


































Realtime Analytics with Hadoop and HBase
- 1. Realtime Analytics using Hadoop & HBase Lars George, Solutions Architect @ Cloudera [email protected] Monday, July 25, 11
- 2. About Me • Solutions Architect @ Cloudera • Apache HBase & Whirr Committer • Working with Hadoop & HBase since 2007 • Author of O’Reilly’s “HBase - The Definitive Guide” Monday, July 25, 11
- 3. The Application Stack • Solve Business Goals • Rely on Proven Building Blocks • Rapid Prototyping ‣ Templates, MVC, Reference Implementations • Evolutionary Innovation Cycles “Let there be light!” Monday, July 25, 11
- 4. LAMP Monday, July 25, 11
- 5. L Linux A Apache M MySQL P PHP/Perl Monday, July 25, 11
- 6. L Linux A Apache M MySQL M Memcache P PHP/Perl Monday, July 25, 11
- 7. The Dawn of Big Data • Industry verticals produce a staggering amount of data • Not only web properties, but also “brick and mortar” businesses ‣ Smart Grid, Bio Informatics, Financial, Telco • Scalable computation frameworks allow analysis of all the data ‣ No sampling anymore • Suitable algorithms derive even more data ‣ Machine learning • “The Unreasonable Effectiveness of Data” ‣ More data is better than smart algorithms Monday, July 25, 11
- 8. Hadoop • HDFS + MapReduce • Based on Google Papers • Distributed Storage and Computation Framework • Affordable Hardware, Free Software • Significant Adoption Monday, July 25, 11
- 9. HDFS • Reliably store petabytes of replicated data across thousands of nodes ‣ Data divided into 64MB blocks, each block replicated three times • Master/Slave Architecture ‣ Master NameNode contains meta data ‣ Slave DataNode manages block on local file system • Built on “commodity” hardware ‣ No 15k RPM disks or RAID required (nor wanted!) ‣ Commodity Server Hardware Monday, July 25, 11
- 10. MapReduce • Distributed programming model to reliably process petabytes of data • Locality of data to processing is vital ‣ Run code where data resides • Inspired by map and reduce functions in functional programming Input ➜ Map() ➜ Copy/Sort ➜ Reduce() ➜ Output Monday, July 25, 11
- 11. From Short to Long Term Internet LAM(M)P • Serves the Client • Stores Intermediate Data Hadoop • Background Batch Processing • Stores Long-Term Data Monday, July 25, 11
- 12. Batch Processing • Scale is Unlimited ‣ Bound only by Hardware • Harness the Power of the Cluster ‣ CPUs, Disks, Memory • Disks extend Memory ‣ Spills represent Swapping • Trade Size Limitations with Time ‣ Jobs run for a few minutes to hours, days Monday, July 25, 11
- 13. From Batch to Realtime • “Time is Money” • Bridging the gap between batch and “now” • Realtime often means “faster than batch” • 80/20 Rule ‣ Hadoop solves the 80% easily ‣ The remaining 20% is taking 80% of the effort • Go as close as possible, don’t overdo it! Monday, July 25, 11
- 14. Stop Gap Solutions • In Memory ‣ Memcached ‣ MemBase ‣ GigaSpaces • Relational Databases ‣ MySQL ‣ PostgreSQL • NoSQL ‣ Cassandra ‣ HBase Monday, July 25, 11
- 15. HBase Architecture Monday, July 25, 11
- 16. Client Access Monday, July 25, 11
- 17. Auto Sharding Monday, July 25, 11
- 19. HBase Key Design Monday, July 25, 11
- 20. Key Cardinality Monday, July 25, 11
- 21. Fold, Store, and Shift Monday, July 25, 11
