Retargeting Embedded Software Stack for Many-Core Systems
Download as PPTX, PDF2 likes1,360 views

The document discusses the challenges and advancements in many-core systems, focusing on collaborative research at the University of North Carolina. It highlights issues with existing embedded software stacks, communication methods, and innovative techniques for achieving scalable applications in various domains. Key areas include scalable scheduling, resource allocation, and the development of middleware for better concurrency management.



























![Message-passing over
shared-memory
Correctness
Hard to achieve in explicit threading (even in task-based libraries)
Lock-based programs are not composable
―Perhaps the most fundamental objection [...] is that lock-based programs do not compose: correct fragments may fail when
combined. For example, consider a hash table with thread-safe insert and delete operations. Now suppose that we want to
delete one item A from table t1, and insert it into table t2; but the intermediate state (in which neither table contains the item)
must not be visible to other threads. Unless the implementer of the hash table anticipates this need, there is simply no way to
satisfy this requirement. [...] In short, operations that are individually correct (insert, delete) cannot be composed into larger
correct operations.‖
—Tim Harris et al., "Composable Memory Transactions", Section 2: Background, pg.2
Message-passing
Composable
Easy to verify and debug
Observe in/out messages only](https://image.slidesharecdn.com/esc-204slidestambe-120406161205-phpapp02/85/Retargeting-Embedded-Software-Stack-for-Many-Core-Systems-30-320.jpg)








Retargeting Embedded Software Stack for Many-Core Systems
- 2. Agenda What‘s happening in many-core world? New Challenges Collaborative Research Real-Time Innovations (RTI) University of North Carolina What we (RTI) do, briefly! Research: Retargeting embedded software stack for many-core systems Components Scalable multi-core Scheduling Scalable communication Middleware Modernization
- 3. Single-core Multi-core Many-Core Interconnect Interconnect Solution Transistor count Interconnect CPU clock speed and power consumption hit a wall circa 2004
- 4. 100‘s of cores available today
- 5. Applications Domains using Multi-core Defense Transportation Financial trading Telecommunications Factory automation Traffic control Medical imaging Simulation 5
- 6. Grand Challenge and Prize Scalable Applications Running faster with more cores Inhibitors Embedded software stack (OS, m/w, and apps) not designed for more than a handful of cores ○ One core maxed-out others idling! ○ Overuse of communication via shared-memory ○ Severe cache coherence overhead Advanced techniques known only to experts ○ Programming languages and paradigms Lack of design and debugging tools
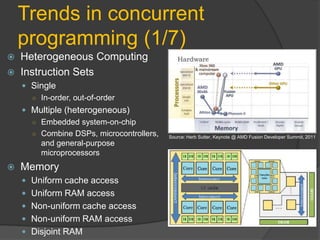
- 7. Trends in concurrent programming (1/7) Heterogeneous Computing Instruction Sets Single ○ In-order, out-of-order Multiple (heterogeneous) ○ Embedded system-on-chip ○ Combine DSPs, microcontrollers, Source: Herb Sutter, Keynote @ AMD Fusion Developer Summit, 2011 and general-purpose microprocessors Memory Uniform cache access Uniform RAM access Non-uniform cache access Non-uniform RAM access Disjoint RAM
- 8. Trends in concurrent programming (2/7) Message-passing instead of shared-memory ―Do not communicate by sharing memory. Instead, share memory by communicating. ‖ Source: Andrew Baumann, et. al, Multi-kernel: A new OS – Google Go Documentation architecture for scalable multicore systems, SOSP‘09 (small data, messages sent to a single server) Costs less than shared-memory Scales better on many-core ○ Shown up to 80 cores Easier to verify and debug Bypass cache coherence Data locality is very important Source: Silas Boyd-Wickizer, Corey: An Operating System for Many Cores, USENIX 2008
- 9. Trends in concurrent programming (3/7) Shared-Nothing Partitioning Data partitioning ○ Single Instruction Multiple Data (SIMD) ○ a.k.a ―sharding‖ in DB circles ○ Matrix multiplication on GPGPU ○ Content-based filters on stock symbols (―IBM‖, ―MSFT‖, ―GOOG‖)
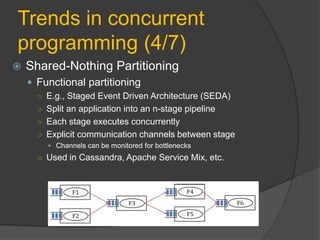
- 10. Trends in concurrent programming (4/7) Shared-Nothing Partitioning Functional partitioning ○ E.g., Staged Event Driven Architecture (SEDA) ○ Split an application into an n-stage pipeline ○ Each stage executes concurrently ○ Explicit communication channels between stage Channels can be monitored for bottlenecks ○ Used in Cassandra, Apache Service Mix, etc.
