
















































































![87 Roadrunner Tutorial February 7, 2008
Overview of Installation
1. Install Operating System on hardware (diskless QS21 requires remote boot)
2. Uninstall SDK 2.1 or SDK 3.0 early release
3. Install pre-requisites including RHEL5.1 specifics:
• Install compat-libstdc++
• Install libspe2 runtimes
• Create and install ppu-sysroot RPMs for cross-compilation
4. Download installer RPM and required ISO images
• Physical media and product TAR file contain both and additional instructions (README.1st)
5. Install the SDK installer
• rpm -ivh cell-install-3.0.0.1.0.noarch.rpm
6. Start the install
• cd /opt/cell
• ./cellsdk [--iso <isodir>] [--gui] install
7. Perform post-install configuration
• RHEL 5.1 specifics (elfspe on QS21, libspe2 and netpbm development libraries
• Complete IDE install into Eclipse and CDT
• Configure DaCS daemons for DaCS for Hybrid-x86 and ALF for Hybrid-x86
• Sync up the Simulator sysroot (Fedora 7 only)](https://image.slidesharecdn.com/roadrunnertutorial-240621130609-ff78d5d4/85/Roadrunner-Tutorial-An-Introduction-to-Roadrunner-and-the-Cell-Processor-87-320.jpg)
















































![138 Roadrunner Tutorial February 7, 2008
ALF - Buffer management on accelerators
ƒ ALF manages buffer allocation on accelerators’ local memory
ƒ ALF runtime provides pointers to 5 different buffers to a
computational kernel
– Task context buffer (RO and RW sections)
– Work block parameters
– Input Buffer
– Input/Output Buffer
– Output Buffer
ƒ ALF implements a best effort double buffering scheme
– ALF determines if there is enough local memory for double buffering
ƒ Double buffer scenarios supported by ALF
– 4 buffers: [In0, Out0; In1, Out1]
– 3 buffers: [In0, Out0; In1] : [Out1; In2, Out2]](https://image.slidesharecdn.com/roadrunnertutorial-240621130609-ff78d5d4/85/Roadrunner-Tutorial-An-Introduction-to-Roadrunner-and-the-Cell-Processor-138-320.jpg)






















Roadrunner Tutorial: An Introduction to Roadrunner and the Cell Processor
- 1. Roadrunner Tutorial An Introduction to Roadrunner and the Cell Processor Cornell Wright HPC-DO [email protected] February 7, 2008 Paul Henning CCS-2 [email protected] Ben Bergen CCS-2 [email protected] LA-UR-08-2818
- 2. 2 Roadrunner Tutorial February 7, 2008 Contents ƒ Roadrunner Project ƒ Roadrunner Architecture ƒ Cell Processor Architecture ƒ Cell SDK ƒ DaCS and ALF ƒ Accelerating an Existing Application ƒ References
- 3. 3 Roadrunner Tutorial February 7, 2008 Contents ƒ Roadrunner Project ƒ Roadrunner Architecture ƒ Cell Processor Architecture ƒ Cell SDK ƒ DaCS and ALF ƒ Accelerating an Existing Application ƒ References
- 4. 4 Roadrunner Tutorial February 7, 2008 Phase I Phase II Phase III Redtail Base System 76 teraflop/s Advanced Algorithms Evaluation of Cell potential for HPC Replacement for Q Opteron Cluster Roadrunner 1.3 petaflop/s Opteron Cluster Cell Accelerated Roadrunner Project Phases
- 5. 5 Roadrunner Tutorial February 7, 2008 Jan 10 Dec 09 Nov 09 Oct 09 Sept 09 Aug 09 July 09 Jun 09 May 09 Apr 09 Mar 09 Feb 09 Jan 09 Dec 08 Nov 08 Oct 08 Sep 08 Aug 08 Start System Delivery Start System Delivery Start Acceptance Start Acceptance Finish Acceptance Finish Acceptance Connect File Systems Connect File Systems Start System & code stabilization Start System & code stabilization Start Science runs Including VPIC Weapons science Start Science runs Including VPIC Weapons science Finish science runs & Stabilization (estimated) Finish science runs & Stabilization (estimated) Secure System Availability After Initial Integration Secure System Availability After Initial Integration Start Accreditation Start Accreditation Finish Accreditation (estimated) Finish Accreditation (estimated) 1 3 2 Roadrunner Phase 3 work plan - Draft Schedules
- 6. 6 Roadrunner Tutorial February 7, 2008 Roadrunner Phase 1 CU layout (Redtail) 288-port IB4x SDR Switch 144+144 To 2nd Stage Switch 143 12 I/O Nodes GE MVLAN GE CVLAN-n SMC Switch Terminal Server 96 131 Compute Nodes Disk Service Node IB IB IB4x SDR IB 4 dual core Opterons
- 7. 7 Roadrunner Tutorial February 7, 2008 Roadrunner Phase 3 layout is almost identical ISR9288 IB4x DDR Switch 192+96 To 2nd Stage Switch 143 12 I/O Nodes GE MVLAN GE CVLAN-n BCMM BC Switch Terminal Server 96 180 Compute Triblades Disk Service Node IB DDR IB4x DDR IB DDR 2 dual core Opterons + 4 Cell Accelerators
- 8. 8 Roadrunner Tutorial February 7, 2008 Contents ƒ Roadrunner Project ƒ Roadrunner Architecture ƒ Cell Processor Architecture ƒ Cell SDK ƒ DaCS and ALF ƒ Accelerating an Existing Application ƒ References
- 9. 9 Roadrunner Tutorial February 7, 2008 ƒ Observation that traditional clusters are straining to reach PF scale: – Processor core performance slowing – Practical limits on network size and cost – Programming challenges with 10Ks of nodes – Technology discontinuity driving price/performance – Accelerators offer promise of 10x reduction in $/MF Interest in Hybrid Computing
- 10. 10 Roadrunner Tutorial February 7, 2008 ƒ Specialized engines can perform selected tasks more efficiently (faster, cheaper, cooler, etc.) than general-purpose cores. ƒ Development of hardware (e.g. PCI-express) and software (e.g. Linux) standards provide convenient attachment points. ƒ Parallelism (e.g. SIMD) exploits increasing number of gates available in each chip generation. ƒ Accelerators have been around for a long time! ™ FPS AP120B, IBM 3838, Intel 80387/80487, Weitek, Atari ANTIC, S3 911 Why Accelerators?
- 11. 11 Roadrunner Tutorial February 7, 2008 Roadrunner Goal: PetaFlop Performance ƒ Provide a large “capacity-mode” computing resource – Purchased in FY2006 and presently in production – Robust HPC architecture with known usability for LANL codes ƒ Upgrade to petascale-class hybrid “accelerated” architecture in 2008 – Follow future trends toward hybrid/heterogeneous computers – More and varied “cores” and special function units – Capable of supporting future LANL weapons physics and science at scale – IBM & LANL strategic collaboration – Capable of achieving a sustained PetaFlop/s
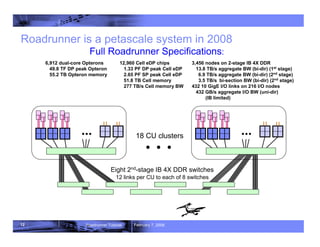
- 12. 12 Roadrunner Tutorial February 7, 2008 Roadrunner is a petascale system in 2008 6,912 dual-core Opterons 49.8 TF DP peak Opteron 55.2 TB Opteron memory 3,456 nodes on 2-stage IB 4X DDR 13.8 TB/s aggregate BW (bi-dir) (1st stage) 6.9 TB/s aggregate BW (bi-dir) (2nd stage) 3.5 TB/s bi-section BW (bi-dir) (2nd stage) 432 10 GigE I/O links on 216 I/O nodes 432 GB/s aggregate I/O BW (uni-dir) (IB limited) Full Roadrunner Specifications: 12,960 Cell eDP chips 1.33 PF DP peak Cell eDP 2.65 PF SP peak Cell eDP 51.8 TB Cell memory 277 TB/s Cell memory BW 18 CU clusters 12 links per CU to each of 8 switches Eight 2nd-stage IB 4X DDR switches
- 13. 13 Roadrunner Tutorial February 7, 2008 Roadrunner Phase 3 is Cell-accelerated, not a cluster of Cells Node-attached Cells is what makes Roadrunner different! Node-attached Cells is what makes Roadrunner different! • • • (100’s of such cluster nodes) Add Cells to each individual node Multi-socket multi-core Opteron cluster nodes Cell-accelerated compute node I/O gateway nodes “Scalable Unit” Cluster Interconnect Switch/Fabric
- 14. 14 Roadrunner Tutorial February 7, 2008 ƒCluster of 18 Connected Units –6,912 AMD dual-core Opterons –12,960 IBM Cell eDP accelerators –49.8 Teraflops peak (Opteron) –1.33 Petaflops peak (Cell eDP) –1PF sustained Linpack ƒInfiniBand 4x DDR fabric –2-stage fat-tree; all-optical cables –Full bi-section BW within each CU –384 GB/s (bi-directional) –Half bi-section BW among CUs –3.45 TB/s (bi-directional) –Non-disruptive expansion to 24 CUs ƒ107 TB aggregate memory –55 TB Opteron –52 TB Cell ƒ216 GB/s sustained File System I/O: –216x2 10G Ethernets to Panasas ƒRHEL & Fedora Linux ƒSDK for Multicore Acceleration ƒxCAT Cluster Management –System-wide GigEnet network ƒ3.9 MW Power: –0.35 GF/Watt ƒArea: –296 racks –5500 ft2 Roadrunner at a glance
