[系列活動] Python 爬蟲實戰
56 likes13,391 views

本文件介绍了Python爬虫实战课程的内容和安排,包括基础的HTML知识、爬虫的工作原理以及如何使用requests和BeautifulSoup库进行网页数据抓取和解析。课程还涵盖了正则表达式和数据分析工具的使用。学员将通过实际编码练习,学习如何创建自己的爬虫程序。










































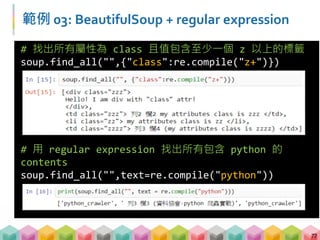
![讓 BeautifulSoup 更好喝的函數 ‐ find_all()
一個 tag 不夠,想找多個怎麼辦?
find_all() 可以幫上忙
用法跟 find() 一樣,但是回傳的是 Python 的 list
43
[ , , ... ]](https://image.slidesharecdn.com/pythonafunjimv1-171213041823/85/Python-43-320.jpg)


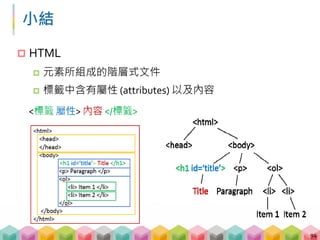
![範例 01: BeautifulSoup 的常用函數
46
# 不指定標籤,但找出所有屬性 class = "zzz" 的標籤
print(soup.find_all("", {"class":"zzz"}))
# 找出所有 td 標籤的第三個並找出其中的 a 標籤
print(soup.find_all("td")[2].find("a"))](https://image.slidesharecdn.com/pythonafunjimv1-171213041823/85/Python-46-320.jpg)
![範例 01: BeautifulSoup 的常用函數
47
# 找出所有內容等於 python_crawler 的文字
print(soup.find_all(text="python_crawler"))
# 找出第一個 a 標籤並印出屬性
print(soup.find("a").attrs)
print(soup.find("a")["href"])](https://image.slidesharecdn.com/pythonafunjimv1-171213041823/85/Python-47-320.jpg)

![練習 01: 答案
49
# 找出所有 td 標籤,並用 len 計算長度
print(len(soup.find_all("td")))
# 找到 div 標籤,屬性 id = "id1",再印出其內容
print(soup.find("div", id="id1").text)
# 透過觀察網頁可以發現 列3欄3 有個 id = hyperlink 可
以幫助我們定位這個 tag,再把 tag 的 href 找出來
print(soup.find("a", {"id":"hyperlink"})["href"])
8](https://image.slidesharecdn.com/pythonafunjimv1-171213041823/85/Python-49-320.jpg)


![BeautifulSoup 的調味料: 正則表達式
甚麼是 regular expression?
[A‐Za‐z0‐9._]+@[A‐Za‐z.]+.(com|edu)+.tw
別害怕! 我們一步一步來
52](https://image.slidesharecdn.com/pythonafunjimv1-171213041823/85/Python-52-320.jpg)

![regular expression 常用符號
54
符號 意義 範例 符合範例的字串
* 前一字元或括號內字元出現
0次或多次
a*b* aaaab、aabb、
bbb
+ 前一字元或括號內字元出現
1次或多次
a+b+ aaabb、abbbb、
abbbbb
{m,n} 前一字元或括號內字元出現
m次到 n 次 (包含 m, n)
a{1,2}b{3,4} abbb、aabbbb、
aabbb
[] 符合括號內的任一字元 [A‐Z]+ APPLE、QWER
跳脫字元 .| .|
. 符合任何單一字元
(符號, 數字, 空格)
a.c auc、abc、a c
regular expression 使用許多符號來訂定搜尋規則,
要學會使用就必須知道符號的意義](https://image.slidesharecdn.com/pythonafunjimv1-171213041823/85/Python-54-320.jpg)



![範例 02‐2: 找到數字
[ ] 代表的意思是這個字元可以是括號內的任何一個
[0‐9] 代表可以是 0~9 之間的任意數字
[a‐z] 代表可以是 a~z 之間的任意文字
58](https://image.slidesharecdn.com/pythonafunjimv1-171213041823/85/Python-58-320.jpg)
![練習 02‐2: 答案
59
[0‐9]+
符合 0‐9 任一數字,且須出現一次以上
[1‐3]+
符合 1‐3 任一數字,且須出現一次以上
123
符合 123 的字元](https://image.slidesharecdn.com/pythonafunjimv1-171213041823/85/Python-59-320.jpg)
![範例 02‐3: 找到文字
當有指定的文字需要搜尋,可透過 [ ] 搭配 *, + , {}
進行搜尋
60](https://image.slidesharecdn.com/pythonafunjimv1-171213041823/85/Python-60-320.jpg)
![練習 02‐3: 答案
61
[A‐Z]+[a‐z]
前兩個字元要是 A‐Z 其中一個,且出現一次以上
最後一個字元要是 a‐z 其中一個](https://image.slidesharecdn.com/pythonafunjimv1-171213041823/85/Python-61-320.jpg)

![練習 02‐4: 答案
63
[A‐Z]+[a‐z]
第一個字元要是 A‐Z 其中一個
第二個字元要是 + 號
第三個字元要是 a‐z 其中一個](https://image.slidesharecdn.com/pythonafunjimv1-171213041823/85/Python-63-320.jpg)


![Email 的 regular expression (1/2)
[A‐Za‐z0‐9._]+@[A‐Za‐z.]+(com|edu).tw
[A‐Za‐z0‐9._]+@
大小寫英文、數字、點、底線,可出現一次以上,
且加上 @
66](https://image.slidesharecdn.com/pythonafunjimv1-171213041823/85/Python-66-320.jpg)
![Email 的 regular expression (2/2)
[A‐Za‐z0‐9._]+@[A‐Za‐z.]+(com|edu).tw
[A‐Za‐z.]+(com|edu).tw
大小寫英文、點,可出現一次以上,且結尾須為 com 或
edu 再加上 .tw,
67](https://image.slidesharecdn.com/pythonafunjimv1-171213041823/85/Python-67-320.jpg)
![甚麼是 regular expression?
再看一次!
[A‐Za‐z0‐9._]+@[A‐Za‐z.]+.(com|edu)+.tw
68
EASY](https://image.slidesharecdn.com/pythonafunjimv1-171213041823/85/Python-68-320.jpg)
![練習 02: regular expression (10 mins)
請觀察 518 黃頁網,並找出所有店家的電話號碼
(包含分機)
請透過開發者工具,觀察目標資訊藏在那些標籤底下?
標籤內有甚麼特別的屬性可以讓我們找到嗎?
怎麼把包含電話號碼的 list 合併成一個大的 test_string?
69
# 非常實用的 for loop 寫法,當你使用 find_all 後,
想一口氣把 list 裡面所有 tags 的內容文字取出時,
可以這樣寫
[tag.text for tag in soup.find_all("tag")]](https://image.slidesharecdn.com/pythonafunjimv1-171213041823/85/Python-69-320.jpg)
![練習 02: 答案
70
# 用 requests 抓取網頁並存在 response
# 用 BeautifulSoup 解析 HTML 並把結果回傳 soup
response = requests.get("
https://jimmy15923.github.io/518")
soup = BeautifulSoup(response.text,"lxml")
# 抓到所有 li 標籤,且屬性 class=comp_tel,並存在 list 裡
all_phone_text = [tag.text for tag in
soup.find_all("li", {"class":"comp_tel"})]
# 將 list 的所有文字,存為一個 string
all_phone_text = "".join(all_phone_text)
# 用 regular expression 找出所有電話號碼
phone_number = re.findall("0[1‐9]‐[0‐9]+",
all_phone_text)](https://image.slidesharecdn.com/pythonafunjimv1-171213041823/85/Python-70-320.jpg)




































![jieba 登場!
把每一條評論斷完詞後,我們就可以得到每條評論
都用了哪些詞 (e.g., 好看、爛片、無聊)
再運用統計的方式,計算一下五星評論與一星評論
之間的用詞頻率是否有所不同
109
# 載入套件
import jieba
# 把"我覺得可以"作斷詞後
print([x for x in jieba.cut("我覺得不行")])](https://image.slidesharecdn.com/pythonafunjimv1-171213041823/85/Python-109-320.jpg)






![Linear Regression on Scikit‐Learn
116
# 切 training data 跟 testing data
X_train,X_test,y_train,y_test = train_test_split(
movie_box["平均星等"], np.log10(movie_box["平均票房"]))
# 建立 Regression 模型
reg = LinearRegression()
# 放入 training data 進行訓練
reg.fit(X_train, y_train)
# 用 testing data 做預測
y_pred = reg.predict(X_test)
# 算出 testing data 與預測結果的相關係數
print(pearsonr(y_pred, y_test)) 0.21](https://image.slidesharecdn.com/pythonafunjimv1-171213041823/85/Python-116-320.jpg)



![Decision Tree on Scikit‐Learn
120
# 切 training data 跟 testing data
X_train,X_test,y_train,y_test = train_test_split(
movie_box[["評論數量", "平均星等", "映期"]], movie_box["平均
票房"])
# 建立 Decision Tree 模型
clf = DecisionTreeClassifier(max_depth=3)
# 放入 training data 進行訓練
clf.fit(X_train, y_train)
# 用 testing data 做預測
y_pred = reg.predict(X_test)
# 算出 testing data 與預測結果的準確率
print(accuracy_score(y_pred, y_test))
0.84](https://image.slidesharecdn.com/pythonafunjimv1-171213041823/85/Python-120-320.jpg)












