Azure Brain: 4th paradigm, scientific discovery & (really) big data
1 like1,571 views

The document discusses INRIA's strategic involvement in cloud computing and big data research, emphasizing its multidisciplinary approach and collaborations with industry. Key initiatives include the development of various project teams focused on cloud infrastructure, data management, and high-performance computing. Notable projects mentioned are the A-Brain project leveraging Microsoft Azure for genetic and neuroimaging data analysis, as well as the Blobseer platform for scalable data management.








































![Data access patterns for workflows [1]
[1] Vairavanathan et al.
A Workflow-Aware Storage
System: An Opportunity Study
http://ece.ubc.ca/~matei/paper
s/ccgrid2012.pdf
Pipeline
Caching
Data informed workflow
Input
Output
Broadcast
Replication
Data size
Input
Output
Reduce/Gather
Co-placement of all data
Data informed workflow
Input
Output
Scatter
File size awareness
Data informed workflow
Input
Output
- 47](https://image.slidesharecdn.com/rec201-mstechdays-final-130213033305-phpapp02-130423104418-phpapp01/85/Azure-Brain-4th-paradigm-scientific-discovery-really-big-data-46-320.jpg)











Azure Brain: 4th paradigm, scientific discovery & (really) big data
- 1. Azure Brain: 4th paradigm, scientific discovery & (really) big data (REC201) Gabriel Antoniu Senior Research Scientist, Inria Head of the KerData Project-Team, Inria Rennes – Bretagne Atlantique Radu Tudoran PhD student, ENS Cachan – Brittany KerData Project-Team, Inria Rennes – Bretagne Atlantique Feb. 12, 2013
- 2. INRIA’s strategy in Cloud Computing INRIA is among the leaders in Europe in the area of distributed computing and HPC • Long history of researches around distributed systems, HPC, Grids • Now several activities virtualized environments/cloud infrastructures • Culture of multidisciplinary research • Culture of exploration tools (owner of massively parallel machines since 1987, large scale testbeds such as Grid’5000) • Strong involvement in national, European and international collaborative projects • Strong collaboration history with industry (Joint Microsoft Research – Inria Centre, IBM, EDF, Bull, etc.) - 2
- 3. Clouds: where within Inria ? 1 2 Networks, Systems and Services, Distributed Computing3 Perception, Cognition, Interaction 4 5 Applied Mathematics, Computation and Simulation Algorithmics, Programming, Software and Architecture Computational Sciences for Biology, Medicine and the Environment - 3
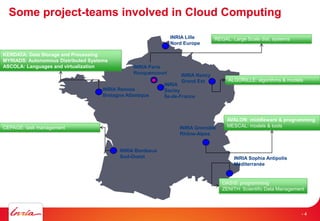
- 4. Some project-teams involved in Cloud Computing INRIA Nancy Grand Est INRIA Grenoble Rhône-Alpes INRIA Sophia Antipolis Méditerranée INRIA Rennes Bretagne Atlantique INRIA Bordeaux Sud-Ouest INRIA Lille Nord Europe INRIA Saclay Île-de-France INRIA Paris Rocquencourt KERDATA: Data Storage and Processing MYRIADS: Autonomous Distributed Systems ASCOLA: Languages and virtualization CEPAGE: task management AVALON: middleware & programming MESCAL: models & tools REGAL: Large Scale dist. systems ALGORILLE: algorithms & models OASIS: programming ZENITH: Scientific Data Management - 4
- 5. Initiatives to support Cloud Computing and HPC within Inria Why dedicated initiatives to support HPC/Clouds ? • Project-teams are geographically dispersed • Project-teams belong to different domains • Researchers from scientific computing need access to the latest research results related to tools, libraries, runtime systems, … • Researchers from “computer science” need access to applications to test their ideas as well as to find new ideas ! Concept of “Inria Large Scale Initiatives” • Enable ambitious projects linked with the strategic plan • Promote an interdisciplinary approach • Mobilizing expertise of Inria researchers around key challenges - 5
- 6. CLOUD COMPUTING@ INRIA RENNES BRETAGNE ATLANTIQUE - 6
- 7. Some Research Focus Areas Software architecture and infrastructure for cloud computing • Autonomic service management, resource management, SLA, sky computing: Myriads • Big Data storage and management, MapReduce: KerData • Hybrid Cloud and P2P systems, privacy: ASAP Advanced usage for specific application communities • Bioinformatics: GENSCALE • Cloud for medical imaging: EasyMed project (IRT B-Com): Visages - 7