- 15. 15 Roadrunner Tutorial February 7, 2008 ƒLS21 AMD Host Blade ƒDual socket dual core AMD Opteron ƒDDR2 direct attach DIMM ƒExpansion Card ƒ2 HT2100 HT<->PCIe bridges ƒQS22 Based Accelerator Blades ƒDual PowerXCell 8i Sockets ƒDDR2 direct attach DIMM ƒAMD Host to Cell eDP connectivity ƒTwo x8 PCIe Host to QS22 links Integrated Hybrid Node
- 16. 16 Roadrunner Tutorial February 7, 2008 HT x16 To misc. I/O: USB & 2x 1GbE etc AMD Dual Core HT2000 PCI-E x8 HT x8 HT x16 PCI-X LS21 HSDC Connector No HSDC DDR2 DDR2 DDR2 DDR2 DDR2 DDR2 DDR2 DDR2 2 x HT 16x Exp. Conn. IB IP x4 DDR HSDC Connector PCI-e 8x IB 1P x4 DDR Std PCIe Connector 2 x HT 16x Exp. Conn. OR PowerXCell 8i / AMD TriBlade (Dual Core Opteron, IB-DDR) ƒ AMD Host Blade + Expansion – Dual socket dual core AMD Opteron (2 x 7.2 GFLOPS) – LS21 + 2 by HT 16x connector – DDR2 direct attach DIMM channels – 16 GB – 10.7 GB/s/socket (0.48 B/FLOP) – New Expansion Card – 2 HT2100 HT<->PCI-e bridges ƒ QS22 Accelerator Blade – Dual PowerXCell 8i Sockets – 204 GFLOPS @ 3.2Ghz (2 x 102 GFLOPS) – DDR2 direct attach DIMM channels – 8 GB – 25.6 GB/s per PowerXCell 8i chip* (0.25 B/FLOP) – AMD Host to PowerXCell 8i connectivity – Two x8 PCIe Host to CB2 links – ~2+2 GB/s/link Æ ~4+ 4 GB/s total POR – New PCI-e Redrive card ƒ Node design points: – One Cell chip per Opteron core – ~400 GF/s double-precision & ~800 GF/s single-precision – 16 GB Cell memory & 16 GB Opteron Memory 2x PCI-E 8x To misc. I/O: USB etc PowerXCell 8i PowerXCell 8i PCI-E x16 PCI CB2 PCI-E x16 PCI-X PCI-E x8 PCI-E x8 Legacy Conn. DDR2 DDR2 DDR2 DDR2 DDR2 DDR2 DDR2 DDR2 2xPCI-E x16 Redrive IBM Southbridge 2x PCI-E 8x To misc. I/O: USB etc PowerXCell 8i PowerXCell 8i PCI-E x16 PCI CB2 PCI-E x16 PCI-X PCI-E x8 PCI-E x8 Legacy Conn. DDR2 DDR2 DDR2 DDR2 DDR2 DDR2 DDR2 DDR2 Redrive IBM Southbridge IBM Southbridge IBM Southbridge 2xPCI-E x16 Legacy Connector HT2100 HT2100 AMD Dual Core
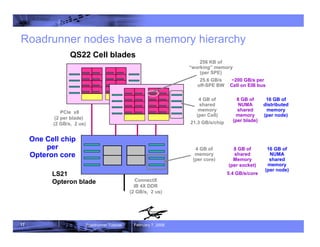
- 17. 17 Roadrunner Tutorial February 7, 2008 Roadrunner nodes have a memory hierarchy 4 GB of memory (per core) 4 GB of shared memory (per Cell) 21.3 GB/s/chip 256 KB of “working” memory (per SPE) 25.6 GB/s off-SPE BW ConnectX IB 4X DDR (2 GB/s, 2 us) PCIe x8 (2 per blade) (2 GB/s, 2 us) QS22 Cell blades LS21 Opteron blade 8 GB of NUMA shared memory (per blade) 8 GB of shared Memory (per socket) 5.4 GB/s/core 16 GB of NUMA shared memory (per node) 16 GB of distributed memory (per node) ~200 GB/s per Cell on EIB bus One Cell chip per Opteron core
- 18. 18 Roadrunner Tutorial February 7, 2008 Tooling Tooling DaCSd To other cluster nodes Opteron Blade Application MPI Accelerated Lib ALF/DaCS Host O/S DD IDE gdb Trace Analysis Cell Blade Tooling IDE Analysis DaCSd Accelerated Lib ALF/DaCS Compilers/Profiling/etc. CellBE Linux Hybrid Node System Software Stack Cell Blade Tooling IDE Analysis DaCSd Accelerated Lib ALF/DaCS Compilers/Profiling/etc. CellBE Linux
- 19. 19 Roadrunner Tutorial February 7, 2008 Three types of processors work together. ƒ Parallel computing on Cell – data partitioning & work queue pipelining – process management & synchronization ƒ Remote communication to/from Cell – data communication & synchronization – process management & synchronization – computationally-intense offload ƒ MPI remains as the foundation Opteron Opteron PPE PPE SPE (8) SPE (8) DaCS (OpenMPI) ALF or libSPE OpenMPI (cluster) x86 compiler PowerPC compiler SPE compiler PCIe IB EIB Cell
- 20. 20 Roadrunner Tutorial February 7, 2008 Using Roadrunner’s memory hierarchy: Today with Hybrid DaCS and Supplemented Tomorrow with ALF 4 GB of shared memory per core 2.7 GB/s/core 4 GB of shared memory (per Cell) 21.3 GB/s/chip 256 KB of “working” memory per SPE ConnectX IB 4X DDR (2 GB/s, 2 us) PCIe x8 (2 GB/s, 2-4 us) Cell blade Opteron node SPE work tiles upload DaCS put pre-fetch DMA gets write-behind DMA puts additional temporary data download DaCS puts multi-physics mesh data single-physics mesh data ALF
- 21. 21 Roadrunner Tutorial February 7, 2008 Roadrunner Early Hardware (Poughkeepsie)
- 22. 22 Roadrunner Tutorial February 7, 2008 Contents ƒ Roadrunner Project ƒ Roadrunner Architecture ƒ Cell Processor Architecture ƒ Cell SDK ƒ DaCS and ALF ƒ Accelerating an Existing Application ƒ References
- 23. 23 Roadrunner Tutorial February 7, 2008 Three Major Limiters to Processor Performance ƒ Frequency Wall – Diminishing returns from deeper pipelines ƒ Memory Wall – Processor frequency vs. DRAM memory latency – Latency introduced by multiple levels of memory ƒ Power Wall – Limits in CMOS technology – Hard limit to acceptable system power
- 24. 24 Roadrunner Tutorial February 7, 2008 Where have all of the transistors gone? ƒ Memory and memory management – Larger and larger cache sizes needed for visible improvement ƒ Trying to extract parallelism – Long pipelines with lots of interlock logic – Superscalar designs (multiple pipelines) with even more interlocks! – Branch prediction to effectively utilize the pipelines – Speculative execution – Out-of-order execution – Hardware threads The amount of transistors doing direct computation is shrinking relative to the total number of transistors.
- 25. 25 Roadrunner Tutorial February 7, 2008 Techniques for Better Efficiency ƒ Chip level multi-processors – Go back to simpler core designs and use the extra available chip area for multiple cores. ƒ Vector Units/SIMD – Have the same instruction execution logic operate on multiple pieces of data concurrently; allows for more throughput with little increase in overhead. ƒ Rethink memory organization – At the register level hidden registers with register renaming is transparent to the end user but expensive to implement. Can a compiler do better with more instruction set architected registers? – Caches are automatic but not necessarily the most efficient use of chip area. Temporal and spatial locality mean little when processing streams of data.
- 26. 26 Roadrunner Tutorial February 7, 2008 Today Microprocessor Design: Power Constrained ƒ Transistor performance scaling – Channel off-current & gate-oxide tunneling challenges supply voltage scaling – Material and structure changes required to stay on Moore’s Law – Power per (switched) transistor decreases only slowly Chip Power Consumption increases faster as before Î Microprocessor performance limited by processor transistor power efficiency Î We know how to design processors we cannot reasonably cool or power Net: Increasing Performance requires Increasing Power Efficiency Moore’s Law: 2x transistor density every 18-24 months
- 27. 27 Roadrunner Tutorial February 7, 2008 Hardware Accelerators Concept ƒ Streaming Systems use Architecture to Address Power/Area/Performance challenge – Processing unit with many specialized co- processor cores – Storage hierarchy (on chip private, on chip shared, off-chip) explicit at software level – Applications coded for parallelism with localized data access to minimize off chip access ƒ Advantage demonstrated per chip and per Watt of ~100x on well behaved applications (graphics, media, dsp,…) Concept/Key Ideas Augment standard CPU with many (8-32) small, efficient, hardware accelerators (SIMD or vector) with private memories, visible to applications. Rewrite code to highly parallel model with explicit on-chip vs. off- chip memory. Stream data between cores on same chip to reduce off-chip accesses.
