + gSummary + line; }else return ""; } } ENCODER package eve.CHuffmanCompressor; import java.io.*; import eve.FileBitIO.CFileBitWriter; public class CHuffmanEncoder implements huffmanSignature{ private String fileName,outputFilename; private HuffmanNode root = null; private long[] freq = new long[MAXCHARS]; private String[] hCodes = new String[MAXCHARS]; private int distinctChars = 0; private long fileLen=0,outputFilelen; private FileInputStream fin; private BufferedInputStream in; private String gSummary; void resetFrequency(){ for(int i=0;i<MAXCHARS;i++) freq[i] = 0; distinctChars = 0; fileLen=0; gSummary =""; } public CHuffmanEncoder(){ loadFile("",""); } public CHuffmanEncoder(String txt){ loadFile(txt); } public CHuffmanEncoder(String txt,String txt2){ loadFile(txt,txt2); } public void loadFile(String txt){ fileName = txt; outputFilename = txt + strExtension; resetFrequency(); } xl
- 41. public void loadFile(String txt,String txt2){ fileName = txt; outputFilename = txt2; resetFrequency(); } public boolean encodeFile() throws Exception{ if(fileName.length() == 0) return false; try{ fin = new FileInputStream(fileName); in = new BufferedInputStream(fin); }catch(Exception e){ throw e; } //Frequency Analysis try { fileLen = in.available(); if(fileLen == 0) throw new Exception("File is Empty!"); gSummary += ("Original File Size : "+ fileLen + "n"); long i=0; in.mark((int)fileLen); distinctChars = 0; while (i < fileLen) { int ch = in.read(); i++; if(freq[ch] == 0) distinctChars++; freq[ch]++; } in.reset(); } catch(IOException e) { throw e; //return false; } gSummary += ("Distinct Chars " + distinctChars + "n"); /* System.out.println("distinct Chars " + distinctChars); //debug for(int i=0;i<MAXCHARS;i++){ if(freq[i] > 0) System.out.println(i + ")" + (char)i + " : " + freq[i]); } */ xli
- 42. CPriorityQueue cpq = new CPriorityQueue (distinctChars+1); int count = 0 ; for(int i=0;i<MAXCHARS;i++){ if(freq[i] > 0){ count ++; //System.out.println("ch = " + (char)i + " : freq = " + freq[i]); HuffmanNode np = new HuffmanNode(freq[i],(char)i,null,null); cpq.Enqueue(np); } } //cpq.displayQ(); HuffmanNode low1,low2; while(cpq.totalNodes() > 1){ low1 = cpq.Dequeue(); low2 = cpq.Dequeue(); if(low1 == null || low2 == null) { throw new Exception("PQueue Error!"); } HuffmanNode intermediate = new HuffmanNode((low1.freq+low2.freq),(char)0,low1,low2); if(intermediate == null) { throw new Exception("Not Enough Memory!"); } cpq.Enqueue(intermediate); } //cpq.displayQ(); //root = new HuffmanNode(); root = cpq.Dequeue(); buildHuffmanCodes(root,""); for(int i=0;i<MAXCHARS;i++) hCodes[i] = ""; getHuffmanCodes(root); /* //debug for(int i=0;i<MAXCHARS;i++){ if(hCodes[i] != ""){ System.out.println(i + " : " + hCodes[i]); } } */ CFileBitWriter hFile = new CFileBitWriter(outputFilename); hFile.putString(hSignature); String buf; buf = leftPadder(Long.toString(fileLen,2),32); //fileLen hFile.putBits(buf); xlii
- 43. buf = leftPadder(Integer.toString(distinctChars-1,2),8); //No of Encoded Chars hFile.putBits(buf); for(int i=0;i<MAXCHARS;i++){ if(hCodes[i].length() != 0){ buf = leftPadder(Integer.toString(i,2),8); hFile.putBits(buf); buf = leftPadder(Integer.toString(hCodes[i].length(),2),5); hFile.putBits(buf); hFile.putBits(hCodes[i]); } } long lcount = 0; while(lcount < fileLen){ int ch = in.read(); hFile.putBits(hCodes[(int)ch]); lcount++; } hFile.closeFile(); outputFilelen = new File(outputFilename).length(); float cratio = (float)(((outputFilelen)*100)/(float)fileLen); gSummary += ("Compressed File Size : " + outputFilelen + "n"); gSummary += ("Compression Ratio : " + cratio + "%" + "n"); return true; } void buildHuffmanCodes(HuffmanNode parentNode,String parentCode){ parentNode.huffCode = parentCode; if(parentNode.left != null) buildHuffmanCodes(parentNode.left,parentCode + "0"); if(parentNode.right != null) buildHuffmanCodes(parentNode.right,parentCode + "1"); } void getHuffmanCodes(HuffmanNode parentNode){ if(parentNode == null) return; int asciiCode = (int)parentNode.ch; if(parentNode.left == null || parentNode.right == null) hCodes[asciiCode] = parentNode.huffCode; if(parentNode.left != null ) getHuffmanCodes(parentNode.left); if(parentNode.right != null ) getHuffmanCodes(parentNode.right); xliii