- 8. Some Research Focus Areas Software architecture and infrastructure for cloud computing • Autonomic service management, resource management, SLA, sky computing: Myriads • Big Data storage and management, MapReduce: KerData • Hybrid Cloud and P2P systems, privacy: ASAP Advanced usage for specific application communities • Bioinformatics: GENSCALE • Cloud for medical imaging: EasyMed project (IRT B-Com): Visages - 8
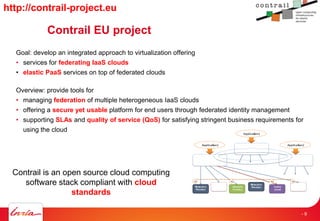
- 9. Contrail EU project Goal: develop an integrated approach to virtualization offering • services for federating IaaS clouds • elastic PaaS services on top of federated clouds Overview: provide tools for • managing federation of multiple heterogeneous IaaS clouds • offering a secure yet usable platform for end users through federated identity management • supporting SLAs and quality of service (QoS) for satisfying stringent business requirements for using the cloud Resource Provider Federa&on)API) +)Fed.)core) Resource Provider Storage( Provider( Public( Cloud( Storage( Provider(Network( Provider( A) A)A) A) Applica&on) Applica&on) Applica&on) Federa&on)API) +)Fed.)core) Federa&on)API) +)Fed.)core) Contrail is an open source cloud computing software stack compliant with cloud standards http://contrail-project.eu - 9
- 11. Open source software under the GNU GPLv2 license http://snooze.inria.fr Other Research Activities on Cloud Computing Snooze: an autonomic energy- efficient IaaS management system Scalability • Distributed VM management system • Self-organizing & self-healing hierarchy Energy conservation • Idle nodes in power-saving mode • Holistic approach to favor idle nodes VM management algorithms • Energy-efficient VM placement • Under-load / overload mitigation • Automatic node power-cycling and wake- up Resilin: Elastic MapReduce on multiple clouds (sky computing) Goals • Creation of MapReduce execution platforms on top of multiple clouds • Elasticity of the platforms • Support all kinds of Hadoop jobs • Support different Hadoop versions Interfaces • Amazon EMR for users • Libcloud with underlying IaaS providers Open source software under GNU Affero GPL license http://resilin.inria.fr - 11
- 12. KerData: Dealing with the Data Deluge Deliver the capability to mine, search and analyze this data in near real time Science itself is evolving Credits: Microsoft 12- 12
- 13. Last few decades The Data Science: The 4th Paradigm for Scientific Discovery Thousand years ago Today and the Future Last few hundred years 2 2 2. 3 4 a cG a a Simulation of complex phenomena Newton’s laws, Maxwell’s equations… Description of natural phenomena Unify theory, experiment and simulation with large multidisciplinary Data Using data exploration and data mining (from instruments, sensors, humans…) Distributed Communities Crédits: Dennis Gannon 13
- 14. Last few decades The Data Science: The 4th Paradigm for Scientific Discovery Thousand years ago Today and the Future Last few hundred years 2 2 2. 3 4 a cG a a Simulation of complex phenomena Newton’s laws, Maxwell’s equations… Description of natural phenomena Unify theory, experiment and simulation with large multidisciplinary Data Using data exploration and data mining (from instruments, sensors, humans…) Distributed Communities 14
- 15. Research Focus: How to efficiently store, share and process data for new-generation, data-intensive applications? • Scientific challenges • Massive data (1 object = 1 TB) • Geographically distributed • Fine-grain access (MB) for reading and writing • High concurrency (10³ concurrent clients) • Without locking - Major goal: high-throughput under heavy concurrency - Our contribution Design and implementation of distributed algorithms Validation with real apps on real platforms with real users • Applications • Massive data analysis: clouds (e.g. MapReduce) • Post-Petascale HPC simulations: supercomputers - 15