- 28. 28 Roadrunner Tutorial February 7, 2008 Cell BE Solutions ƒ Increase concurrency – Multiple cores – SIMD/Vector operations in a core – Start memory movement early so that memory is available when needed ƒ Increase efficiency – Simpler cores devote more resources to actual computation – Programmer managed memory is more efficient than dragging data through caches – Large register files give the compiler more flexibility and eliminate transistors needed for register renaming – Specialize processor cores for specific tasks
- 29. 29 Roadrunner Tutorial February 7, 2008 Other (Micro)Architectural and Decisions ƒ Large shared register file ƒ Local store size tradeoffs ƒ Dual issue, In order ƒ Software branch prediction ƒ Channels Microarchitecture decisions, more so than architecture decisions show bias towards compute-intensive codes
- 30. 30 Roadrunner Tutorial February 7, 2008 The Cell BE Concept ƒ Compatibility with 64b Power Architecture™ – Builds on and leverages IBM investment and community ƒ Increased efficiency and performance – Attacks on the “Power Wall” – Non Homogenous Coherent Multiprocessor – High design frequency @ a low operating voltage with advanced power management – Attacks on the “Memory Wall” – Streaming DMA architecture – 3-level Memory Model: Main Storage, Local Storage, Register Files – Attacks on the “Frequency Wall” – Highly optimized implementation – Large shared register files and software controlled branching to allow deeper pipelines ƒ Interface between user and networked world – Image rich information, virtual reality, shared reality – Flexibility and security ƒ Multi-OS support, including RTOS / non-RTOS – Combine real-time and non-real time worlds
- 31. 31 Roadrunner Tutorial February 7, 2008 Cell Synergy ƒ Cell is not a collection of different processors, but a synergistic whole – Operation paradigms, data formats and semantics consistent – Share address translation and memory protection model ƒ PPE for operating systems and program control ƒ SPE optimized for efficient data processing – SPEs share Cell system functions provided by Power Architecture – MFC implements interface to memory – Copy in/copy out to local storage ƒ PowerPC provides system functions – Virtualization – Address translation and protection – External exception handling ƒ EIB integrates system as data transport hub
- 32. 32 Roadrunner Tutorial February 7, 2008 State of the Art: Intel Core 2 Duo Guess where the cache is?
- 33. 33 Roadrunner Tutorial February 7, 2008 State of the Art: IBM Power 5 How about on this one?
- 34. 34 Roadrunner Tutorial February 7, 2008 Unconventional State of the Art: Cell BE memory warehousing vs. in-time data processing
- 35. 35 Roadrunner Tutorial February 7, 2008 Today’s x86 Quad Core processors are Dual Chip Modules (DCMs), 2 of these processor stacked vertically & packaged together Cell/B.E. - ½ the space & power vs traditional approaches On any traditional processor, shown ratio of cores to cache, prediction, & related items illustrated here remains at ~50% of area the chip area Example Dual Core 349mm2, 3.4 GHz @ 150W 2 Cores, ~54 SP GFlops Cell/B.E. 3.2 GHz 9 Cores, ~230 SP GFlops
- 36. 36 Roadrunner Tutorial February 7, 2008 Cell BE Architecture
- 37. 37 Roadrunner Tutorial February 7, 2008 Cell Architecture is … COHERENT BUS Power ISA MMU/BIU Power ISA MMU/BIU … IO transl. Memory Incl. coherence/memory compatible with 32/64b Power Arch. Applications and OS’s 64b Power Architecture™
- 38. 38 Roadrunner Tutorial February 7, 2008 Cell Architecture is … 64b Power Architecture™ COHERENT BUS (+RAG) Power ISA +RMT MMU/BIU +RMT Power ISA +RMT MMU/BIU +RMT IO transl. Memory Plus Memory Flow Control (MFC) MMU/DMA +RMT Local Store Memory MMU/DMA +RMT Local Store Memory LS Alias LS Alias … … …
- 39. 39 Roadrunner Tutorial February 7, 2008 Cell Architecture is … 64b Power Architecture™+ MFC COHERENT BUS (+RAG) Power ISA +RMT MMU/BIU +RMT Power ISA +RMT MMU/BIU +RMT IO transl. Memory Plus Synergistic Processors MMU/DMA +RMT Local Store Memory MMU/DMA +RMT Local Store Memory LS Alias LS Alias … … … Syn. Proc. ISA Syn. Proc. ISA
- 40. 40 Roadrunner Tutorial February 7, 2008 Coherent Offload Model ƒ DMA into and out of Local Store equivalent to Power core loads & stores ƒ Governed by Power Architecture page and segment tables for translation and protection ƒ Shared memory model – Power architecture compatible addressing – MMIO capabilities for SPEs – Local Store is mapped (alias) allowing LS to LS DMA transfers – DMA equivalents of locking loads & stores – OS management/virtualization of SPEs – Pre-emptive context switch is supported (but not efficient)
- 41. 41 Roadrunner Tutorial February 7, 2008 Cell Broadband Engine TM: A Heterogeneous Multi-core Architecture * Cell Broadband Engine is a trademark of Sony Computer Entertainment, Inc.
- 42. 42 Roadrunner Tutorial February 7, 2008 Cell BE Block Diagram 16B/cycle BIC FlexIOTM MIC Dual XDRTM 16B/cycle EIB (up to 96B/cycle) 64-bit Power Architecture with VMX PPE SPE LS SXU SPU MFC PXU L1 PPU 16B/cycle L2 32B/cycle LS SXU SPU MFC LS SXU SPU MFC LS SXU SPU MFC LS SXU SPU MFC LS SXU SPU MFC LS SXU SPU MFC LS SXU SPU MFC
- 43. 43 Roadrunner Tutorial February 7, 2008 1 PPE core: - VMX unit - 32k L1 caches - 512k L2 cache - 2 way SMT
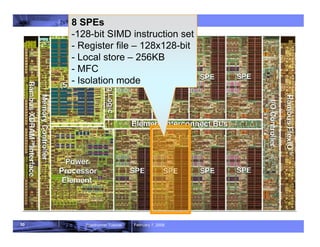
- 44. 44 Roadrunner Tutorial February 7, 2008 8 SPEs -128-bit SIMD instruction set - Register file – 128x128-bit - Local store – 256KB - MFC - Isolation mode
- 45. 45 Roadrunner Tutorial February 7, 2008 Element Interconnect Bus (EIB) - 96B / cycle bandwidth
- 46. 46 Roadrunner Tutorial February 7, 2008 System Memory Interface: - 16 B/cycle - 25.6 GB/s (1.6 Ghz)
- 47. 47 Roadrunner Tutorial February 7, 2008 I/O Interface: - 16 B/cycle x 2
- 48. 48 Roadrunner Tutorial February 7, 2008 1 PPE core: - VMX unit - 32k L1 caches - 512k L2 cache - 2 way SMT
- 49. 49 Roadrunner Tutorial February 7, 2008 Pre-Decode L1 Instruction Cache Microcode SMT Dispatch (Queue) Decode Dependency Issue Branch Scan Fetch Control L2 Interface VMX/FPU Issue (Queue) VMX Load/Store/ Permute VMX Arith./Logic Unit FPU Load/Store FPU Arith/Logic Unit Load/Store Unit Branch Execution Unit Fixed-Point Unit FPU Completion VMX Completion Completion/Flush 8 4 2 1 2 1 1 1 1 4 Thread A Thread B Threads alternate fetch and dispatch cycles Thread A Thread B Thread A L1 Data Cache PPE Block Diagram 1 1 1 2
- 50. 50 Roadrunner Tutorial February 7, 2008 8 SPEs -128-bit SIMD instruction set - Register file – 128x128-bit - Local store – 256KB - MFC - Isolation mode
- 51. 51 Roadrunner Tutorial February 7, 2008 SPE Block Diagram SPU Core (SXU) Channel Unit Local Store MFC (DMA Unit) SPU SPE To Element Interconnect Bus ƒ SPU Core: Registers & Logic ƒ Channel Unit: Message passing interface for I/O ƒ Local Store: 256KB of SRAM private to the SPU Core ƒ DMA Unit: Transfers data between Local Store and Main Memory
- 52. 52 Roadrunner Tutorial February 7, 2008 Local Store ƒ Never misses – No tags, backing store, or prefetch engine – Predictable real-time behavior – Less wasted bandwidth – Easier programming model to achieve very high performance – Software managed caching – Large register file –or– local memory – DMA’s are fast to setup – almost like normal load instructions – Can move data from one local store to another ƒ No translation – Multiuser operating system is running on control processor – Can be mapped as system memory - cached copies are non-coherent wrt SPU loads/stores
- 53. 53 Roadrunner Tutorial February 7, 2008 DMA & Multibuffering Init DMA Fetch Wait for Data Compute Init DMA Store Init DMA Fetch Wait for Data Compute Thread 2 Thread 1 Goto Thread 2 Goto Thread 1 DMA Transfers ƒDMA commands move data between system memory & Local Storage ƒDMA commands are processed in parallel with software execution ƒDouble buffering ƒSoftware Multithreading ƒ16 queued commands - up to 16 kB/command ƒUp to 16, 128 Byte, transfers in flight on the on chip interconnect ƒRicher than typical cache prefetch instructions ƒScatter-gather ƒFlexible DMA command status, can achieve low power wait
- 54. 54 Roadrunner Tutorial February 7, 2008 Channels: Message Passing I/O ƒ The interface from SPU core to rest of system ƒ Channels have capacity => allows pipelining ƒ Instructions: read, write, read capacity ƒ Effects appear at SPU core interface in instruction order ƒ Blocking reads & writes stall SPU in low power wait mode ƒ Example facilities accessible through the channel interface: – DMA control – counter-timer – interrupt controller – Mailboxes – Status ƒ Interrupts, BISLED
