Random forest and decision tree
Download as PPTX, PDF1 like494 views

The document provides a comprehensive overview of decision trees and random forests, essential supervised machine learning algorithms used for classification and regression tasks. It discusses their definitions, advantages, disadvantages, and challenges in building decision trees, as well as methods to avoid overfitting. The document also includes hands-on examples of implementing decision trees and random forests using Python and their respective libraries.






















![Hands-On Decision Tree
path = clf.cost_complexity_pruning_path(X_train, y_train)
ccp_alphas, impurities = path.ccp_alphas, path.impurities
ccp_alphas
clfs = []
for ccp_alpha in ccp_alphas:
clf = DecisionTreeClassifier(random_state=0, ccp_alpha=ccp_alpha)
clf.fit(X_train, y_train)
clfs.append(clf)
print("Number of nodes in the last tree is: {} with ccp_alpha: {}".format(
clfs[-1].tree_.node_count, ccp_alphas[-1]))
train_scores = [clf.score(X_train, y_train) for clf in clfs]
test_scores = [clf.score(X_test, y_test) for clf in clfs]
fig, ax = plt.subplots()
ax.set_xlabel("alpha")
ax.set_ylabel("accuracy")
ax.set_title("Accuracy vs alpha for training and testing sets")
ax.plot(ccp_alphas, train_scores, marker='o', label="train",
drawstyle="steps-post")
ax.plot(ccp_alphas, test_scores, marker='o', label="test",
drawstyle="steps-post")
ax.legend()
plt.show()](https://image.slidesharecdn.com/randomforestanddecisiontree-211122135714/85/Random-forest-and-decision-tree-24-320.jpg)