- 16. BlobSeer: A Software Platform for Scalable, Distributed BLOB Management Started in 2008, 6 PhD theses (Gilles Kahn/SPECIF PhD Thesis Award in 2011) Main goal: optimized for concurrent accesses under heavy concurrency Three key ideas •Decentralized metadata management •Lock-free concurrent writes (enabled by versioning) - Write = create new version of the data •Data and metadata “patching” rather than updating A back-end for higher-level data management systems •Short term: highly scalable distributed file systems •Middle term: storage for cloud services Our approach •Design and implementation of distributed algorithms •Experiments on the Grid’5000 grid/cloud testbed •Validation with “real” apps on “real” platforms: Nimbus, Azure, OpenNebula clouds… http://blobseer.gforge.inria.fr/ 16- 16
- 17. Impact of BlobSeer: MapReduce BlobSeer improves Hadoop • Gain (execution time) : 35% ANR MapReduce Project (2010-2014) • Lead: G. Antoniu (KerData) • Partners: INRIA (AVALON), Argonne National Lab, U. Illinois Urbana-Champaign, IBM, JLPC, IBCP, MEDIT • Strong collaboration with the Nimbus team from Argonne National Lab - BlobSeer integrated with the Nimbus cloud toolkit - BlobSeer used for efficient VM deployment and snapshotting • Validation : Grid’5000 with Nimbus, FutureGrid (USA), Open Cirrus (USA) http://mapreduce.inria.fr - 17
- 18. The A-Brain Project: Data-Intensive Processing on Microsoft Azure Clouds Application • Large-scale joint genetic and neuroimaging data analysis Goal • Assess and understand the variability between individuals Approach • Optimized data processing on Microsoft’s Azure clouds Inria teams involved • KerData (Rennes) • Parietal(Saclay) Framework • Joint MSR-Inria Research Center • MS involvement: Azure teams, EMIC 18
- 19. Genetic information: SNPs G G T G T T T G G G MRI brain images Clinical / behaviour The Imaging Genetics Challenge: Comparing Heterogeneous Information THere we focus on this link - 19
- 20. Neuroimaging-genetics: The Problem Several brain diseases have a genetic origin, or their occurrence/severity related to genetic factors Genetics important to understand & predict response to treatment Genetic variability captured in DNA micro-array data p( )| Gene→Image geneticimage 20
- 21. Imaging Genetics Methodological Issues Genetic dataBrain image Y ~105-106 ~2000 X ~105-106 – Anatomical MRI – Functional MRI – Diffusion MRI – DNA array (SNP/CNV) – gene expression data – others... - 21
- 22. A BIG DATA Challenge … Azure can help… Data: double permutation voxels SNPs 5%-10% useful Computation: Estimate timespan on single machine Estimation for A-Brain on Azure (350 cores) Storage capacity estimations (350 cores)
- 23. Imaging Genetics Methodological Issues Multivariate methods: predict brain characteristic with many genetic variables Elastic net regularization: combination of ℓ1 and ℓ2 penalties → sparse loadings parameters setting: internal cross-validation/bootstrap Performance evaluated using permutations 23
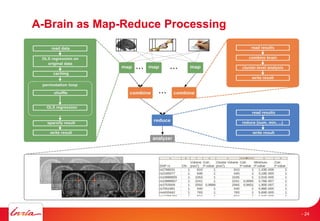
- 24. A-Brain as Map-Reduce Processing - 24
- 25. A-Brain as Map-Reduce Data Processing 25
- 26. Efficient Procedures for Statistics Example : voxelwise Genome Wide Association Studies (vGWAS) 740 subjects ~ 50,000 voxels ~ 500,000 SNPs 10,000 permutations → ~ 12,000 hours of computation → ~ 1.8 Po of statistical scores - 26
- 27. Efficient Procedures for Statistics Example : Ridge regression with cross-validation loops Some costly computations (SVD ~ 60 sec) are used 1-2 millions of times and cannot be kept in memory. ~ 60-120 x 106 sec / SVD (1.9-3.8 years / SVD) → An efficient distributed cache can achieve huge speedup! - 27
- 29. Requirements for a cloud storage / data management High throughput under heavy concurrency Fine grain access Scalability / Elasticity Data availability Transparency Design principles Data locality – use the local storage No modification on the cloud middleware Loose coupling between storage and applications Storage hierarchy - 29
- 30. TomusBlobs - Architecture - 30 Computation nodes