- 55. 55 Roadrunner Tutorial February 7, 2008 Permute Unit Load-Store Unit Floating-Point Unit Fixed-Point Unit Branch Unit Channel Unit Result Forwarding and Staging Register File Local Store (256kB) Single Port SRAM 128B Read 128B Write DMA Unit Instruction Issue Unit / Instruction Line Buffer 8 Byte/Cycle 16 Byte/Cycle 128 Byte/Cycle 64 Byte/Cycle On-Chip Coherent Bus SPE Block Diagram (Detailed)
- 56. 56 Roadrunner Tutorial February 7, 2008 SPE Instruction Issue ƒ In-order ƒ Dual issue requires alignment according to type ƒ Instruction Swap forces single issue ƒ Saves a pipeline stage & simplifies resource checking ƒ 9 units & 2 pipes chosen for best balance Byte Branch Floating Integer Local Store Shift Channel Single Precision Permute Simple Fixed instruction from address 4 instruction from address 0
- 57. 57 Roadrunner Tutorial February 7, 2008 SPE Pipeline Diagram 1 1 1 1 0 0 0 0 0 Pipe 4 Branch 4 Permute (PERM) 6 Load (LS) 7 Floating Integer (FP) 4 Byte (BYTE) 6 Single Precision (FP) 4 Shift (FX) 6 Channel 2 Simple Fixed (FX) Latency Instruction Class
- 58. 58 Roadrunner Tutorial February 7, 2008 SPE Branch Considerations ƒ Mispredicts cost 18 cycles ƒ No hardware history mechanism ƒ Branch penalty avoidance techniques – Write frequent path as inline code – Compute both paths and use select instruction – Unroll loops – also reduces dependency stalls – Load target into branch target buffer – Branch hint instruction – 16 cycles ahead of branch instruction – Single entry BTB
- 59. 59 Roadrunner Tutorial February 7, 2008 SPE Instructions ƒ Scalar processing supported on data-parallel substrate – All instructions are data parallel and operate on vectors of elements – Scalar operation defined by instruction use, not opcode – Vector instruction form used to perform operation ƒ Preferred slot paradigm – Scalar arguments to instructions found in “preferred slot” – Computation can be performed in any slot
- 60. 60 Roadrunner Tutorial February 7, 2008 Register Scalar Data Layout ƒ Preferred slot in bytes 0-3 – By convention for procedure interfaces – Used by instructions expecting scalar data – Addresses, branch conditions, generate controls for insert
- 61. 61 Roadrunner Tutorial February 7, 2008 Memory Management & Mapping
- 62. 62 Roadrunner Tutorial February 7, 2008 System Memory Interface: - 16 B/cycle - 25.6 GB/s (1.6 Ghz)
- 63. 63 Roadrunner Tutorial February 7, 2008 Legend: Data Bus Snoop Bus Control Bus Xlate Ld/St MMIO Local Store SPU DMA Engine DMA Queue Atomic Facility MMU RMT Bus I/F Control SPC MMIO MFC Detail Memory Flow Control System •DMA Unit •LS <-> LS, LS<-> Sys Memory, LS<-> I/O Transfers •8 PPE-side Command Queue entries •16 SPU-side Command Queue entries •MMU similar to PowerPC MMU •8 SLBs, 256 TLBs •4K, 64K, 1M, 16M page sizes •Software/HW page table walk •PT/SLB misses interrupt PPE •Atomic Cache Facility •4 cache lines for atomic updates •2 cache lines for cast out/MMU reload •Up to 16 outstanding DMA requests in BIU •Resource / Bandwidth Management Tables •Token Based Bus Access Management •TLB Locking Isolation Mode Support (Security Feature) ƒ Hardware enforced “isolation” – SPU and Local Store not visible (bus or jtag) – Small LS “untrusted area” for communication area ƒ Secure Boot – Chip Specific Key – Decrypt/Authenticate Boot code ƒ “Secure Vault” – Runtime Isolation Support – Isolate Load Feature – Isolate Exit Feature
- 64. 64 Roadrunner Tutorial February 7, 2008 Per SPE Resources (PPE Side) Problem State 8 Entry MFC Command Queue Interface DMA Command and Queue Status DMA Tag Status Query Mask DMA Tag Status 32 bit Mailbox Status and Data from SPU 32 bit Mailbox Status and Data to SPU 4 deep FIFO Signal Notification 1 Signal Notification 2 SPU Run Control SPU Next Program Counter SPU Execution Status 4K Physical Page Boundary 4K Physical Page Boundary Optionally Mapped 256K Local Store Privileged 1 State (OS) 4K Physical Page Boundary SPU Privileged Control SPU Channel Counter Initialize SPU Channel Data Initialize SPU Signal Notification Control SPU Decrementer Status & Control MFC DMA Control MFC Context Save / Restore Regs SLB Management Registers Privileged 2 State (OS or Hypervisor) 4K Physical Page Boundary SPU Master Run Control SPU ID SPU ECC Control SPU ECC Status SPU ECC Address SPU 32 bit PU Interrupt Mailbox MFC Interrupt Mask MFC Interrupt Status MFC DMA Privileged Control MFC Command Error Register MFC Command Translation Fault Register MFC SDR (PT Anchor) MFC ACCR (Address Compare) MFC DSSR (DSI Status) MFC DAR (DSI Address) MFC LPID (logical partition ID) MFC TLB Management Registers Optionally Mapped 256K Local Store 4K Physical Page Boundary
- 65. 65 Roadrunner Tutorial February 7, 2008 Per SPE Resources (SPU Side) 128 - 128 bit GPRs External Event Status (Channel 0) Decrementer Event Tag Status Update Event DMA Queue Vacancy Event SPU Incoming Mailbox Event Signal 1 Notification Event Signal 2 Notification Event Reservation Lost Event External Event Mask (Channel 1) External Event Acknowledgement (Channel 2) Signal Notification 1 (Channel 3) Signal Notificaiton 2 (Channel 4) Set Decrementer Count (Channel 7) Read Decrementer Count (Channel 8) 16 Entry MFC Command Queue Interface (Channels 16-21) DMA Tag Group Query Mask (Channel 22) Request Tag Status Update (Channel 23) Immediate Conditional - ALL Conditional - ANY Read DMA Tag Group Status (Channel 24) DMA List Stall and Notify Tag Status (Channel 25) DMA List Stall and Notify Tag Acknowledgement (Channel 26) Lock Line Command Status (Channel 27) Outgoing Mailbox to PU (Channel 28) Incoming Mailbox from PU (Channel 29) Outgoing Interrupt Mailbox to PU (Channel 30) SPU Direct Access Resources SPU Indirect Access Resources (via EA Addressed DMA) System Memory Memory Mapped I/O This SPU Local Store Other SPU Local Store Other SPU Signal Registers Atomic Update (Cacheable Memory)
- 66. 66 Roadrunner Tutorial February 7, 2008 Memory Flow Controller Commands LSA - Local Store Address (32 bit) EA - Effective Address (32 or 64 bit) TS - Transfer Size (16 bytes to 16K bytes) LS - DMA List Size (8 bytes to 16 K bytes) TG - Tag Group(5 bit) CL - Cache Management / Bandwidth Class DMA Commands Command Parameters Put - Transfer from Local Store to EA space Puts - Transfer and Start SPU execution Putr - Put Result - (Arch. Scarf into L2) Putl - Put using DMA List in Local Store Putrl - Put Result using DMA List in LS (Arch) Get - Transfer from EA Space to Local Store Gets - Transfer and Start SPU execution Getl - Get using DMA List in Local Store Sndsig - Send Signal to SPU Command Modifiers: <f,b> f: Embedded Tag Specific Fence Command will not start until all previous commands in same tag group have completed b: Embedded Tag Specific Barrier Command and all subsiquent commands in same tag group will not start until previous commands in same tag group have completed SL1 Cache Management Commands sdcrt - Data cache region touch (DMA Get hint) sdcrtst - Data cache region touch for store (DMA Put hint) sdcrz - Data cache region zero sdcrs - Data cache region store sdcrf - Data cache region flush Synchronization Commands Lockline (Atomic Update) Commands: getllar - DMA 128 bytes from EA to LS and set Reservation putllc - Conditionally DMA 128 bytes from LS to EA putlluc - Unconditionally DMA 128 bytes from LS to EA barrier - all previous commands complete before subsiquent commands are started mfcsync - Results of all previous commands in Tag group are remotely visible mfceieio - Results of all preceding Puts commands in same group visible with respect to succeeding Get commands
- 67. 67 Roadrunner Tutorial February 7, 2008 Element Interconnect Bus
- 68. 68 Roadrunner Tutorial February 7, 2008 Element Interconnect Bus (EIB) - 96B / cycle bandwidth
- 69. 69 Roadrunner Tutorial February 7, 2008 Internal Bandwidth Capability ƒ EIB data ring for internal communication – Four 16 byte data rings, supporting multiple transfers – 96B/cycle peak bandwidth – Over 100 outstanding requests ƒ Each EIB Bus data port supports 25.6GBytes/sec* in each direction ƒ The EIB Command Bus streams commands fast enough to support 102.4 GB/sec for coherent commands, and 204.8 GB/sec for non- coherent commands. ƒ The EIB data rings can sustain 204.8GB/sec for certain workloads, with transient rates as high as 307.2GB/sec between bus units * The above numbers assume a 3.2GHz core frequency – internal bandwidth scales with core frequency
