Protect your private data with ORC column encryption
Download as PPTX, PDF1 like1,116 views

The document discusses ORC column encryption as a means to protect private data within Hadoop environments. It covers the importance of secure authentication, fine-grained authorization, and various encryption practices that cater to data in motion, at rest, and during access. The presentation also highlights tools and strategies for implementing effective data protection while maintaining compatibility with existing systems and users.


































Protect your private data with ORC column encryption
- 1. PROTECT YOUR PRIVATE DATA WITH ORC COLUMN ENCRYPTION Owen O’Malley [email protected] September 2019 @owen_omalley
- 2. © 2019 Cloudera, Inc. All rights reserved. 2 WHO AM I? • First committer added to Hadoop MapReduce Scaling Security • Hive ACID transactions • ORC Creator
- 3. SECURITY AND DATA PROTECTION IN HADOOP
- 4. © 2019 Cloudera, Inc. All rights reserved. 4 EXAMPLE DATA LAKE SCENARIO Marketing Demographics Electronic medical records CRM POS (Structured)(Structured) (Structured) (Structured) (Structured) Cluster 1: Dublin Cluster 2: San Francisco (Unstructured)(Unstructured)(Unstructured) Cluster 3: Prague (Structured) On Premise Data Lakes (Unstructured)(Structured) (Unstructured) (Structured) Cloud Data Lakes Social Weblogs & Feeds Transactional Mobile IoT Personal Data
- 5. © 2019 Cloudera, Inc. All rights reserved. 5 DIFFERENCES IN THE BIG DATA CONTEXT • Breaking down silos: fantastic for analytics, but security challenges Centralized data lake with multi-tenancy requires secure (and easy) authentication and fine-grained authorization • Data democratization and the Data Scientist role (often a data super user with elevated privileges) • Data is maintained over a long duration • Cloud and Hybrid architectures spanning data center and (multiple) public clouds further broaden the attack surface area and present novel authentication and authorization challenges • Along with adherence to security fundamentals and defense in-depth, a data-centric approach to security becomes critical
- 6. Watch Towers Limited Entry Points Moat Kerberos Securing your data lake High Hard Walls Check Identity Inner Walls Firewall Encryption, TLS, Key Trustee, Navigator Encrypt, Ranger KMS LDAP/AD Apache Knox: AuthN, API Gateway, Proxy, SSO Apache Ranger : ABAC AuthZ, Audits, Anonymization Apache Metron: Detection
- 7. © 2019 Cloudera, Inc. All rights reserved. 7 DATA PROTECTION IN HADOOP • Must be applied in three different levels Storage – encrypt data at rest • HDFS encryption zones • Volume encryption Transmission – encrypt data in motion • SSL Upon access – apply restrictions when accessed • Ranger dynamic masking and row filtering
- 8. Dynamic Row Filtering & Column Masking WithApache Ranger &Apache Hive User 2: Ivanna Location : EU Group: HR User 1: Joe Location : US Group: Analyst Original Query: SELECT country, nationalid, ccnumber, mrn, name FROM ww_customers Country National ID CC No DOB MRN Name Policy ID US 232323233 4539067047629850 9/12/1969 8233054331 John Doe nj23j424 US 333287465 5391304868205600 8/13/1979 3736885376 Jane Doe cadsd984 Germany T22000129 4532786256545550 3/5/1963 876452830A Ernie Schwarz KK-2345909 Country National ID CC No MRN Name US xxxxx3233 4539 xxxx xxxx xxxx null John Doe US xxxxx7465 5391 xxxx xxxx xxxx null Jane Doe Ranger Policy Enforcement Query Rewritten based on Dynamic Ranger Policies: Filter rows by region & apply relevant column masking Users from US Analyst group see data for US persons with CC and National ID (SSN) as masked values and MRN is nullified Country National ID Name MRN Germany T22000129 Ernie Schwarz 876452830A EU HR Policy Admins can see unmasked but are restricted by row filtering policies to see data for EU persons only Original Query: SELECT country, nationalid, name, mrn FROM ww_customers Analysts HR Marketing Ranger
- 9. WHAT ARE WE FIXING?