- 31. Architecture contd. System components Initiator - Cloud specific - Generic stub - Properties: Scaling; Self configuration Distributed Storage - Aggregates the virtual disks - Not depending on a specific solution Client API - Cloud specific API - Expose the operation transparently Initiator Local Disk Application Client API TB entity VM snapshot Customizable Environment - 31
- 32. TomusBlobs Evaluation • Scenario: Single reader / writer • Data transfer from memory to storage • Metric: Client IO throughput
- 33. TomusBlobs Evaluation Cumulative read throughput Cumulative write throughput • Scenario: Multiple readers / writers • Throughput limited by bandwidth • Read 4X ; Write 5X - 34
- 34. TomusBlobs as a Storage Backend for Sharing Application Data in MapReduce App API App App App App API API API API TomusBlobs - 35
- 35. TomusMapReduce Evaluation • Scenario: Increase the problem size • Optimize computation by managing better intermediate data - 36
- 36. Iterative MapReduce - Daytona Merge Step In-Memory Caching of static data Cache aware hybrid scheduling using Queues as well as using a bulletin board (special table) Reduce Reduce Merge Add Iteration? No Map Combine Map Combine Map Combine Data Cache Yes Hybrid scheduling of the new iteration Job Start Job Finish Crédits: Dennis Gannon - 37
- 37. Beyond MapReduce • Unique result with parallel reduce phase • No central control entity • No synchronization barrier Map Reducer Map Map Map Map Reducer - 38
- 38. Zoom on the Reduction Ratio • Compute the minimum of a set of large matrixes (7.5 GB) using 30 mappers - 39
- 40. The Most Frequent Words benchmark •Input data size varies from 3.2 GB to 32 GB •ReductionRatio = 5 - 41
- 41. Execution times for A-Brain •Increasing number of map jobs = increasing size of data (5 GB to 50 GB) - 42
- 42. Beyond Single Site processing • Data movements across geo-distributed deployments is costly • Minimize the size and number of transfers • The overall aggregate must collaborate towards reaching the goal • The deployments work as independent services • The architecture can be used for scenarios in which data is produced in different locations - 43
- 43. Towards a Geo-distributed TomusBlobs approach • TomusBlobs for intra- deployment data management • Public Storage (Azure Blobs/Queues) for intra- deployment communication • Iterative Reduce technique for minimizing number of transfers (and data size) • Balance the network bottleneck from single data center - 44
- 44. Multi-Site MapReduce • 3 deployments (NE,WE,NUS) • 1000 CPUs • ABrain execution across multiple sites - 45
- 45. Beyond MapReduce - Workflow Processing - 46
- 46. Data access patterns for workflows [1] [1] Vairavanathan et al. A Workflow-Aware Storage System: An Opportunity Study http://ece.ubc.ca/~matei/paper s/ccgrid2012.pdf Pipeline Caching Data informed workflow Input Output Broadcast Replication Data size Input Output Reduce/Gather Co-placement of all data Data informed workflow Input Output Scatter File size awareness Data informed workflow Input Output - 47
- 48. Generic Worker Walkthrough (Microsoft ATLE) Local storage Client code Researcher Job Management Service Algorithm HD GW Driver Pluggable Runtime Environment Runtime Business Logic Job Details Table Job Index Table Notification Listeners (Accounting, Status Change, etc..) BLOB Storage Notification Service Scaling Service OGF BES VM SOAP WS–* Use of interoperable standard protocols and data schemas! OGF JSDL Application Code GW Services & SDKs Existing Components Input Files Output Files Shared Storage - 49 Credits: Microsoft
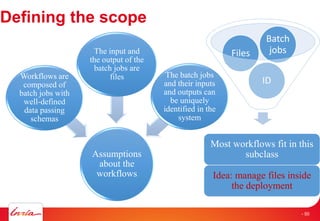
- 49. Defining the scope ID Files Batch jobs Assumptions about the workflows Workflows are composed of batch jobs with well-defined data passing schemas The input and the output of the batch jobs are files The batch jobs and their inputs and outputs can be uniquely identified in the system Most workflows fit in this subclass Idea: manage files inside the deployment - 50
- 50. The Concept File Name Locations F1 VM1 F2 VM1,VM2 F3 VM2 VM 1 VM 2 Local Disk Local Disk F1F2 F3 Transfer Module File Metadata Registry (1) Register (F1,VM1) (2) GetLocation(F1) (3) DownloadFile(F1) F1 F2 • Metadata Registry • Transfer Module Components Transfer Module - 51