- 70. 70 Roadrunner Tutorial February 7, 2008 Element Interconnect Bus - Data Topology ƒ Four 16B data rings connecting 12 bus elements – Two clockwise / Two counter-clockwise ƒ Physically overlaps all processor elements ƒ Central arbiter supports up to three concurrent transfers per data ring – Two stage, dual round robin arbiter ƒ Each element port simultaneously supports 16B in and 16B out data path – Ring topology is transparent to element data interface 16B 16B 16B 16B Data Arb 16B 16B 16B 16B 16B 16B 16B 16B 16B 16B 16B 16B 16B 16B 16B 16B 16B 16B 16B 16B SPE0 SPE2 SPE4 SPE6 SPE7 SPE5 SPE3 SPE1 MIC PPE BIF/IOIF0 IOIF1
- 71. 71 Roadrunner Tutorial February 7, 2008 Example of eight concurrent transactions MIC SPE0 SPE2 SPE4 SPE6 BIF / IOIF1 Ramp 7 Controller Ramp 8 Controller Ramp 9 Controller Ramp 10 Controller Ramp 11 Controller Controller Ramp 0 Controller Ramp 1 Controller Ramp 2 Controller Ramp 3 Controller Ramp 4 Controller Ramp 5 Controller Ramp 6 Controller Ramp 7 Controller Ramp 8 Controller Ramp 9 Controller Ramp 10 Controller Ramp 11 Data Arbiter Ramp 7 Controller Ramp 8 Controller Ramp 9 Controller Ramp 10 Controller Ramp 11 Controller Controller Ramp 5 Controller Ramp 4 Controller Ramp 3 Controller Ramp 2 Controller Ramp 1 Controller Ramp 0 PPE SPE1 SPE3 SPE5 SPE7 IOIF1 PPE SPE1 SPE3 SPE5 SPE7 IOIF1 PPE SPE1 SPE3 SPE5 SPE7 IOIF1 MIC SPE0 SPE2 SPE4 SPE6 BIF / IOIF0 Ring1 Ring3 Ring0 Ring2 controls
- 72. 72 Roadrunner Tutorial February 7, 2008 I/O and Memory Interfaces
- 73. 73 Roadrunner Tutorial February 7, 2008 I/O Interface: - 16 B/cycle x 2
- 74. 74 Roadrunner Tutorial February 7, 2008 I/O and Memory Interfaces ƒ I/O Provides wide bandwidth – Dual XDRTM controller (25.6GB/s @ 3.2Gbps) – Two configurable interfaces (76.8GB/s @6.4Gbps) – Configurable number of Bytes – Coherent or I/O Protection – Allows for multiple system configurations
- 75. 75 Roadrunner Tutorial February 7, 2008 Cell BE Processor Can Support Many Systems ƒ Game console systems ƒ Blades ƒ HDTV ƒ Home media servers ƒ Supercomputers Cell BE Processor XDRtm XDRtm IOIF0 IOIF1 Cell BE Processor XDRtm XDRtm IOIF BIF Cell BE Processor XDRtm XDRtm IOIF Cell BE Processor XDRtm XDRtm IOIF BIF Cell BE Processor XDRtm XDRtm IOIF Cell BE Processor XDR tm XDR tm IOIF BIF Cell BE Processor XDR tm XDR tm IOIF SW
- 76. 76 Roadrunner Tutorial February 7, 2008 Cell Synergy ƒ Cell is not a collection of different processors, but a synergistic whole – Operation paradigms, data formats and semantics consistent – Share address translation and memory protection model ƒ PPE for operating systems and program control ƒ SPE optimized for efficient data processing – SPEs share Cell system functions provided by Power Architecture – MFC implements interface to memory – Copy in/copy out to local storage ƒ PowerPC provides system functions – Virtualization – Address translation and protection – External exception handling ƒ EIB integrates system as data transport hub
- 77. 77 Roadrunner Tutorial February 7, 2008 Cell Application Affinity – Target Applications
- 78. 78 Roadrunner Tutorial February 7, 2008 Contents ƒ Roadrunner Project ƒ Roadrunner Architecture ƒ Cell Processor Architecture ƒ Cell SDK ƒ DaCS and ALF ƒ Accelerating an Existing Application ƒ References
- 79. 79 Roadrunner Tutorial February 7, 2008 Programmer Experience Development Tools Stack Hardware or System Level Simulator Linux PPC64 with Cell Extensions SPE Management Lib Application Libs Samples Workloads Demos Code Dev Tools Debug Tools Performance Tools Standards: Language extensions ABI Verification Hypervisor Development Environment End-User Experience Execution Environment Miscellaneous Tools Cell Software Environment
- 80. 80 Roadrunner Tutorial February 7, 2008 Firmware e.g. Blades, Development platforms, etc Linux Operating System Features e.g. SPE exploitation, CellBE support Device Drivers Compilers C, C++, Fortran, etc Application Tooling and Environment Programming model/APIs for Cell and Hybrid, Eclipse IDE, Performance Tools Cluster and Scale out Systems Cluster Systems Management, Accelerator Management,, cluster file systems and protocols, etc Sector Specific Libraries ISVs, Universities, Labs, Open Source, etc. Applications Partners, ISVs, Universities, Labs, etc CellBE Based Hardware Core Librairies e.g. SPE intrinsic, etc Ubiquitous for all Markets Market Segment Specific Cell based systems Software Stack QS20, QS21 support, F7: Triblade prototype RHEL5.1 Distro support, Fedora7: IPMI and Power Executive Support, RAS Enhancements, MSI on QS21, Perfmon2, SPE statistics, SPE Context in Crash Files, Axon DDR2 for Swap Libspe2.0 enhancements, Newlib enhancements, tag manager and spetimers on SPEs, Infix vector operations XLC GA with additional distro hosted platform coverage/OpenMP/Fortran, gcc C++ library support and exception handling; gcc and xlC continued work on auto-vectorization/SIMDization; gcc fortran on PPE& SPE, ADA on PPE In addition SDK 3.0 has: MAMBO simulator enhancements and overall simulation speedup; GA Quality Release on RHEL5.1; More comprehensive performance and integration test suite; System test for hybrid systems RHEL5.1 Enterprise Linux Distro H.264 encoder and decoder, BLAS, ALF samples, Black Scholes sample Data communication and synchronization layer (DaCS), Accelerated Library Framework (ALF); Prorotype ALF and DaCS hybrid x86-Cell function, newlib enhancements; Performance tooling & visualization (VPA), Code Analysis Tooling (oProfile, SPU timing, PDT, FDPR-Pro); Prototype Gdbserver support for combined hybrid (Cell/x86) remote debugging; IDE ALF / DaCS Data description templates,wizards,code builders; IDE PDT integration; Prototype IDE Hybrid Performance Analysis QS20, QS21 support, F7: Triblade prototype
- 81. 81 Roadrunner Tutorial February 7, 2008 SDK v3.0 Themes & Enhancements ƒ Product Level Tested ƒ Multiple HW Platform Support – QS20 (CB1) – Fedora Only – QS21(CB+) – Production Support ƒ Linux Support – Fedora 7 (Kernel level 2.6.22) – Red Hat Enterprise Level v5.1 (Kernel Level 2.6.18) – Toolchain packages: gcc 4.1.1, binutils 2.17+, newlib 1.15+, gdb 6.6+ ƒ Programmer Productivity – Performance Tools – VPA – Visual Performance Analyzer – PDT – Performance Debugging Tool – PEP/Lock Analyzer & Trace Analysis Tools – CodeAnalyzer – Enhanced Oprofile support – FDPR-Pro for Cell – Hybrid Code Analyzer – Hybrid System Performance and Tracing Facility ƒ Programmer Productivity – Development – Eclipse IDE plug-ins – Dual source XLC , Dual Source XLF – Fortran (beta), Single Source XLC (beta) – Cell and Hybrid HPC software sample code – Enhanced GNU toolchain support – GNU Fortran for PPE & SPE – GNU ADA (GNAT) for PPE – gcc autovectorization and performance enhancements ƒ Programmer Productivity - Runtime – Product Level ALF and DaCs for Cell – Hybrid DaCS/ALF (Prototype) – Productization of combined ppe/spe gdb debugger – SPE-side Software Managed Cache (from iRT technology) ƒ Market Segment Library Enablement – Highly optimized SIMD and MASS Math Libraries – Highly Optimized BLAS – Highly optimized libFFT – Monte Carlo RNG Library – Cell Security Technology (prototype/preview)
- 82. 82 Roadrunner Tutorial February 7, 2008 IBM SDK Development Worldwide Teams AUSTIN QDC Prog models, libs, advanced apps, marquee customer engagement, SDK Integration, Integration Test ROCHESTER QDC Prog models, Test, Libs, Cluster enablement BOEBLINGEN QDC Extended Team LTC (kernel, toolchain, performance) Toronto QDC Extended Team SWG XLC Compiler Yorktown QDC Extended Team XLC Compiler Haifa, Israel QDC Extended Team STG Performance (Tools) Beijing China QDC Programming model, libs Brazil QDC Extended Team LTC (IDE) Canberra, Australia LTC (kernel & toolchain) Raleigh, NC QDC Extended Team RISCWatch (TBD) Austin QDC Extended Teams LTC (kernel, toolchain, IDE), ARL (Mambo), STG Performance (tools & Analysis) India QDC Programming model, libs
- 83. 83 Roadrunner Tutorial February 7, 2008 Supported Environments Fedora 7 QS20/QS21 Fedora 7 X86/x86_64 (F7 Cross with 3.0 compiler) Fedora 7 Power RHEL5 QS21 RHEL5 Power RHEL5 QS21 Service Offering Tested Application Build Application Execution Service Offering 3.0 compiler RHEL5 x86/x86_64 (Cross RHEL5 with 3.0 compiler) Fedora 7 QS20/QS21 Fedora 7 (Simulator with F7 sysroot) Not Required Does not Work
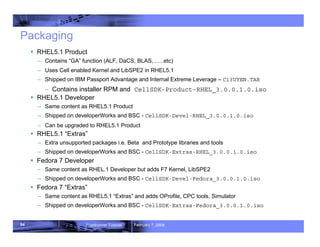
- 84. 84 Roadrunner Tutorial February 7, 2008 Packaging ƒ RHEL5.1 Product – Contains “GA” function (ALF, DaCS, BLAS, …..etc) – Uses Cell enabled Kernel and LibSPE2 in RHEL5.1 – Shipped on IBM Passport Advantage and Internal Extreme Leverage – C13UYEN.TAR – Contains installer RPM and CellSDK-Product-RHEL_3.0.0.1.0.iso ƒ RHEL5.1 Developer – Same content as RHEL5.1 Product – Shipped on developerWorks and BSC - CellSDK-Devel-RHEL_3.0.0.1.0.iso – Can be upgraded to RHEL5.1 Product ƒ RHEL5.1 “Extras” – Extra unsupported packages i.e. Beta and Prototype libraries and tools – Shipped on developerWorks and BSC - CellSDK-Extras-RHEL_3.0.0.1.0.iso ƒ Fedora 7 Developer – Same content as RHEL.1 Developer but adds F7 Kernel, LibSPE2 – Shipped on developerWorks and BSC - CellSDK-Devel-Fedora_3.0.0.1.0.iso ƒ Fedora 7 “Extras” – Same content as RHEL5.1 “Extras” and adds OProfile, CPC tools, Simulator – Shipped on developerWorks and BSC - CellSDK-Extras-Fedora_3.0.0.1.0.iso
