









































Recurrent neural networks for sequence learning and learning human identity from motion patterns
- 1. Review of Recurrent Neural Networks for Sequence Learning 16.08.05 You Sung Min Paper review Neverova, Natalia, et al. "Learning human identity from motion patterns." IEEE Access 4 (2016): 1810-1820.
- 2. 1. Sequence Learning 2. Architecture of Neural Networks - Recurrent Neural Networks - Long Short-Term Memory 3. Paper Review (Learning Human Identity From Motion Patterns) Contents
- 3. Sequence Labelling All tasks where sequences of data are transcribed with sequence of discrete labels Sequence Learning Handwritten String (Images) Speech Signal (Time-series)
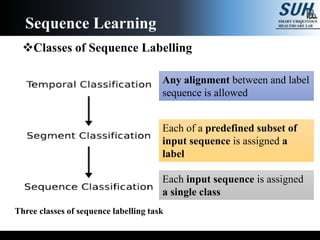
- 4. Classes of Sequence Labelling Sequence Learning Three classes of sequence labelling task Each input sequence is assigned a single class Each of a predefined subset of input sequence is assigned a label Any alignment between and label sequence is allowed
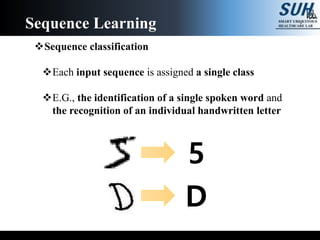
- 5. Sequence classification Each input sequence is assigned a single class E.G., the identification of a single spoken word and the recognition of an individual handwritten letter Sequence Learning 5 D
- 6. Segment classification Each of a predefined subset of input sequence is assigned a label Tasks where the target sequence consist of multiple labels, but the location of the label (i.e., the alignment) are known in advance E.G., the natural language processing The use of context information is crucial Sequence Learning defence
- 7. Temporal classification Any alignment between and label sequence is allowed In most general case, nothing can be assumed about the label sequence Therefore, it requires an algorithm that can decide where in the input sequence the classifications should be made Usually combine generative models (e.g., Hidden Markov Model(HMMs)) Sequence Learning
- 8. Multilayer Perceptrons (MLP) A multilayer perceptron Forward Pass Backward Pass Error backpropagation Architecture of Neural Networks
- 9. Recurrent Neural Networks (RNNs) RNNs allows cyclic connections The recurrent connections allow a ‘memory’ of previous input to persist in the network’s internal state Architecture of Neural Networks
- 10. Unfolding To visualize RNNs by considering the update graph along the input sequence An unfolded recurrent network Output Layer Input Layer Hidden Layer (Folded) RNN Architecture of Neural Networks
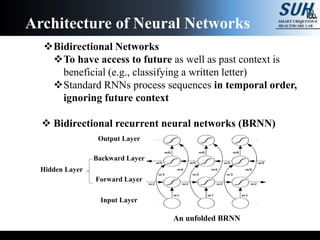
- 11. Bidirectional Networks To have access to future as well as past context is beneficial (e.g., classifying a written letter) Standard RNNs process sequences in temporal order, ignoring future context Bidirectional recurrent neural networks (BRNN) An unfolded BRNN Backward Layer Forward Layer Output Layer Input Layer Hidden Layer Architecture of Neural Networks
- 12. Casual Tasks Bidirectional networks violate causality For task that unable to access future inputs(e.g., prediction or real-time tasks), BRNNs is unfeasible BRNNs can be applied to temporal task, as long as the network output are only need at the end of some input segment Some tasks where the data is divided up in to some subsets, each of which is completely processed before output labelling is required. (e.g., speech and handwriting recognition) Architecture of Neural Networks
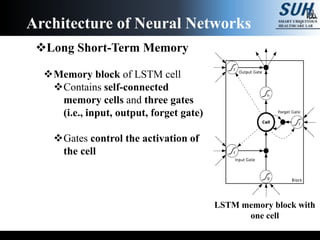
- 13. Long Short-Term Memory Memory block of LSTM cell Contains self-connected memory cells and three gates (i.e., input, output, forget gate) Gates control the activation of the cell Architecture of Neural Networks LSTM memory block with one cell
- 14. LSTM Networks Architecture of Neural Networks An LSTM networks 4 connections from input layer (toward network input, input gate, forget gate and output gate) Only 1 connection from memory cell (hidden layer)
