



![REGEX의 예시
요상해 보이지만 배우고 나면 별것 아니다.
몇 시간이면 다 배울 수 있는 간단한 것들이다.
a.cdef?
[a-zA-Z]+
.*boy
(caret|dollar)
(.*/)[^/]*
^Do.*?$
http://([a-zA-Z0-9.-])/.*
https?://.*?(.*)
REGEX를 배운 뒤에 해석해봅시다!](https://image.slidesharecdn.com/5regularexpressionregex-vim-150322082908-conversion-gate01/85/Regular-expression-regex-5-320.jpg)




![REGEX and EBNF
REGEX와 EBNF 문법
특히 *, +, ?, [...]는 EBNF의 영향이 크다.
EBNF를 포멀한 형태로 패턴화
즉 EBNF를 알고 있다면 학습이 쉬워진다.
* EBNF (Extended Backus-Naur Form)](https://image.slidesharecdn.com/5regularexpressionregex-vim-150322082908-conversion-gate01/85/Regular-expression-regex-10-320.jpg)






![POSIX REGEX: meta char.
문자 지정 . 임의의 문자 한 개를 의미합니다.
반복 지정
? 선행문자패턴이 0개 혹은 1개 나타납니다. - ERE
+ 선행문자패턴이 1개 이상 반복됩니다. - ERE
* 선행문자패턴이 0개 이상 반복됩니다.
{m,n}
(interval) 반복수를 직접 지정할 수 있습니다. - ERE
m이나 n중에 하나를 생략할 수 있다.
(예) {3} : 3번 반복 {,7} : 7번 이하 {2,5} : 2~5번 반복
위치 지정
^ 라인의 앞부분을 의미합니다.
$ 라인의 끝부분을 의미합니다.
그룹 지정
[...] 안에 지정된 문자들 그룹 중에 한 문자를 지정합니다.
[^...] 안에 지정된 그룹의 문자를 제외한 나머지(여집합)를 지정합니다.
기타
(escape) 메타의 의미를 없애줍니다.
| (alternation,choice) OR연산을 합니다. - ERE
( ) 괄호는 패턴을 그룹화 및 백레퍼런스의 작동을 합니다. - ERE
* ERE - Extended Regular Expression
(ERE를 사용하면 약간의 속도 저하가 발생하는 플랫폼도 있으나 큰 차이는 없다.)
* POSIX RE - IEEE std 1003.1 (International standard)](https://image.slidesharecdn.com/5regularexpressionregex-vim-150322082908-conversion-gate01/85/Regular-expression-regex-17-320.jpg)







![Character sets
[ ], [^ ] - character class
[abcd] : a, b, c, d 중에 하나
[0-9] : 0, 1, 2, ... , 9
[a-zA-Z0-9] : 대소문자 알파벳과 숫자
[^0-9] : [0-9]을 제외한 나머지
^ 문자 자체를 그룹에 넣으려면?
^이 [ 바로 뒤에만 오지 않으면 된다.
[0-9^]
혹은 escape 시키거나...
[ ] : (square) brackets](https://image.slidesharecdn.com/5regularexpressionregex-vim-150322082908-conversion-gate01/85/Regular-expression-regex-25-320.jpg)
![Practice #1-a : POSIX BRE
REGEX로 단어를 검색해보자. (붉은색 부분이 매칭된 결과)
패턴 해석
p 가 등장하고,
그 다음에 [a-d]중에 적어도 1번 이상이 등장하고,
그 다음에 ous가 등장하는 경우
$ grep --color "p[abcd]+ous" /usr/share/dict/words
opacous
opacousness
semiopacous](https://image.slidesharecdn.com/5regularexpressionregex-vim-150322082908-conversion-gate01/85/Regular-expression-regex-26-320.jpg)
![Practice #1-b : POSIX BRE
anchor를 이용해서 패턴을 수정
패턴 해석
p가 등장하고,
그 다음에 [a-d]중에 적어도 1번 이상이 등장하고,
그 다음에 ous가 매칭의 끝 부분에 등장하는 경우
$가 지정되면 그 뒤로는 라인의 끝을 의미한다.
$ grep --color "p[abcd]+ous$" /usr/share/dict/words
opacous
semiopacous](https://image.slidesharecdn.com/5regularexpressionregex-vim-150322082908-conversion-gate01/85/Regular-expression-regex-27-320.jpg)
![Practice #2
log data를 검색 (아래와 같은 로그가 있다고 가정 : 파일명 exjournal.log 으로 가정)
May 09 18:02:40 dev03.rh0xhf su[43726]: (to root) sunyzero on pts/14
May 09 18:02:40 dev03.rh0xhf su[43726]: pam_systemd(su-l:session): Cannot create session
May 09 18:02:40 dev03.rh0xhf su[43726]: pam_unix(su-l:session): session opened for user root by (uid=1000)
May 10 14:07:58 dev03.rh0xhf systemd[1272]: Time has been changed
May 10 15:35:56 dev03.rh0xhf su[43726]: pam_unix(su-l:session): session closed for user root
May 20 22:40:10 dev03.rh0xhf su[31978]: pam_unix(su-l:session): session closed for user root
May 25 17:11:54 dev03.rh0xhf systemd[1272]: Time has been changed
May 30 15:51:30 dev03.rh0xhf su[63881]: (to root) sunyzero on pts/5
May 30 15:51:30 dev03.rh0xhf su[63881]: pam_systemd(su-l:session): Cannot create session
May 30 15:51:30 dev03.rh0xhf su[63881]: pam_unix(su-l:session): session opened for user root by (uid=1000)
May 30 15:54:53 dev03.rh0xhf su[63881]: pam_unix(su-l:session): session closed for user root
May 30 15:55:16 dev03.rh0xhf su[63977]: (to root) sunyzero on pts/5
May 30 15:55:16 dev03.rh0xhf su[63977]: pam_systemd(su-l:session): Cannot create session
May 30 15:55:16 dev03.rh0xhf su[63977]: pam_unix(su-l:session): session opened for user root by (uid=1000)
May 30 15:57:28 dev03.rh0xhf su[63977]: pam_unix(su-l:session): session closed for user root
pam_systemd가 session 생성에 실패한 로그만 뽑아 보고 싶다.
= pam_systemd 문자열이 들어간 행만 뽑아내야 한다.](https://image.slidesharecdn.com/5regularexpressionregex-vim-150322082908-conversion-gate01/85/Regular-expression-regex-28-320.jpg)
![Practice #2 (con't)
grep 활용. (붉은색 강조된 부분이 매칭된 결과)
$ grep --color pam_systemd exjournal.log
May 09 18:02:40 dev03.rh0xhf su[43726]: pam_systemd(su-l:session): Cannot create session
May 30 15:51:30 dev03.rh0xhf su[63881]: pam_systemd(su-l:session): Cannot create session
May 30 15:55:16 dev03.rh0xhf su[63977]: pam_systemd(su-l:session): Cannot create session
$ grep --color -A 1 "pam_systemd" exjournal.log
May 09 18:02:40 dev03.rh0xhf su[43726]: pam_systemd(su-l:session): Cannot create session
May 09 18:02:40 dev03.rh0xhf su[43726]: pam_unix(su-l:session): session opened for user root by (uid=1000)
--
May 30 15:51:30 dev03.rh0xhf su[63881]: pam_systemd(su-l:session): Cannot create session
May 30 15:51:30 dev03.rh0xhf su[63881]: pam_unix(su-l:session): session opened for user root by (uid=1000)
--
May 30 15:55:16 dev03.rh0xhf su[63977]: pam_systemd(su-l:session): Cannot create session
May 30 15:55:16 dev03.rh0xhf su[63977]: pam_unix(su-l:session): session opened for user root by (uid=1000)
패턴 매칭에서 다음 행을 뽑아주는 패턴은 없다.
이건 grep의 옵션(-A, -B)으로 해결할 문제이다.
실패한 유저명은 그 다음행의 로그에 나온다.
매칭에 성공한 행의 뒷 행을 출력하려면?](https://image.slidesharecdn.com/5regularexpressionregex-vim-150322082908-conversion-gate01/85/Regular-expression-regex-29-320.jpg)



![Greedy matching (con't)
<.+> 에서 임의의 문자인 . 를 [^<>] 표현으로 변경하면?