- 85. 85 Roadrunner Tutorial February 7, 2008 SDK 3.0 Packages Yes Mambo Simulator, Isolation, and CPC Separate Product with 60 day Trial GA XL C/C++ DS compilers Not Supported Separate Product with Beta and then GM 4Q07 GA Fortran DS compiler alphaWorks Download Visual Performance Analyzer Yes Yes Yes Yes BSC Download BSC Download ILAN Fedora 7 Devel Included in RHEL Kernel, LibSPE Fedora 7 Extras RHEL5u1 Extras RHEL5u1 Devel RHEL5u1 Product Component Yes Yes Performance Tools (SPU Timing) BSC Download Performance Tools (OProfile) BSC Download BSC Download GCC Compiler Yes Yes Cell Eclipse IDE ILEAR ILAER ILAN IPLA License Yes Yes Examples, Demos Tutorial, Docs Yes Yes XL C/C++ SS compilers Yes Yes Performance Tools (FDPR-PRO, PDT, PDTR) Yes Yes Yes Development Libraries (FFT, MC, SPU Timer, ALF/DaCS for Hybrid) Yes Development Libraries (ALF, DaCS, BLAS, SIMDMath, MASS) GA SDK BETA SDK Non-SDK
- 86. 86 Roadrunner Tutorial February 7, 2008 Installation ƒ YUM-based with a wrapper script – Repositories for BSC and ISO images – YUM groups with mandatory, default and optional RPMs – Cell Runtime Environment (only installed with - -runtime flag) – Cell Development Libraries – Cell Development Tools – Cell Performance Tools – Cell Programming Examples – Cell Simulator ƒ GUI install provided by pirut (using –gui flag) ƒ Script also supports – Verify – lists what is installed – Uninstall – Update – to a service pack (RHEL5.1 only) – Backout – remove previous service pack (RHEL5.1 only)
- 87. 87 Roadrunner Tutorial February 7, 2008 Overview of Installation 1. Install Operating System on hardware (diskless QS21 requires remote boot) 2. Uninstall SDK 2.1 or SDK 3.0 early release 3. Install pre-requisites including RHEL5.1 specifics: • Install compat-libstdc++ • Install libspe2 runtimes • Create and install ppu-sysroot RPMs for cross-compilation 4. Download installer RPM and required ISO images • Physical media and product TAR file contain both and additional instructions (README.1st) 5. Install the SDK installer • rpm -ivh cell-install-3.0.0.1.0.noarch.rpm 6. Start the install • cd /opt/cell • ./cellsdk [--iso <isodir>] [--gui] install 7. Perform post-install configuration • RHEL 5.1 specifics (elfspe on QS21, libspe2 and netpbm development libraries • Complete IDE install into Eclipse and CDT • Configure DaCS daemons for DaCS for Hybrid-x86 and ALF for Hybrid-x86 • Sync up the Simulator sysroot (Fedora 7 only)
- 88. 88 Roadrunner Tutorial February 7, 2008 SDK 3.0 Documentation ƒ Supplied as: – PDFs, Man Pages, READMEs, XHTML (for accessibility) ƒ Contained in: – cell-install-3.0.0-1.0.noarch.rpm (Installation Guide in the installer RPM) – cell-documentation-3.0-5.noarch.rpm – cell-extras-documentation-3.0-5.noarch.rpm – alfman-3.0-10.noarch.rpm – dacsman-3.0-6.noarch.rpm – libspe2man-2.2.0-5.noarch.rpm – simdman-3.0-6.noarch.rpm – Individual other RPMs e.g. Tutorial, IDE ƒ Located in: – /opt/cell/sdk/docs - subdirectories used for different parts of the SDK – developerWorks - http://www-128.ibm.com/developerworks/power/cell/documents.html ƒ Other Documentation: – XL C/C++ compilers – see http://www.ibm.com/software/awdtools/xlcpp/library/ – QS20/QS21 hardware – see dW documentation site for links – CBEA Architecture docs - see dW documentation site for links
- 89. 89 Roadrunner Tutorial February 7, 2008 SDK 3.0 Documentation Mathematical Acceleration Subsystem (MASS) SPU Timer Library Cell Broadband Engine Security Software Development Kit - Installation and User's Guide Cell BE Monte Carlo Library API Reference Manual Example Library API Reference Basic Linear Algebra Subprograms Programmer's Guide and API Reference Software Development Kit 3.0 SIMD Math Library Specifications Accelerated Library Framework for Hybrid-x86 Programmer's Guide and API Reference Accelerated Library Framework Programmer's Guide and API Reference SPE Runtime Management Library Version 1.2 to 2.2 Migration Guide (revised name) SPE Runtime Management Library Data Communication and Synchronization for Hybird-x86 Programmer's Guide and API Reference Data Communication and Synchronization Programmer's Guide and API Reference Programming Library Documentation SPU Assembly Language Specification Cell Broadband Engine Linux Reference Implementation Application Binary Interface Specification SIMD Math Library Specification for Cell Broadband Engine Architecture SPU Application Binary Interface Specification C/C++ Language Extensions for Cell Broadband Engine Architecture Programming Standards IBM Visual Performance Analyzer User's Guide Using the single-source compiler XL Fortran Compiler Information Installation Guide, Getting Started, Compiler Reference Language Reference, Programming Guide XL C/C++ Compiler Information Installation Guide, Getting Started, Compiler Reference Language Reference, Programming Guide IBM Full-System Simulator User's Guide Performance Analysis with the IBM Full-System Simulator Programming Tools Documentation Security SDK V3.0 Installation and User’s Guide PDT (SDK Programmer's Guide) Oprofile (SDK Programmer's Guide) Cell Broadband Engine Programmer's Guide Cell Broadband Engine Programming Tutorial Cell Broadband Engine Programming Handbook IBM SDK for Multicore Acceleration Installation Guide Software Development Kit Updated, New
- 90. 90 Roadrunner Tutorial February 7, 2008 Related Products ƒ IBM XL C/C++ for Multicore Acceleration for Linux – http://www-306.ibm.com/software/awdtools/ccompilers/ – http://www-306.ibm.com/software/awdtools/xlcpp/features/multicore/ ƒ IBM XL Fortran for Multicore Acceleration for Linux on System p – http://www.alphaworks.ibm.com/tech/cellfortran (GA planned for 11/30) ƒ Visual Performance Analyzer (VPA) on alphaWorks – http://www.alphaworks.ibm.com/tech/vpa ƒ IBM Assembly Visualizer for Cell Broadband Engine on alphaWorks – http://www.alphaworks.ibm.com/tech/asmvis ƒ IBM Interactive Ray Trace Demo on alphaWorks – http://www.alphaworks.ibm.com/tech/irt
- 91. 91 Roadrunner Tutorial February 7, 2008 Linux Kernel ƒ Patches made to Linux 2.6.22 kernel to provide services required to support the Cell BE hardware facilities ƒ Patches distributed by Barcelona Supercomputer Center – http://www.bsc.es/projects/deepcomputing/linuxoncell ƒ For the QS20/QS21, – the kernel is installed into the /boot directory – yaboot.conf is modified – needs reboot to activate this kernel
- 92. 92 Roadrunner Tutorial February 7, 2008 Kernel and LibSPE2 ƒ Distro Support – RHEL5.1 – Fedora7 ƒ QS21 Support – IPMI and Power Executive Support – RAS Enhancements – Perfmon2 – MSI support for QS21 (PCIe interrupt signaling) – Axon DDR2 for Swap ƒ SPE utilization statistics ƒ SPE preemptive scheduling ƒ SPE Context in Crash Files ƒ Enabling for Secure SDK (under CDA only)
- 93. 93 Roadrunner Tutorial February 7, 2008 IBM Full-System Simulator ƒ Emulates the behavior of a full system that contains a Cell BE processor. ƒ Can start Linux on the simulator and run applications on the simulated operating system. ƒ Supports the loading and running of statically-linked executable programs and standalone tests without an underlying operating system. ƒ Simulation models – Functional-only simulation: Models the program-visible effects of instructions without modeling the time it takes to run these instructions. – ÎFor code development and debugging. – Performance simulation: Models internal policies and mechanisms for system components, such as arbiters, queues, and pipelines. Operation latencies are modeled dynamically to account for both processing time and resource constraints. – ÎFor system and application performance analysis. ƒ Improvements in SDK 3.0: – New Fast execution mode on 64-bit platforms – Improved performance models – New Graphical User Interface features – Improved diagnostic and statistics reporting – New device emulation support to allow booting of unmodified Linux kernels – Supplied with Fedora 7 Sysroot Image
- 94. 94 Roadrunner Tutorial February 7, 2008 GCC and GNU Toolchain ƒ Base toolchain – Based on GCC 4.1.1 extended by PPE and SPE support – binutils 2.18, SPE newlib 1.15.0+, GDB 6.6+ ƒ Support additional languages – GNU Fortran for PPE and SPE – No SPE-specific extensions (e.g. intrinsics) – GNU Ada for PPE only – Will provide Ada bindings for libspe2 ƒ Compiler performance enhancements – Improved auto-vectorization capabilities – Extract parallelism from straight-line code, outer loops – Other SPE code generation improvements – If-conversion, modulo-scheduling enhancements ƒ New hardware support – Code generation for SPE with enhanced double precision FP
