Reference architecture for Internet of Things
14 likes7,847 views

The document outlines a reference architecture for the Internet of Things (IoT), focusing on the challenges and requirements for capturing, processing, and storing large volumes of sensor data in real-time. It emphasizes the need for scalable solutions using technologies like Apache Kafka for data capture, Apache Spark for processing, and various storage solutions such as HDFS and NoSQL databases for efficient data management. The final architecture incorporates a lambda model to facilitate both real-time and batch processing, while adhering to best practices in open source technology.



















































Reference architecture for Internet of Things
- 1. A REFERENCE ARCHITECTURE FOR INTERNET OF THINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANTSCALE [email protected] (c) Elephant Scale 2015
- 2. HI, I’M SUJEE MANIYAM • Founder / Principal @ ElephantScale • Consulting & Training in Big Data • Training in Spark / Hadoop / NoSQL / Data Science • Author • “Hadoop illuminated” open source book • “HBase Design Patterns • Open Source contributor: github.com/sujee • [email protected] • http://sujee.net (c) Elephant Scale 2015 Spark Training available!
- 3. INTERNET OF THINGS – A REALITY (c) Elephant Scale 2015
- 4. DATA INFRASTRUCTURE ? (c) Elephant Scale 2015
- 5. DATA VOLUME ? A NAPKIN CALCULATION Say we have • Million sensors • Each sensor reports every minute • data size 1KB This will result in : • 1.44 Billions events / day ! • 1.44 TB / day !! (c) Elephant Scale 2015
- 6. SENSOR DATA WORKSHEET IoT Temperature Sensor Projection variables description sensors 1M 1.00E+06 1 million signal frequency every min / 60 secs 60 secs event size 1KB 1000 bytes events per day per sensor 1440 total events per day 1.44E+09 1440$$millions1.44$$billion total events / sec 1.67E+04 16,666.67$$ total data size per day 1.44E+12 1440$$$GB 1.44$$TB (c) Elephant Scale 2015
- 7. SENSOR DATA : TEXAS UTILITIES SMART METER DATA Texas Smart Meter Projections variables description sensors 10 million customers 1.00E+07 10 million signal frequency every 15 mins 900 secs event size 1.4 K 1400 bytes events per day per sensor 96 total events per day 9.60E+08 960$$millions 0.96$$billion total events / sec 1.11E+04 11,111.11$$ total data size per day 1.34E+12 1344$$$GB 1.344$$TB (c) Elephant Scale 2015
- 8. BIG ‘DATA’ (c) Elephant Scale 2015
- 9. DATA VELOCITY Say we have • Million sensors • Each sensor reports every minute • data size 1KB è • Millions events / minute • ~ 17,000 events / sec (c) Elephant Scale 2015
- 10. DATA PROCESSING SPEED • Need (near) real time processing most of the time • E.g. Need to alert if temperature suddenly spikes temp Time Alert (c) Elephant Scale 2015
- 11. CHALLENGE = BIG DATA + REAL TIME • Don’t loose events ! • Any event could be important • Most events are mundane (e.g. temperature stays between 68’F – 72’ F) • Process them in near real time • Store the events for a long time • Audit • Diagnose • Support various queries • Real time (what is the latest temperature for sensor id 123?) • Aggregate (what is the avg. temp in zipcode 12345) (c) Elephant Scale 2015