- 15. Long term dependencies of LSTM Shading indicates sensitivity to the input at time one Architecture of Neural Networks Preservation of gradient information by LSTM Vanishing gradient problem for RNNs Gate open (O) Gate closed (―)
- 16. Bidirectional Long Short-Term Memory Appling LSTM into the bidirectional recurrent neural networks (BRNN) is bidirectional LSTM (BLSTM) BLSTM provide access to long range context in both directions Architecture of Neural Networks
- 17. An large scale study of temporal deep neural networks for biometric authentication with mobile inertial sensor Recording from 1,500 volunteers using own smartphone daily over several months Paper Review
- 18. For smartphone users, remembering password or spending seconds on entering pins or drawing swipe patterns becomes a source of frustration Researches in many fields are working on behavior biometrics for fast and secure authentication Previous studies are poorly representing real world scenario The amount and variety of data have been limited to lab- scale collections Self consciousness of participants during performing tasks Introduction
- 19. This research created an unprecedented dataset of natural prehensile movements from 1,500 volunteers over several months Developing a continuous authentication system for smartphones The main challenge of this research Efficiently learning task-relevant representations of noisy inertial data Incorporating system into a biometric setting, characterized by limited resources Introduction
- 20. This research propose a non-cooperative and non-intrusive method for on-device authentication Temporal feature extraction by deep neural networks Classification via a probabilistic generative model This research assess several deep architectures One-dimensional CNNs, RNNs and LSTM Contributed to development of a new temporal model Introduction
- 21. Convolutional networks have been explored in the context of gesture and activity recognitions Lefebvre et al. applied BLSTM to a problem of 14-class gesture classification Berlemont et al. proposed Siameses networks for same task Deep learning technique achieved modeling sequential data such as motion capture and video captioning Related Works
- 22. The goal is to separate a user from an impostor based on a time series of inertial measurements A feature extractor which associates each user’s motion sequence with a collection of discriminative features A biometric model which accepts those features and perform verification The feature extractor is the most interest and novel aspect of this paper A Generative Biometric Frameworks
- 23. The Movement Data Each recording (frame) is a synchronized raw input steam of accelerometer and gyroscope ({𝒂 𝒙, 𝒂 𝒚, 𝒂 𝒛, 𝝎 𝒙, 𝝎 𝒚, 𝝎 𝒛}) A Generative Biometric Frameworks
- 24. The Movement Data Two steps prior to feature extraction Obfuscation-Based Regularization : A device could be identified by a response of its motion sensor to a given signal : This is due to the imperfection in calibration of a sensor (e.g., constant offsets and scaling coefficients (gains)) : This paper introduces low-level offset and gain noise for training example A Generative Biometric Frameworks
- 25. The Movement Data Data Preprocessing : From accelerometer and gyroscope ({𝑎 𝑥, 𝑎 𝑦, 𝑎 𝑧, 𝜔 𝑥, 𝜔 𝑦, 𝜔 𝑧}) : Angles 𝜶{𝒙, 𝒚, 𝒛} and orientation 𝝋{𝒙, 𝒚, 𝒛} are extracted : The magnitude 𝒂 𝒂𝒏𝒅 |𝝎| are computed : Each of x, y, z components are normalized with magnitudes : Normalized coordinates, angles and magnitudes are combined in 14-dimensional vector 𝑿(𝒕) along frame t Final output are integrated over 30 sec window After 30sec, the user is either authenticated or rejected A Generative Biometric Frameworks