- 95. 95 Roadrunner Tutorial February 7, 2008 GCC and GNU Toolchain ƒHelp simplify Cell/B.E. application development – Syntax extension to allow use of operators (+, -, …) on vectors – Additional PPU VMX intrinsics – Simplify embedding of SPE binaries into PPE objects – SPE static stack-space requirement estimation – Extended C99/POSIX run-time library support on SPE ƒIntegrated PPE address-space access on SPE – Syntax extension to provide address-space qualified types – Access PPE-side symbols in SPE code – Integrated software-managed cache for data access ƒCombined PPE/SPE debugger enhancements – Extended support for debugging libspe2 code – Improved resolution of multiply-defined symbols
- 96. 96 Roadrunner Tutorial February 7, 2008 GNU tool chain ƒ Contains the GCC compiler for the PPU and the SPU. – ppu-gcc, ppu-g++, ppu32-gcc, ppu32-g++, spu-gcc, spu-g++ – For the PPU, GCC replaces the native GCC on PPC platforms and it is a cross-compiler on x86. The GCC for the PPU is preferred and the makefiles are configured to use it when building the libraries and samples. – For the SPU, GCC contains a separate SPE cross-compiler that supports the standards defined in the following documents: – C/C++ Language Extensions for Cell BE Architecture V2.4 – SPU Application Binary Interface (ABI) Specification V1.7 – SPU Instruction Set Architecture V1.2 ƒ The assembler and linker are common to both the GCC and XL C/C++ compilers. – ppu-ld, ppu-as, spu-ld, spu-as – The GCC associated assembler and linker additionally support the SPU Assembly Language Specification V1.5. ƒ GDB support is provided for both PPU and SPU debugging – The debugger client can be in the same process or a remote process. ƒ GDB also supports combined (PPU and SPU) debugging. – ppu-gdb, ppu-gdbserver, ppu32-gdbserver
- 97. 97 Roadrunner Tutorial February 7, 2008 XL C/C++/Fortran Compilers ƒ IBM XL C/C++ for Multicore Acceleration for Linux, V9.0 (dual source compiler) – Product quality and support – Performance improvements in auto-SIMD – Improved diagnostic capabilities for detecting SIMD opportunities (-qreport) – Enablement of high optimization levels (O4, O5) on the SPE – Automatic generation of code overlays ƒ IBM XL Fortran for Multicore Acceleration for Linux, V11.1 (dual source compiler) – Beta level (with GA targeted for 11/30/07) – Optimized Fortran code generation for PPE and SPE – Support for Fortran 77, 90 and 95 standards as well as many features from the Fortran 2003 standard – Auto-SIMD optimizations – Automatic generation of code overlays ƒ IBM XL C/C++ Alpha Edition for Multicore Acceleration, V0.9 (single source compiler) – Beta level – Allows programmer to use OpenMP directives to specify parallelism on PPE and SPE – Compiler hides complexity of DMA transfers, code partitioning, overlays, etc.. from the programmer – See http://www.research.ibm.com/journal/sj/451/eichenberger.html
- 98. 98 Roadrunner Tutorial February 7, 2008 IBM XL C/C++ compiler ƒ A cross-compiler hosted on a x86 and PPC platform. ƒ Requires the GCC Tool chain for cross-assembling and cross-linking applications for both the PPE and SPE. ƒ Supports the revised 2003 International C++ Standard ISO/IEC 14882:2003(E), Programming Languages -- C++ and the ISO/IEC 9899:1999, Programming Languages -- C standard, also known as C99, and the C89 Standard and K&R style, and language extensions for vector programming ƒ The XL C/C++ compiler provides the following invocation commands: – ppuxlc, ppuxlc++ – spuxlc, spuxlc++ ƒ The XL C/C++ compiler includes the following base optimization levels: – -O0: almost no optimization – -O2: strong, low-level optimization that benefits most programs – -O3: intense, low-level optimization analysis with basic loop optimization – -O4: all of -O3 and detailed loop analysis and good whole-program analysis at link time – -O5: all of -O4 and detailed whole-program analysis at link time. ƒ Auto-SIMDization is enabled at O3 -qhot or O4 and O5 by default.
- 99. 99 Roadrunner Tutorial February 7, 2008 Eclipse IDE ƒ IBM IDE, which is built upon the Eclipse and C/C++ Development Tools (CDT) platform, integrates Cell GNU tool chain, XLC/GCC compilers, IBM Full-System Simulator for the Cell BE, and other development components in order to provide a comprehensive, user-friendly development platform that simplifies Cell BE development. Eclipse CDT Cell IDE Cell Tool Chain Sim perf
- 100. 100 Roadrunner Tutorial February 7, 2008 Cell IDE Key Features ƒ Cell C/C++ PPE/SPE managed make project support ƒ A C/C++ editor that supports syntax highlighting; a customizable template; and an outline window view for procedures, variables, declarations, and functions that appear in source code. ƒ Full configurable build properties. ƒ A rich C/C++ source level PPE and/or SPE cell GDB debugger integrated into eclipse. ƒ Seamless integration of Cell BE Simulator into Eclipse ƒ Automatic makefile generator, builder, performance tools, and several other enhancements. ƒ Support development platforms (x86, x86_64, Power PC, Cell) ƒ Support target platforms – Local Cell Simulator – Remote Cell Simulator – Remote Native Cell Blade ƒ Performance tools Support . ƒ Automatic embedSPU integration ƒ ALF programming model support ƒ SOMA support
- 101. 101 Roadrunner Tutorial February 7, 2008 ALF and DaCS: IBM’s Software Enablement Strategy for Multi- core Memory-Hierarchy Systems Application Library ALF DaCS Remote DMA Error Handling Others Send / Receive Synchronization Process Management Topology Mailbox Tooling IDE Compilers gdb Trace Analysis Platform Process Management Data Partitioning Workload Distribution Error Handling MFC PCIe 10GigE libSPE
- 102. 102 Roadrunner Tutorial February 7, 2008 DaCS – Data Communications and Synchronization ƒ Focused on data movement primitives – DMA like interfaces (put, get) – Message interfaces (send/recv) – Mailbox – Endian Conversion ƒ Provides Process Management, Accelerator Topology Services ƒ Based on Remote Memory windows and Data channels architecture ƒ Common API – Intra-Accelerator (CellBE), Host - Accelerator ƒ Double and multi-buffering – Efficient data transfer to maximize available bandwidth and minimize inherent latency – Hide complexity of asynchronous compute/communicate from developer ƒ Supports ALF, directly used by US National Lab for Host-Accelerator HPC environment ƒ Thin layer of API support on CELLBE native hardware ƒ Hybrid DaCS – Prototyped on IB Verbs (incomplete) – Developed on Sockets (prototype in SDK3) – Developed on PCI-e (Tri-blade) SDK3.0 – internal, SDK4.0 GA
- 103. 103 Roadrunner Tutorial February 7, 2008 DaCS Components Overview ƒ Process Management – Supports remote launching of an accelerator’s process from a host process ƒ Topology Management – Identify the number of Accelerators of a certain type – Reserve a number of Accelerators of a certain type ƒ Data Movement Primitives – Remote Direct Memory Access (rDMA) – put/get – put_list/get_list – Message Passing – send/receive – Mailbox – write to mailbox/read from mailbox ƒ Synchronization – Mutex / Barrier ƒ Error Handling HE (x86_64) AE (CBE) AE (CBE) AE (SPE) AE (SPE)
- 104. 104 Roadrunner Tutorial February 7, 2008 Accelerator Library Framework (ALF) Overview ƒ Aims at workloads that are highly parallelizable – e.g. Raycasting, FFT, Monte Carlo, Video Codecs ƒ Provides a simple user-level programming framework for Cell library developers that can be extended to other hybrid systems. ƒ Division of Labor approach – ALF provides wrappers for computational kernels – Frees programmers from writing their own architectural-dependent code including: data transfer, task management, double buffering, data communication ƒ Manages data partitioning – Provides efficient scatter/gather implementations via CBE DMA – Extensible to variety of data partitioning patterns – Host and accelerator describe the scatter/gather operations – Accelerators gather the input data and scatter output data from host’s memory – Manages input/output buffers to/from SPEs ƒ Remote error handling ƒ Utilizes DaCS library for some low-level operations (on Hybrid)
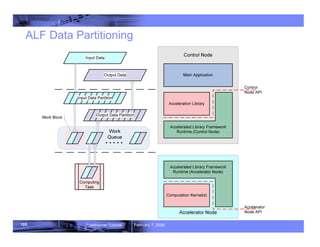
- 105. 105 Roadrunner Tutorial February 7, 2008 ALF Data Partitioning