![133
範例 05: 將高鐵時刻表的結果存成 CSV ‐
by columns
# 找出所有 td 標籤 屬性 class=column1 的內容,並存成 list
train_number = [tag.text for tag in
soup_post.find_all("td", class_="column1")]
# 找出所有 td 標籤 屬性 class=column3 的內容,並存成 list
departure = [tag.text for tag in
soup_post.find_all("td", class_="column3")]
# 找出所有 td 標籤 屬性 class=column4 的內容,並存成 list
arrival = [tag.text for tag in
soup_post.find_all("td", class_="column4")]
# 找出所有 td 標籤 屬性 class=column2 的內容,並存成 list
travel_time = [tag.text for tag in
soup_post.find_all("td", class_="column2")]](https://image.slidesharecdn.com/pythonafunjimv1-171213041823/85/Python-133-320.jpg)
![範例 05: 將高鐵時刻表的結果存成 CSV ‐
by columns
134
# 建立 DataFrame,把 dictionary 放入,並指定 columns 順序
highway_df = pd.DataFrame(
{"車次":train_number,
"出發時間":departure,
"抵達時間":arrival,
"行車時間":travel_time},
columns = ["車次", "出發時間", "抵達時間", "行車時間"])](https://image.slidesharecdn.com/pythonafunjimv1-171213041823/85/Python-134-320.jpg)
![範例 05: 將高鐵時刻表的結果存成 CSV ‐
by rows
135
# 先建立 DataFrame,確定 columns
highway_df = pd.DataFrame(columns = ["車次","出發時間",
"抵達時間", "行車時間"])
# loop 3 次,每次取出一個 row 的 3 個值並存入 DataFrame
for i in range(3):
row = soup_post.find_all("table", class_=
"touch_table")[i]
row_contents = [tag.text for tag in row.find_all("td",
class_= re.compile("column"))]
highway_df.loc[i] = row_contents](https://image.slidesharecdn.com/pythonafunjimv1-171213041823/85/Python-135-320.jpg)


![練習 05: 答案
138
# 萬年起手式
response = requests.get("http://yp.518.com.tw/service‐
life.html?ctf=10")
soup = BeautifulSoup(response.text, "lxml")
# 店家名稱與電話存在同一標籤,地址則在另一標籤
name_phone = [tag.text for tag in soup.find_all("li",
class_="comp_tel")]
address = [tag.text for tag in soup.find_all("li",
class_="comp_loca")]
# 運用 re 找到所有的電話號碼,運用 split,抓到店家名稱
name_phone_str = "".join(name_phone)
phone = re.findall("[0‐9]{2}‐[0‐9]+", name_phone_str)
name = [x.split("/")[0].strip() for x in name_phone]](https://image.slidesharecdn.com/pythonafunjimv1-171213041823/85/Python-138-320.jpg)
![練習 05: 答案
139
# 將剛剛處理完的 list,以 dictionary 放進 pd.DataFrame 中
df = pd.DataFrame({"店名":name,
"地址": address,
"電話": phone},columns = ["店名","地址","電話"])
df.to_csv("csv_results/practice05.csv", index =False,
encoding="cp950")](https://image.slidesharecdn.com/pythonafunjimv1-171213041823/85/Python-139-320.jpg)














![爬圖片的過程 ‐ 偽裝成瀏覽器發送請求
部份網站會判斷你是否為爬蟲程式
偽裝成瀏覽器發送請求預防被檔
156
from urllib.request import build_opener
from urllib.request import install_opener
opener = build_opener()
opener.addheaders = [('User‐Agent', 'Mozilla/5.0
(X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like
Gecko) Chrome/60.0.3112.78 Safari/537.36')]
install_opener(opener)](https://image.slidesharecdn.com/pythonafunjimv1-171213041823/85/Python-156-320.jpg)



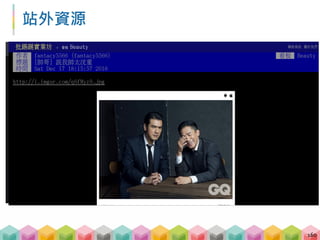




![圖片存檔 ‐ 原始檔名與正確的副檔名
透過圖片 URL 提取檔名
透過檢查過後的圖片格式當作副檔名
165
# url = 'http://i.imgur.com/q6fMyz9.jpg'
filename = url.split('/')[‐1] # q6fMyz9.jpg
filename = filename.split('.')[0] # q6fMyz9
ext = image.format.lower() # JPEG ‐> jpeg
download_filename = '{}.{}'.format(filename,
ext) # q6fMyz9.jpeg](https://image.slidesharecdn.com/pythonafunjimv1-171213041823/85/Python-165-320.jpg)






![檔案爬蟲 ‐ 定位節點
尋找相同圖片而且上層是 a tag 的 img tag
172
# 透過 regular expression 找到相同圖片的 img tag
images = soup.find_all('img',
{'src': re.compile('application‐pdf.png')})
for image in images:
# 透過 parent 函數尋訪 img tag 的上一層 tag
print(image.parent['href'])](https://image.slidesharecdn.com/pythonafunjimv1-171213041823/85/Python-172-320.jpg)













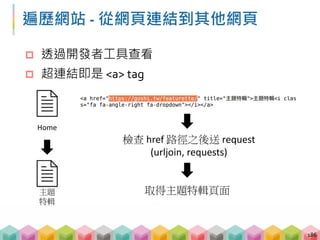


![遍歷網站
看過網站所有超連結 = 看過所有網頁所有超連結
紀錄所有需要送 requests 的超連結,直到送過所
有超連結
189
root
index1 index2 index3 hidden
[ index2, index3 ][ index3 ][ hidden ][ ]](https://image.slidesharecdn.com/pythonafunjimv1-171213041823/85/Python-189-320.jpg)
![遍歷網站 ‐ 直到看過所有連結
宣告一個 list 儲存即將要送 request 的網址
決定送 request 的中止條件
190
# 儲存即將要送 request 的網址
wait_list = ['https://afuntw.github.io/demo‐
crawling/demo‐page/ex1/index1.html']
# 當 wait list 裡還有網址的時候...
while wait_list != []:
# 送 request 的流程](https://image.slidesharecdn.com/pythonafunjimv1-171213041823/85/Python-190-320.jpg)




![解決遍歷網站的迴圈問題
建立一個已經送過 request 的清單 viewed_list
wait_list 裏面也不能有重複的 URL
195
viewed_list = []
# 將送過 request 的網址存入 viewed_list
viewed_list.append(url)
# 檢查新網址沒有出現在 wait_list 與 viewed_list
if new_url not in wait_list and new_url not in
viewed_list:
wait_list.append(new_url)](https://image.slidesharecdn.com/pythonafunjimv1-171213041823/85/Python-195-320.jpg)





![過濾 href
201
import re
# 過濾錨點, e.g. #top
check_url_1 = re.match('#.*', url) # True/False
# 過濾其他協定, 只接受 http/https
from urllib.parse import urlparse
check_url_2 = urlparse(url).scheme not in
['https', 'http']
# 過濾程式碼, e.g. javascript:alert();
check_url_3 = re.match('^javascript.*', url)](https://image.slidesharecdn.com/pythonafunjimv1-171213041823/85/Python-201-320.jpg)






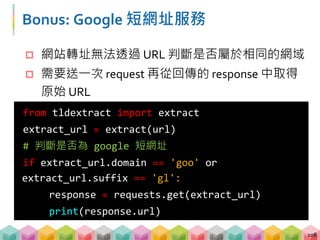















![XPath 範例
Beautifulsoup 寫法
soup.find_all('div')[2].find_all('div')[0]
224
from selenium import webdriver
# 打開瀏覽器, 視窗最大化, 對目標網址送 request...
# 尋找一個 html > body > div[2] > div[0]
h2 = driver.find_element_by_xpath(
'/html/body/div[2]/div[0]')](https://image.slidesharecdn.com/pythonafunjimv1-171213041823/85/Python-224-320.jpg)

![XPath 範例
226
from selenium import webdriver
from selenium.webdriver.common.by import By
# 尋找任何一個 id = 'first' 的 tag
h2 = driver.find_element(By.XPATH,
'//*[@id="first"]')
# 尋找網頁中 id = 'second' 或 'third' 的 h2 tag
p = driver.find_elements(By.XPATH,
'//h2[@id="second"] | //h2[@id="third"]')](https://image.slidesharecdn.com/pythonafunjimv1-171213041823/85/Python-226-320.jpg)