- 44. } String leftPadder(String txt,int n){ while(txt.length() < n ) txt = "0" + txt; return txt; } String rightPadder(String txt,int n){ while(txt.length() < n ) txt += "0"; return txt; } public String getSummary(){ return gSummary; } } GZIP COMPRESSOR DECODER package eve.CGZipCompressor; import java.io.*; import java.util.zip.*; public class CGZipDecoder{ private String fileName,outputFilename; private long fileLen,outputFilelen; private String gSummary; public CGZipDecoder(){ loadFile("",""); } public CGZipDecoder(String txt){ loadFile(txt); } public CGZipDecoder(String txt,String txt2){ loadFile(txt,txt2); } public void loadFile(String txt){ fileName = txt; outputFilename = stripExtension(txt,".gz"); xliv
- 45. gSummary = ""; } String stripExtension(String ff,String ext){ ff = ff.toLowerCase(); if(ff.endsWith(ext.toLowerCase())){ return ff.substring(0,ff.length()-ext.length()); } return ff + ".dat"; } public void loadFile(String txt,String txt2){ fileName = txt; outputFilename = txt2; gSummary = ""; } public boolean decodeFile()throws Exception{ try{ fileLen = new File(fileName).length(); GZIPInputStream gzipInputStream = new GZIPInputStream(new FileInputStream(fileName)); // Open the output file OutputStream out = new FileOutputStream(outputFilename); // Transfer bytes from the compressed file to the output file byte[] buf = new byte[1024]; int len; while ((len = gzipInputStream.read(buf)) > 0) { out.write(buf, 0, len); } // Close the file and stream gzipInputStream.close(); out.close(); outputFilelen = new File(outputFilename).length(); gSummary += ("Compressed File Size : "+ fileLen + "n"); gSummary += ("Original File Size : "+ outputFilelen + "n"); }catch(Exception e){throw e;} xlv
- 46. return true; } public String getSummary(){ return gSummary; } } ENCODER package eve.CGZipCompressor; import java.io.*; import java.util.zip.*; public class CGZipEncoder{ private String fileName,outputFilename; private long fileLen,outputFilelen; private String gSummary; public CGZipEncoder(){ loadFile("",""); } public CGZipEncoder(String txt){ loadFile(txt); } public CGZipEncoder(String txt,String txt2){ loadFile(txt,txt2); } public void loadFile(String txt){ fileName = txt; outputFilename = txt + ".gz"; gSummary = ""; } public void loadFile(String txt,String txt2){ fileName = txt; outputFilename = txt2; gSummary = ""; } public boolean encodeFile() throws Exception{ if(fileName.length() == 0) return false; try{ FileInputStream in = new FileInputStream(fileName); GZIPOutputStream out = new GZIPOutputStream(new FileOutputStream(outputFilename)); fileLen = in.available(); xlvi
- 47. if(fileLen == 0 ) throw new Exception("Source File Empty!"); gSummary += "Original Size : " + fileLen + "n"; byte[] buf = new byte[1024]; int len; while ((len = in.read(buf)) > 0) { out.write(buf, 0, len); } in.close(); out.finish(); out.close(); outputFilelen = new File(outputFilename).length(); float cratio = (float)(((outputFilelen)*100)/(float)fileLen); gSummary += ("Compressed File Size : " + outputFilelen + "n"); gSummary += ("Compression Ratio : " + cratio + "%" + "n"); }catch(Exception e){throw e; } return true; } public String getSummary(){ return gSummary; } } FILE BIT IO FILE BIT READER package eve.FileBitIO; import java.io.*; //File Bit Reader - Read Files BitWise public class CFileBitReader { private String fileName; private File inputFile; private FileInputStream fin; private BufferedInputStream in; xlvii