- 11. Trends in concurrent programming (5/7) Erlang-Style Concurrency (Actor Model) Concurrency-Oriented Programming (COP) Fast asynchronous messaging Selective message reception Copying message-passing semantics (share-nothing concurrency) Process monitoring Fast process creation/destruction Ability to support >> 10 000 concurrent processes with largely unchanged characteristics Source: http://ulf.wiger.net
- 12. Trends in concurrent programming (6/7) Consistency via Safely Shared Resources Replacing coarse-grained locking with fine- grained locking Using wait-free primitives Using cache-conscious algorithms Exploit application-specific data locality New programming APIs ○ OpenCL, PPL, AMP, etc.
- 13. Trends in concurrent programming (7/7) Effective concurrency patterns Wizardry Instruction Manuals!
- 14. Explicit Multi-threading: Too much to worry about! 1. The Pillars of Concurrency (Aug 2007) 2. How Much Scalability Do You Have or Need? (Sep 2007) 3. Use Critical Sections (Preferably Locks) to Eliminate Races (Oct 2007) 4. Apply Critical Sections Consistently (Nov 2007) 5. Avoid Calling Unknown Code While Inside a Critical Section (Dec 2007) 6. Use Lock Hierarchies to Avoid Deadlock (Jan 2008) 7. Break Amdahl‘s Law! (Feb 2008) 8. Going Super-linear (Mar 2008) 9. Super Linearity and the Bigger Machine (Apr 2008) 10. Interrupt Politely (May 2008) 11. Maximize Locality, Minimize Contention (Jun 2008) 12. Choose Concurrency-Friendly Data Structures (Jul 2008) 13. The Many Faces of Deadlock (Aug 2008) 14. Lock-Free Code: A False Sense of Security (Sep 2008) 15. Writing Lock-Free Code: A Corrected Queue (Oct 2008) 16. Writing a Generalized Concurrent Queue (Nov 2008) 17. Understanding Parallel Performance (Dec 2008) 18. Measuring Parallel Performance: Optimizing a Concurrent Queue(Jan 2009) 19. volatile vs. volatile (Feb 2009) 20. Sharing Is the Root of All Contention (Mar 2009) 21. Use Threads Correctly = Isolation + Asynchronous Messages (Apr 2009) 22. Use Thread Pools Correctly: Keep Tasks Short and Non-blocking(Apr 2009) 23. Eliminate False Sharing (May 2009) 24. Break Up and Interleave Work to Keep Threads Responsive (Jun 2009) 25. The Power of ―In Progress‖ (Jul 2009) 26. Design for Many-core Systems (Aug 2009) 27. Avoid Exposing Concurrency – Hide It Inside Synchronous Methods (Oct 2009) 28. Prefer structured lifetimes – local, nested, bounded, deterministic(Nov 2009) Source: POSA2: Patterns for Concurrent, Parallel, and 29. Prefer Futures to Baked-In ―Async APIs‖ (Jan 2010) Distributed Systems, Dr. Doug Schmidt 30. Associate Mutexes with Data to Prevent Races (May 2010) 31. Prefer Using Active Objects Instead of Naked Threads (June 2010) 32. Prefer Using Futures or Callbacks to Communicate Asynchronous Results (August 2010) 33. Know When to Use an Active Object Instead of a Mutex (September 2010) Source: Effective Concurrency, Herb Sutter
- 15. Threads are hard! Data race Deadlock Atomicity Violation Order Violation Forgotten Synchronization Incorrect Granularity Two-Step Dance Read and Write Tearing Priority Inversion Lock-Free Reordering Patterns for Achieving Safety Lock Convoys Immutability Purity Isolation Source: MSDN Magazine, Joe Duffy
- 17. Collaborative Research! Prof. James Anderson University of North Carolina Real-Time Innovations IEEE Fellow Sunnyvale, CA
- 19. Integrating Enterprise Systems with Edge Systems Enterprise System Edge System JMS App SQL App Temperature Web-Service Sensor GetTemp GetTemp Temp Temp Temperature Response Request SOAP JMS Adapter Socket Adapter DB Adapter Connector Connector Adapter Connector Connector RTPS Data-Centric Messaging Bus