[系列活動] Python 爬蟲實戰
- 1. 歡迎來到 Python 爬蟲實戰課程! 還沒有下載 code 的同學,請到以下網址下載或是 教室前方有隨身碟可以使用 https://goo.gl/e5csuH or google 搜尋 afunTW github→afunTW (C.M. Yang) ∙ GitHub→dsc‐crawling 有任何問題可以先參考網頁上的說明文件,若無法 排除則可以請旁邊的助教們幫忙 1
- 3. Lecturers 台大土木所畢 中研院資訊所研究助理 研究領域 社群媒體資料處理分析 製造工業影像資料分析 中研院資訊所研究助理 研究領域 pattern recognition 資料分析 3
- 4. 課程進行方式 今日的課程共分為四個 Session,課程會用到的 code 及 data 都放在相對應的資料夾內 4 Python 爬蟲實戰 Session_A 課程會先由講師講解範例,在看到 這個符號出現時,就代表是大家的練習時間囉! 練習時有任何問題歡迎隨時舉手詢問旁邊的助教們 Session_B Session_C Session_D
- 5. Outline – 上午 A. 爬蟲基本介紹 HTML 初次見面 第一支爬蟲程式 BeautifulSoup 的常用函數 正則表達式 (regular expression) B. 爬蟲實戰與資料分析 BeautifulSoup + regular expression GET vs. POST 文字探勘與資料分析 使用 pandas 儲存資料 (optional) 5
- 6. Outline – 下午 C. 靜態網頁以外的爬蟲 圖片爬蟲 檔案爬蟲 網站爬蟲 D. 現實世界的爬蟲 現代網站爬蟲衍生的問題 動態網頁爬蟲 6
- 7. 上午你將會學到… 運用 requests 發送 GET, POST 請求 運用 BeautifulSoup 解析 HTML 網頁 運用 regular expression 尋找目標資訊 運用 sklearn, jieba, wordcloud 做簡單的資料分析 運用 pandas 將抓到的資訊儲存為表格 (optional) 7 實際 coding 把網頁資料爬下來!
- 9. 如何開啟 jupyter notebook 如有安裝 Anacnoda,即可在資料夾下順利找到 9
- 10. 基礎操作 10
- 11. Import 套件 11
- 12. Outline A. 爬蟲基本介紹 爬蟲介紹與 HTML 初次見面 第一支爬蟲程式 BeautifulSoup 的常用函數 正則表達式 (regular expression) 12
- 13. 爬蟲是什麼? 有毒嗎? 13
- 14. 網路爬蟲 (Web Crawler) 網路爬蟲是一種機器人,可以幫您自動地瀏覽網際 網路並擷取目標資訊 自動化爬取目標網站,並按照您的需求 蒐集目標資料 無所不在的爬蟲 ‐ 爬遍世界上的網站,建立索引來成立搜尋引擎 14
- 15. 爬蟲可以做甚麼? 爬遍所有航空公司的網站,讓使用者只要輸入起訖 點就可以知道最便宜的票價在哪裡 爬遍 Ptt、新聞評論,建立輿情分析系統,測風向! 你還能做甚麼? 15
- 16. 網路爬蟲三步驟 1. 取得指定網域下的 HTML 資料 透過 requests 取得 HTML 2. 解析這些資料以取得目標資訊 透過開發者工具,觀察目標資訊的位置 透過 BeautifulSoup 解析 HTML 3. Loop! 16
- 17. 爬蟲眼中的世界 17
- 18. 網頁的組成 18
- 19. 什麼是 HTML? HyperText Markup Language (超文件標示語言) 由一群元素 (Elements) 所組成的階層式文件 一個元素包含開始標籤、結束標籤、屬性以及內容 19 … <標籤 屬性> 內容 </標籤> 元素
- 20. HTML 的結構 <標籤 屬性> 內容 </標籤> 以樹狀結構,階層式呈現元素之間的關係 20 <html> <head> </head> <body> <h1 id="title"> Title </h1> <p> Paragraph </p> <ol> <li> Item 1 </li> <li> Item 2 </li> </ol> </body> </html> Document Object Model
- 21. HTML 元素的組成 ‐ 標籤 (Tags) 標籤通常是成對出現,有一個開始標籤 (start tag) 與 結束標籤 (end tag),例如此處的 <h1>, </h1> 21 <h1>I am heading!</h1> <p class="Hi!我是 attributes">Hi!我是 contents</p> <title>My Coding Journal</title> 標籤內可以有屬性 (attributes) 來說明這個標籤的性質 開始標籤與結束標籤所包含的即為內容 (contents), 通常為顯示在網頁上的文字 開始標籤 結束標籤
- 22. 常見的標籤 (Tags) 標籤名稱 用途 <h1> ‐ <h6> 標題 <p> 段落 <a> 超連結 <table> 表格 <tr> 表格內的 row <td> 表格內的 cell <br/> 換行 (無結束標籤) 22
- 23. 標籤內的屬性 (Attributes) 標籤內可以有屬性 (attributes) 來說明這個標籤的性 質,通常以 name = "value" 的方式呈現 一個標籤內也可同時存在多個屬性 1. class = "value" 2. id = "123" 超連結通常都是屬性 href 的值 23 <p class="Hi!我是 attributes">Hi!我是 contents</p> <div class="value" id="123">Hi!我有兩個屬性</div> <a href="http://foundation.datasci.tw/">資料協會網站</a>
- 24. 常見的屬性 (Attributes) 24 屬性名稱 意義 class 標籤的類別 (可重複) id 標籤的 id (不可重複) title 標籤的顯示資訊 style 標籤的樣式 data‐* 自行定義新的屬性
- 25. 與 HTML 的初次見面 (1/3) Step 1. 請先用 Chrome 打開 example_page.html 25
- 26. 與 HTML 的初次見面 (2/3) Step 2. 請再用文字編輯器 (sublime text, 記事本…) 打開 example_page.html 26
- 27. 與 HTML 的初次見面 (3/3) Step 3. 用文字編輯器 (sublime text, 記事本..) 打開 example_page.html 後 在 h3 標籤的下一行加入 <h4>我是 h4</h4> 將 p 標籤,屬性 title = "i‐am‐title" 的值改成 "i‐am‐new‐ title",存檔後將滑鼠移到 "這是 p 標籤的內容"上看看 將 "列 2 欄 3" 的 a 標籤,屬性 href 的值改成 "http://www.google.com.tw" 27
- 28. CSS 的基本介紹 Cascading Style Sheets (串接樣式表) 一種用來替 HTML 增加 style 的語言,舉凡修改顏 色、字體大小、字體類型等等,皆由 CSS 完成 28 <html> <head> <style> #i‐am‐id { background‐color: LightCyan; } </style> </head> </html>
- 29. CSS 小試 請用文字編輯器 (sublime text, notepad…) 打開 example_page.html 後 將 #i‐am‐id {background‐color: LightCyan;} 的 LightCyan 改成 Royalblue,存檔後重新整理剛剛打開的網頁 29
- 30. 小結 甚麼元素、標籤、屬性都聽不懂,有沒有懶人包?! 30 <p class="value"> target </p> 目標資訊目標標籤 輔助資訊
- 31. 在動手寫爬蟲之前… 31 前人種樹,後人乘涼 許多爬蟲程式在 GitHub 可以找得到 e.g. PTT Crawler, 漫畫下載器 想爬的網站是否有 API? 許多公司會透過 API 來提供乾淨、整齊的資料,並訂定 爬行的規則 e.g. Facebook API, Google Maps API 當一隻有禮貌的爬蟲 過於頻繁、大量的送出 requests 會造成伺服器的負擔
- 32. Outline A. 爬蟲基本介紹 爬蟲介紹與 HTML 初次見面 第一支爬蟲程式 BeautifulSoup 的常用函數 正則表達式 (regular expression) 32
- 33. 情境 又是難受的星期一,慣老闆一進到公司後,就要你 把上周所有的新聞標題抓下來,要好好關心一下國 家大事 剛上完 Python 爬蟲實戰的你,開始回想起上課的 內容 33
- 34. 標題文字在哪個標籤裡? 34
- 35. 範例 00: 第一支爬蟲程式 如何透過程式,取出範例網頁中的大標題 「Python 爬蟲實戰」? 35 # import 套件 import requests from bs4 import BeautifulSoup # 用 requests 抓取網頁並存在 response response = requests.get("https://jimmy15923.github.io/ example_page") # 用 BeautifulSoup 解析 HTML 並把結果回傳 soup soup = BeautifulSoup(response.text, "lxml") # 印出 h1 標籤 print(soup.find("h1"))
- 36. Requests 的功能 Requests: HTTP for Humans 最常用的兩個方法 GET POST 36 response = requests.get("www.yahoo.com.tw") www.yahoo.com.tw
- 37. Requests 的常用函數 response.status_code 200 403 Forbidden 404 Not Found response.encoding 如果是中文網站要特別注意編碼的問題 response.text 目標網頁的 HTML 文字 37
- 39. BeautifulSoup 登場! 強大且簡單易學的 HTML 解析器 將 HTML 轉變成 BeautifulSoup 物件 再用 BeautifulSoup 的函數取得想要的標籤資訊 39
- 40. 練習 00: 淺嘗 BeautifulSoup 40 BeautifulSoup 可以直接找出你想要的 tags 而不需告訴他路徑 # 請輸入以下的 codes 並 print 出結果 . print(soup.find("h1") print(soup.h1) print(soup.html.h1) print(soup.body.h1) print(soup.html.body.h1)
- 41. Outline A. 爬蟲基本介紹 爬蟲介紹與 HTML 初次見面 第一支爬蟲程式 BeautifulSoup 的常用函數 正則表達式 (regular expression) 41
- 42. 讓 BeautifulSoup 更好喝的函數 ‐ find() find(tag, attribute, recursive, text, keywords) 當你想要找一個標籤 42 soup.find("tag") soup.tag 當你想要找一個標籤且屬性為特定值 soup.find("tag",{"attr":"value"}) soup.find("tag",attr="value")
- 43. 讓 BeautifulSoup 更好喝的函數 ‐ find_all() 一個 tag 不夠,想找多個怎麼辦? find_all() 可以幫上忙 用法跟 find() 一樣,但是回傳的是 Python 的 list 43 [ , , ... ]
- 44. 找到標籤了! 其實我們不在乎標籤本身,我們要的是那個躲在標 籤裡面的內容或是屬性! 加上 .text 後,成功拿到這個標籤的內容 44
- 45. 範例 01: BeautifulSoup 的常用函數 45 # 找出第一個 td 的標籤 print(soup.find("td")) # 找出第一個 td 的標籤並印出其文字內容 print(soup.find("td").text) # 找出所有 td 的標籤 print(soup.find_all("td"))
- 46. 範例 01: BeautifulSoup 的常用函數 46 # 不指定標籤,但找出所有屬性 class = "zzz" 的標籤 print(soup.find_all("", {"class":"zzz"})) # 找出所有 td 標籤的第三個並找出其中的 a 標籤 print(soup.find_all("td")[2].find("a"))