- 48. private String currentByte; public CFileBitReader() throws Exception{ try{ fileName = ""; //loadFile(fileName); }catch(Exception e){ throw e; } } public CFileBitReader(String txt) throws Exception{ try{ fileName = txt; loadFile(fileName); }catch(Exception e){ throw e; } } public boolean loadFile(String txt) throws Exception{ fileName = txt; try xlviii
- 49. { inputFile = new File(fileName); fin = new FileInputStream(inputFile); in = new BufferedInputStream(fin); currentByte = ""; return true; }catch(Exception e){ throw e; } //return true; } String leftPad8(String txt){ while(txt.length() < 8 ) txt = "0" + txt; return txt; } String rightPad8(String txt){ while(txt.length() < 8 ) txt += "0"; return txt; } public String getBit() throws Exception{ try{ xlix
- 50. if(currentByte.length() == 0 && in.available() >= 1){ int k = in.read(); currentByte = Integer.toString(k,2); currentByte = leftPad8(currentByte); } if(currentByte.length() > 0){ String ret = currentByte.substring(0,1); currentByte = currentByte.substring(1); return ret; } return ""; }catch(Exception e){throw e;} } public String getBits(int n) throws Exception{ try{ String ret = ""; for(int i=0;i<n;i++){ ret += getBit(); } return ret; }catch(Exception e){throw e;} } public String getBytes(int n) throws Exception{ try{ String ret = "",temp; l
- 51. for(int i=0;i<n;i++){ temp = getBits(8); char k = (char)Integer.parseInt(temp,2); ret += k; } return ret; }catch(Exception e){throw e;} } public boolean eof() throws Exception{ try{ return (in.available()== 0); }catch(Exception e){throw e;} } public long available() throws Exception{ try{ return in.available(); }catch(Exception e){throw e;} } public void closeFile() throws Exception{ try{ in.close(); }catch(Exception e){throw e;} li
- 52. }} FILE BIT WRITER package eve.FileBitIO; import java.io.*; //File Bit Writer - Write to Files BitWise public class CFileBitWriter { private String fileName; private File outputFile; private FileOutputStream fout; private BufferedOutputStream outf; private String currentByte; public CFileBitWriter() throws Exception{ try{ fileName = ""; //loadFile(fileName); }catch(Exception e){ throw e; } } public CFileBitWriter(String txt) throws Exception{ lii
- 53. try{ fileName = txt; loadFile(fileName); }catch(Exception e){ throw e; } } public boolean loadFile(String txt) throws Exception{ fileName = txt; try { outputFile = new File(fileName); fout = new FileOutputStream(outputFile); outf = new BufferedOutputStream(fout); currentByte = ""; return true; }catch(Exception e){ throw e; } //return true; } liii
- 54. public void putBit(int bit) throws Exception{ try{ bit = bit % 2; currentByte = currentByte + Integer.toString(bit); if(currentByte.length() >= 8){ int byteval = Integer.parseInt(currentByte.substring(0,8),2); outf.write(byteval); currentByte = ""; //reset } }catch(Exception e){throw e;} } public void putBits(String bits) throws Exception{ try{ while(bits.length() > 0){ int bit = Integer.parseInt(bits.substring(0,1)); putBit(bit); bits = bits.substring(1); } }catch(Exception e){throw e;} } liv
- 55. public void putString(String txt) throws Exception{ try{ while(txt.length() > 0){ String binstring = Integer.toString(txt.charAt(0),2); binstring = leftPad8(binstring ); putBits(binstring); txt = txt.substring(1); } }catch(Exception e){throw e;} } String leftPad8(String txt){ while(txt.length() < 8 ) txt = "0" + txt; return txt; } String rightPad8(String txt){ while(txt.length() < 8 ) txt += "0"; return txt; } public void closeFile() throws Exception{ lv
- 56. try{ //check if incomplete byte exists while(currentByte.length() > 0){ putBit(1); } outf.close(); }catch(Exception e){ throw e;} } } 7.8.2 SOFTWARE INTEGRATION & VERIFICATION: Each unit is developed independently and can be tested for its functionality. This is the so called Unit Testing. It simply verifies if the modules or units to check if they lvi