$ var2="It’s gonna be <b>real</b>It’s gonna <i>change everything </i> I feel"
$ echo $var2 | egrep -o "<.+>"
<b>real</b>It's gonna <i>change everything</i>
$ echo $var2 | egrep -o "<[^<>]+>"
<b>
</b>
<i>
</i>
<.+> . [^<>]
태그 부분만 뽑아낸 결과다.
greedy matching된 결과에서 더 세밀하게 패턴을 조정했다.](https://image.slidesharecdn.com/5regularexpressionregex-vim-150322082908-conversion-gate01/85/Regular-expression-regex-33-320.jpg)
![Non-greedy matching
최소 매칭 기능 == greedy matching의 반대 개념
앞서 <.+> 대신에 [ 을 사용하면 최소 매칭이 되는데...
POSIX RE에서는 패턴을 수정하여 non-greedy matching 효과와 같은 결과의
패턴을 만든다.
POSIX RE에서는 non-greedy matching 수량자를 제공하지는 않는다.
따라서 패턴을 변경해서 non-greedy matching 결과를 만드는 것이다.
하지만 PCRE는 non-greedy matching을 쉽게 할 수 있는 quantifier를 제공한다.
이를 lazy quantifier라고 부른다.
<[^<>]+>](https://image.slidesharecdn.com/5regularexpressionregex-vim-150322082908-conversion-gate01/85/Regular-expression-regex-34-320.jpg)
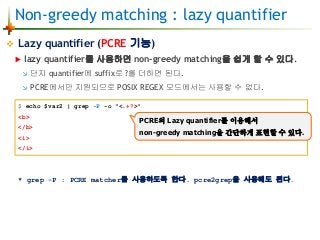
![Non-greedy matching (con't)
On POSIX RE : It dosen't support non-greedy matching.
On PCRE : It can be non-greedy matching by lazy quantifier.
* 예제 타이핑시 맨 앞의 $ 문자는 프롬프트이므로 타이핑하지 않는다.
$ echo $var2 | egrep -o "<[^<>]+>"
<b>
</b>
<i>
</i>
$ echo $var2 | grep -P -o "<.+?>"
<b>
</b>
<i>
</i>](https://image.slidesharecdn.com/5regularexpressionregex-vim-150322082908-conversion-gate01/85/Regular-expression-regex-36-320.jpg)



![Back-slash (con't)
BRE에서 ERE의 ?, { }, +, |, ( ) 패턴 사용시 앞에 사용.
grep은 기본값으로 BRE를 사용하므로 위와 같이 + 으로 사용해야 한다.
* 는 BRE이므로 back-slash를 사용할 필요가 없다.
$ echo $var3 | grep --color '[0-9bc]*'
abc cab cbb ccb zxy cdb c1b c2b c.b c*b 123
$ echo $var3 | grep --color '[0-9bc]+'
매칭 실패!!! 아무것도 출력되지 않는다. (왜냐하면 +가 ERE이기 때문이다)
$ echo $var3 | grep --color '[0-9bc]+'
abc cab cbb ccb zxy cdb c1b c2b c.b c*b 123
+앞에 를 사용해야 성공!](https://image.slidesharecdn.com/5regularexpressionregex-vim-150322082908-conversion-gate01/85/Regular-expression-regex-40-320.jpg)

![Practice #3 : back-slash
BRE vs ERE : 우선 BRE의 특징부터 살펴보자.
$ var4='URLs : http://asdf.com/en/ , https://asdf.com/en/'
$ echo $var4 | grep --color 'http://[A-Za-z./]*'
URLs : http://asdf.com/en/ , https://asdf.com/en/
var4 변수에 URL 주소를 2개 넣었다.
그리고 grep을 이용해서 'http://[A-Za-z./]*' 패턴 적용](https://image.slidesharecdn.com/5regularexpressionregex-vim-150322082908-conversion-gate01/85/Regular-expression-regex-42-320.jpg)
![Practice #3 : back-slash
BRE vs ERE : 앞서 패턴에서 +를 추가했더니 실패한다.
해법은? ERE에서 사용되는 메타 문자앞에 back-slash 추가!
$ echo $var4 | grep --color 'http://[A-Za-z./]+'
매칭 실패!!! 아무것도 출력되지 않는다. (왜냐하면 +가 ERE이기 때문이다)
$ echo $var4 | grep --color 'http://[A-Za-z./]+'
URLs : http://asdf.com/en/ , https://asdf.com/en/
+는 ERE이므로
BRE가 기본인 grep에서는 +를 인식하지 못하고 실패한다.
하지만 +앞에 back-slash를 추가해주면 성공한다.](https://image.slidesharecdn.com/5regularexpressionregex-vim-150322082908-conversion-gate01/85/Regular-expression-regex-43-320.jpg)
![Practice #3 : back-slash
BRE vs ERE :
ERE를 사용하는 egrep에서는 굳이 back-slash가 없어도 된다.
$ echo $var4 | egrep --color 'http://[A-Za-z./]+'
URLs : http://asdf.com/en/ , https://asdf.com/en/
ERE를 사용하는 경우에는
grep -E 혹은 egrep 으로 명령한다.](https://image.slidesharecdn.com/5regularexpressionregex-vim-150322082908-conversion-gate01/85/Regular-expression-regex-44-320.jpg)
![Practice #4-a
www.naver.com 페이지에서 URL 링크를 추출해보자.
curl : 터미널에서 웹 페이지를 접속하는 유틸
$ curl -s http://www.naver.com | egrep -o 'http://[0-9A-Za-z.]+/'
http://www.naver.com/
http://static.naver.net/
http://www.naver.com/
http://static.naver.net/
...생략...
$ curl -s http://www.naver.com | egrep --color 'http://[0-9A-Za-z.]+/'
...생략...
ERE를 사용하는 egrep은
+앞에 back-slash를 사용하지 않아도 된다.](https://image.slidesharecdn.com/5regularexpressionregex-vim-150322082908-conversion-gate01/85/Regular-expression-regex-45-320.jpg)
![Practice #4-b
www.naver.com 페이지에서 URL 링크를 추출해보자.
중복되는 링크를 제거해보자.
$ curl -s http://www.naver.com | egrep -o 'http://[0-9A-Za-z.]+/' | sort | uniq
http://blog.naver.com/
http://cafe.naver.com/
http://castbox.shopping.naver.com/
http://cecs.naver.com/
http://entertain.naver.com/
...생략...](https://image.slidesharecdn.com/5regularexpressionregex-vim-150322082908-conversion-gate01/85/Regular-expression-regex-46-320.jpg)
![Practice #4-c
www.naver.com 페이지에서 URL 링크를 추출해보자.
img 태그만 추출해보자.
$ curl -s http://www.naver.com | egrep -o "<img [^<>]+>"
<img data-src="http://img.naver.net/static/www/dl_qr_naver.png" width="68" height="8
4" alt="네이버 앱 QR코드" />
<img data-src="http://img.naver.net/static/www/up/2012/naver_homepage.png" width="88
0" height="31" alt="시작페이지" usemap="#sliding" />
...생략...](https://image.slidesharecdn.com/5regularexpressionregex-vim-150322082908-conversion-gate01/85/Regular-expression-regex-47-320.jpg)

![Practice #4-d
www.naver.com 페이지에서 URL 링크를 추출해보자.
아래 ERE를 BRE로 바꿔보자 (egrep대신에 grep을 사용하도록 한다.)
$ curl -s http://www.naver.com | egrep -o "<img [^<>]+>"
$ curl -s http://www.naver.com | egrep -o 'http://[0-9A-Za-z.]+/' | sort | uniq
$ curl -s http://www.naver.com | grep -o "<img [^<>]+>"
$ curl -s http://www.naver.com | grep -o 'http://[0-9A-Za-z.]+/' | sort | uniq
BRE를 사용할 때는 어디에 back-slash를
추가해야 하는지 기억해두자.](https://image.slidesharecdn.com/5regularexpressionregex-vim-150322082908-conversion-gate01/85/Regular-expression-regex-49-320.jpg)


![Back-reference
매칭된 결과를 다시 사용하는 패턴 (백레퍼런스)
"( )"로 묶인 패턴 매칭 부분을 "#"의 형태로 재사용
(#는 숫자가 순서대로), 0번은 전체 매칭 결과
options
-v : invert
--color : Surround the matched (non-empty) strings
$ egrep "^(.+):x:[0-9]+:[0-9]+:.*:/home/1:" /etc/passwd
sunyzero:x:500:500:Steven Kim:/home/sunyzero:/bin/bash
linuxer:x:502:502::/home/linuxer:/bin/bash
$ egrep -v "^(.+):x:[0-9]+:[0-9]+:.*:/home/1:" /etc/passwd
... (생략, 상상하시기 바랍니다) ...