- 26. Biometric Model For authentication on smartphone device, the available storage, memory and processing power is limited Adapting to a new user should be quick, resulting in a limited amount of training data for ‘positive’ class Purely discriminative algorithm that learning a separate model per user would hardly be feasible The generative model, Gaussian Mixture Model (GMM) are adapted to estimate a general data distribution in dynamic motion features space A Generative Biometric Frameworks
- 27. Biometric Model With GMM, an universal background model (UBM) are learned offline with a large amount of pre-collected training data The adaptation of UBM to create a client model with a very small amount of enrollment samples on device UBM and client model are used for real-time calculation of trust scores allowing continuous authentication : Trust score are calculated by log-likelihood ratio A Generative Biometric Frameworks
- 28. Learning representation with deep neural networks Multi-scale temporal aggregation via 1-dimentional convolutional networks (CNNs) Modeling of temporal dependencies via recurrent neural networks (RNNs) Learning Effective and Efficient Representations
- 29. Learning representation with deep neural networks CNNs involve convolutional learning of integrated temporal statistic from sequence of data RNNs generate latency feature vectors built in the context of previously observed user behavior : A basic RNN : Long Short-Term Memory (LSTM) : Clockwork RNN All feature extractors(CNNs) are pre-trained discriminatively for classification task Learning Effective and Efficient Representations
- 30. Classical RNN and Clockwork RNN Learning Effective and Efficient Representations Clockwork RNN RNN Activate and update with several temporal sacles
- 31. Long Short-Term Memory Recurrent Neural Networks with memory cells Best perform model for learning long-term temporal dependencies High complexity appear to computationally waste full in the mobile situation Learning Effective and Efficient Representations
- 32. Dense convolutional Clockworks RNNs Among architectures, the clockwork RNNs appear to me most attractive due to low computational burden with high modeling capacity Inactivation of “slow’ units disturb the respond to high frequency changes This network will respond different to the same input but different moment in time Dense Convolutional Clockwork RNNs Clockwork RNN
- 33. Dense convolutional Clockworks RNNs To overcome those issues, a new architecture are proposed Dense Convolutional Clockwork RNNs Dense Clockwork RNN
- 34. Google ATAP (Project Abacus) The dataset is a part of a more general multi-modal collection by google Volunteers are provided with LG Nexus 5 research phone which had a specialized read only memory (ROM) for data collection The motion data was acquired from three sensors (accelerometer, gyroscope, magnetometer) Motion dada was recorded from the moment after the phone unlock until it is locked again To prevent useless recording, data were not recorded when the device was at rest (i.e., without motion) Data Collections
- 35. Sampling rate for acc. and gyro. was 200Hz, while 5 Hz for mag. All data was resampled as 50 Hz Data from 587 devices were used for discriminative feature extractor as training set Data from 150 devices performed the validation Another 150 devices represented the “clients” as test set Data Collections
- 36. Visualization: HMOG dataset 100 subjects with 24 session of predefined task To explore the shift-invariance of temporal models For each networks, 128 runs of shifted input was performed Experimental Results
- 37. Google Abacus Dataset Feature extraction : A binary authentication task with validation and test set Experimental Results