- 57. meet their specifications. This involves functional tests at the interfaces of the modules, but also more detailed tests which consider the inner structure of the software modules. During integration the units which are developed and tested for their functionalities are brought together. The modules are integrated into a complete system and tested to check if all modules cooperate as expected. 7.8.3 SYSTEM VERIFICATION: After successfully integration including the related tests the complete system has to be tested against its initial requirements. This will include the original hardware and environment, whereas the previous integration and testing phase may still be performed in a different environment or on a test bench . 7.8.4 OPERATION & MAINTENANCE: The system is handed over to the customer and will be used the first time by him. Naturally the customer will check if his requirements were implemented as expected but he will also validate if the correct requirements have been set up in the beginning. In case there are changes necessary it has to be fixed to make the system usable or to make it comply with the customer wishes. In most of the "Waterfall Model" descriptions this phase is extended to a never ending phase of "Operations & Maintenance". All the problems which did not arise during the previous phases will be solved in this last phase . 7.9 DESIGN STRATEGY: A good system design strategy is to organize the program modules in such a way that are easy to develop and later to, change. Structured design techniques help developers to deal with the size and complexity of programs. Analysts create instructions for the developers about how code should be written and how pieces of code should fit together to form a program. It is important for two reasons: First, even pre-existing code, if any, needs to be understood, organized and pieced together. Second, it is still common for the product team to have to write some code and produce original programs that support the application logic of the system. There are two main design strategies: Top-down and Bottom-up strategies. 7.9.1 BOTTOM-UP lvii
- 58. In our project we follow bottom up design strategy because we are aware of the modules of our project and we decide how to combine these modules to provide larger ones; to combine those to even larger ones, and so on, till we arrive at one big module which is the whole of the desired program. In a bottom-up approach the individual base elements of the system are first specified in great detail. These elements are then linked together to form larger subsystems, which then in turn are linked, sometimes in many levels, until a complete top-level system is formed. This strategy often resembles a "seed" model, whereby the beginnings are small, but eventually grow in complexity and completeness. 7.9.2 OBJECT ORIENTED DESIGN Object oriented design is the result of focusing attention not on the function performed by the program but instead on the data that are to be manipulated by the program. We use java technology as the base technology for our project which follows principles of OOPS (Object-oriented programming system).Object-oriented programming (OOP) is a programming paradigm that uses "objects" to design applications and computer programs. Object Oriented Design is not dependent on any specific implementation language. Problems are modeled using objects. Objects have: Behavior (they do things) State ( which changes when they do things ) 7.9 DATA FLOW DIAGRAM Data flow oriented techniques advocate that the major data items handled by a system must be first identified and then the processing required on these data items to produce the desired outputs should be determined. The DFD (also called as bubble chart) is a simple graphical formalism that can be used to represent a system in terms of input data to the system, various processing carried out on these data, and the output generated by the system. It was introduced by De Macro (1978), Gane and Sarson (1979).The primitive symbols used for constructing DFD’s are: Symbols used in DFD lviii