( ) : parenthesis](https://image.slidesharecdn.com/5regularexpressionregex-vim-150322082908-conversion-gate01/85/Regular-expression-regex-52-320.jpg)
![Back-reference (con’t)
back-reference 응용 : tag로 감싸여진 부분 추출
$ var2='It’s gonna be <b>real</b>It’s gonna <i>change everything</i> I feel'
$ echo $var2 | egrep -o '<([a-zA-Z0-9]+)>.*</1>'
<b>real</b>
<i>change everything</i>
$ echo $var2 | egrep --color '<([a-zA-Z0-9]+)>.*</1>'
... 생략 ...](https://image.slidesharecdn.com/5regularexpressionregex-vim-150322082908-conversion-gate01/85/Regular-expression-regex-53-320.jpg)

![Practice #4-e
www.naver.com 페이지에서 URL 링크를 추출해보자.
<a ...> ... </a> 로 감싸진 태그 내용을 추출해보자.
(a|A) 부분이 back-reference가 되고 첫번째 소괄호이므로 1 이 된다.
(a|A) : a 혹은 A가 등장하는 경우
$ curl -s http://www.naver.com | egrep -o "<(a|A) [^<>]+>.+</1>"
<a href="http://www.navercorp.com/" target="_blank" id="plc.intronhn">회사소개</a>
<a href="http://mktg.naver.com/" id="plc.adinfo">광고</a>
<a href="https://help.naver.com/" id="plc.helpcenter">네이버 고객센터</a>
<a href="https://submit.naver.com/" id="plc.search">마이비즈니스</a>
...생략...
egrep이므로 ERE를 사용하고 있는데,
grep의 BRE로 바꿔서 사용하려면?](https://image.slidesharecdn.com/5regularexpressionregex-vim-150322082908-conversion-gate01/85/Regular-expression-regex-55-320.jpg)
![Practice #4-e (con't)
grep의 BRE로 변경해보면?
BRE에서는 ERE meta character인 ?, +, { }, ( ) , | 를 escape 시켜야 한다.
$ curl -s http://www.naver.com | grep -o "<(a|A) [^<>]+>.+</1>"
<a href="http://www.navercorp.com/" target="_blank" id="plc.intronhn">회사소개</a>
<a href="http://mktg.naver.com/" id="plc.adinfo">광고</a>
<a href="https://help.naver.com/" id="plc.helpcenter">네이버 고객센터</a>
<a href="https://submit.naver.com/" id="plc.search">마이비즈니스</a>
...생략...](https://image.slidesharecdn.com/5regularexpressionregex-vim-150322082908-conversion-gate01/85/Regular-expression-regex-56-320.jpg)
![Practice #4-f
www.naver.com 페이지에서 URL 링크를 추출해보자.
jpg, png 확장자를 가진 파일 링크만 추출해보자.
주의 할 점은 확장자는 대문자일 수도 있다. 즉 JPG, jpg 둘다 잡아내야 한다.
위 REGEX의 .은 진짜 dot 문자를 의미하는 것이다. (.을 이스케이프 시킨 것!)
$ curl -s http://www.naver.com | egrep -o 'http://[0-9A-Za-z./_]+.(jpg|JPG|png|PNG)'
http://img.naver.net/static/www/dl_qr_naver.png
http://img.naver.net/static/www/up/2012/naver_homepage.png
http://img.naver.net/static/www/mobile/edit/2016/0609/mobile_16305721761.jpg
http://img.naver.net/static/www/mobile/edit/2016/0610/mobile_164630175157.JPG
http://img.naver.net/static/www/m/guide/dummy_1X1.jpg
...생략...](https://image.slidesharecdn.com/5regularexpressionregex-vim-150322082908-conversion-gate01/85/Regular-expression-regex-57-320.jpg)
![Substitution - sed (stream ed)
sed에서 제일 많이 쓰는 기능이 substitution이다.
sed의 subst. 기능은 vim의 substitution command와 같다.
sed의 substitution에서 separator는 slash(/)를 많이 쓰지만 comma(,)를 쓰기
도 한다. 기계적으로 slash만 쓰는 걸로 외웠다면 지식을 업데이트 하자!
vim의 substitution command는 sed의 기능이 포함된 것뿐이다!
= sed를 알면 vim도 알고... UNIX는 이렇게 서로 연관된 기능들이 많다.
sed는 BRE를 기반으로 하므로 + 로 표현되었다.
$ echo $var2 | sed -e "s/<[^<>]+>/ /g"
It's gonna be real It's gonna change everything I feel
$ echo $var2 | sed -e "s,<[^<>]+>, ,g"
< > : chevron](https://image.slidesharecdn.com/5regularexpressionregex-vim-150322082908-conversion-gate01/85/Regular-expression-regex-59-320.jpg)
![Substitution - awk
awk에서도 위의 모든 기능을 구현할 수 있다.
awk의 gsub(global substitution)에서 REGEX로 교체하는 방법이다.
awk는 ERE를 사용하므로 + 앞에 back slash를 쓰지 않는다.
$ echo $var2 | awk '{ gsub(/[ ]*<[^<>]+>[ ]*/, " "); print }'
It’s gonna be real It’s gonna change everything I feel
{ } : (curly) brace](https://image.slidesharecdn.com/5regularexpressionregex-vim-150322082908-conversion-gate01/85/Regular-expression-regex-60-320.jpg)
![Practice #4-e
www.naver.com 페이지에서 URL 링크를 제거해보자.
<a ...> ... </a> 로 감싸진 태그 내용을 일반 메시지로 변경해보자.
( ), |, + 앞에 back-slash를 쓴 이유는?
sed는 BRE를 쓰기 때문이다.
ERE를 쓰려면 -r 옵션을 사용하면 된다.
$ curl -s http://www.naver.com | sed -n "s,<(a|A) [^<>]+>(.+)</1>,2,gp"
<dd class="f">회사소개</dd>
<dd>광고</dd>
<dd>네이버 고객센터</dd>
<dd>마이비즈니스</dd>
...생략...](https://image.slidesharecdn.com/5regularexpressionregex-vim-150322082908-conversion-gate01/85/Regular-expression-regex-61-320.jpg)

![Boundary - ERE
word 경계 검색에 사용
b boundary가 맞는 표현식만 찾는다. (단어 경계면 검색)
B boundary에 맞지 않는 표현식만 찾는다. (단어 경계면이 아닌 경우만 검색)
$ var5="abc? <def> 123hijklm"
$ echo $var5 | egrep -o "[a-j]+"
abc
def
hij
$ echo $var5 | egrep --color "b[a-j]+b"
abc? <def> 123hijklm
$ echo $var5 | egrep --color "B[a-j]+B"
abc? <def> 123hijklm](https://image.slidesharecdn.com/5regularexpressionregex-vim-150322082908-conversion-gate01/85/Regular-expression-regex-63-320.jpg)
![Predefined character class
클래스 설 명
[[:alnum:]] 알파벳과 숫자들의 모음
[[:alpha:]] 알파벳들 (대소문자)
[[:blank:]] Tab(t)을 의미
[[:cntrl:]] 제어문자들을 의미
[[:digit:]] 숫자들을 의미
[[:xdigit:]] 16진수(hex)형 숫자들을 의미, 즉 0-9a-fA-F 를 포함한다.
[[:upper:]] 알파벳 대문자
[[:lower:]] 알파벳 소문자
[[:space:]] tab(t), CR(r), New line(n) 을 포함한다.
[[:print:]] 출력 가능한 문자들
[[:graph:]] 공백을 제외한 문자들
[[:punct:]] 출력 가능한 특수문자들](https://image.slidesharecdn.com/5regularexpressionregex-vim-150322082908-conversion-gate01/85/Regular-expression-regex-64-320.jpg)
![Predefined character class (con't)
[...]안에 조합가능
sunyzero@email까지만 잘렸다. 모두 나오게 하려면?