- 47. 範例 01: BeautifulSoup 的常用函數 47 # 找出所有內容等於 python_crawler 的文字 print(soup.find_all(text="python_crawler")) # 找出第一個 a 標籤並印出屬性 print(soup.find("a").attrs) print(soup.find("a")["href"])
- 48. 練習 01: BeautifulSoup 的常用函數 (8 mins) 請觀察範例網頁後,嘗試回答以下的問題 請計算範例網頁中,共含有幾個 "td" 的標籤 (tags)? 請找出 "div"標籤,且屬性 (attributes) id = "i‐am‐id" 的 文字內容? 請找出列 3 欄 3 背後的超連結網址? (在網頁上面按右鍵 →檢查,有哪些輔助資訊可以幫我們找到這個標籤?) 48
- 49. 練習 01: 答案 49 # 找出所有 td 標籤,並用 len 計算長度 print(len(soup.find_all("td"))) # 找到 div 標籤,屬性 id = "id1",再印出其內容 print(soup.find("div", id="id1").text) # 透過觀察網頁可以發現 列3欄3 有個 id = hyperlink 可 以幫助我們定位這個 tag,再把 tag 的 href 找出來 print(soup.find("a", {"id":"hyperlink"})["href"]) 8
- 50. Outline A. 爬蟲基本介紹 爬蟲介紹與 HTML 初次見面 第一支爬蟲程式 BeautifulSoup 的常用函數 正則表達式 (regular expression) 50
- 51. 情境 慣老闆一大清早就跑過來,交給你上百份文件,要 你從這些文件裡面,整理出所有客戶的 Email 清單 ,怎麼辦? 而這對剛上完 Python 爬蟲實戰的你,毫無困難 51
- 52. BeautifulSoup 的調味料: 正則表達式 甚麼是 regular expression? [A‐Za‐z0‐9._]+@[A‐Za‐z.]+.(com|edu)+.tw 別害怕! 我們一步一步來 52
- 54. regular expression 常用符號 54 符號 意義 範例 符合範例的字串 * 前一字元或括號內字元出現 0次或多次 a*b* aaaab、aabb、 bbb + 前一字元或括號內字元出現 1次或多次 a+b+ aaabb、abbbb、 abbbbb {m,n} 前一字元或括號內字元出現 m次到 n 次 (包含 m, n) a{1,2}b{3,4} abbb、aabbbb、 aabbb [] 符合括號內的任一字元 [A‐Z]+ APPLE、QWER 跳脫字元 .| .| . 符合任何單一字元 (符號, 數字, 空格) a.c auc、abc、a c regular expression 使用許多符號來訂定搜尋規則, 要學會使用就必須知道符號的意義
- 55. Python 的 re Python 有內建的 regular expression 函數 推薦使用 re.findall() 55 # 找出所有內容等於 python_crawler 的文字 pattern = "我寫好的 regular expression" string = "我想要搜尋的字串" re.findall(pattern, string)
- 56. 範例 02‐1: *, +, {} 的用法 * 代表前面的字元可出現零次以上 + 代表前面的字元至少要出現一次以上 {m,n} 代表前面的字元可出現 m 次 ~ n 次 (包含) 56
- 57. 練習 02‐1: 答案 57 a*b+c a 出現零次以上 b 出現一次以上 C 出現一次
- 58. 範例 02‐2: 找到數字 [ ] 代表的意思是這個字元可以是括號內的任何一個 [0‐9] 代表可以是 0~9 之間的任意數字 [a‐z] 代表可以是 a~z 之間的任意文字 58
- 59. 練習 02‐2: 答案 59 [0‐9]+ 符合 0‐9 任一數字,且須出現一次以上 [1‐3]+ 符合 1‐3 任一數字,且須出現一次以上 123 符合 123 的字元
- 60. 範例 02‐3: 找到文字 當有指定的文字需要搜尋,可透過 [ ] 搭配 *, + , {} 進行搜尋 60
- 61. 練習 02‐3: 答案 61 [A‐Z]+[a‐z] 前兩個字元要是 A‐Z 其中一個,且出現一次以上 最後一個字元要是 a‐z 其中一個
- 62. 範例 02‐4: 跳脫符號 萬一我今天想要找到的就是 + 這個符號怎麼辦? 在前面加上一個跳脫符號 . 代表任何字元 (符號、數字、空格) 62
- 63. 練習 02‐4: 答案 63 [A‐Z]+[a‐z] 第一個字元要是 A‐Z 其中一個 第二個字元要是 + 號 第三個字元要是 a‐z 其中一個
- 64. 範例 02‐5: 條件式搜尋 | 代表左右邊只要任一符合條件即可 64
- 65. 練習 02‐5: 答案 65 jimy|jim{3}y 符合 jimy 或是符合 jimmmy
- 66. Email 的 regular expression (1/2) [A‐Za‐z0‐9._]+@[A‐Za‐z.]+(com|edu).tw [A‐Za‐z0‐9._]+@ 大小寫英文、數字、點、底線,可出現一次以上, 且加上 @ 66
- 67. Email 的 regular expression (2/2) [A‐Za‐z0‐9._]+@[A‐Za‐z.]+(com|edu).tw [A‐Za‐z.]+(com|edu).tw 大小寫英文、點,可出現一次以上,且結尾須為 com 或 edu 再加上 .tw, 67
- 69. 練習 02: regular expression (10 mins) 請觀察 518 黃頁網,並找出所有店家的電話號碼 (包含分機) 請透過開發者工具,觀察目標資訊藏在那些標籤底下? 標籤內有甚麼特別的屬性可以讓我們找到嗎? 怎麼把包含電話號碼的 list 合併成一個大的 test_string? 69 # 非常實用的 for loop 寫法,當你使用 find_all 後, 想一口氣把 list 裡面所有 tags 的內容文字取出時, 可以這樣寫 [tag.text for tag in soup.find_all("tag")]
- 70. 練習 02: 答案 70 # 用 requests 抓取網頁並存在 response # 用 BeautifulSoup 解析 HTML 並把結果回傳 soup response = requests.get(" https://jimmy15923.github.io/518") soup = BeautifulSoup(response.text,"lxml") # 抓到所有 li 標籤,且屬性 class=comp_tel,並存在 list 裡 all_phone_text = [tag.text for tag in soup.find_all("li", {"class":"comp_tel"})] # 將 list 的所有文字,存為一個 string all_phone_text = "".join(all_phone_text) # 用 regular expression 找出所有電話號碼 phone_number = re.findall("0[1‐9]‐[0‐9]+", all_phone_text)
- 71. Session B 即將在 10:50 開始… 請先使用 jupyter notebook 打開 Session_B/Practice/03_BeautifulSoup+regular_expres sion.ipynb 還沒有下載 code 的同學,請到以下網址下載或是 教室前方有隨身碟可以使用 https://goo.gl/e5csuH 71
- 72. 爬蟲實戰練習與資料分析 72
- 73. Outline B. 爬蟲實戰練習與資料分析 BeautifulSoup + regular expression GET vs. POST 文字探勘與資料分析 使用 pandas 儲存資料 (optional) 73
- 74. 情境 自從慣老闆發現你很好用之後,某天又突然跑過來 ,這次是要請你把美食網站上面,所有店家的地址 都抓下來,而且老闆限定要是新北市的喔! 同樣的,這對剛上完 Python 爬蟲實戰的你, 也是小菜一碟 74
- 75. BeautifulSoup + regular expression BeautifulSoup 可以幫您解析 HTML regular expression 可以按照您的規則回傳字串 兩個加在一起,就可以按照想要的規則取出目標標籤 75
- 76. 範例 03: BeautifulSoup + regular expression 運用 BeautifulSoup 加上 regular expression,可以抓 到任何給定條件的資訊 在 BeautifulSoup 裡必須使用 re.compile 來寫 pattern re.compile 可以用來尋找 tags, attrs 及 contents 76 # import 套件 import re # 用 regular expression 找出所有 td 或 tr 標籤 soup.find_all(re.compile("t(d|r)"))
- 77. 範例 03: BeautifulSoup + regular expression 77 # 找出所有屬性為 class 且值包含至少一個 z 以上的標籤 soup.find_all("",{"class":re.compile("z+")}) # 用 regular expression 找出所有包含 python 的 contents soup.find_all("",text=re.compile("python"))
- 78. 1. 請找出範例網頁中所有標籤,其屬性 href 的值包 含資料科學協會的網址 ("http://foundation.datasci.tw/...") 要怎麼找到屬性是 href 的所有標籤? 要如何把 regular expression 加進 BeautifulSoup ? 2. 請觀察518 黃頁網,並找出所有位在新北市的店家 地址 地址的資訊都藏在哪些 tags 底下? 怎麼把 regular expression 用在 contents 上面? 78 練習 03: BeautifulSoup + regular expression (10 mins)
- 79. 練習 03‐1: 答案 79 # 萬年起手式,先 requests 再用 BeautifulSoup 解析 response = requests.get(" https://jimmy15923.github.io/example_page") soup = BeautifulSoup(response.text, "lxml") # 不指定標籤,找到屬性 href,值為特定網址 print(soup.find_all("", {"href":re.compile( "http://foundation.datasci.tw")}))
- 80. 練習 03‐2: 答案 80 # 萬年起手式,先 requests 再用 BeautifulSoup 解析 response = requests.get(" https://jimmy15923.github.io/518 ") soup = BeautifulSoup(response.text, "lxml") # 找到標籤 li,且屬性 class=comp_loca,內容包含 "新北" print(soup.find_all("li",{"class":"comp_loca"}, text=re.compile("新北")))
- 81. Outline B. 爬蟲實戰與資料分析 Beautiful Soup + regular expression GET vs. POST 文字探勘與資料分析 使用 pandas 儲存資料 (optional) 81
- 82. 情境 慣老闆又出現啦!這次想要請你把某個時段的高鐵 時刻表全部找出來,方便以後出差的時候參考 你找到高鐵時刻表網站,開心的想起萬年起手式, 開始 import requests,request.get,這時… 82
- 83. 不會改變的網址 上網時常發現,許多操作像是搜尋、點選等均都是 在同一個網址底下完成,這種網頁該如何用我們之 前學的 requests 來爬取? 83 http://www.thsrc.com.tw/tw/TimeTable/SearchResult http://www.thsrc.com.tw/tw/TimeTable/SearchResult
- 84. 為何網址不會改變? 兩種常見原因 網頁透過 POST 的方式取得資料,先由瀏覽器在背景送 一些資料給 Server,Server 收到 POST 請求後,回傳相對 應的資料 現代的網頁為了提升使用者體驗,會運用 JavaScript, AJAX 等技術,來動態載入資料而不需重新整理網頁 84
- 85. GET vs. POST GET: 發送 requests,Server 回傳資料 URL 會隨著不同的網頁改變 1. http://www.taipeibo.com/yearly/2017 2. http://www.taipeibo.com/yearly/2016 POST: 發送 requests 並附帶資料,Server 回傳資料 網址不會改變,但是網頁資料會隨著使用者不同的 requests 改變 85