- 59. A circle represents a process. A rectangle represents external entity A square defines a source or destination of the system data. An arrow identifies dataflow. 7.10.1 Context Level Diagram Context Diagram File zip by Compress Files Administrator Huffman Decompress algorithm Files Level 1 DFD Administrator lix
- 60. lx
- 61. Use Case Diagram Administrator Login Compress/Dec Login details for ompress Login verification and Files/Folders validation Search for Manage Files/Folders ment View files in compressed folder Set Icons and Extensions lxi
- 62. FLOW CHART 73 lxii
- 63. lxiii
- 64. CHAPTER 8 TESTING 8.1 WHAT IS TESTING? Software testing is a specialized discipline in the process of software development. Testing is the process of demonstrating that errors are not present. The purpose of testing is to show that a program performs its intended functions correctly. Testing is the process of establishing confidence that a program does what it is supposed to do. Levels of Testing There are three levels of testing: Unit Testing Unit testing is the process of taking a module and running it in isolation from the rest of the software product by using prepared test cases and comparing actual results with the results predicted by the specifications and design of the Module. As we use waterfall model for designing our software thus we perform unit testing side by side after coding every individual module. Integration Testing We perform integration testing using bottom up integration and we get positive Results in test. System Testing This type of testing is done when the system is ready to execute with full functionality. Acceptance Testing This type of testing covers all the test cases applied by the customer and comprises of two main parts 1. Alpha Testing 2. Beta Testing lxiv
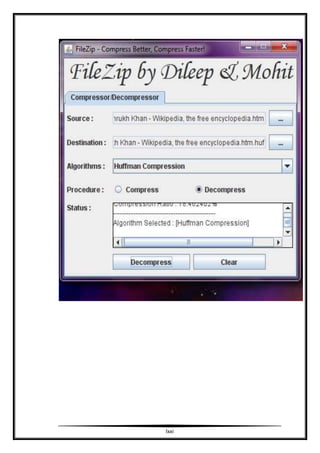
- 65. Functional Testing Functional testing also known as black box testing is performed on our project. Here we test the functionality of our program. In functional testing we observe the output for certain input values and it produces positive results. SCREEN SHOTS lxv
- 66. lxvi
- 67. lxvii
- 68. lxviii
- 69. lxix
- 70. lxx
- 71. lxxi
- 72. CHAPTER 10 CONCLUSION The project FileZip is completed, satisfying the required design specifications. The system provides a user-friendly interface. The software is developed with modular approach. All modules in the system have been tested with valid data and invalid data and everything work successfully. Thus the system has fulfilled all the objectives identified and is able to replace the existing system. The constraints are met and overcome successfully. The system is designed as like it was decided in the design phase. The system is very user friendly and will reduce time consumption. This software has a user-friendly screen that enables the user to use without any inconvenience. The user need not depend on third party software’s like winzip, winrar, Stuff etc. The software can be used to compress files and they can be decompressed when the need arises. The application has been tested with live data and has provided a successful result. Hence the software has proved to work efficiently. lxxii
- 73. REFERENCES javatpoint.com—(by M.R Sonu Jaiswal) http://www.gzip.org/algorithm.txt Herhert Schildt --The Complete Reference Java2 (Fifth Edition) E. Balaguruswamy—Core Java Jim Farely $ William Crawford—Java Enterprise (Third edition) lxxiii
- 74. lxxiv