- 10. © 2019 Cloudera, Inc. All rights reserved. 10 FRAMING THE PROBLEM… • Related data, different security requirements • Authorization – who can see it • Audit – track who read it • Encrypt on disk – regulatory • File-level (or blob) granularity isn’t enough • File systems don’t understand columns
- 11. © 2019 Cloudera, Inc. All rights reserved. 11 REQUIREMENTS • Readers should transparently decrypt data If and only if the user has access to the key The data must be decrypted locally Old readers must not break! • Columns are only decrypted as necessary • Master keys must be managed securely Support for Key Management Server & hardware Support for key rolling
- 13. © 2019 Cloudera, Inc. All rights reserved. 13 PARTIAL SOLUTION – HDFS ENCRYPTION ZONES • Transparent HDFS Encryption • Encryption zones • HDFS directory trees • Unique master key for each zone • Client decrypts data • Key Management via KeyProvider API
- 14. © 2019 Cloudera, Inc. All rights reserved. 14 HDFS ENCRYPTION ZONE LIMITATIONS • Very coarse protection • Only entire directory subtrees • No ability to protect columns • A lot of users need access to keys • Moves between zones is painful • When writing with Hive, data is moved multiple times per a query
- 15. © 2019 Cloudera, Inc. All rights reserved. 15 PARTIAL SOLUTION – HIVE SERVER 2 • Limit access to warehouse data to Hive • Only “hive” user has HDFS access • Breaks Hadoop’s multi-paradigm data access • Many customers use both Hive & Spark • JDBC isn’t a distributed protocol • Funneling large data through a small pipe • Spark Data Warehouse Connector to LLAP fixes this
- 16. © 2019 Cloudera, Inc. All rights reserved. 16 PARTIAL SOLUTION – SEPARATE TABLES • Split private information out of tables • Separate directories in HDFS • HDFS and/or HS2 authorization • Enables HDFS encryption • Limitations • Need to join with other tables • Higher operational overhead
- 17. © 2019 Cloudera, Inc. All rights reserved. 17 PARTIAL SOLUTION – ENCRYPTION UDF • Hive has user defined functions • aes_encrypt and aes_decrypt • Limitations • Key management is problematic • Encryption is not seeded • Size of value leaks information
- 18. THE WINNER IS …
- 19. © 2019 Cloudera, Inc. All rights reserved. 19 COLUMNAR ENCRYPTION • Columnar file formats, such as ORC and Parquet • Write data in columns • Column projection • Better compression • Encryption works really well • Only encrypt bytes for column • Can store multiple variants of data
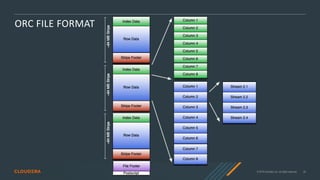
- 20. © 2019 Cloudera, Inc. All rights reserved. 20 ORC FILE FORMAT
- 21. © 2019 Cloudera, Inc. All rights reserved. 21 USER EXPERIENCE • Set table properties for encryption • orc.encrypt = ”pii:ssn,email;credit:card_info” • orc.mask = “sha256:card_info” • Define where to get the encryption keys • Configuration defines the key provider via URI
- 22. © 2019 Cloudera, Inc. All rights reserved. 22 KEY MANAGEMENT • Create a master key for each use case • “pii”, “pci”, or “hipaa” • Each column in each file uses unique local key • Allows audit of which users read which files • Ranger policies limit access to keys • Who, What, When, Where
- 23. © 2019 Cloudera, Inc. All rights reserved. 23 KEY PROVIDER API • Provides limited access to encryption keys • Encrypts or decrypts local keys • Users are never given master keys • Key versions and key rolling of master keys • Allows 3rd party plugins • Supports Cloud, Hadoop or Ranger KMS
- 24. © 2019 Cloudera, Inc. All rights reserved. 24 ENCRYPTION DATA FLOW
- 25. © 2019 Cloudera, Inc. All rights reserved. 25 ENCRYPTION FLOW • Local key • Random for each encrypted column in file • Encrypted w/ master key by KMS • Encrypted local key is stored in file metadata • IV is generated to be unique • Column, kind, stripe, & counter
- 26. © 2019 Cloudera, Inc. All rights reserved. 26 STATIC DATA MASKING • What happens without key access? • Define static masks • Nullify – all values become null • Redact – mask values ‘Xxxxx Xxxxx!’ • Can define ranges to unmask • SHA256 – replace with SHA256 • Custom - user defined
- 27. © 2019 Cloudera, Inc. All rights reserved. 27 DATA ANONYMIZATION • Anonymization is hard! • AOL search logs • Netflix prize datasets • NYC taxi dataset • Always evaluate security tradeoffs • Tokenization is a useful technique • Assigns arbitrary replacements
- 28. © 2019 Cloudera, Inc. All rights reserved. 28 KEY DISPOSAL • Often need to keep data for 90 days • Currently the data is written twice • With column encryption: • Roll keys daily • Delete master key after 90 days
- 29. © 2019 Cloudera, Inc. All rights reserved. 29 ORC ENCRYPTION DESIGN • Write both variants of streams • Masked unencrypted • Unmasked encrypted • Encrypt both data and statistics • Maintain compatibility for old readers • Read unencrypted variant • Preserve ability to seek in file
- 30. © 2019 Cloudera, Inc. All rights reserved. 30 ORC WRITE PIPELINE • Streams go through pipeline • Run length encoding • Compression (zlib, snappy, lzo, lz4, zstd, or none) • Encryption • Encryption is AES/CTR • Allows seek • No padding
- 31. CONCLUSIONS
- 32. © 2019 Cloudera, Inc. All rights reserved. 32 CONCLUSIONS • ORC column encryptions provides Transparent encryption Multi-paradigm column security Compatible with old readers Static masking Audit logging (via KMS logging) • Supports file merging • Released in ORC 1.6
- 33. © 2019 Cloudera, Inc. All rights reserved. 33 INTEGRATION WITH OTHER TOOLS • Hive & Spark No change other than defining table properties • Apache Hive’s LLAP Cache and fast processing of SQL queries Column encryption changes internal interfaces Cache both encrypted and unencrypted variants Ensure audit log reflects end-user and what they accessed
- 34. © 2019 Cloudera, Inc. All rights reserved. 34 LIMITATIONS • Need encryption policy for write Current Atlas & Ranger tags lag data Auto-discovery requires pre-access • Changes to masking policy Need to re-write files • Need additional data masks Credit card, addresses, etc. • Decrypted local keys could be saved