Random forest and decision tree
- 1. Machine Learning Decision Tree and Random Forest
- 2. Machine Learning • Introduction • What is ML, DL, AL? • Decision Tree Definition Why Decision Tree? Basic Terminology Challenges • Random Forest Definition Why Random Forest How it works? • Advantages & Disadvantages
- 3. Machine Learning According to Arthur Samuel (1950) “Machine Learning is a field of study that gives computers the ability to learn without being explicitly programmed”. Machine learning is a study and design of algorithms which can learn by processing input (learning samples) data. The most widely used definition of machine learning is that of Carnegie Mellon University Professor Tom Mitchell: “A computer program is said to learn from experience ‘E’, with respect to some class of tasks ‘T’ and performance measure ‘P’ if its performance at tasks in ‘T’ as measured by ‘P’ improves with experience ‘E’”.
- 5. Decision Tree & Random Forest • Decision Tree Definition Why Decision Tree? Basic Terminology Challenges • Random Forest Definition Why Random Forest How it works?
- 6. Decision Tree Decision tree is a supervised machine learning algorithm which can be used for classification as well as for regression problems. It represent the target on its leaf nodes as a result or inferring's with a tree like structure Why Decision Tree? Helpful in solving more complex problem where a linear prediction line does not perform well Gives wonderful graphical presentation of each possible results Decision Tree & Random Forest
- 7. Why Decision Tree? Prediction can be done with a linear regression line Dose(mg) Effectiveness Dose (mg) Age Sex Effect 10 25 F 95 20 78 M 0 35 52 F 98 5 12 M 44 … … … … … … … … … … … … Prediction can not be done with a linear regression line
- 8. Why Decision Tree? Dose (mg) Age Sex Effect 10 25 F 95 20 78 M 0 35 52 F 98 5 12 M 44 … … … … … … … … … … … … Sample dataset Sample Decision Tree
- 9. Decision Tree Root Node Intermediate Node Leaf node Leaf Node Intermediate Node Leaf node Root Node: The top-most node of a decision tree. It does not have any parent node. It represents the entire population or sample Leaf / Terminal Nodes: Nodes that do not have any child node are known as Terminal/Leaf Nodes
- 10. Challenge in building Decision Tree Challenge in building Decision Tree: 1. How to decide splitting Criteria? • Target Variable(Categorical) • Target Variable(Continuous) 2. How to decide depth of decision tree/ when to stop? • Considerably all data points have been covered • Check for node purity/ homogeneity 3. Over fitting • Pre Pruning • Post Pruning
- 11. How to built a decision tree using criteria: How to built a decision tree Love Popcorn Love Soda Gender Love Ice cream Y Y M N Y N F N N Y M Y N Y M Y Y Y F Y Y N F N N N M N Y N M ? Root node?
- 12. How to decide splitting Criteria? 1. Check if target variable if Categorical: Gini Impurity: It indicate the feature purity, less impurity of a feature help it to be a root node or split node Entropy/ Information Gain: Information gain and Entropy are opposite to each other, here entropy indicates the impurity of a feature. That means higher the entropy, lesser the information gain. If information gain of a node is high, higher the chances it become the root node. Chi Square:
- 13. 2. Target Variable(Continuous): • Reduction in variance: When target variable is a continuous type of variable then this method can be used to check variance of feature to decide it will be a splitting node or not. How to decide splitting Criteria?
- 14. How to built a decision tree using criteria(Gini Index/ impurity): How to built a decision tree Love Popcorn Love Soda Gender Love Ice cream Y Y M N Y N F N N Y M Y N Y M Y Y Y F Y Y N F N N N M N Y N M ? Root node?
- 15. G.I. of leaf love popcorn (yes): 0.375 G.I. of leaf love popcorn (no): 0.444 G.I of feature love popcorn: 0.404 G.I. of leaf love Soda (yes): 0.375 G.I. of leaf love Soda (no): 0 G.I of feature love soda: 0.214 G.I. of leaf Gender (Male): 0.5 G.I. of leaf Gender (Female): 0.444 G.I of feature Gender: 0.476 Figure: Feature description with target variable i.e. Love Ice-cream Decision Tree
- 16. Figure: Initial Decision Tree Next node? Decision Tree
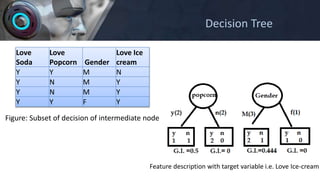
- 17. Love Soda Love Popcorn Gender Love Ice cream Y Y M N Y N M Y Y N M Y Y Y F Y Figure: Subset of decision of intermediate node Feature description with target variable i.e. Love Ice-cream Decision Tree
- 18. G.I. of leaf love popcorn (yes): 0.5 G.I. of leaf love popcorn (no): 0. G.I of feature love popcorn: 0.25 G.I. of leaf Gender (Male): 0.444 G.I. of leaf Gender (Female): 0 G.I of feature Gender: 0.333 Figure: Feature description with target variable i.e. Love Ice-cream Decision Tree
- 19. Love Soda Love Popcorn Gender Love Icecream Y Y M N Y Y F Y Decision Tree
- 20. Figure: Final Decision tree Love Popcorn Love Soda Gender Love Ice cream Y Y M N Y N F N N Y M Y N Y M Y Y Y F Y Y N F N N N M N Y Y M ? Decision Tree
- 21. Decision Tree Over fitting Problem: Decision tree are prune to over fitting because of high variance in outcome produced, it make decision tree results uncertain. It can be overcome with following methods: Pre Pruning: Tune hyper parameters while fitting the feature in decision tree classifier. Post Pruning: Set alpha parameter after preparation of decision tree and prune with CCP alpha parameter.
- 22. Hands-On Decision Tree %matplotlib inline import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.datasets import load_breast_cancer from sklearn.tree import DecisionTreeClassifier X, y = load_breast_cancer(return_X_y=True) X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0) clf = DecisionTreeClassifier(random_state=0) clf.fit(X_train,y_train) pred=clf.predict(X_test) from sklearn.metrics import accuracy_score accuracy_score(y_test, pred)
- 23. Hands-On Decision Tree from sklearn import tree plt.figure(figsize=(15,10)) tree.plot_tree(clf,filled=True)
- 24. Hands-On Decision Tree path = clf.cost_complexity_pruning_path(X_train, y_train) ccp_alphas, impurities = path.ccp_alphas, path.impurities ccp_alphas clfs = [] for ccp_alpha in ccp_alphas: clf = DecisionTreeClassifier(random_state=0, ccp_alpha=ccp_alpha) clf.fit(X_train, y_train) clfs.append(clf) print("Number of nodes in the last tree is: {} with ccp_alpha: {}".format( clfs[-1].tree_.node_count, ccp_alphas[-1])) train_scores = [clf.score(X_train, y_train) for clf in clfs] test_scores = [clf.score(X_test, y_test) for clf in clfs] fig, ax = plt.subplots() ax.set_xlabel("alpha") ax.set_ylabel("accuracy") ax.set_title("Accuracy vs alpha for training and testing sets") ax.plot(ccp_alphas, train_scores, marker='o', label="train", drawstyle="steps-post") ax.plot(ccp_alphas, test_scores, marker='o', label="test", drawstyle="steps-post") ax.legend() plt.show()
- 25. Hands-On Decision Tree clf = DecisionTreeClassifier(random_state=0, ccp_alpha=0.012) clf.fit(X_train,y_train) pred=clf.predict(X_test) from sklearn.metrics import accuracy_score accuracy_score(y_test, pred) from sklearn import tree plt.figure(figsize=(15,10)) tree.plot_tree(clf,filled=True)
- 26. Random Forest: Definition: Random forest is a type of ensemble techniques named as BAGGING(Bootstrap Aggregation). It works on the principal of “Wisdom of Crowd”. Why Random Forest? Random forest are mostly used to overcome the issue of over fitting while using decision tree classifier as it reduces the variance problem of decision tree and produce efficient outcome with maximum accuracy. Random Forest
- 27. How it works? Random Forest
- 28. Decision Tree & Random Forest Decision Tree: Advantages: 1. Simple and easy implementation like IF-ELSE statements 2. Better visualization and understandable 3. Used for Classification as well as for Regression Disadvantages: 1. Over fitting 2. Unstable Results 3. Prone to noisy data 4. Less effective with large dataset
- 29. Decision Tree & Random Forest Random Forest: Advantages: 1. Overcome for problem of over fitting with decision tree 2. Used for Classification as well as for Regression Disadvantages: 1. Higher training time than decision tree 2. Less effective with small dataset 3. Require computation power as well as resources
- 30. Decision Tree & Random Forest References: • https://en.wikipedia.org/wiki/Decision_tree • https://en.wikipedia.org/wiki/Random_forest • https://en.wikipedia.org/wiki/Random_forest#Bagging • https://en.wikipedia.org/wiki/Decision_tree#Association_rule_induction • https://en.wikipedia.org/wiki/Decision_tree#Advantages_and_disadvantages • https://en.wikipedia.org/wiki/Machine_learning • https://en.wikipedia.org/wiki/Machine_learning#Artificial_intelligence • https://en.wikipedia.org/wiki/Machine_learning#Overfitting • https://www.abrisconsult.com/artificial-intelligence-and-data-science/
- 31. Decision Tree & Random Forest