$ var5="sunyzero@email.com:010-8500-80**:Sun-young Kim:AB-0105R"
$ echo $var5 | egrep -o "^[[:alpha:]@]+"
sunyzero@email
$ echo $var5 | egrep -o "[[:upper:][:digit:]-]{8}"
010-8500
AB-0105R](https://image.slidesharecdn.com/5regularexpressionregex-vim-150322082908-conversion-gate01/85/Regular-expression-regex-65-320.jpg)

![Practice #5
IPv4 address를 REGEX로 표현하면?
IPv4주소는 각 요소가 0~255 (0xff)사이의 값만을 가져야만 한다.
두자리 이상의 숫자 범위에 대해 정의하려면?
Hint : 0~63까지 표현하려면...
[0-9]{,3}.[0-9]{,3}.[0-9]{,3}.[0-9]{,3}
이 표현식은 IP주소로는 틀렸다.
왜냐하면 단순하게 숫자 3개만 검사하므로,
333.469.789.1 처럼 범위를 벗어나도 매칭성공된다.
(6[0-3]|[5-1][0-9]|[0-9])](https://image.slidesharecdn.com/5regularexpressionregex-vim-150322082908-conversion-gate01/85/Regular-expression-regex-67-320.jpg)
![Practice #6 : Hangul, Hanja
i18n을 만족하는 Linux는 UTF-8 한글 처리도 가능하다.
$ cat <<HEREDOC >hangul-utf8.txt
This is ascii text in UTF-8 character-set.
한글은 한국어에서 사용되는 문자이다. 여기 UTF8로 인코딩된 한글과 한자(漢字)가 보이는가?
HEREDOC
$ egrep --color '한.' hangul-utf8.txt
한글은 한국어에서 사용되는 문자이다. 여기 UTF8로 인코딩된 한글과 한자(漢字)가 보이는가?
$ egrep --color '한[글자]' hangul-utf8.txt
한글은 한국어에서 사용되는 문자이다. 여기 UTF8로 인코딩된 한글과 한자(漢字)가 보이는가?
$ egrep --color '..字' hangul-utf8.txt
한글은 한국어에서 사용되는 문자이다. 여기 UTF8로 인코딩된 한글과 한자(漢字)가 보이는가?
* 첫번째 cat 명령은 redirection의 HERE document기법이다.](https://image.slidesharecdn.com/5regularexpressionregex-vim-150322082908-conversion-gate01/85/Regular-expression-regex-68-320.jpg)
정규표현식 Regular expression (regex)
- 1. Regualar expression (정규표현식) 김선영 sunyzero@gmail(dot)com 버 전: 2016-10-13 가메 출판사 http://www.kame.co.kr 인사이트 http://blog.insightbook.co.kr 저자블로그 http://sunyzero.tistory.com
- 2. Preface Regular Expression (정규표현식)의 약칭 REGEX(리젝스,레젝스) 혹은 RE라고 표현하기도 한다. string pattern은 문자열의 조합되는 규칙 meta charater는 다른 의미를 수식하는 문자 grep은 정규식을 평가할 수 있는 유틸리티입니다. egrep, fgrep은 grep의 특화된 버전입니다. sed는 스트림 에디터입니다. awk는 패턴식을 다룰 수 있는 언어툴입니다.
- 3. 1. String pattern A. REGEX 종류 : POSIX, PCRE B. POSIX REGEX의 종류 : BRE, ERE 2. Utility : grep, sed, awk 3. POSIX REGEX 문법 A. REGEX meta characters B. Greedy Matching / Non-greedy Matching C. Back-slash D. Back-Reference / Alternation E. Substitution F. Boundary G. Character class H. Hangul
- 4. String, pattern 문자열 중에는 일정한 규칙이 존재하는 경우가 있다. e-mail 주소의 경우 : 중간에 @ 문자가 등장 @ 문자의 오른쪽은 dot 와 영문, 아스키코드로 이루어짐; 왼쪽은 계정명 Web URL의 경우 : http:// 으로 시작 호스트이름뒤에는 URI 가 붙고 디렉토리구조로 명명 CGI 기법이 사용될 경우에 ? 이 등장할수도 있음 IPv4 주소의 경우 : 111.222.111.222 의 4개의 숫자로 이루어져 있다.
- 5. REGEX의 예시 요상해 보이지만 배우고 나면 별것 아니다. 몇 시간이면 다 배울 수 있는 간단한 것들이다. a.cdef? [a-zA-Z]+ .*boy (caret|dollar) (.*/)[^/]* ^Do.*?$ http://([a-zA-Z0-9.-])/.* https?://.*?(.*) REGEX를 배운 뒤에 해석해봅시다!
- 6. REGEX : POSIX, PCRE REGEX에는 여러 변종이 있지만 가장 유명한 것은 아래 2가지: POSIX REGEX UNIX 계열 표준 정규표현식 PCRE (Perl Compatible Regular Expression) Perl 정규표현식 호환으로 확장된 기능을 가지고 있다.
- 7. REGEX : POSIX REGEX POSIX REGEX UNIX 계열 표준 정규표현식 POSIX 표준 BRE (Basic RE), ERE (Extended RE)가 있다. 기능도 적은데 꼭 POSIX REGEX를 배워야 하나? POSIX REGEX부터 배워야 다른 변종 REGEX를 접할 때 혼란을 줄일 수 있 다.
- 8. REGEX : POSIX RE : BRE, ERE POSIX REGEX에서 제공되는 2가지 기법 BRE : Basic REGEX grep이 작동되는 기본값 ERE : Extended REGEX 좀 더 많은 표현식과 편의성을 제공한다. 다음에 나올 meta character중에 ERE라고 적혀있는 것을 의미한다. egrep의 기본값이다. POSIX ERE를 기준으로 배워두는게 초반에는 혼동을 줄일 수 있다.
- 9. REGEX : PCRE Perl Compatible Regular Expression Perl에서 제공되던 REGEX의 기능이 매우 훌륭하여... 이를 다른 언어에서도 제공하기 위해 만들어진 기능 C언어 기반으로 시작 POSIX REGEX에 비해 좀 더 성능이 좋다. 현재는 PCRE2 버전을 사용 과거 PCRE에서 사용되던 pcregrep은 pcre2grep으로 버전업 알아두면 도움이 된다. 하지만 부담스럽다면 조금 나중에 배워도 된다.
- 10. REGEX and EBNF REGEX와 EBNF 문법 특히 *, +, ?, [...]는 EBNF의 영향이 크다. EBNF를 포멀한 형태로 패턴화 즉 EBNF를 알고 있다면 학습이 쉬워진다. * EBNF (Extended Backus-Naur Form)
- 11. 1. String pattern A. REGEX 종류 : POSIX, PCRE B. POSIX REGEX의 종류 : BRE, ERE 2. Utility : grep, sed, awk 3. POSIX REGEX 문법 A. REGEX meta characters B. Greedy Matching / Non-greedy Matching C. Back-slash D. Back-Reference / Alternation E. Substitution F. Boundary G. Character class
- 12. REGEX : command line utility grep (global regular expression print) 유닉스에서 가장 기본적인 REGEX 평가 유틸리티 sed stream editor로서 REGEX 기능을 일부 탑재하고 있다. awk REGEX뿐만 아니라 문자열 관련의 방대한 기능을 가진 프로그래밍 언어 제일 많은 기능을 가지고 있다. awk를 만든 사람이 누군지 알아두는 것도 좋다. grep >>> sed >>> awk 순으로 공부를 하는 편이 좋다. 여기서는 지면상 가장 기초적인 grep, egrep을 중점적으로 살펴보겠다. (아주 가끔 sed, awk의 일부 기능을 소개하겠지만... 그냥 넘어가도 무방하다)
- 13. grep : matcher selection grep 실행시 matcher를 고를 수 있다. -G BRE를 사용하여 작동한다. (기본값) -E ERE를 사용하여 작동한다. egrep으로 작동시킨 것과 같다. -P PCRE를 사용하여 작동한다. pcre2grep으로 작동시킨 것과 같다. -F 고정길이 문자열을 탐색하는 모드로 작동한다. 실상은 fgrep과 같다. 장점 : 속도가 빠르다.
- 14. grep : options grep 주요 옵션 --color Surround the matched (non-empty) strings. -o Print only the matched (non-empty) parts of a matching line -e PATTERN Use PATTERN as the pattern. This can be used to specify multiple search patterns, or to protect a pattern beginning with a hyphen (-).
- 15. grep : options grep 주요 옵션 -v, --invert-match Invert the sense of matching, to select non-matching lines. -c Suppress normal output; instead print a count of matching lines for each input file. -q, --quite Quiet; do not write anything to standard output. Exit immediately with zero status if any match is found, even if an error was detected.
