






![クローリング
• 英語の意味は、[ はう、ゆっくり進む]
• Webページのリンクの内容をたどる
• Webページの内容をダウンロードして収集
• クローラー、スパイダーと呼ばれる](https://image.slidesharecdn.com/pythonweb-140823055727-phpapp01/85/Python-Web-7-320.jpg)
![スクレイピング
• 英語の意味は、[ 削ること ]
• ページの内容から、必要な情報を抽出すること](https://image.slidesharecdn.com/pythonweb-140823055727-phpapp01/85/Python-Web-8-320.jpg)

























![Spider作成
class MininovaSpider(CrawlSpider):
name = 'mininova'
allowed_domains = ['mininova.org']
start_urls = ['http://www.mininova.org/yesterday/']
rules = [Rule(LinkExtractor(allow=['/tor/d+']), parse_torrent')]
!
def parse_torrent(self, response):
torrent = TorrentItem()
torrent['url'] = response.url
torrent['name'] = response.xpath("//h1/text()").extract()
return torrent](https://image.slidesharecdn.com/pythonweb-140823055727-phpapp01/85/Python-Web-37-320.jpg)
![実行
$ scrapy crawl mininova -o scraped_data.json
$ cat scraped_data.json
{
"url": "http://www.mininova.org/tor/13277197",
"name": ["lady anna voice free plugin VSTI free download new by Softrave ]
},
{
"url": "http://www.mininova.org/tor/13277195",
"name": ["mandala VSTI free download new by Softrave ]
},](https://image.slidesharecdn.com/pythonweb-140823055727-phpapp01/85/Python-Web-38-320.jpg)