- 20. Data-Centric Messaging Standards-based API for application developers Based on DDS Standard (OMG) DDS = Data Distribution Service Data Distribution DDS Services is an API specification RTI Data Distribution Service for Real-Time Systems Real-time provides publish-subscribe paradigm publish-subscribe wire protocol provides quality-of-service tuning uses interoperable wire protocol (RTPS) Open protocol for interoperability
- 21. DDS Communication Model Provides a ―Global Data Space‖ that is accessible to all interested applications. Data objects addressed by Domain, Topic and Key Subscriptions are decoupled from Publications Contracts established by means of QoS Automatic discovery and configuration Participant Participant Pub Pub Track,2 Participant Sub Sub Track,1 Track,3 Global Data Space Participant Pub Participant Alarm Sub
- 22. Data-Centric vs. Message-Centric Design Data-Centric Message-Centric Infrastructure does Infrastructure does not understand your data understand your data What data schema(s) will be Opaque contents vary from used message to message Which objects are distinct from No object identity; messages which other objects indistinguishable What their lifecycles are Ad-hoc lifecycle management How to attach behavior (e.g. Behaviors can only apply to filters, QoS) to individual whole data stream objects Example technologies Example technologies JMS API DDS API AMQP protocol RTPS (DDSI) protocol
- 23. Re-enabling the Free Lunch, Easily! Positioning applications to run faster on machines with more cores—enabling the free lunch! Three Pillars of Concurrency Coarse-grained parallelism (functional partitioning) Fine-grained parallelism (running a ‗for‘ loop in parallel) Reducing the cost of resource sharing (improved locking)
- 24. Scalable Communication and Scheduling for Many-Core Systems Objectives Create a Component Framework for Developing Scalable Many-core Applications Develop Many-Core Resource Allocation and Scheduling Algorithms Investigate Efficient Message-Passing Mechanisms for Component Dataflow Architect DDS Middleware to Improve Internal Concurrency Demonstrate ideas using a prototype
- 25. Component-based Software Engineering C C Facilitate Separation of Concerns Functional partitioning to enable MIMD-style parallelism Manage resource allocation and scheduling algorithms Ease of application lifecycle management Component-based Design Naturally aligned with functional partitioning (pipeline) Components are modular, cohesive, loosely coupled, and independently deployable
- 26. Component-based Software Engineering C Message passing communication C C Isolation of state C Shared-nothing concurrency Ease of validation Lifecycle management Application design Transformation Deployment Resource allocation Scheduling Deployment and Configuration Placement based on data-flow dependencies Cache-conscious placement on cores Formal Models
- 27. Scheduling Algorithms for Many-core Academic Research Partner Real-Time Systems Group, Prof. James Anderson University of North Carolina, Chapel Hill Processing Graph Method (PGM) Clustered scheduling on many-core G1 N nodes G2 G3 to M cores G4 G5 N nodes to G6 M cores G7 Tilera TILEPro64 Multi-core Processor. Source: Tilera.com
- 28. Scheduling Algorithms for Many-cores Key requirements Efficiently utilizing the processing capacity within each cluster Minimizing data movement across clusters Exploit data locality A many-core Processor An on-chip distributed system! Cores are addressable Send messages to other cores directly On-chip networks (interconnect) ○ MIT RAW = 4 networks ○ Tilera iMesh = 6 networks ○ On chip switches, routing algorithms, packet switching, multicast!, deadlock prevention E.g., Tilera iMesh Architecture. Source: Tilera.com Sending messages to distant core takes longer