- 16. 1. String pattern A. REGEX 종류 : POSIX, PCRE B. POSIX REGEX의 종류 : BRE, ERE 2. Utility : grep, sed, awk 3. POSIX REGEX 문법 A. REGEX meta characters B. Greedy Matching / Non-greedy Matching C. Back-slash D. Back-Reference / Alternation E. Substitution F. Boundary G. Character class
- 17. POSIX REGEX: meta char. 문자 지정 . 임의의 문자 한 개를 의미합니다. 반복 지정 ? 선행문자패턴이 0개 혹은 1개 나타납니다. - ERE + 선행문자패턴이 1개 이상 반복됩니다. - ERE * 선행문자패턴이 0개 이상 반복됩니다. {m,n} (interval) 반복수를 직접 지정할 수 있습니다. - ERE m이나 n중에 하나를 생략할 수 있다. (예) {3} : 3번 반복 {,7} : 7번 이하 {2,5} : 2~5번 반복 위치 지정 ^ 라인의 앞부분을 의미합니다. $ 라인의 끝부분을 의미합니다. 그룹 지정 [...] 안에 지정된 문자들 그룹 중에 한 문자를 지정합니다. [^...] 안에 지정된 그룹의 문자를 제외한 나머지(여집합)를 지정합니다. 기타 (escape) 메타의 의미를 없애줍니다. | (alternation,choice) OR연산을 합니다. - ERE ( ) 괄호는 패턴을 그룹화 및 백레퍼런스의 작동을 합니다. - ERE * ERE - Extended Regular Expression (ERE를 사용하면 약간의 속도 저하가 발생하는 플랫폼도 있으나 큰 차이는 없다.) * POSIX RE - IEEE std 1003.1 (International standard)
- 18. Any single character dot/period : . - any single character c.b : cab, cbb, ccb, cdb, c1b, c2b 등등 a..b : axyb, a12b, ax0b, a#-b 등등 a.........b : 이런 방식으로는 쓰지 않는다. quantifier, interval 기법을 쓰는 것이 더 현명하기 때문이다. (바로 뒷장에서 살펴보자) $ var3='abc cab cbb ccb zxy cdb c1b c2b c.b c*b 123' $ echo $var3 | grep --color 'c.b' abc cab cbb ccb zxy cdb c1b c2b c.b c*b 123 $ echo $var3 | grep --color 'c.b' abc cab cbb ccb zxy cdb c1b c2b c.b c*b 123 * 예제 타이핑시 맨 앞의 $ 문자는 프롬프트이므로 타이핑하지 않는다. * 예제는 bash shell prompt에서 실행하는 것으로 가정한다.
- 19. Quantifier (수량자) ?, +, *, {m,n} - 수량자의 종류는 총 4가지이다. 수량자는 선행문자패턴(or atom이라고도 함)을 수식하는 기능을 가진다. 아래 패턴의 의미를 생각해보자. X?ML can* can+ http.* ? : question mark * : asterisk, star + : plus sign {}: (curly) braces
- 20. Quantifier (수량자) X?ML : XML or ML ?앞에 문자인 X가 0개 혹은 1개가 존재한다. can* : ca, can, cann, cannn, ... *앞에 문자인 n이 0개 이상 존재한다. can+ : can, cann, cannn, cannnn, ... +앞에 문자인 n이 1개 이상 존재한다. http.* : http://, httpd, https, http1234 ... "http"뒤에 어떤 문자도 붙을 수 있다. 혹은 붙지 않을 수도 있다. 참고로 * 수량자만 BRE (Basic RE)이다. 당연히 나머지 수량자는 ERE이다. ? : question mark * : asterisk, star + : plus sign {}: (curly) braces ? 수량자가 수식하는 선행문자패턴은 X이다.
- 21. Quantifier (수량자) {m,n} - interval expression abc{2,5} : abcc, abccc, abcccc, abccccc interval expression은 몇몇 유틸, RE matching engine에서는 지원 않는다. e.g. awk (gawk는 --re-interval 옵션으로 interval expression을 켤 수 있다) {n} {n,} {n,m}은 표준이고, {,m}은 GNU extension이다. 연습 : ?, *, +를 { }으로 표현하면? {0,}는 무엇일까? {,1}는 무엇일까? {1,}는 무엇일까? ? : question mark * : asterisk, star + : plus sign {}: (curly) braces
- 22. EBNF vs REGEX quantifier * (The Kleene Star) vs (The Kleene Plus) 곱셈은 0을 곱하면 0이 된다. = 즉 * 는 0개 이상을 의미한다. 덧셈은 0을 더하면 1이 된다. = 즉 + 는 1개 이상을 의미한다. 단순하게 외우기보다는 이해를 하고나면 잊어버리지 않는다. * (The Kleene Star) = means 0 or more occurrences C를 임의의 문자라고 할 때 : C * 0 = NULL (C를 0을 곱하면) C * 1 = C (C에 1을 곱하면) C * 2 = CC (C에 2를 곱하면) C * 3 = CCC ... C * n = n (즉 *는 0개 이상) + (The Kleene Plus) = means 1 or more occurrences C를 임의의 문자라고 할 때 : C + NULL = C (C에 0을 더하면) C + "1개의 C" = CC (1개의 C를 더하면) C + "2개의 C" = CCC (2개의 C를 더하면) C + "3개의 C" = CCCC ... C + "n개의 C" = (즉 +는 1개 이상)
- 23. Quantifier (수량자) : BRE vs ERE grep은 기본값으로 BRE로 작동하므로 : * 수량자만 바로 사용 가능 +, ?, { } 패턴은 (back-slash)를 앞에 더해줘야만 한다. egrep은 기본값으로 ERE로 작동하므로 : *, +, ?, { } 패턴의 모든 기능이 기본적으로 제공된다. egrep을 사용하는 모드를 기본으로 배워두는게 좀 더 편리하다. 자세한 차이는 back-slash를 다룰때 다시 다루겠다. 여기서는 * 수량자만 BRE 기능이라는 점만 숙지하고 대충 넘어가자. ? : question mark * : asterisk, star + : plus sign {}: (curly) braces
- 24. Anchor ^, $ - 패턴의 위치를 지정하는 패턴이다. ^ftp : "ftp"로 시작하는 행 ^$ : 비어있는 행 (행의 시작과 끝에 아무런 문자도 없다) <BR>$ : <BR>로 끝나는 경우 간혹 라인단위 처리를 하지 않는 경우, 즉 개행문자(newline) 단위로 처리하지 않는 경우에는 $는 문서의 끝을 의미한다. ^ : caret $ : dollar sign
- 25. Character sets [ ], [^ ] - character class [abcd] : a, b, c, d 중에 하나 [0-9] : 0, 1, 2, ... , 9 [a-zA-Z0-9] : 대소문자 알파벳과 숫자 [^0-9] : [0-9]을 제외한 나머지 ^ 문자 자체를 그룹에 넣으려면? ^이 [ 바로 뒤에만 오지 않으면 된다. [0-9^] 혹은 escape 시키거나... [ ] : (square) brackets
- 26. Practice #1-a : POSIX BRE REGEX로 단어를 검색해보자. (붉은색 부분이 매칭된 결과) 패턴 해석 p 가 등장하고, 그 다음에 [a-d]중에 적어도 1번 이상이 등장하고, 그 다음에 ous가 등장하는 경우 $ grep --color "p[abcd]+ous" /usr/share/dict/words opacous opacousness semiopacous
- 27. Practice #1-b : POSIX BRE anchor를 이용해서 패턴을 수정 패턴 해석 p가 등장하고, 그 다음에 [a-d]중에 적어도 1번 이상이 등장하고, 그 다음에 ous가 매칭의 끝 부분에 등장하는 경우 $가 지정되면 그 뒤로는 라인의 끝을 의미한다. $ grep --color "p[abcd]+ous$" /usr/share/dict/words opacous semiopacous
- 28. Practice #2 log data를 검색 (아래와 같은 로그가 있다고 가정 : 파일명 exjournal.log 으로 가정) May 09 18:02:40 dev03.rh0xhf su[43726]: (to root) sunyzero on pts/14 May 09 18:02:40 dev03.rh0xhf su[43726]: pam_systemd(su-l:session): Cannot create session May 09 18:02:40 dev03.rh0xhf su[43726]: pam_unix(su-l:session): session opened for user root by (uid=1000) May 10 14:07:58 dev03.rh0xhf systemd[1272]: Time has been changed May 10 15:35:56 dev03.rh0xhf su[43726]: pam_unix(su-l:session): session closed for user root May 20 22:40:10 dev03.rh0xhf su[31978]: pam_unix(su-l:session): session closed for user root May 25 17:11:54 dev03.rh0xhf systemd[1272]: Time has been changed May 30 15:51:30 dev03.rh0xhf su[63881]: (to root) sunyzero on pts/5 May 30 15:51:30 dev03.rh0xhf su[63881]: pam_systemd(su-l:session): Cannot create session May 30 15:51:30 dev03.rh0xhf su[63881]: pam_unix(su-l:session): session opened for user root by (uid=1000) May 30 15:54:53 dev03.rh0xhf su[63881]: pam_unix(su-l:session): session closed for user root May 30 15:55:16 dev03.rh0xhf su[63977]: (to root) sunyzero on pts/5 May 30 15:55:16 dev03.rh0xhf su[63977]: pam_systemd(su-l:session): Cannot create session May 30 15:55:16 dev03.rh0xhf su[63977]: pam_unix(su-l:session): session opened for user root by (uid=1000) May 30 15:57:28 dev03.rh0xhf su[63977]: pam_unix(su-l:session): session closed for user root pam_systemd가 session 생성에 실패한 로그만 뽑아 보고 싶다. = pam_systemd 문자열이 들어간 행만 뽑아내야 한다.