- 51. Characteristics of the components Metadata Registry Transfer Module Role • Transfer files from one node to another Data type • Files Accessibility • Each VM has such a module • Applications access the local module • The modules interact across nodes Solutions • FTP; Torrent; InMemory, HTTP etc. Role •Hold the location of files within the deployment Data type •Key-value pairs – (file identification; retrieval information) Accessibility •Accessible by all nodes Solutions •Azure Caching Preview, Azure Tables, InMemory DB Idea: Adopt multiple transfer solutions Adapt to the context: select the one that fits best - 52
- 52. Transfer methods Method Observations InMemory • Caching data • InMemory data offers fast access • GBs of memory capacity per deployment • Small files BitTorrent • Replicas for file dissemination • Collaborative reads • New way of stage-in data FTP • TCP transfer • Medium and large files • Potential of inter-operability - 53
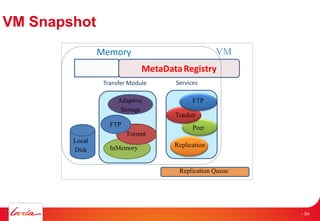
- 53. VM Snapshot VMMemory MetaDataRegistry Adaptive Storage FTP Torrent InMemory Transfer Module Services Replication Queue Replication FTP Tracker Peer Local Disk - 54
- 54. F1 Azure Caching Adaptive Storage Adaptive Storage App App F1 Create Upload(F1) GetMetadata Read(F1) Memory Memory Local Storage Local Storage Read (F1) WriteMetadata Write(F1) Download (F1) API API - 55
- 55. Scenario 2 – Large files ; replication enabled 0 10 20 30 40 50 60 70 80 50 100 150 200 250 Time(sec) Size of a single file (MB) DirectLink Torrent Adaptive AzureBlobs • Torrents are superior for broadcast when replicas are used • DirectLink is faster for pipeline (reduction tree) • Adaptive storage can chose each time the best strategy - 56
- 56. NCBI Blast for Azure Seamless Experience • Evaluate data and invoke computational models from Excel. • Computationally heavy analysis done close to large database of curated data. • Scalable for large, surge computationally heavy analysis. selects DBs and input sequence Web Role Input Splitter Worker Role BLAST Execution Worker Role #n…. Combiner Worker Role Genome DB 1 Genome DB K BLAST DB Configuration Azure Blob Storage BLAST Execution Worker Role #1 Crédits: Dennis Gannon - 57
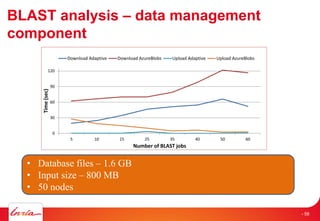
- 57. BLAST analysis – data management component 0 30 60 90 120 5 10 15 25 35 40 50 60 Time(sec) Number of BLAST jobs Download Adaptive Download AzureBlobs Upload Adaptive Upload AzureBlobs • Database files – 1.6 GB • Input size – 800 MB • 50 nodes - 58
- 58. Scalable Storage on Clouds: Open Issues Understanding price-performance trade-offs • Consistency, availability, performance, cost, security, quality of service, energy consumption • Autonomy, adaptive consistency • Dynamic elasticity • Trade-offs exposed to the user High performance variability - Understand it, model it, cope with it Deployment/application launching time is high Latency of data accesses is still an issue Data movements are expensive Cope with tightly-coupled applications Cope with various cloud programming models Virtualization overhead Benchmarking Performance modeling Self-optimization for cost reduction - Elastic scale down Security and privacy - 59
- 59. Extreme scale does matter BUT not only Other focus areas – Affordability and usability of intermediate size systems – Pervasiveness of usage across the entire industry, including Small and Medium Enterprises (SMEs) and ISVs – New HPC deployments (e.g. Big Data, HPC in Clouds) – HPC and Cloud usage expansion, fostering the development of consultancy, expertise and service business / end-user support – Facilitating the creation of start-ups and the development of the SME sector (hw/sw supply side) – Education and training (inc. engineering skills for industry) Cloud Computing@INRIA Strategic Research Agenda - 60
- 60. - 61 Azure Brain: 4th paradigm, scientific discovery & (really) big data (REC201) Gabriel Antoniu Senior Research Scientist, Inria Head of the KerData Project-Team, Inria Rennes – Bretagne Atlantique Radu Tudoran PhD student, ENS Cachan – Brittany KerData Project-Team, Inria Rennes – Bretagne Atlantique Contacts: [email protected], [email protected]