- 86. 如何知道 request methods? (1/4) 1. 右鍵→檢查 86
- 87. 如何知道 request methods? (2/4) 2. 選擇 Network 並勾選底下的 Preserve log 87
- 88. 如何知道 request methods? (3/4) 3. 設定要查詢的資料後送出 88
- 89. 如何知道 request methods? (4/4) 4. 上方的標籤選 Headers, 可以看到 Request Method 是 POST! 89
- 90. Form Data 90 Form Data 是我們剛剛在做 POST 時,傳送給 Server 的資料 Server 看到你的 POST,且透過你附帶的 Form data ,回傳你想要查詢的 HTML 結果
- 91. 範例 04: 如何使用 POST 91 # 觀察網頁後,找到 option 的值 form_data = { "StartStation":"2f940836‐cedc‐41ef‐8e28‐c2336ac8fe68", "EndStation":"e6e26e66‐7dc1‐458f‐b2f3‐71ce65fdc95f", "SearchDate":"2017/12/18 ", "SearchTime":"20:30", "SearchWay":"DepartureInMandarin"} # requests 改用 POST,並放入 form_data response_post = requests.post("https://www.thsrc.com.tw/tw/ TimeTable/SearchResult", data = form_data) soup_post = BeautifulSoup(response_post.text, "lxml")
- 92. 練習 04: 如何使用 POST (8 mins) 請運用 POST 方式,找出 2017 年 12 月 18 日 21:30 南港站到台南站共有幾個班次? 觀察南港、台南站的 option value 是甚麼? 查看班次的資訊都藏在哪些標籤內? 92
- 93. 練習 04: 答案 93 # 將要查詢的資料寫成 dictionary form_data = { "StartStation":"2f940836‐cedc‐41ef‐8e28‐c2336ac8fe68", "EndStation":"9c5ac6ca‐ec89‐48f8‐aab0‐41b738cb1814", "SearchDate":"2017/12/18", "SearchTime":"21:30", "SearchWay":"DepartureInMandarin"} # requests 改用 POST,並放入 form_data response_post = requests.post("https://www.thsrc.com.tw/tw/ TimeTable/SearchResult", data = form_data) soup_post = BeautifulSoup(response_post.text, "lxml") # 找出有幾個 td 標籤,屬性為 class=column1 print(len(soup_post.find_all("td", class_="column1"))) 3
- 94. 小結 HTML 元素所組成的階層式文件 標籤中含有屬性 (attributes) 以及內容 94
- 95. 小結 requests GET, POST BeautifulSoup find_all(tags, attributes) regular expression find_all(tags, {attributes: "your_re"}) 95
- 96. 爬蟲實戰練習 96
- 97. 爬蟲實戰攻略 ‐ 掌握階層式的架構 當你使用 find_all() 時,會抓出所有符合條件的標籤 ,但當你先找到一個特定標籤,在使用 find_all () 時,找到的就是在那特定標籤底下所有符合條件的 標籤。 97 # 找出所有 tr 標籤 soup.find_all("tr") # 找到 table 標籤底下的所有 tr 標籤 soup.find("table").find_all("tr") # Warning! 不可以這樣寫! Why? soup.find_all("table").find("tr")
- 98. 爬蟲實戰小技巧 找到目標資訊藏在哪些標籤底下? stripped_strings: 找出 tag 底下所有的文字,且幫你去除 所有空格、換行符號等等,需要用 iterate 的方式取值。 98
- 99. 爬蟲實戰小技巧 如何找出沒有任何屬性的標籤? 99 如何對 list 做 loop,同時增加 index 值?
- 100. 練習 05: 爬蟲實戰 請運用所學過的方法,嘗試爬取以下這兩個網頁的 資訊,並儲存成 CSV 台北票房觀測站‐年度排名,請爬取 2016、2017 年度排名 (15 ~ 20 mins) 如果卡住的話,歡迎參考範例 06 的 code yahoo 奇摩電影評論,請選擇在票房排行榜上任何一部您 喜歡的電影,並將其所有的評論文字、評論星等以及該電 影的名稱抓下來 (20 ~ 25 mins) 如果卡住的話,歡迎參考練習 06‐2 的 提示 100
- 102. Outline B. 爬蟲實戰與資料分析 BeautifulSoup + regular expression GET vs. POST 文字探勘與資料分析 使用 pandas 儲存資料 (optional) 102
- 103. 情境 辛苦把資料都抓下來,也把成功資料儲存成結構化 的數據,慣老闆突然神來一筆,最近大數據還有甚 麼 AI 不是非常紅嗎?為什麼不用這些資料來做一些 大數據分析阿! 已經受不了在準備辭呈的你突然想起,Python 爬蟲 實戰好像也有玩過一點資料分析耶! 103
- 104. Data Summary 電影票房資料 ‐ 排名、片名、院數、映期、上映日 期、平均票房、累積票房 2016, 2017 年各 100 部 電影評論資料 ‐ 片名、評論文字、評論星等 200 部電影的所有評論及星等 104
- 105. 資料清理 在資料分析開始前,資料清理永遠都是最重要的 工作,資料的乾淨與否會影響分析的結果 檢查是不是抓下來的資訊是否正確? 格式是不是可以使用? 105
- 107. 文字探勘與文字雲 探討評論文字與星等之間的關係 給五顆星的人都寫了甚麼? 給一顆星的人又都寫了甚麼? 文字雲可以美觀地呈現出文字的重要程度 107
- 108. 中文字是需要斷詞的 甚麼是斷詞? 例如:我覺得不行 我 / 覺得 / 不行 ○ 我覺 / 得不行 X 英文本身就已經用空格做好斷詞這件事,但是中文 真的不行 乖乖的做斷詞吧! 108
- 109. jieba 登場! 把每一條評論斷完詞後,我們就可以得到每條評論 都用了哪些詞 (e.g., 好看、爛片、無聊) 再運用統計的方式,計算一下五星評論與一星評論 之間的用詞頻率是否有所不同 109 # 載入套件 import jieba # 把"我覺得可以"作斷詞後 print([x for x in jieba.cut("我覺得不行")])
- 110. 文字雲的應用 經過斷詞後,我們得到了詞彙在評論中出現的頻率 ,透過 WordCloud 這個套件可以呈現出這樣的結果 110
- 111. TF‐IDF 直接統計頻率好像太 Low 了,有沒有潮一點的方法? Term Frequency ‐ Inverse Document Frequency TF: 詞頻,該詞在某一文件中出現的次數 IDF: 逆向文件頻率,該詞在所有文件中出現的次數 111
- 112. TF‐IDF 的文字雲 透過 TF‐IDF 的分析過後,較有意義的詞會更容易 得到更高的權重 112
- 113. 只要有 Data,不怕沒得玩 換套斷詞方式 (中研院斷詞系統 ) word2vec (詞向量) 文字探勘 113 天 地 溫拿 魯蛇
- 115. 用平均星等來預測票房 將電影所有的評論星等作平均,即可獲得該電影的 平均評價 透過 Linear Regression,來探討平均星等與票房之 間的關係 115 預測
- 116. Linear Regression on Scikit‐Learn 116 # 切 training data 跟 testing data X_train,X_test,y_train,y_test = train_test_split( movie_box["平均星等"], np.log10(movie_box["平均票房"])) # 建立 Regression 模型 reg = LinearRegression() # 放入 training data 進行訓練 reg.fit(X_train, y_train) # 用 testing data 做預測 y_pred = reg.predict(X_test) # 算出 testing data 與預測結果的相關係數 print(pearsonr(y_pred, y_test)) 0.21
- 118. 為什麼這麼差? (2/2) Features 用的太少 還有很多變數可以解釋票房的變異 回歸太難了 試試用分類吧! 118 不叫座<票房中位數<叫座
- 119. 分類問題的好幫手 ‐ 決策樹 (Decision Tree) 在空間中找到一些線 (rule) 讓這些點可以被分開 每個分支就好像在做決策 (Decision) 119
- 120. Decision Tree on Scikit‐Learn 120 # 切 training data 跟 testing data X_train,X_test,y_train,y_test = train_test_split( movie_box[["評論數量", "平均星等", "映期"]], movie_box["平均 票房"]) # 建立 Decision Tree 模型 clf = DecisionTreeClassifier(max_depth=3) # 放入 training data 進行訓練 clf.fit(X_train, y_train) # 用 testing data 做預測 y_pred = reg.predict(X_test) # 算出 testing data 與預測結果的準確率 print(accuracy_score(y_pred, y_test)) 0.84
- 121. 生成的決策樹 121 評論數量 125 筆 大於 映期 58 天 小於 小於 大於 小於 大於 評論數量 185 筆 小於 小於 大於 映期 81 天 平均星等 3.65 小於 評論數量 35 筆 大於 大於
- 122. 小結 122 透過 Decision Tree 的 features importance,我們 可以發現,平均星等根本就不太重要嘛! 你還能想出其他的 features 嗎?
- 123. Outline B. 爬蟲實戰與資料分析 BeautifulSoup + regular expression GET vs. POST 文字探勘與資料分析 使用 pandas 儲存資料 (optional) 123
- 124. 情境 辛苦抓完所有東西後,慣老闆卻要求說,要把資料 全部都存成表格,這樣我才能方便用 excel 打開還 有編輯啊! 所幸,Python 爬蟲實戰還是有教過怎麼做 124 Success!
- 125. pandas 登場 pandas 是一個基於 numpy 的函式庫,不論是用來 讀取、處理數據都非常的簡單方便 處理結構化的數據非常好用! 125
- 126. pandas 的核心 ‐ DataFrame DataFrame 就是由 rows 跟 columns 所組成的一個 大表格 126
- 127. DataFrame 的組成 一個 DataFrame 的組成可以分成兩種情形來看 由 rows 組成 由 columns 組成 127
- 128. 如何用 pandas 儲存爬下來的資料? 如果爬下來的資料是以 row 為單位 128
- 129. 把爬下來的資料變成表格 如果爬下來的資料是以 column 為單位 129
- 130. 常用的資料格式 ‐ CSV Comma‐Separated Values,是一種常見的資料格式 ,本身是一個純文字檔,用來記錄欄位的資料,欄 位之間的資料常用逗號作分隔 130
- 131. 將 DataFrame 存成 CSV index =False 代表不須額外增加 index 這個欄位 windows 系統,encoding 使用 cp950 (有中文的話用 excel 打開才不會亂碼),若為 linux 則用 utf‐8 131 # 將剛剛建立好的 DataFrame 存成 csv df.to_csv("filename.csv", index=False, encoding="cp950")