- 29. Practice #2 (con't) grep 활용. (붉은색 강조된 부분이 매칭된 결과) $ grep --color pam_systemd exjournal.log May 09 18:02:40 dev03.rh0xhf su[43726]: pam_systemd(su-l:session): Cannot create session May 30 15:51:30 dev03.rh0xhf su[63881]: pam_systemd(su-l:session): Cannot create session May 30 15:55:16 dev03.rh0xhf su[63977]: pam_systemd(su-l:session): Cannot create session $ grep --color -A 1 "pam_systemd" exjournal.log May 09 18:02:40 dev03.rh0xhf su[43726]: pam_systemd(su-l:session): Cannot create session May 09 18:02:40 dev03.rh0xhf su[43726]: pam_unix(su-l:session): session opened for user root by (uid=1000) -- May 30 15:51:30 dev03.rh0xhf su[63881]: pam_systemd(su-l:session): Cannot create session May 30 15:51:30 dev03.rh0xhf su[63881]: pam_unix(su-l:session): session opened for user root by (uid=1000) -- May 30 15:55:16 dev03.rh0xhf su[63977]: pam_systemd(su-l:session): Cannot create session May 30 15:55:16 dev03.rh0xhf su[63977]: pam_unix(su-l:session): session opened for user root by (uid=1000) 패턴 매칭에서 다음 행을 뽑아주는 패턴은 없다. 이건 grep의 옵션(-A, -B)으로 해결할 문제이다. 실패한 유저명은 그 다음행의 로그에 나온다. 매칭에 성공한 행의 뒷 행을 출력하려면?
- 30. Tip! - grep : line control options -A NUM, --after-context=NUM Print NUM lines of trailing context after matching lines. -B NUM, --before-context=NUM Print NUM lines of leading context before matching lines. -C NUM, -NUM, --context=NUM Print NUM lines of output context. e.g.) -C 1 equal to -A 1 -B 1 --group-separator=SEP Use SEP as a group separator. By default SEP is double hyphen (--). --no-group-separator Use empty string as a group separator.
- 31. 1. String pattern A. REGEX 종류 : POSIX, PCRE B. POSIX REGEX의 종류 : BRE, ERE 2. Utility : grep, sed, awk 3. POSIX REGEX 문법 A. REGEX meta characters B. Greedy Matching / Non-greedy Matching C. Back-slash D. Back-Reference / Alternation E. Substitution F. Boundary G. Character class
- 32. Greedy matching greedy matching 이란? pattern 은 최대한 많은 수의 매칭을 하려고 하는 성질이 있다. <.+>이 <b>이 아니라 <b>real ... </i>까지 매칭된 결과 = greedy matching greedy matching 후 result set의 범위를 줄여나가면서 정확한 표현식을 완성하도록 해야 한다. <b>real ... </i>의 result set에서 <b> 만 뽑아내려면? 표현식을 더 세밀하게 작성하면 된다. = 뒷장에서 살펴보자. $ var2="It’s gonna be <b>real</b>It’s gonna <i>change everything</i> I feel" $ echo $var2 | egrep -o "<.+>" <b>real</b>It's gonna <i>change everything</i> * 예제 타이핑시 맨 앞의 $ 문자는 프롬프트이므로 타이핑하지 않는다.
- 33. Greedy matching (con't) <.+> 에서 임의의 문자인 . 를 [^<>] 표현으로 변경하면? $ var2="It’s gonna be <b>real</b>It’s gonna <i>change everything </i> I feel" $ echo $var2 | egrep -o "<.+>" <b>real</b>It's gonna <i>change everything</i> $ echo $var2 | egrep -o "<[^<>]+>" <b> </b> <i> </i> <.+> . [^<>] 태그 부분만 뽑아낸 결과다. greedy matching된 결과에서 더 세밀하게 패턴을 조정했다.
- 34. Non-greedy matching 최소 매칭 기능 == greedy matching의 반대 개념 앞서 <.+> 대신에 [ 을 사용하면 최소 매칭이 되는데... POSIX RE에서는 패턴을 수정하여 non-greedy matching 효과와 같은 결과의 패턴을 만든다. POSIX RE에서는 non-greedy matching 수량자를 제공하지는 않는다. 따라서 패턴을 변경해서 non-greedy matching 결과를 만드는 것이다. 하지만 PCRE는 non-greedy matching을 쉽게 할 수 있는 quantifier를 제공한다. 이를 lazy quantifier라고 부른다. <[^<>]+>
- 35. Non-greedy matching : lazy quantifier Lazy quantifier (PCRE 기능) lazy quantifier를 사용하면 non-greedy matching을 쉽게 할 수 있다. 단지 quantifier에 suffix로 ?를 더하면 된다. PCRE에서만 지원되므로 POSIX REGEX 모드에서는 사용할 수 없다. * grep -P : PCRE matcher를 사용하도록 한다. pcre2grep을 사용해도 된다. $ echo $var2 | grep -P -o "<.+?>" <b> </b> <i> </i> PCRE의 Lazy quantifier를 이용해서 non-greedy matching을 간단하게 표현할 수 있다.
- 36. Non-greedy matching (con't) On POSIX RE : It dosen't support non-greedy matching. On PCRE : It can be non-greedy matching by lazy quantifier. * 예제 타이핑시 맨 앞의 $ 문자는 프롬프트이므로 타이핑하지 않는다. $ echo $var2 | egrep -o "<[^<>]+>" <b> </b> <i> </i> $ echo $var2 | grep -P -o "<.+?>" <b> </b> <i> </i>
- 37. 1. String pattern A. REGEX 종류 : POSIX, PCRE B. POSIX REGEX의 종류 : BRE, ERE 2. Utility : grep, sed, awk 3. POSIX REGEX 문법 A. REGEX meta characters B. Greedy Matching / Non-greedy Matching C. Back-slash D. Back-Reference / Alternation E. Substitution F. Boundary G. Character class
- 38. Back-slash meta char.의 의미를 없앤다. 아래 2가지 패턴의 차이는? 1번 패턴 : c.b cab, cbb, ccb, cdb, c1b, c2b 등등이지만... 2번 패턴 : c.b c.b : dot(.)가 메타의 의미가 아닌 진짜 일반 문자 '.'을 의미하게 된다. $ var3='abc cab cbb ccb zxy cdb c1b c2b c.b c*b 123' $ echo $var3 | grep --color 'c.b' abc cab cbb ccb zxy cdb c1b c2b c.b c*b 123 $ echo $var3 | grep --color 'c.b' abc cab cbb ccb zxy cdb c1b c2b c.b c*b 123
- 39. Back-slash (con't) BRE에서 ERE의 일부 기능을 표현할 때 사용한다. 예를 들어 : ERE의 {m,n}을 BRE로 표현할 때 {m,n} 으로 사용한다. ERE의 ?을 BRE로 표현할 때 ? 으로 사용한다. ?, +, { }, |, ( )에 대해 back-slash를 사용한다. (BRE인 경우에만...) BRE에서 back-slash를 ERE pattern으로 해석하도록 하는 용도로 사용하는 경우 는 가끔 헷갈릴 수 있으므로, 왠만하면 ERE만 사용하는 것이 좋다. 즉 egrep을 사용하는 경우에는 back-slash가 필요없다. 예제로 살펴보자.