More Related Content




































































PythonによるWebスクレイピング入門
- 2. 自己紹介 • 関根裕紀(せきね ひろのり) • アライドアーキテクツ株式会社 • ソフトウェア・エンジニア • PyCon JP 2014 スタッフ • Twitter(@checkpoint )
- 3. • 前職まで • RSSリーダー、SNS • WebMail • 写真共有サービス • 現在(アライドアーキテクツ) • モニプラFacebook、Social-IN • Webアプリケーション開発全般を担当 経歴
- 4. アジェンダ • Webスクレイピングとは • PythonでのWebスクレイピング • ライブラリの紹介、サンプル(入門編)
- 6. Webスクレイピング • WebサイトからHTMLのデータを収集 • 特定のデータを抽出、加工 • 抽出したデータを再利用 • クローリング + スクレイピング
- 7. クローリング • 英語の意味は、[ はう、ゆっくり進む] • Webページのリンクの内容をたどる • Webページの内容をダウンロードして収集 • クローラー、スパイダーと呼ばれる
- 8. スクレイピング • 英語の意味は、[ 削ること ] • ページの内容から、必要な情報を抽出すること
- 9. 用途 • 検索エンジン • 価格比較 • 気象データの監視 • サイトの変更検出 • Webサイトの情報解析、研究(比較、分類、統計など) • マッシュアップ
- 10. 方法(1) • Webサービス、アプリケーション • Yahoo! Pipes( https://pipes.yahoo.com/ ) • kimono ( https://www.kimonolabs.com/ ) • import.io ( https://import.io/ )
- 11. 方法(2) • Ruby • Nokogiri • Mechanize • Perl • Web::Scraper • JavaScript • CasperJS
- 12. Pythonでのスクレイピング • 標準ライブラリ • BeautifulSoup • pyquery • Scrapy(スクレピー、スクラパイ、スクレパイ)
- 14. 標準ライブラリ • Pythonの標準ライブラリはとても充実している • ネットワーク、正規表現ライブラリ • Pythonの処理系だけあれば良い • 簡単なスクレイピングであれば十分実用的
- 15. サンプル import re, urllib2 res = urllib2.urlopen( http://ll.jus.or.jp/2014/program") pattern_title = re.compile( <title>(.*?)</title>') m = pattern_title.search(res.read()) title = m.group(1) print title >>> プログラム ¦ LL Diver
- 16. Beautiful Soup • 2004年からあるライブラリ • HTMLやXMLからデータを抽出して取得できる • 複数のパーサーに対応、パーサーを指定できる • 最新バーションはBeautiful Soup 4系 • Python 2.7、Python 3.2に対応 • スクレイピング
- 17. サンプル import urllib2 from bs4 import BeautifulSoup res = urllib2.urlopen( http://ll.jus.or.jp/2014/program ) soup = BeautifulSoup(res.read()) soup.title >>> <title>プログラム ¦ LL Diver</title> for link in soup.find_all( a'): print(link.get( href')) >>> http://ll.jus.or.jp/2014/ >>> http://ll.jus.or.jp/2014/
- 18. pyquery • jQuery風にHTML/XML操作が可能 • パーサーにはlxmlを使用(高速) • JQuery風のセレクタを利用できる • スクレイピング
- 19. サンプル from pyquery import PyQuery as pq d = pq("http://ll.jus.or.jp/2014/program") print d( title").text() >>> プログラム ¦ LL Diver print d( .entry-title").text() >>> プログラム print d( #day ).text() >>> 昼の部
- 21. Scrapyの特徴 • クローリング、スクレイピングフレームワーク • シンプル、拡張性がある • バッテリー付属 • ドキュメント、テストが充実 • コミュニティが活発 • Python2.7のみ対応
- 22. Scrapyの主な機能 • Webページからの情報抽出 • Robots.txtのパース • ドメイン、IPアドレス単位のクロール間隔調整 • 並行処理 • エラー時のリトライ(回数を設定) • http://orangain.hatenablog.com/entry/scrapy
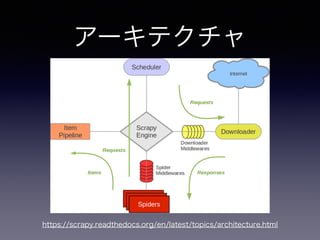
- 25. Scrapy Engine • 全てのコンポーネントを制御するシステム • 特定のアクションが発生したら、イベントを起 こす責任を持つ。
- 27. Spider • ユーザーが作成するカスタムクラス • 取得したいURL、抽出する項目などを記述する • 取得した内容をスクレイピングして、Itemとし てItem Pipelineに送る
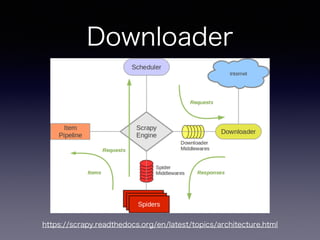
- 31. Downloader • 実際にWebページを取得する • Downloader middlewaresで処理を差し込む事 ができる。(キャッシュなど)
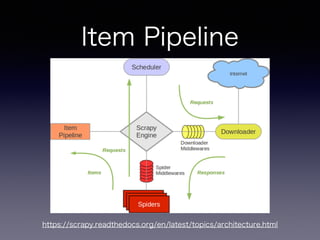
- 33. Item Pipeline • スパイダーによって抽出されたアイテムを出力 • データのクレンジング、検証 • 永続化(JSON、File、DB、Mail)など
- 34. 手順 • Scrapy プロジェクトの作成 • 抽出するアイテムの定義 • アイテムの抽出とクローリングのためのSpider を作成 • 抽出したアイテムのパイプライン部分作成 • 基本はSpiderとItem部分を書いていけばOK
- 35. プロジェクト作成 $ scrapy startproject scrapy_sample $ tree scrapy_sample scrapy_sample/ ├── scrapy.cfg └── scrapy_sample ├── __init__.py ├── items.py ├── pipelines.py ├── settings.py └── spiders └── __init__.py
- 36. 抽出するItem定義 class TorrentItem(scrapy.Item): url = scrapy.Field() name = scrapy.Field()
- 37. Spider作成 class MininovaSpider(CrawlSpider): name = 'mininova' allowed_domains = ['mininova.org'] start_urls = ['http://www.mininova.org/yesterday/'] rules = [Rule(LinkExtractor(allow=['/tor/d+']), parse_torrent')] ! def parse_torrent(self, response): torrent = TorrentItem() torrent['url'] = response.url torrent['name'] = response.xpath("//h1/text()").extract() return torrent
- 38. 実行 $ scrapy crawl mininova -o scraped_data.json $ cat scraped_data.json { "url": "http://www.mininova.org/tor/13277197", "name": ["lady anna voice free plugin VSTI free download new by Softrave ] }, { "url": "http://www.mininova.org/tor/13277195", "name": ["mandala VSTI free download new by Softrave ] },
- 39. まとめ • Pythonでスクレイピングを行う場合、色々なア プローチがある。 • 標準のライブラリから、フレームワークまで選 択肢は沢山あるので、要件に合わせて使用すれ ば良い • Pythonに限らず、LL言語はスクレイピング用の ライブラリがたくさん。
- 40. 参考URL • http://scrapy.org ( Scrapy ) • http://www.slideshare.net/MasayukiIsobe/web-scraping-20140622isobe • https://github.com/gawel/pyquery/ ( pyquery ) • http://www.crummy.com/software/BeautifulSoup/ ( BeautfulSoup ) • http://orangain.hatenablog.com/entry/scrapy • http://akiniwa.hatenablog.jp/entry/2013/04/15/001411 • http://tokyoscrapper.connpass.com/ ( Webスクレイピング勉強会 ) • http://www.slideshare.net/nezuQ/web-36143026?ref=http://www.slideshare.net/slideshow/ embed_code/36143026 • http://qiita.com/nezuq/items/c5e827e1827e7cb29011( 注意事項 )
- 41. 宣伝 • PyCon JP 2014は来月開催です。
- 42. 宣伝 • https://pycon.jp/2014/ • 9/12 (金)∼ 9/15(月)の4日間 • チュートリアル(9/12) • カンファレンス(9/13、14) • スプリント(9/15) • 絶賛準備中。お待ちしております!
- 43. ご静聴ありがとうございました。