- 132. 132 範例 05: 將高鐵時刻表的結果存成 CSV # 將要查詢的資料寫成 dictionary form_data = { "StartStation":"2f940836‐cedc‐41ef‐8e28‐c2336ac8fe68", "EndStation":"9c5ac6ca‐ec89‐48f8‐aab0‐41b738cb1814", "SearchDate":"2017/12/18", "SearchTime":"21:30", "SearchWay":"DepartureInMandarin"} # requests 改用 POST,並放入 form_data response_post = requests.post("https://www.thsrc.com.tw/tw/ TimeTable/SearchResult", data = form_data) soup_post = BeautifulSoup(response_post.text, "lxml")
- 133. 133 範例 05: 將高鐵時刻表的結果存成 CSV ‐ by columns # 找出所有 td 標籤 屬性 class=column1 的內容,並存成 list train_number = [tag.text for tag in soup_post.find_all("td", class_="column1")] # 找出所有 td 標籤 屬性 class=column3 的內容,並存成 list departure = [tag.text for tag in soup_post.find_all("td", class_="column3")] # 找出所有 td 標籤 屬性 class=column4 的內容,並存成 list arrival = [tag.text for tag in soup_post.find_all("td", class_="column4")] # 找出所有 td 標籤 屬性 class=column2 的內容,並存成 list travel_time = [tag.text for tag in soup_post.find_all("td", class_="column2")]
- 134. 範例 05: 將高鐵時刻表的結果存成 CSV ‐ by columns 134 # 建立 DataFrame,把 dictionary 放入,並指定 columns 順序 highway_df = pd.DataFrame( {"車次":train_number, "出發時間":departure, "抵達時間":arrival, "行車時間":travel_time}, columns = ["車次", "出發時間", "抵達時間", "行車時間"])
- 135. 範例 05: 將高鐵時刻表的結果存成 CSV ‐ by rows 135 # 先建立 DataFrame,確定 columns highway_df = pd.DataFrame(columns = ["車次","出發時間", "抵達時間", "行車時間"]) # loop 3 次,每次取出一個 row 的 3 個值並存入 DataFrame for i in range(3): row = soup_post.find_all("table", class_= "touch_table")[i] row_contents = [tag.text for tag in row.find_all("td", class_= re.compile("column"))] highway_df.loc[i] = row_contents
- 136. 範例 05: 將高鐵時刻表的結果存成 CSV 136 # 把建立好的 DataFrame 存成 CSV # for windows highway_df.to_csv("csv_results/demo05_highway_schedule.csv" , index = False, encoding = "cp950") # for linux highway_df.to_csv("csv_results/demo05_highway_schedule.csv" , index = False, encoding = "utf‐8")
- 137. 請觀察 518 黃頁網,並將店名、地址及電話三個欄 位抓下來,並存成表格如下 觀察店名、地址及電話都藏在哪些標籤底下? 有共通的 屬性嗎? 選擇要用 rows 或 columns 來組成 DataFrame 137 店家 地址 電話 藍柚小廚 新北市/永和區… 02‐2924… 果蔗新鮮 桃園縣/龍潭鄉… 03‐470… … … … 練習 05: 將抓下來的資訊儲存成表格 (8 mins)
- 138. 練習 05: 答案 138 # 萬年起手式 response = requests.get("http://yp.518.com.tw/service‐ life.html?ctf=10") soup = BeautifulSoup(response.text, "lxml") # 店家名稱與電話存在同一標籤,地址則在另一標籤 name_phone = [tag.text for tag in soup.find_all("li", class_="comp_tel")] address = [tag.text for tag in soup.find_all("li", class_="comp_loca")] # 運用 re 找到所有的電話號碼,運用 split,抓到店家名稱 name_phone_str = "".join(name_phone) phone = re.findall("[0‐9]{2}‐[0‐9]+", name_phone_str) name = [x.split("/")[0].strip() for x in name_phone]
- 139. 練習 05: 答案 139 # 將剛剛處理完的 list,以 dictionary 放進 pd.DataFrame 中 df = pd.DataFrame({"店名":name, "地址": address, "電話": phone},columns = ["店名","地址","電話"]) df.to_csv("csv_results/practice05.csv", index =False, encoding="cp950")
- 140. 上午我們學到了… 運用 BeautifulSoup 解析 HTML 網頁 運用 requests 發送 GET, POST 請求 運用 regular expression 尋找目標資訊 運用 pandas 將抓到的資訊儲存為表格 運用 sklearn, matplotlib, wordcloud 做簡單的資料分析 140 requests.get("website"), requests.post("website", form_data) soup = BeautifulSoup(response.text), soup.find_all() re.findall(pattern, test_string) DataFrame.to_csv(file_path)
- 141. 下午你會學到更多! 靜態網頁以外的爬蟲 圖片爬蟲 檔案爬蟲 網站爬蟲 現實世界的爬蟲 現代網站爬蟲衍生的問題 動態網頁爬蟲 141
- 142. Outline C. 靜態網頁以外的爬蟲 圖片爬蟲 檔案爬蟲 網站爬蟲 D. 現實世界的爬蟲 現代網站爬蟲衍生的問題 動態網頁爬蟲 142
- 143. 打開瀏覽器的開發者工具 選擇 inspect 工具 滑鼠移到你想選擇的圖片 圖片爬蟲 ‐ 圖片的 tag? 143
- 144. 文字爬蟲 送 request 到目標網頁 透過 Beautifulsoup 取得目標文字 tag 透過 .text 可以直接拿到文字資訊 圖片爬蟲透過解析網頁只能拿到圖片位置資訊 送 request 到目標網頁 透過 Beautifulsoup 取得目標圖片 tag 透過 src 屬性拿到圖片位置 再送 request 到圖片真正的位置 取得圖片並儲存 圖片爬蟲 ‐ 與文字爬蟲的差異 144
- 145. 爬文字的過程 爬文字的過程 ‐ 取得頁面資訊 145 request request Client Server https://gushi.tw/hu‐shih‐memorial‐hall/ .html .html
- 146. 爬文字的過程 爬文字的過程 ‐ 解析頁面並取得文字 146 Client Beautifulsoup( ) 尋找第 4 個 <p> tag 透過 .text 取得文字資訊 .html
- 147. 爬圖片的過程 ‐ 取得頁面資訊 147 request request Client Server https://gushi.tw/hu‐shih‐memorial‐hall/ .html .html
- 148. 爬圖片的過程 爬圖片的過程 ‐ 取得位置資訊 148 Client Beautifulsoup( ) 尋找第 1 個 <img> tag 透過 src 取得圖片位置資訊 .html
- 149. 爬圖片的過程 爬圖片的過程 ‐ 取得圖片 149 request request Client Server http://gushi.tw/wp‐ content/uploads/2016/08/logo.png img img
- 150. 爬圖片的過程 ‐ 下載圖片 150 from urllib.request import urlretrieve # 透過 urlretrieve 下載圖片 # url: 你要下載的圖片位置 # file: 你要儲存的文件名稱 urlretrieve(url, file)
- 151. 爬圖片的過程 ‐ 偽裝成瀏覽器發送請求 部份網站會判斷你是否為爬蟲程式 加上身份識別偽裝成瀏覽器送出請求 151 request request Client Server
- 152. 身份識別 User‐Agent 敘述瀏覽器使用的系統, 平台, 版本等資訊的字串 瀏覽器開發者工具 > Network 152
- 153. 身份識別 User‐Agent 敘述瀏覽器使用的系統, 平台, 版本等資訊的字串 瀏覽器開發者工具 > Network > 重新整理網頁 153
- 154. 身份識別 User‐Agent 重新整理網頁之後選擇對網頁送出的 request 154
- 155. 身份識別 User‐Agent 檢查 Headers 欄位中的 Request Headers 155
- 156. 爬圖片的過程 ‐ 偽裝成瀏覽器發送請求 部份網站會判斷你是否為爬蟲程式 偽裝成瀏覽器發送請求預防被檔 156 from urllib.request import build_opener from urllib.request import install_opener opener = build_opener() opener.addheaders = [('User‐Agent', 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.78 Safari/537.36')] install_opener(opener)
- 157. 練習 00: 下載圖片 (5 ~ 8 mins) 目標程式:00_download_image.py 目標網站:https://gushi.tw/hu‐shih‐memorial‐hall/ 目標:下載該頁面的第一個圖片 取得圖片的位置 透過開發者工具找到 User‐Agent 的值 偽裝成瀏覽器送出請求 下載圖片 157
- 158. Bonus: 檢查圖片下載百分比 透過 urlretrieve 的 callback 實作 callback 代表做完功能 A 時要做的功能 B 158 from urllib.request import urlretrieve # 設計 callback def check_percentage(chunk, size, remote): percent = 100.0 * chunk * size / remote if percent > 100.0: percent = 100.0 print('Download...{:.2f}%'.format(percent)) urlretrieve(url, 'logo.png', check_percentage)
- 159. 圖片存檔 ‐ 副檔名的重要性 副檔名只是讓電腦知道要用甚麼方式讀取的提示 副檔名錯誤就無法正確開啟檔案 直接更改副檔名並不等於轉檔 159 test.docx test.xlsx 用 Office Word 開啟的文件 用 Office Excel 開啟的文件 無法開啟文件 rename
- 160. 站外資源 160
- 164. 獲取真實的圖片格式 164 import requests from bs4 import BeautifulSoup from PIL import Image url = 'http://i.imgur.com/q6fMyz9.jpg' response = requests.get(url, stream=True) # 讓 PIL.Image 讀進圖片幫我們了解圖片格式 image = Image.open(response.raw) print(image.format) # JPEG