- 40. Back-slash (con't) BRE에서 ERE의 ?, { }, +, |, ( ) 패턴 사용시 앞에 사용. grep은 기본값으로 BRE를 사용하므로 위와 같이 + 으로 사용해야 한다. * 는 BRE이므로 back-slash를 사용할 필요가 없다. $ echo $var3 | grep --color '[0-9bc]*' abc cab cbb ccb zxy cdb c1b c2b c.b c*b 123 $ echo $var3 | grep --color '[0-9bc]+' 매칭 실패!!! 아무것도 출력되지 않는다. (왜냐하면 +가 ERE이기 때문이다) $ echo $var3 | grep --color '[0-9bc]+' abc cab cbb ccb zxy cdb c1b c2b c.b c*b 123 +앞에 를 사용해야 성공!
- 41. Back-slash (con't) back-slash를 문자 앞에 두는 행동을... escape 시킨다고 표현한다. 예를 들어 . 으로 적으면 ". 을 이스케이프 시켰다"고 표현한다. 왜 escape 라고 표현할까? Parser의 의미를 생각해보면 직관적으로 이해할 수 있을것이다. 그래도 모르겠다면 숙제~~ .
- 42. Practice #3 : back-slash BRE vs ERE : 우선 BRE의 특징부터 살펴보자. $ var4='URLs : http://asdf.com/en/ , https://asdf.com/en/' $ echo $var4 | grep --color 'http://[A-Za-z./]*' URLs : http://asdf.com/en/ , https://asdf.com/en/ var4 변수에 URL 주소를 2개 넣었다. 그리고 grep을 이용해서 'http://[A-Za-z./]*' 패턴 적용
- 43. Practice #3 : back-slash BRE vs ERE : 앞서 패턴에서 +를 추가했더니 실패한다. 해법은? ERE에서 사용되는 메타 문자앞에 back-slash 추가! $ echo $var4 | grep --color 'http://[A-Za-z./]+' 매칭 실패!!! 아무것도 출력되지 않는다. (왜냐하면 +가 ERE이기 때문이다) $ echo $var4 | grep --color 'http://[A-Za-z./]+' URLs : http://asdf.com/en/ , https://asdf.com/en/ +는 ERE이므로 BRE가 기본인 grep에서는 +를 인식하지 못하고 실패한다. 하지만 +앞에 back-slash를 추가해주면 성공한다.
- 44. Practice #3 : back-slash BRE vs ERE : ERE를 사용하는 egrep에서는 굳이 back-slash가 없어도 된다. $ echo $var4 | egrep --color 'http://[A-Za-z./]+' URLs : http://asdf.com/en/ , https://asdf.com/en/ ERE를 사용하는 경우에는 grep -E 혹은 egrep 으로 명령한다.
- 45. Practice #4-a www.naver.com 페이지에서 URL 링크를 추출해보자. curl : 터미널에서 웹 페이지를 접속하는 유틸 $ curl -s http://www.naver.com | egrep -o 'http://[0-9A-Za-z.]+/' http://www.naver.com/ http://static.naver.net/ http://www.naver.com/ http://static.naver.net/ ...생략... $ curl -s http://www.naver.com | egrep --color 'http://[0-9A-Za-z.]+/' ...생략... ERE를 사용하는 egrep은 +앞에 back-slash를 사용하지 않아도 된다.
- 46. Practice #4-b www.naver.com 페이지에서 URL 링크를 추출해보자. 중복되는 링크를 제거해보자. $ curl -s http://www.naver.com | egrep -o 'http://[0-9A-Za-z.]+/' | sort | uniq http://blog.naver.com/ http://cafe.naver.com/ http://castbox.shopping.naver.com/ http://cecs.naver.com/ http://entertain.naver.com/ ...생략...
- 47. Practice #4-c www.naver.com 페이지에서 URL 링크를 추출해보자. img 태그만 추출해보자. $ curl -s http://www.naver.com | egrep -o "<img [^<>]+>" <img data-src="http://img.naver.net/static/www/dl_qr_naver.png" width="68" height="8 4" alt="네이버 앱 QR코드" /> <img data-src="http://img.naver.net/static/www/up/2012/naver_homepage.png" width="88 0" height="31" alt="시작페이지" usemap="#sliding" /> ...생략...
- 48. Tip! BRE vs ERE 어떤 툴이 BRE를 사용하는지 ERE를 사용하는지 알아두면 언제 back-slash를 붙여야 하는지 쉽게 판단할 수 있다. BRE를 사용하는 유틸 grep (기본값), vim, sed ... ERE를 사용하는 유틸 egrep, awk PCRE는 별개의 문제지만 기본적으로 ERE를 베이스로 한다.
- 49. Practice #4-d www.naver.com 페이지에서 URL 링크를 추출해보자. 아래 ERE를 BRE로 바꿔보자 (egrep대신에 grep을 사용하도록 한다.) $ curl -s http://www.naver.com | egrep -o "<img [^<>]+>" $ curl -s http://www.naver.com | egrep -o 'http://[0-9A-Za-z.]+/' | sort | uniq $ curl -s http://www.naver.com | grep -o "<img [^<>]+>" $ curl -s http://www.naver.com | grep -o 'http://[0-9A-Za-z.]+/' | sort | uniq BRE를 사용할 때는 어디에 back-slash를 추가해야 하는지 기억해두자.
- 50. 1. String pattern A. REGEX 종류 : POSIX, PCRE B. POSIX REGEX의 종류 : BRE, ERE 2. Utility : grep, sed, awk 3. POSIX REGEX 문법 A. REGEX meta characters B. Greedy Matching / Non-greedy Matching C. Back-slash D. Back-Reference / Alternation E. Substitution F. Boundary G. Character class
- 51. ( ) : Back-reference, subst. , alternation ( ) 괄호는 여러가지 기능으로 사용된다. back-reference group alternation 기능에도 group 기능을 사용한다.
- 52. Back-reference 매칭된 결과를 다시 사용하는 패턴 (백레퍼런스) "( )"로 묶인 패턴 매칭 부분을 "#"의 형태로 재사용 (#는 숫자가 순서대로), 0번은 전체 매칭 결과 options -v : invert --color : Surround the matched (non-empty) strings $ egrep "^(.+):x:[0-9]+:[0-9]+:.*:/home/1:" /etc/passwd sunyzero:x:500:500:Steven Kim:/home/sunyzero:/bin/bash linuxer:x:502:502::/home/linuxer:/bin/bash $ egrep -v "^(.+):x:[0-9]+:[0-9]+:.*:/home/1:" /etc/passwd ... (생략, 상상하시기 바랍니다) ... ( ) : parenthesis
- 53. Back-reference (con’t) back-reference 응용 : tag로 감싸여진 부분 추출 $ var2='It’s gonna be <b>real</b>It’s gonna <i>change everything</i> I feel' $ echo $var2 | egrep -o '<([a-zA-Z0-9]+)>.*</1>' <b>real</b> <i>change everything</i> $ echo $var2 | egrep --color '<([a-zA-Z0-9]+)>.*</1>' ... 생략 ...
- 54. Alternation ( )는 alternation 용도로도 사용됨 "( )" alternation 이나 pattern group을 묶을때도 사용된다. 묶을 때 사용했어도 back-reference의 기능도 함께 가진다. $ echo "cat is not dog" | egrep -o "(cat|dog)" cat dog $ echo "My Childhood~~~ bye bye" | egrep -o "(child|boy)?hood" hood
- 55. Practice #4-e www.naver.com 페이지에서 URL 링크를 추출해보자. <a ...> ... </a> 로 감싸진 태그 내용을 추출해보자. (a|A) 부분이 back-reference가 되고 첫번째 소괄호이므로 1 이 된다. (a|A) : a 혹은 A가 등장하는 경우 $ curl -s http://www.naver.com | egrep -o "<(a|A) [^<>]+>.+</1>" <a href="http://www.navercorp.com/" target="_blank" id="plc.intronhn">회사소개</a> <a href="http://mktg.naver.com/" id="plc.adinfo">광고</a> <a href="https://help.naver.com/" id="plc.helpcenter">네이버 고객센터</a> <a href="https://submit.naver.com/" id="plc.search">마이비즈니스</a> ...생략... egrep이므로 ERE를 사용하고 있는데, grep의 BRE로 바꿔서 사용하려면?