- 12. HIGH LEVEL ARCHITECTURE (c) Elephant Scale 2015
- 13. NEXT : (1) CAPTURE (c) Elephant Scale 2015
- 14. (1) CAPTURE REQUIREMENTS Requirements: • Capture events coming at high speed • Tens of thousands events / sec (some times millions / sec) • Don’t loose events • Tolerate hardware / software failure • Tolerate intermittent connectivity issues • Scale ‘easily’ (c) Elephant Scale 2015
- 15. (1) CAPTURE CHOICES • MQ (RabbitMQ ..etc) • Good adoption in enterprises / durable • FluentD • Data collector for various sources • Flume • Part of Hadoop eco system • Good for collecting logs from many sources • AWS Kinesis • Queue system in Amazon Cloud • Kafka • Distributed queue (c) Elephant Scale 2015
- 16. (1) CAPTURE MEET KAFKA • Apache Kafka is a distributed messaging system • Came out of LinkedIn… open sourced in 2011 • Built to tolerate hardware / software / network failures • Built for high throughput and scale • LinkedIn : 220 Billion messages / day • At peak : 3+ million messages / day (c) Elephant Scale 2015
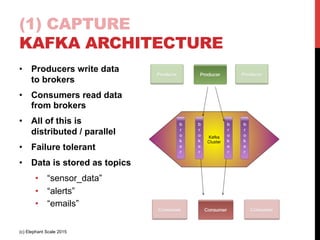
- 17. (1) CAPTURE KAFKA ARCHITECTURE • Publisher - subscriber / producer – consumer model (c) Elephant Scale 2015
- 18. (1) CAPTURE KAFKA ARCHITECTURE • Producers write data to brokers • Consumers read data from brokers • All of this is distributed / parallel • Failure tolerant • Data is stored as topics • “sensor_data” • “alerts” • “emails” (c) Elephant Scale 2015
- 19. (1) CAPTURE KAFKA USERS • Linked In • Track user activities • Sending emails • Netflix • Real time monitoring • Spotify • Ship logs to hadoop • Uber… AirBnB…. (c) Elephant Scale 2015
- 20. (1) CAPTURE ARCHITECTURE WITH KAFKA (c) Elephant Scale 2015
- 21. NEXT : (2) PROCESSING (c) Elephant Scale 2015
- 22. (2) PROCESSING REQUIREMENTS • Process events in real time or near real time • High velocity • Tens of thousands à millions of events / sec • Guaranteed processing • Process an event at-least-once • Exactly-once (harder to achieve) • Failure tolerant • Scale ‘easily’ (c) Elephant Scale 2015
- 23. (2) PROCESSING CHOICES • Storm • Process streams • Events based • Came out of twitter • Apache Samza • Stream processing framework based on Kafka + Hadoop YARN • Apache NiFi • Data flow • New project / incubating • Spark streaming (c) Elephant Scale 2015
- 24. (2) PROCESSING MEET SPARK • Spark is the new darling of ‘Big Data’ world • Lot’s of activity and interest • Fast and Expressive Cluster Compute Engine • “First Big Data platform to integrate batch, streaming and interactive computations in a unified framework” – stratio.com Hadoop Spark (c) Elephant Scale 2015
- 25. (2) PROCESSING SPARK ECO-SYSTEM (c) Elephant Scale 2015 Spark Core Spark SQL Spark Streaming ML lib Schema / sql Real Time Machine Learning Stand alone YARN MESOS Cluster managers GraphX Graph processing
- 26. (2) PROCESSING SPARK DATA SOURCE ABSTRACTION Spark (compute engine) HDFS Amazon S3 Cassandra ??? RDD Hadoop RDD Cassandra RDD (c) Elephant Scale 2015
- 27. (2) PROCESSING SPARK : ‘UNIFIED’ STACK Spark supports multiple programming models • Map reduce style batch processing • Streaming / real time processing • Querying via SQL • Machine learning All modules are tightly integrated • Facilitates rich applications Spark can be only stack you need ! (c) Elephant Scale 2015 Image: buymeposters.com