- 165. 圖片存檔 ‐ 原始檔名與正確的副檔名 透過圖片 URL 提取檔名 透過檢查過後的圖片格式當作副檔名 165 # url = 'http://i.imgur.com/q6fMyz9.jpg' filename = url.split('/')[‐1] # q6fMyz9.jpg filename = filename.split('.')[0] # q6fMyz9 ext = image.format.lower() # JPEG ‐> jpeg download_filename = '{}.{}'.format(filename, ext) # q6fMyz9.jpeg
- 166. 練習 01: 判斷格式並下載圖片 (5 ~ 8 mins) 目標程式:01_download_image_and_check_format.py 目標:下載圖片並以正確格式儲存 透過 stream 的方式送出請求 透過 PIL.Image 檢查圖片格式 透過字串處理取得適合的檔案名稱 下載圖片 166 url = 'http://imgur.com/rqCqA.png' url = 'http://imgur.com/rqCqA.jpg' url = 'http://imgur.com/rqCqA.gif'
- 167. 練習 01: 延伸思考 是否可以不透過 stream 的方式來判斷圖片? 透過 BytesIO 將圖片轉成 PIL.Image 需要的格式 是否可以只傳一次 request 就做判斷格式與存檔 bonus_one_requests.py 直接使用 PIL.Image 存檔而不透過 urlretrieve 167
- 168. Outline 靜態網頁以外的爬蟲 圖片爬蟲 檔案爬蟲 網站爬蟲 現實世界的爬蟲 現代網站爬蟲衍生的問題 動態網頁爬蟲 168
- 169. 檔案爬蟲 ‐ 超連結檔案 透過開發者工具查看檔案的 tag 169
- 170. 檔案爬蟲 ‐ 超連結的本體 外表看似圖片,但其實本體是超連結 170 <a href=”...”> </a> <img src=”...”>
- 171. 檔案爬蟲 ‐ 定位節點 尋找所有 a tag 再用 regular expression 過濾 href 尋找所有裏面包含 img tag 的 a tag 尋找相同圖片而且上層是 a tag 的 img tag 171 src = 'http://140.112.115.12/exam/sites/all/modules/filefield/ic ons/application‐pdf.png' <a href=”...”> </a> <img src=”...”>
- 172. 檔案爬蟲 ‐ 定位節點 尋找相同圖片而且上層是 a tag 的 img tag 172 # 透過 regular expression 找到相同圖片的 img tag images = soup.find_all('img', {'src': re.compile('application‐pdf.png')}) for image in images: # 透過 parent 函數尋訪 img tag 的上一層 tag print(image.parent['href'])
- 173. href 的絕對路徑與相對路徑 透過給予檔案位置 (URL) 讓網頁可以參考並顯示 e.g. <a href='...'>, <img src='...'> 敘述檔案位置的方式分為 絕對路徑 (e.g. http://140.112.115.12/exam/sites/all/modules/filefield/ico ns/application‐pdf.png ) 相對路徑 (e.g. /exam/sites/all/modules/pubdlcnt/pubdlcnt.php) 173
- 174. 檔案爬蟲 ‐ 相對位置 URL 代表檔案在網路上的位置 無法直接對相對路徑送 requests 174 請問可以外送十杯咖啡嗎? 可以阿,請問要送到哪裡? 門口進來左轉的樓梯到三樓右手邊的櫃台 … 是奧客嗎
- 175. 檔案爬蟲 ‐ 相對位置 URL 代表檔案在網路上的位置 無法直接對相對路徑送 requests 175 url = '/exam/sites/all/modules/pubdlcnt/pubdlcnt.php?file=http://140 .112.115.12/exam/sites/default/files/exam/graduate/106g/106_gr aduate_4.pdf&nid=5814' response = requests.get(image_url)
- 176. 檔案爬蟲 ‐ 將相對路徑轉為絕對路徑 必須把相對路徑轉為絕對路徑才能送出 request URL 有一定的格式,很難單純做字串處理轉換 透過參考用的絕對路徑就可以轉換相對路徑 176 http://exam.lib.ntu.edu.tw/graduate /exam/sites/all/modules/pubdlcnt/pubdlcnt.php 絕對路徑 相對路徑 http://exam.lib.ntu.edu.tw/exam/sites/all/modules /pubdlcnt/pubdlcnt.php 組合
- 177. 檔案爬蟲 ‐ 取得絕對位置 透過 urllib.parse.urljoin 取得絕對位置 當前網頁的 URL 最適合拿來做參考用的絕對路徑 177 from urllib.parse import urljoin print(urljoin(絕對路徑, 相對路徑))
- 178. 檔案爬蟲 ‐ 解析 URL urljoin 其實是透過 urllib.parse.urlparse 將兩組 URL 拆解成數個片段再去組合出新的絕對路徑 178 絕對路徑 相對路徑
- 179. 練習 02‐1: 檔案下載與 URL 轉換 (5 ~ 8 mins) 目標程式:02_1_observe_urljoin.py 目標:觀察不同的情況透過 urljoin 的結果 開頭有無斜線與兩條斜線的差別 不斷回到上一層的結果 179 print(urljoin(response.url, '105g/')) print(urljoin(response.url, '/105g/')) print(urljoin(response.url, '//facebook.com')) print(urljoin(response.url, '../')) print(urljoin(response.url, '../../'))
- 180. 練習 02‐2: 檔案下載與 URL 轉換 (5 ~ 8 mins) 目標程式:02_2_download_history_exam.py 目標網站:http://140.112.115.12/exam/graduate 目標:下載頁面上的所有考古題 (25 份) 定位超連結的 tag 將超連結的相對路徑轉換成絕對路徑 字串處理取得要下載的檔案名稱 下載檔案 180
- 181. Outline 靜態網頁以外的爬蟲 圖片爬蟲 檔案爬蟲 網站爬蟲 現實世界的爬蟲 現代網站爬蟲衍生的問題 動態網頁爬蟲 181
- 182. 網站結構 網頁是一份 HTML 檔案 網站是一堆網頁以階層式的方式組成的集合 182 root articles imgs js
- 184. 網站瀏覽行為 網站存放在遠端電腦中,我們稱該電腦為主機 網站瀏覽即是查看目標主機的不同檔案而已 184 root articles imgs js Home
- 185. 網站瀏覽行為 網站存放在遠端電腦中,我們稱該電腦為主機 網站瀏覽即是查看目標主機的不同檔案而已 185 root articles imgs js 主題 特輯
- 186. 遍歷網站 ‐ 從網頁連結到其他網頁 透過開發者工具查看 超連結即是 <a> tag 186 Home 主題 特輯 檢查 href 路徑之後送 request (urljoin, requests) 取得主題特輯頁面
- 187. 透過迴圈尋訪網站 透過迴圈對所有網址超連結都送出 request 187 root index1 index2 index3
- 188. 透過迴圈尋訪網站 並不是所有網頁的超連結都會出現在首頁 只做一次迴圈無法發現其他網頁裡的超連結 188 root index1 index2 index3 hidden
- 189. 遍歷網站 看過網站所有超連結 = 看過所有網頁所有超連結 紀錄所有需要送 requests 的超連結,直到送過所 有超連結 189 root index1 index2 index3 hidden [ index2, index3 ][ index3 ][ hidden ][ ]
- 190. 遍歷網站 ‐ 直到看過所有連結 宣告一個 list 儲存即將要送 request 的網址 決定送 request 的中止條件 190 # 儲存即將要送 request 的網址 wait_list = ['https://afuntw.github.io/demo‐ crawling/demo‐page/ex1/index1.html'] # 當 wait list 裡還有網址的時候... while wait_list != []: # 送 request 的流程
- 191. 遍歷網站 ‐ 更新 wait_list 清單 從 wait_list 中取出網址 從 wait_list 中刪除已經取出的網址 從 wait_list 中放入新的網址 191 # 從 wait_list 中取出第一個網址並更新 url = wait_list.pop(0) # 從 wait_list 中放入新的網址 wait_list.append(new_url)
- 192. 練習 03: 取得真正的所有標題 (5~8 mins) 目標程式:03_crawling_demo1_hidden.py 目標網站:demo_website_1 目標:透過超連結不斷爬取多個網頁的 h1 tag 將需要送 request 的超連結存入等待清單 不斷的拿等待清單的超連結送 request 192
- 194. 遍歷網站的迴圈問題 194 wait list About Contact wait list Contact wait list Contact Home Contact 1. wait list 有重複 URL 2. 打算對 Home 重複存取
- 195. 解決遍歷網站的迴圈問題 建立一個已經送過 request 的清單 viewed_list wait_list 裏面也不能有重複的 URL 195 viewed_list = [] # 將送過 request 的網址存入 viewed_list viewed_list.append(url) # 檢查新網址沒有出現在 wait_list 與 viewed_list if new_url not in wait_list and new_url not in viewed_list: wait_list.append(new_url)
- 196. 練習 04: 避免迴圈問題 (5~8 mins) 目標程式:04_crawling_demo2_no_infinite.py 目標網站:demo_website_2 目標:避免無窮迴圈的爬取網站的 h1 tag 將需要送 request 的超連結存入等待清單 紀錄送過的 request 196 root index1 index2 index3 hidden
- 197. Summary 圖片爬蟲 & 檔案爬蟲 如果下載檔案被拒絕可以嘗試加上 User‐Agent 必要時下載圖片要檢查格式 送 request 之前記得確認路徑是否為絕對路徑 網站爬蟲 超連結網頁裡的超連結網頁也要送 request 紀錄存取過的網頁 197
- 198. Outline 靜態網頁以外的爬蟲 圖片爬蟲 檔案爬蟲 網站爬蟲 現實世界的爬蟲 現代網站爬蟲衍生的問題 動態網頁爬蟲 198
- 200. 你對 href 夠了解嗎? 對 anchor 送出 request 會拿到同樣的頁面 網頁一般只會用 HTTP 或是 HTTPS 協定 無法對程式碼送出 request 200 href 可能的值 敘述 範例 absolute URL 絕對路徑 https://gushi.tw/ relative URL 相對路徑 /ex1/html1.html anchor 同一頁面的其他 tag #top other protocols 其他協定 mailto://[email protected] JavaScript 程式碼 javascript:console.log(“Hello”)
- 201. 過濾 href 201 import re # 過濾錨點, e.g. #top check_url_1 = re.match('#.*', url) # True/False # 過濾其他協定, 只接受 http/https from urllib.parse import urlparse check_url_2 = urlparse(url).scheme not in ['https', 'http'] # 過濾程式碼, e.g. javascript:alert(); check_url_3 = re.match('^javascript.*', url)
