July 2014 HUG : Pushing the limits of Realtime Analytics using Druid
Download as PPTX, PDF33 likes10,778 views

1) The presentation discusses Druid, an open source analytics engine that can perform aggregations on memory mapped data in sub-second time. 2) It describes how Druid fits into their software stack at the API layer and how they extend its capabilities through a SQL interface and addressing limitations like limited querying and missing features like distinct counts. 3) Examples of SQL queries against Druid are shown to demonstrate its capabilities like group by, filtering, joins, and handling of timeseries data.























July 2014 HUG : Pushing the limits of Realtime Analytics using Druid
- 1. Yahoo! Presentation, Confidential 16 July 2014 July 16, 2014 Pushing the limits of Realtime analytics with Druid Reza Iranmanesh Srikalyan Chandrashekar By realtime we mean subsecond response, highly concurrent and realtime ingestion too
- 2. Yahoo! Presentation, Confidential 16 July 2014 Agenda 1. What is Druid ? 2. Fitting Druid into our Software Stack; Druid in the API layer 3. The SQL 4 Druid suite (compiler, driver and client). 4. Contrast with traditional RDBMS SQL. 5. Features of SQL 4 Druid suite. 6. Current state. 7. Demo. 8. Future plans.
- 3. Yahoo! Presentation, Confidential 16 July 2014 What is Analytics? Analytics The process of accessing, cleaning, transforming and modeling data with the goal of discovering information. Business Intelligence analytics focused on business information. Star Schema Data Cubes / OLAP Systems
- 4. Yahoo! Presentation, Confidential 16 July 2014 What is Druid? - A google dremel inspired, open source OLAP-like engine that can do aggregate operations in sub second (most of them) on memory mapped data. - de-normalized data - Time-based segments - Timeseries/GroupBy/TopN - Plays well with Hadoop
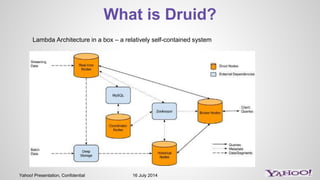
- 5. Yahoo! Presentation, Confidential 16 July 2014 What is Druid? Lambda Architecture in a box – a relatively self-contained system
- 6. Yahoo! Presentation, Confidential 16 July 2014 Main Components Indexing Service • Realtime ingestion • Hadoop batch ingestion • Local batch ingestion • Aggregates are defined at indexing stage • Final output: segments of data that will eventually live on deep store. Each segment holds a timerange of data. Coordinator Node • The Coordinator! Takes care of reading metadata from MySQL and looking at zookeeper to see who’s there and putting segment distribution information for Historicals to pick, etc. Broker Node • Forwards the queries to the nodes who have the segments that fall into the given time interval • Takes care of aggregating the partial aggregates from historical nodes Historical Node • Loads segments of immutable indexed data that live on the deep store (usually Grid) • Each historical node Realtime Node
- 7. Yahoo! Presentation, Confidential 16 July 2014 Why Druid? Pros: • Horizontal Scalability with linear performance gains • Sub-second response time for most use cases • Native time zone support • Relatively self-contained (batch + real-time ingestion/query support, distributed memcached support, multi-tier replication/load support) • Active and responsive community Cons: • Limited query power compared with SQL/MDX • Lack of joins • Missing distinct count • Memory bounds for GroupBy Query
- 8. Yahoo! Presentation, Confidential 16 July 2014 Horizontal Scalability
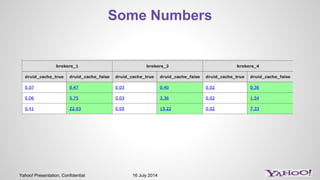
- 9. Yahoo! Presentation, Confidential 16 July 2014 Some Numbers
- 10. Yahoo! Presentation, Confidential 16 July 2014 Some Numbers
- 11. Yahoo! Presentation, Confidential 16 July 2014 Druid in our API Layer Limitation Solution groupBy memory bounded - Replace with TopN - Not a real limit in Analytics world Limited Query power - Extend Druid’s limits - Some extra work in the API layer - Implement a SQL layer Missing exact Distinct Count - Use HyperLogLog implementation - Create pre-aggregates on the grid when we need exact values; create a multiplexer on the API side The problem of mutable dimension data; supporting star schema - Query pipeline in the API layer Missing joins - SQL layer
- 12. Yahoo! Presentation, Confidential 16 July 2014 Grid RDBMS Druid Druid in our API Layer Star Schema Solving the problem of mutable dimension tables with a Druid query pipeline and one-to-one joins: filter on pre-aggregates / join on post-aggregates - uuid - name - url - uuid - name - url - views - clicks First Druid groupby First result as input to the next Query Select sum(uuid), .. From … Join … Where … API
- 13. Yahoo! Presentation, Confidential 16 July 2014 Druid in our API Layer Unique Counts Unique_count_1_hour Unique_count_7_day Unique_count_24_hour Unique_count_14_day Unique_count_30_day use hyperLogLog aggregate What is the granularity? hour? day? all? Hybrid approach to take care of distinct counts:
- 14. Yahoo! Presentation, Confidential 16 July 2014 SQL 4 Druid suite 1. JDBC driver 2. Command line client the driver is powered by the DCompiler.
- 15. Yahoo! Presentation, Confidential 16 July 2014 Demo
- 16. Yahoo! Presentation, Confidential 16 July 2014 Sql features 1. GroupBy, Having clause supported. 2. Post aggregation including javascript functions accepted. 3. Order BY and LIMIT which essentially is Top N. 4. Where clause translates into filters. 5. Aggregators: count, double_sum, long_sum, unique, max, min etc. 6. BREAK BY translates into granularity. 7. HINT timeseries if dimension is timestamp.
- 17. Yahoo! Presentation, Confidential 16 July 2014 Sql features continued 8. Specify micro and adhoc interval ranges. 9. Select-type query(no aggregation) just plain dimension (and/or) metrics retrieval.
- 18. Yahoo! Presentation, Confidential 16 July 2014 Sample SQLs
- 19. Yahoo! Presentation, Confidential 16 July 2014 Driver features. 1. Can do JOIN(Inner, Left and Right), can go only two level deep right now. 2. Template parameters.
- 20. Yahoo! Presentation, Confidential 16 July 2014 Driver features continued. 3. Map data to list . 4. Map data to bean. 5. Dynamic column type inference on select queries(Ex: dimension/metric is found from Coordinator)
- 21. Yahoo! Presentation, Confidential 16 July 2014 Client Features. 1. GroupBy,TS and TopN, search queries. 2. Generate Bean source code based on previous SQL executed. 3. See all tables(data sources), schema of table etc. 4. Navigate through command history. 5. MySQL like pretty print.
- 22. Yahoo! Presentation, Confidential 16 July 2014 We Are Hiring [email protected] [email protected] Contact us:
- 23. Yahoo! Presentation, Confidential 16 July 2014 Appendix A Timeseries with adhoc interval spec
- 24. Yahoo! Presentation, Confidential 16 July 2014 Appendix B Select Query on dimensions and metrics
- 25. Yahoo! Presentation, Confidential 16 July 2014 Appendix C GroupBy With Join