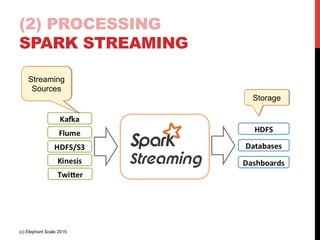
- 28. (2) PROCESSING SPARK STREAMING Streaming Sources Storage (c) Elephant Scale 2015
- 29. (2) PROCESSING SPARK STREAMING • Provides ‘high level’ operations in time windows • E.g. ‘calculate X for the past 10 seconds’ • Good adoption (c) Elephant Scale 2015
- 30. (2) PROCESSING ARCHITECTURE WITH SPARK STREAMING (c) Elephant Scale 2015
- 31. NEXT : STORAGE (c) Elephant Scale 2015
- 32. (3) STORAGE REQUIREMENTS • Handle ‘Big Data’ ( 1 TB / day !) • Traditional storages are not effective (or too expensive) • Need two types of storage 1. ‘forever’ storage • Store multi terabytes of data for a long periods • Support Batch queries 2. ‘fast / real-time lookup’ storage • Query in real time (milliseconds) “what is the latest reading for sensor-123 ?” • Store latest / new data (e.g. last 3 months) • Flexible schema for semi-structured data • Both need to scale (c) Elephant Scale 2015
- 33. (3) STORAGE REQUIREMENTS (c) Elephant Scale 2015
- 34. (3) STORAGE CHOICES • ‘forever’ storage • Scalable distributed file systems • Hadoop ! (HDFS actually) • ‘real time store’ • Traditional RDBMS won’t work • Don’t scale well (or too expensive) • Rigid schema layout • NoSQL ! (c) Elephant Scale 2015
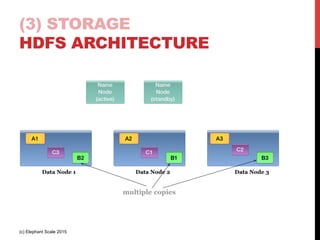
- 35. (3) STORAGE HDFS (IN 20 SECS) • Distributed file system • Runs on commodity servers • à high ROI • Can keep ticking even when nodes go down • à fault tolerant • Replicates data to prevent data loss in case of node failures • à built in backup J • Scales to Peta bytes (horizontal scalability) • Proven in the field (c) Elephant Scale 2015
- 36. (3) STORAGE HDFS ARCHITECTURE (c) Elephant Scale 2015
- 37. (3) STORAGE COST OF BIG DATA Source : hortonworks (c) Elephant Scale 2015
- 38. (3) STORAGE HDFS • Can handle big data • Scales easily • Cost effective • “Source of Truth” • Files are immutable within HDFS (new data is ‘appended’ ) • Audit friendly (c) Elephant Scale 2015
- 39. (3) STORAGE CAPACITY PLANNING (HADOOP) Variables (tweak these) description value units Average daily ingest 1000 GB raw data node storage eg. 12 disks x 3TB 36 TB replication default 3 3 space allocated for HDFS HDFS 75% + Mapreduce 25% 75.00% growth per month (not calculated) 0 Calculation effective data storage per node 27 TB growth 1 month 6 month 1 yr 2 yr data size (TB) 90 540 1,080 2,160 # data nodes 3.333333333 20 40 80 (c) Elephant Scale 2015
- 40. (3) STORAGE (REAL TIME) CHOICES FOR NOSQL • Too many ! J • HBase • Part of Hadoop eco system • Uses HDFS for storage • Provides consistent view of data • Cassandra • Popular NoSQL store • No Single Point of Failure (SPOF) – ring architecture • No dependency on Hadoop • Accumulo • Came out of NSA ! • Uses HDFS for storage • Provides very good security (naturally !) (c) Elephant Scale 2015
- 41. (3) STORAGE CAP THEOREM (c) Elephant Scale 2015
- 42. (3) STORAGE ARCHITECTURE SO FAR (c) Elephant Scale 2015
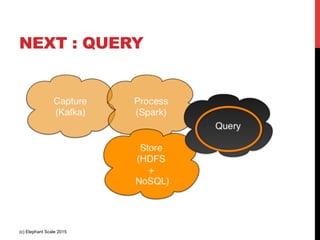
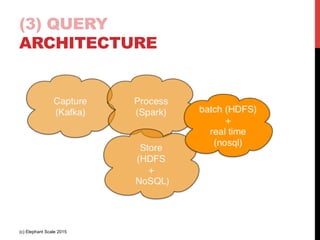
- 43. NEXT : QUERY (c) Elephant Scale 2015