- 38. This research confirmed that natural human kinematic without specific task convey necessary information about human identity The result showed the possibility of the non-intrusive and non- cooperative system Further augmentation with data extracted from keystroke, touch patterns, location, connectivity and application may be a key to create secure non-obtrusive mobile authentication framework Conclusion
- 39. End Q & A
- 40. Forward Pass The recurrent connections allow a ‘memory’ of previous input to persist in the network’s internal state Input of hidden unit h at time t 𝒂 𝒉 𝒕 = 𝒊=𝟏 𝑰 𝒘𝒊𝒉 𝒙𝒊 𝒕 + 𝒉′=𝟏 𝑯 𝒘 𝒉′𝒉 𝒃 𝒉′ 𝒕−𝟏 Activation of hidden unit h at time t 𝒃 𝒉 𝒕 = 𝜽 𝒉(𝒂 𝒉 𝒕 ) Input of output units 𝑎 𝑘 𝑡 = ℎ=1 𝐻 𝑤ℎ𝑘 𝑏ℎ 𝑡 Activations before T=t (i.e., previous information) Architecture of Neural Networks
- 41. Backward Pass Real time recurrent learning (RTRL) Backpropagation through time (BPTT) Error derivative at time t 𝝏𝓛 𝝏𝒂𝒋 𝒕 = 𝜹 𝒉 𝒕 = 𝜽′(𝒂 𝒉 𝒕 )( 𝒌=𝟏 𝑲 𝜹 𝒌 𝒕 𝒘 𝒉𝒌 + 𝒉′=𝟏 𝑯 𝜹 𝒉′ 𝒕+𝟏 𝒘 𝒉′ 𝒉) Calculated recursively by starting at t = T Derivatives with network weights (with chain-rule) 𝝏𝓛 𝝏𝒘𝒊𝒋 = 𝒕=𝟏 𝑻 𝝏𝓛 𝝏𝒂𝒋 𝒕 𝝏𝒂𝒋 𝒕 𝝏𝒘𝒊𝒋 = 𝒕=𝟏 𝑻 𝜹𝒋 𝒕 𝒃𝒊 𝒕 Architecture of Neural Networks
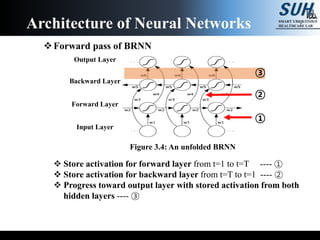
- 42. Forward pass of BRNN Store activation for forward layer from t=1 to t=T ---- ① Store activation for backward layer from t=T to t=1 ---- ② Progress toward output layer with stored activation from both hidden layers ---- ③ Architecture of Neural Networks Figure 3.4: An unfolded BRNN Backward Layer Forward Layer Output Layer Input Layer ② ① ③
- 43. Backward pass of BRNN (with BPTT) Backward pass for the output layer, storing 𝜹 at each time step ---- ③ BPTT for the forward layer with stored 𝜹 of the output layer from t=T to t=1 ---- ② BPTT for the backward layer with stored 𝜹 of the output layer from t=T to t=1 ---- ① Architecture of Neural Networks Figure 3.4: An unfolded BRNN Backward Layer Forward Layer Output Layer Input Layer ② ③ ①
- 44. Network Training Gradient Descent Algorithm (steepest descent) To repeatedly take a fixed-size step in the direction of the negative error gradient of the loss function ∆𝑤 𝑛 = −𝛼 𝜕ℒ 𝜕𝑤 𝑛 ∆𝑤 𝑛 = 𝑚∆𝑤 𝑛−1 − 𝛼 𝜕ℒ 𝜕𝑤 𝑛 Generalisation Whether training set performance carries over to the test set In general, the larger the training set the better generalisation Method for improved generalisation with a fixed size training set are referred as Regularisers (regularization) E.G., early stopping, input noise and weight noise Architecture of Neural Networks Momentum term
- 45. Generalisation – Early stopping Part of the training set is separated as validation set All stopping criteria are tested on the validation set Picking the weights that minimize on the validation set Simplest and most universally applicable method Architecture of Neural Networks Figure 3.7: Overfitting on training data
- 46. Generalisation – Input noise Adding zero-mean, fixed-variance Gaussian noise to the network input during training To artificially enhance the size of the training set Difficult to determine the noise variance in advance The input perturbation are only effective if the variation are found in the real data Architecture of Neural Networks Figure 3.8: Different kinds of input perturbation Gaussian Noise Elastic deformations
- 47. Generalisation – Weight noise Adding zero-mean, fixed-variance Gaussian noise to the network weight during training Weight noise is less effective than carefully designed input perturbation, can lead to very slow convergence Input Representation In some case, it is more important to the final performance than algorithm itself The input representation should contain all information required to successfully predict the outputs and reasonably compact (i.e., curse of dimensionality) Weight Initialisation Weights are initialised either a flat random distribution or Gaussian distribution Architecture of Neural Networks