- 202. 練習 05: 過濾 href (5~10 mins) 目標程式:05_crawling_demo3_filter_href.py 目標網站:demo_website_3 目標:過濾不必要的超連結並取得網站的所有 h2 tag 判斷過濾不必要的超連結的時機 urljoin 前還是後? 202 # 觀察下列的值並嘗試送出 request anchor = urljoin(url, '#top') protocol = urljoin(url, 'mailto:[email protected]') code = urljoin(url, 'javascript:alert("Hi");')
- 203. 符合絕對路徑的 url 一定沒問題? 符合絕對路徑的 URL 可以送 request 可以送 request 的 URL 不代表是你需要的 203
- 204. 使用 urlparse 的極限 urlparse 可分析的 URL 片段 shceme://netloc/path;params?query#fragment e.g. http://www.facebook.com/twdsconf 完全不一樣的網站仍然可透過判斷 netloc 決定 若是網站有子網站就會被忽略 204
- 205. 子網域, 網域與後綴 透過 urlparse 取得的 netloc 可以再拆解 netloc = 子網域.網域.後綴 e.g. www.facebook.com 205 子網域 網域 後綴 台大首頁 http://www.ntu.edu.tw 台大中文 http://www.cl.ntu.edu.tw 台大法律 http://www.law.ntu.edu.tw 台大化工 http://www.che.ntu.edu.tw ...
- 206. 透過 tldextract 分析網域 將 netloc 分段成子網域.網域.後綴並不是單純透 過 “.” 來切割字串就好 不同的網站可以用 netloc 或是 domain 判斷 子網站用 netloc 無法判斷 206
- 207. 練習 06: 檢查域名 (5~8 mins) 目標程式:06_crawling_demo4_extract_domain.py 目標網站:demo_website_4 目標:分析網域,只對 www 或是跟原本網址一樣的 sub domain 送出 request 過濾不必要的超連結後再分析域名 207 # 延伸思考:短網址或是路徑為 ip 拆解的結果? from tldextract import extract print(extract('https://goo.gl/z321G7')) print(extract('https://127.0.0.1:80'))
- 208. Bonus: Google 短網址服務 網站轉址無法透過 URL 判斷是否屬於相同的網域 需要送一次 request 再從回傳的 response 中取得 原始 URL 208 from tldextract import extract extract_url = extract(url) # 判斷是否為 google 短網址 if extract_url.domain == 'goo' or extract_url.suffix == 'gl': response = requests.get(extract_url) print(response.url)
- 209. 爬網站的重點回顧 若是要尋訪所有網頁, 要不斷對找到的網址送 request,並且紀錄尋訪過的網址 href 的值要經過過濾,取出符合網址格式 分析網址格式與域名確認識自己想要爬的網頁 209
- 210. Outline 靜態網頁以外的爬蟲 圖片爬蟲 檔案爬蟲 網站爬蟲 現實世界的爬蟲 現代網站爬蟲衍生的問題 動態網頁爬蟲 210
- 212. 靜態網頁 vs. 動態網頁 透過 requests.get 拿到的是靜態網頁 檢視網頁原始碼看到的是靜態網頁 開發者工具 (inspect) 看到的是動態網頁 212 靜態網頁 動態網頁
- 213. 檢查網頁是靜態還是動態 Chrome extension (Quick Javascript Switcher) 透過工具的開關檢查頁面是否有變化 213 關掉 JavaScript 打開 JavaScript
- 214. 取得程式更新後的網頁 送出 request 之後等到網頁 loading 完成再要求回 傳網頁 214
- 215. 模擬使用者操作瀏覽器的行為 Selenium 本來是網頁自動測試工具 Selenium 經常被拿來處理動態網頁爬蟲 因為是模擬操作瀏覽器,速度上會比靜態網頁慢 215 from selenium import webdriver # 透過指定的瀏覽器 driver 打開 Chrome driver = webdriver.Chrome('../webdriver/chromedriver') # 透過瀏覽器取得網頁 driver.get('https://afuntw.github.io/demo‐ crawling/demo‐page/ex4/index1.html')
- 217. 瀏覽器視窗最大化 一開始打開瀏覽器的時候並非視窗最大化 建議一般使用情況都先將瀏覽器視窗最大化 217 from selenium import webdriver # 透過指定的瀏覽器 driver 打開 Chrome driver = webdriver.Chrome('../webdriver/chromedriver') # 將瀏覽器視窗最大化 driver.maximize_window()
- 218. Selenium 定位 tag 大致上與 Beautifulsoup 定位 tag 的方法相似 find_element_by_id() find_element_by_tag_name() find_element_by_class_name() ... 218 # e.g. 取得 id='first' 的 tag id_tag = drver.find_element_by_id('first') print(id_tag)
- 219. 練習 07: 靜態與動態爬蟲的差異 (5 mins) 目標程式:07_crawling_demo4_selenium.py 目標網站:demo_website_4 目標:分別透過 requests 與 Selenium 爬網站上 id = 'first' 的 tag 開啟瀏覽器並且將視窗最大化 透過 Selenium 定位 tag 並取得文字資料 219 >>> requests: First featurette heading. It'll blow your mind. >>> selenium: Rendered by Javascript
- 220. 了解 tag 之間的關係 book 是 title 與 author 的 parent title 與 author 都是 book 的 child 220 <bookstore> <book> <title>Harry Potter</title> <author>K. Rowling</author> </book> </bookstore>
- 221. 了解 tag 之間的關係 title 與 author 各自為對方的 sibling bookstore, book 都是 title 與 author 的 ancestors book, title, author 都是 bookstore 的 descendant 221 <bookstore> <book> <title>Harry Potter</title> <author>K. Rowling</author> </book> </bookstore>
- 222. Selenium 定位 tag ‐ XPath Selenium 還可透過類似路徑寫法的 XPath 定位 tag 222 語法 意義 / 從 root 開始選擇 // 從任何地方開始選擇 . 選擇當下這個 node .. 選擇當下這個 node 的 parent node @ 選擇 attribute * 選擇任何 node | OR
- 224. XPath 範例 Beautifulsoup 寫法 soup.find_all('div')[2].find_all('div')[0] 224 from selenium import webdriver # 打開瀏覽器, 視窗最大化, 對目標網址送 request... # 尋找一個 html > body > div[2] > div[0] h2 = driver.find_element_by_xpath( '/html/body/div[2]/div[0]')
- 225. XPath 範例 225 from selenium import webdriver from selenium.webdriver.common.by import By # 打開瀏覽器, 視窗最大化, 對目標網址送 request... # 尋找網頁中所有的 p tag p = driver.find_elements(By.XPATH, '//p') 透過 By 可以更簡單更換定位方式
- 226. XPath 範例 226 from selenium import webdriver from selenium.webdriver.common.by import By # 尋找任何一個 id = 'first' 的 tag h2 = driver.find_element(By.XPATH, '//*[@id="first"]') # 尋找網頁中 id = 'second' 或 'third' 的 h2 tag p = driver.find_elements(By.XPATH, '//h2[@id="second"] | //h2[@id="third"]')
- 228. 透過開發者工具取得 XPath 228
- 229. 練習 08: 透過 XPath 做動態爬蟲 (10 mins) 目標程式:08_crawling_pchome_selenium.py 目標網站:http://24h.pchome.com.tw/region/DHBE 目標:取得頁面上調列商品的名稱與價格 (30 項) 229
- 230. Summary 現代網站爬蟲衍生的問題 過濾非必要的 href 解析網域判斷是否要存取該網頁 動態網頁 透過 Selenium 取得程式改變後的網頁結構 透過 XPath 定位 tag 230
- 231. 爬蟲不一定要爬網頁 有 API (Application Programming Interface) 的話就 透過 API 做爬蟲 (e.g. Facebook Graph API) 231
- 232. 沒有絕對的爬蟲 具有價值的資料, 公司不希望不斷被爬蟲紀錄 反爬蟲核心思想 判斷 request 是人類還是程式發出來的 誤判情形決策 要防止多大規模的爬蟲程式? 232
- 233. 常見的反爬蟲策略 透過網站後端判斷真人與程式 User‐Agent Cookie Referrer 檢測, 判斷 request 從哪裡來 帳號/密碼 驗證碼 IP 限制存取次數 233
- 234. 常見的反反爬蟲策略 逼近真人的程式行為 送 request 時夾帶使用者訊息 更改 IP 深度學習/ OCR 檢測驗證碼 234
- 235. 沒有絕對的反反爬蟲 爬蟲方願意花多少時間與資源去爬資料? 反爬蟲方願意花多少時間與資源去保護資料? 透過後端判斷人類與程式 透過前端增加爬蟲難度 235
- 236. 案例分享 ‐ 天貓電影 透過 CSS 的 font‐face 搭配不同的字典檔 透過 tag 爬取分數只會拿到亂碼 每次重新 render 都會有不一樣的字典檔 236 Reference: Litten ‐ 反击爬虫,前端工程师的脑洞可以有多大?
- 237. 案例分享 – 汽車之家 重要訊息透過 css render 237 Reference: Litten ‐ 反击爬虫,前端工程师的脑洞可以有多大?
- 238. 案例分享 – 去哪兒 透過錯誤的 tag 順序搭配 css 算出正確顯示位置 238 Reference: Litten ‐ 反击爬虫,前端工程师的脑洞可以有多大?
- 239. 案例分享 – 去哪兒手機板 透過重新定義字典檔改變顯示資訊 239 Reference: Litten ‐ 反击爬虫,前端工程师的脑洞可以有多大?
- 240. 案例分享 – 去哪兒手機板 透過重新定義字典檔改變顯示資訊 240 Reference: Litten ‐ 反击爬虫,前端工程师的脑洞可以有多大?
- 241. 爬蟲在深度學習上的應用 2017 台灣資料科學年會 ASAP 電商比價爬蟲 自動化靜態網站爬蟲 自我學習 DOM 架構 電商爬蟲的困難 通用性 即時性 自適性 241
- 242. Reference 維基 User Agent 詳細格式說明 href 定義 XPath cheat sheet Selenium 文件 反击爬虫,前端工程师的脑洞可以有多大? 242