- 22. Complemental Design #1 Internet • Keep Backup in HDFS • MapReduce over HDFS • Synchronize HBase LAM(M)P ‣Batch Puts ‣Bulk Import Hadoop HBase Monday, July 25, 11
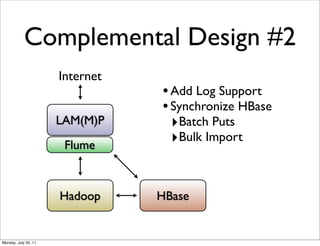
- 23. Complemental Design #2 Internet • Add Log Support • Synchronize HBase LAM(M)P ‣Batch Puts Flume ‣Bulk Import Hadoop HBase Monday, July 25, 11
- 24. Mitigation Planning • Reliable storage has top priority • Disaster Recovery • HBase Backups ‣ Export - but what if HBase is “down” ‣ CopyTable - same issue ‣ Snapshots - not available Monday, July 25, 11
- 25. Complemental Design #3 Internet • Add Log Processing • Remove Direct Connection LAM(M)P • Synchronize HBase ‣Batch Puts Flume ‣Bulk Import Log Hadoop HBase Proc Monday, July 25, 11
- 26. Facebook Insights • > 20B Events per Day • 1M Counter Updates per Second ‣ 100 Nodes Cluster ‣ 10K OPS per Node Web ➜ Scribe ➜ Ptail ➜ Puma ➜ HBase Monday, July 25, 11
- 27. Collection Layer • “Like” button triggers AJAX request • Event written to log file using Scribe ‣ Handles aggregation, delivery, file roll over, etc. ‣ Uses HDFS to store files ✓ Use Flume or Scribe Monday, July 25, 11
- 28. Filter Layer • Ptail “follows” logs written by Scribe • Aggregates from multiple logs • Separates into event types ‣ Sharding for future growth • Facebook internal tool ✓ Use Flume Monday, July 25, 11
- 29. Batching Layer • Puma batches updates ‣ 1 sec, staggered • Flush batch, when last is done • Duration limited by key distribution • Facebook internal tool ✓ Use Coprocessors (0.92.0) Monday, July 25, 11
- 30. Counters • Store counters per Domain and per URL ‣ Leverage HBase increment (atomic read-modify- write) feature • Each row is one specific Domain or URL • The columns are the counters for specific metrics • Column families are used to group counters by time range ‣ Set time-to-live on CF level to auto-expire counters by age to save space, e.g., 2 weeks on “Daily Counters” family Monday, July 25, 11
- 31. Key Design • Reversed Domains, eg. “com.cloudera.www”, “com.cloudera.blog” ‣ Helps keeping pages per site close, as HBase efficiently scans blocks of sorted keys • Domain Row Key = MD5(Reversed Domain) + Reversed Domain ‣ Leading MD5 hash spreads keys randomly across all regions for load balancing reasons ‣ Only hashing the domain groups per site (and per subdomain if needed) • URL Row Key = MD5(Reversed Domain) + Reversed Domain + URL ID ‣ Unique ID per URL already available, make use of it Monday, July 25, 11
- 32. Insights Schema Row Key: Domain Row Key Columns: Hourly Counters CF Daily Counters CF Lifetime Counters CF 6pm 6pm 6pm 7pm 1/1 1/1 2/1 ... 1/1 Total ... Total Male Female US ... Total Male US ... Male US ... 100 50 92 45 1000 320 670 990 10000 6780 3220 9900 Row Key: URL Row Key Columns: Hourly Counters CF Daily Counters CF Lifetime Counters CF 6pm 6pm 6pm 7pm 1/1 1/1 2/1 ... 1/1 Total ... Total Male Female US ... Total Male US ... Male US ... 10 5 9 4 100 20 70 99 100 8 92 100 Monday, July 25, 11
- 33. Summary • Design for Use-Case ‣ Read, Write, or Both? • Avoid Hotspotting ‣ Region and Table • Manage Automatism at Scale ‣ For now! Monday, July 25, 11
- 34. Monday, July 25, 11
- 35. Monday, July 25, 11
- 36. Questions? [email protected] http://cloudera.com Monday, July 25, 11