- 29. Message-passing over shared-memory Two key issues Performance Correctness Performance Shared-memory does not scale on many-core Full chip cache coherence is expensive Too much power Too much bandwidth Not all cores need to see the update ○ Data stalls reduce performance Source: Ph.D. defense: Natalie Enright Jerger
- 30. Message-passing over shared-memory Correctness Hard to achieve in explicit threading (even in task-based libraries) Lock-based programs are not composable ―Perhaps the most fundamental objection [...] is that lock-based programs do not compose: correct fragments may fail when combined. For example, consider a hash table with thread-safe insert and delete operations. Now suppose that we want to delete one item A from table t1, and insert it into table t2; but the intermediate state (in which neither table contains the item) must not be visible to other threads. Unless the implementer of the hash table anticipates this need, there is simply no way to satisfy this requirement. [...] In short, operations that are individually correct (insert, delete) cannot be composed into larger correct operations.‖ —Tim Harris et al., "Composable Memory Transactions", Section 2: Background, pg.2 Message-passing Composable Easy to verify and debug Observe in/out messages only
- 31. Component Dataflow using DDS Entities
- 32. Core-Interconnect Transport for DDS RTI DDS Supports many transports for messaging UDP, TCP, Shared-memory, Zero-copy, etc In future: a ―core-interconnect transport‖!! Tilera provides Tilera Multicore Components (TMC) library Higher-level library for MIT RAW in progress
- 33. Erlang-Style Concurrency: A Panacea? Actor Model OO programming of the concurrency world Concurrency-Oriented Programming (COP) Fast asynchronous messaging Selective message reception Copying message-passing semantics (share-nothing concurrency) Process monitoring Fast process creation/destruction Ability to support >> 10 000 concurrent processes with largely unchanged characteristics Source: http://ulf.wiger.net
- 34. Actors using Data-Centric Messaging? Fast asynchronous messaging ○ < 100 micro-sec latency ○ Vendor neutral but old (2006) results ○ Source: Ming Xiong, et al., Vanderbilt University Selective Message Reception ○ Standard DDS data partitioning: Domains, Partitions, Topics ○ Content-based Filter Topic (e.g., ―key == 0xabcd‖) ○ Time-based Filter, Query conditions, Sample States etc. Copying message-passing semantics ―Process‖ monitoring RTI Fast ―process‖ creation/destruction RESEARCH >> 10,000 concurrent ―processes‖
- 35. Middleware Modernization Event-handling patterns Reactor ○ Offers coarse-grained concurrency control Proactor (asynchronous IO) ○ Decouples of threading from concurrency Concurrency Patterns Leader/follower ○ Enhances CPU cache affinity, minimizes locking overhead reduces latency Half-sync half-async ○ Faster low-level system services
- 36. Middleware Modernization Effective Concurrency (Sutter) Concurrency-friendly data structures ○ Fine-grained locking in linked-lists ○ Skip-list for fast parallel search i i i i ○ But compactness is important too! See Going Native 2012 Keynote by Dr. Stroustrup: Slide #45 (Vector vs. List) std::vector beats std::list in insertion and deletion! Reason: Linear search dominates. Compact = cache-friendly Data locality aspect ○ A first-class design concern ○ Avoid false sharing Lock-free data structures (Java ConcurrentHashMap) ○ New one will earn you a Ph.D. Processor Affinity and load-balancing ○ E.g., pthread_setaffinity_np
- 37. Concluding Remarks Scalable Communication and Scheduling for Many-Core Systems Research Create a Component Framework for Developing Scalable Many-core Applications Develop Many-Core Resource Allocation and Scheduling Algorithms Investigate Efficient Message-Passing Mechanisms for Component Dataflow Architect DDS Middleware to Improve Internal Concurrency
- 38. Thank you!