- 44. (3) QUERY REQUIREMENTS • Real Time queries • “what is the latest reading for the sensor id = 123” • Useful for building applications / dashboards • Latency : milli-seconds • Batch / Aggregate queries • “What is the average temperature in zip code = 12345” ? • May need to go through large data points • Latency : ‘batch’ (minutes / hours) (c) Elephant Scale 2015
- 45. (3) QUERY SOLUTIONS • Batch queries • Query data in HDFS (and or NoSQL) • Hadoop mapreduce (Pig / Hive) • Spark batch analytics • Real time queries • Queries to go NoSQL store HDFS NoSQL Real time queries Batch queries (c) Elephant Scale 2015
- 46. (3) QUERY ARCHITECTURE (c) Elephant Scale 2015
- 47. FINAL ARCHITECTURE (c) Elephant Scale 2015
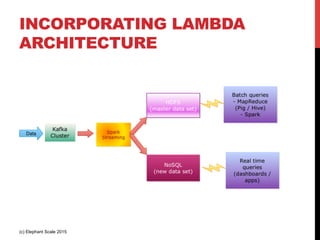
- 48. LAMBDA ARCHITECTURE (c) Elephant Scale 2015
- 49. LAMBDA ARCHITECTURE EXPLAINED 1. All new data is sent to both batch layer and speed layer 2. Batch layer • Holds master data set (immutable , append-only) • Answers batch queries 3. Serving layer • updates batch views so they can be queried adhoc 4. Speed Layer • Handles new data • Facilitates fast / real-time queries 5. Query layer • Answers queries using batch & real-time views (c) Elephant Scale 2015
- 50. INCORPORATING LAMBDA ARCHITECTURE (c) Elephant Scale 2015
- 51. OUR ARCHITECTURE • Each component is scalable • Each component is fault tolerant • Incorporates best practices • All open source ! (c) Elephant Scale 2015
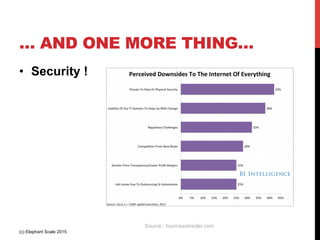
- 52. … AND ONE MORE THING… • Security ! (c) Elephant Scale 2015 Source : businessinsider.com
- 53. HOW EVER… (c) Elephant Scale 2015 At scale nothing works as advertised !
- 54. GOOD NEWS ! • We are building an open source, reference data platform for IoT / connected devices! • Yes, open source ! J • ElephantScale is a strong believer in open source • “hadoop illuminated” – open source Hadoop book • Github.com/elephantscale • Best practices • Bringing together lots of expertise in Big Data systems • Register your interest http://elephantscale.com/iotx/ (c) Elephant Scale 2015
- 55. GOALS FOR IOTX http://elephantscale.com/iotx/ • Use open-source proven components • Capture : • Kafka • Kinesis (AWS) • Processing : Spark Streaming • Batch storage : Hadoop / HDFS • Real Time Store : support multiple data stores • Cassandra • Hbase • Accumulo • ??? (c) Elephant Scale 2015
- 56. GOALS FOR IOTX… http://elephantscale.com/iotx/ • Query templates using • Spark • Hadoop Map Reduce (Pig / Hive) • Incorporate third party libraries for • Outlier detection (temperature is outside norms) • Trend detection (stock price is trending up) • Alerts (fire !) • Monitoring & Metrics (key !!) • What’s going in the system? • Host / system level (cpu / network ..etc) – easier • application level (e.g. find slow queries) – harder • Incorporate third party libraries (c) Elephant Scale 2015
- 57. THANKS AND QUESTIONS? “A Reference Architecture for Internet of Things (IoT)” Sujee Maniyam Founder / Principal @ ElephantScale Expert Consulting + Training in Big Data technologies [email protected] Elephantscale.com Project sign up page : http://elephantscale.com/iotx/ (c) Elephant Scale 2015
- 58. IMAGE CREDITS • www.engadget.com • Xfinity.com • Tesla.com (c) Elephant Scale 2015