- 56. Practice #4-e (con't) grep의 BRE로 변경해보면? BRE에서는 ERE meta character인 ?, +, { }, ( ) , | 를 escape 시켜야 한다. $ curl -s http://www.naver.com | grep -o "<(a|A) [^<>]+>.+</1>" <a href="http://www.navercorp.com/" target="_blank" id="plc.intronhn">회사소개</a> <a href="http://mktg.naver.com/" id="plc.adinfo">광고</a> <a href="https://help.naver.com/" id="plc.helpcenter">네이버 고객센터</a> <a href="https://submit.naver.com/" id="plc.search">마이비즈니스</a> ...생략...
- 57. Practice #4-f www.naver.com 페이지에서 URL 링크를 추출해보자. jpg, png 확장자를 가진 파일 링크만 추출해보자. 주의 할 점은 확장자는 대문자일 수도 있다. 즉 JPG, jpg 둘다 잡아내야 한다. 위 REGEX의 .은 진짜 dot 문자를 의미하는 것이다. (.을 이스케이프 시킨 것!) $ curl -s http://www.naver.com | egrep -o 'http://[0-9A-Za-z./_]+.(jpg|JPG|png|PNG)' http://img.naver.net/static/www/dl_qr_naver.png http://img.naver.net/static/www/up/2012/naver_homepage.png http://img.naver.net/static/www/mobile/edit/2016/0609/mobile_16305721761.jpg http://img.naver.net/static/www/mobile/edit/2016/0610/mobile_164630175157.JPG http://img.naver.net/static/www/m/guide/dummy_1X1.jpg ...생략...
- 58. 1. String pattern A. REGEX 종류 : POSIX, PCRE B. POSIX REGEX의 종류 : BRE, ERE 2. Utility : grep, sed, awk 3. POSIX REGEX 문법 A. REGEX meta characters B. Greedy Matching / Non-greedy Matching C. Back-slash D. Back-Reference / Alternation E. Substitution F. Boundary G. Character class
- 59. Substitution - sed (stream ed) sed에서 제일 많이 쓰는 기능이 substitution이다. sed의 subst. 기능은 vim의 substitution command와 같다. sed의 substitution에서 separator는 slash(/)를 많이 쓰지만 comma(,)를 쓰기 도 한다. 기계적으로 slash만 쓰는 걸로 외웠다면 지식을 업데이트 하자! vim의 substitution command는 sed의 기능이 포함된 것뿐이다! = sed를 알면 vim도 알고... UNIX는 이렇게 서로 연관된 기능들이 많다. sed는 BRE를 기반으로 하므로 + 로 표현되었다. $ echo $var2 | sed -e "s/<[^<>]+>/ /g" It's gonna be real It's gonna change everything I feel $ echo $var2 | sed -e "s,<[^<>]+>, ,g" < > : chevron
- 60. Substitution - awk awk에서도 위의 모든 기능을 구현할 수 있다. awk의 gsub(global substitution)에서 REGEX로 교체하는 방법이다. awk는 ERE를 사용하므로 + 앞에 back slash를 쓰지 않는다. $ echo $var2 | awk '{ gsub(/[ ]*<[^<>]+>[ ]*/, " "); print }' It’s gonna be real It’s gonna change everything I feel { } : (curly) brace
- 61. Practice #4-e www.naver.com 페이지에서 URL 링크를 제거해보자. <a ...> ... </a> 로 감싸진 태그 내용을 일반 메시지로 변경해보자. ( ), |, + 앞에 back-slash를 쓴 이유는? sed는 BRE를 쓰기 때문이다. ERE를 쓰려면 -r 옵션을 사용하면 된다. $ curl -s http://www.naver.com | sed -n "s,<(a|A) [^<>]+>(.+)</1>,2,gp" <dd class="f">회사소개</dd> <dd>광고</dd> <dd>네이버 고객센터</dd> <dd>마이비즈니스</dd> ...생략...
- 62. 1. String pattern A. REGEX 종류 : POSIX, PCRE B. POSIX REGEX의 종류 : BRE, ERE 2. Utility : grep, sed, awk 3. POSIX REGEX 문법 A. REGEX meta characters B. Greedy Matching / Non-greedy Matching C. Back-slash D. Back-Reference / Substitution / Alternation E. Boundary F. Character class
- 63. Boundary - ERE word 경계 검색에 사용 b boundary가 맞는 표현식만 찾는다. (단어 경계면 검색) B boundary에 맞지 않는 표현식만 찾는다. (단어 경계면이 아닌 경우만 검색) $ var5="abc? <def> 123hijklm" $ echo $var5 | egrep -o "[a-j]+" abc def hij $ echo $var5 | egrep --color "b[a-j]+b" abc? <def> 123hijklm $ echo $var5 | egrep --color "B[a-j]+B" abc? <def> 123hijklm
- 64. Predefined character class 클래스 설 명 [[:alnum:]] 알파벳과 숫자들의 모음 [[:alpha:]] 알파벳들 (대소문자) [[:blank:]] Tab(t)을 의미 [[:cntrl:]] 제어문자들을 의미 [[:digit:]] 숫자들을 의미 [[:xdigit:]] 16진수(hex)형 숫자들을 의미, 즉 0-9a-fA-F 를 포함한다. [[:upper:]] 알파벳 대문자 [[:lower:]] 알파벳 소문자 [[:space:]] tab(t), CR(r), New line(n) 을 포함한다. [[:print:]] 출력 가능한 문자들 [[:graph:]] 공백을 제외한 문자들 [[:punct:]] 출력 가능한 특수문자들
- 65. Predefined character class (con't) [...]안에 조합가능 sunyzero@email까지만 잘렸다. 모두 나오게 하려면? $ var5="[email protected]:010-8500-80**:Sun-young Kim:AB-0105R" $ echo $var5 | egrep -o "^[[:alpha:]@]+" sunyzero@email $ echo $var5 | egrep -o "[[:upper:][:digit:]-]{8}" 010-8500 AB-0105R
- 66. REGEX and PCRE POSIX REGEX 간단한 패턴 매칭에 사용된다. 패턴의 복잡함이 늘어나면 성능저하가 발생. 처음엔 POSIX REGEX부터 학습해야만 한다.- Standard니까! PCRE (Perl Compatible Regular Expr.) Perl에서 파생된 확장된 정규표현식 매우 빠른 속도, 확장된 표현식에... C, C++, 기타 대부분의 언어가 지원한다. (추가 라이브러리로 제공) 실무라면 PCRE를 사용하는 편이 낫다. 다음 챕터에서 배우자.
- 67. Practice #5 IPv4 address를 REGEX로 표현하면? IPv4주소는 각 요소가 0~255 (0xff)사이의 값만을 가져야만 한다. 두자리 이상의 숫자 범위에 대해 정의하려면? Hint : 0~63까지 표현하려면... [0-9]{,3}.[0-9]{,3}.[0-9]{,3}.[0-9]{,3} 이 표현식은 IP주소로는 틀렸다. 왜냐하면 단순하게 숫자 3개만 검사하므로, 333.469.789.1 처럼 범위를 벗어나도 매칭성공된다. (6[0-3]|[5-1][0-9]|[0-9])
- 68. Practice #6 : Hangul, Hanja i18n을 만족하는 Linux는 UTF-8 한글 처리도 가능하다. $ cat <<HEREDOC >hangul-utf8.txt This is ascii text in UTF-8 character-set. 한글은 한국어에서 사용되는 문자이다. 여기 UTF8로 인코딩된 한글과 한자(漢字)가 보이는가? HEREDOC $ egrep --color '한.' hangul-utf8.txt 한글은 한국어에서 사용되는 문자이다. 여기 UTF8로 인코딩된 한글과 한자(漢字)가 보이는가? $ egrep --color '한[글자]' hangul-utf8.txt 한글은 한국어에서 사용되는 문자이다. 여기 UTF8로 인코딩된 한글과 한자(漢字)가 보이는가? $ egrep --color '..字' hangul-utf8.txt 한글은 한국어에서 사용되는 문자이다. 여기 UTF8로 인코딩된 한글과 한자(漢字)가 보이는가? * 첫번째 cat 명령은 redirection의 HERE document기법이다.