- 106. 106 Roadrunner Tutorial February 7, 2008 SPU Overlays ƒ Overlays must be used if the sum of the lengths of all the code segments of a program, plus the lengths of the data areas required by the program, exceeds the SPU local storage size ƒ They may be used in other circumstances; for example performance might be improved if the size of a data area can be increased by moving rarely used functions (such as error or exception handlers) to overlays Local Storage Code segment Code segment Data segment Code segment Code segment Data segment Data segment Code segment
- 107. 107 Roadrunner Tutorial February 7, 2008 SPE Software Managed Cache ƒ SPE memory accesses are to Local Store Addresses only. Access to main memory requires explicit DMA calls. – This represents a new programming model ƒ Software cache has many benefits in SPE environment – Simplifies programming model – familiar load/store effective address model can be used – Decreases time to port to SPE – Take advantage of locality of reference – Can be easily optimized to match data access patterns
- 108. 108 Roadrunner Tutorial February 7, 2008 SIMD Math Library – tgammaf4 (PPU/SPU) – tgammad2 (SPU) – lgammaf4 (PPU/SPU) – erff4 (PPU/SPU) – erfcf4 (PPU/SPU) – fpclassifyd2 (SPU) – fpclassifyf4 (PPU/SPU) – nextafterd2 (SPU) – nextafterf4 (PPU/SPU) – modff4 (PPU/SPU) – lldivi2 (SPU) – lldivu2 (SPU) – iroundf4 (PPU/SPU) – irintfr (PPU/SPU) – log1pd2 (SPU) – log1pf4 (PPU/SPU) – expm1d2 (SPU) – expm1f4 (PPU/SPU) – hypotf4 (PPU/SPU) – sincosd2 (SPU) – sincosf4 (PPU/SPU) – tanhd2 (SPU) – tanhf4 (PPU/SPU) – atand2dp – acoshd2 (SPU) – acoshf4 (PPU/SPU) – asinhd2 (SPU) – asinhf4 (PPU/SPU) – atanhd2 (SPU) – atanhf4 (PPU/SPU) – atan2d2 (SPU) – atan2f4 (PPU/SPU) ƒ Completed Implementation of JSRE SIMD Math Library by adding:
- 109. 109 Roadrunner Tutorial February 7, 2008 MASS and MASS/V Library ƒ Mathematical Acceleration SubSystem – High-performance alternative to standard system math libraries – i.e. libm, SIMDmath – Versions exist for PowerPCs, PPU, SPU – Up to 23x faster than libm functions ƒ PPU MASS – 57 scalar functions, 60 vector functions – both single and double precision ƒ SPU MASS – SDK 2.1 contains 28 SIMD functions and 28 vector functions (SP only) – Expanded SPU MASS to include all single-precision functions in PPU MASS – Added 8 new SP functions – erf, erfc, expm1, hypot, lgamma, log1p, vpopcnt4, vpopcnt8 – Improved tuning of existing functions
- 110. 110 Roadrunner Tutorial February 7, 2008 BLAS Library ƒ BLAS on PPU – Conforming to standard BLAS interface – Easy port of existing applications – Selected routines optimized utilizing SPUs – Only real single precision and real double precision versions supported. Complex version is not supported. ƒ Selected Routines (Based on use in Cholesky factorization/LU) – BLAS I (scal, copy, axpy, dot, i_amax) – BLAS II (gemv) – BLAS III (gemm, syrk, trsm) – Focus on single precision optimization ƒ BLAS on SPU – Offer SPU Kernel routines to SPU applications – Underlying functionality implemented on the SPE – Operate on data (input/output) residing in local store – Similar to the corresponding PPU routine but not conforming to APIs
- 111. 111 Roadrunner Tutorial February 7, 2008 FFT Library (Prototype) 2 to 2048 (BE) out of place forward 2D Rectangular Single C2C low primes R2C low primes C2R low primes C2C power of 2 R2C power of 2 C2R power of 2 32 to 2048 (BE) In/out of place forward/inverse 2D Rectangular Double 2 to 2048 (BE) out of place forward 32 to 2048 (BE) In/out of place forward/inverse 2D Square Single 2 to 8192 SPU) 2 to 8192 (BE) out of place forward/inverse 2 to 8192(SPU) 2 to 8192 (BE) out of place forward 2 to 8192(SPU) 2 to 8192 (BE) out of place forward 2 to 8192 SPU) 2 to 8192 (BE) out of place forward/inverse 2 to 8192(SPU) 2 to 8192 (BE) out of place forward 2 to 8192(SPU) 2 to 8192 (BE) out of place forward 1D Single •1D, 2D Square, 2D rectangular, 3D cube, 3D rectangular •Integer, Single Precision, Double Precision •Complex to Real, Real to Complex, Complex to Complex •Row size is Power-of-2, Power-of-Low-Primes, factorization of row size includes large primes •SPU, BE, ppu •In place, out of place •Forward, Inverse
- 112. 112 Roadrunner Tutorial February 7, 2008 Monte Carlo Random Number Generator Library (Prototype) Types of Random Number Generators ƒ True - – not repeatable – hardware support on IBM blades (not Simulator) ƒ Quasi – repeatable with same seed – attempts to uniformly fill n-dimension space – Sobol ƒ Pseudo – repeatable with same seed – Mersenne Twister – Kirkpatrick-Stoll
- 113. 113 Roadrunner Tutorial February 7, 2008 Choosing a Random Number Generator Quasi Fastest Large Sobol Pseudo Moderate Moderate Mersenne Twister Pseudo Fast Moderate Kirkpatrick-Stoll Random Slowest Small Hardware Randomess Speed Size Algorithm
- 114. 114 Roadrunner Tutorial February 7, 2008 SPU Timer Library (Prototype) ƒ Provides virtual clock and timer services for SPU programs ƒ Virtual Clock – Software managed 64-bit timebase counter – Built on top of 32-bit decrementer register – Can be used for high resolution time measurements ƒ Virtual Timers – Interval timers built on virtual clock – User registered handler is called on requested interval – Can be used for statistical profiling – Up to 4 timers can be active simultaneously, with different intervals
- 115. 115 Roadrunner Tutorial February 7, 2008 Performance Tools – Static Analysis ƒ FDPR-Pro – Perform global optimization at the entire executable ƒ SPU Timing – Analysis of SPE instruction scheduling
- 116. 116 Roadrunner Tutorial February 7, 2008 Performance Tools – Dynamic Analysis ƒ Performance Debugging and Tool (PDT) – Generalized tracing facility; instrumentation of DaCS and ALF – Hybrid system support, e.g. PDT on Opteron, etc. ƒ PDTR: PDT post-processor – Post processes PDT traces – Provide analysis and summary reports (Lock analysis, DMA analysis, etc.) ƒ OProfile (Fedora 7 only) – PPU Time and event profiling – SPU time profiling ƒ Hardware Performance Monitoring (Fedora 7 only) – Collect performance monitoring events – Perfmon2 support and enablement for PAPI, etc. ƒ Hybrid System Performance Monitoring and Tracing facility – Launch, activate and dynamically configure tools on CellBlades and Opteron host blade – Synchronize, merge and aggregate traces ƒ Visual Performance Analyzer (from alphaWorks)
- 117. 117 Roadrunner Tutorial February 7, 2008 Cell/B.E. Security Technology & Security SDK Application (Guest) Isolated SPE Application (Other Guests) Operating System (Hotel Manager) Bus PPE SPE ƒ Cell/B.E. has a security architecture which ƒ “vaults” and protects SPE applications. ƒ a hardware key is used to check/decrypt applications. ƒ Secure boot ƒ Hardware anti-tampering ƒ Because of these robust security features, Cell/B.E. makes an ideal platform for A&D applications ƒ Fulfill MILS requirements ƒ The Security SDK provides tools for encrypting/singing applications and for managing keys. ƒ Using industry standard (X.509)
- 118. 118 Roadrunner Tutorial February 7, 2008 Contents ƒ Roadrunner Project ƒ Roadrunner Architecture ƒ Cell Processor Architecture ƒ Cell SDK ƒ DaCS and ALF ƒ Accelerating an Existing Application ƒ References
- 119. 119 Roadrunner Tutorial February 7, 2008 Tooling Tooling DaCSd To other cluster nodes Opteron Blade Application MPI Accelerated Lib ALF/DaCS Host O/S DD IDE gdb Trace Analysis Cell Blade Tooling IDE Analysis DaCSd Accelerated Lib ALF/DaCS Compilers/Profiling/etc. CellBE Linux Hybrid Node System Software Stack Cell Blade Tooling IDE Analysis DaCSd Accelerated Lib ALF/DaCS Compilers/Profiling/etc. CellBE Linux
- 120. 120 Roadrunner Tutorial February 7, 2008 ALF and DaCS: IBM’s Software Enablement Strategy for Multi- core Memory-Hierarchy Systems Application Library ALF DaCS Remote DMA Error Handling Others Send / Receive Synchronization Process Management Topology Mailbox Tooling IDE Compilers gdb Trace Analysis Platform Process Management Data Partitioning Workload Distribution Error Handling MFC PCIe 10GigE libSPE
- 121. 121 Roadrunner Tutorial February 7, 2008 DaCS – Data Communications and Synchronization ƒ Focused on data movement primitives – DMA like interfaces (put, get) – Message interfaces (send/recv) – Mailbox – Endian Conversion ƒ Provides Process Management, Accelerator Topology Services ƒ Based on Remote Memory windows and Data channels architecture ƒ Common API – Intra-Accelerator (CellBE), Host - Accelerator ƒ Double and multi-buffering – Efficient data transfer to maximize available bandwidth and minimize inherent latency – Hide complexity of asynchronous compute/communicate from developer ƒ Supports ALF, directly used by US National Lab for Host-Accelerator HPC environment ƒ Thin layer of API support on CELLBE native hardware ƒ Hybrid DaCS – Prototyped on IB Verbs (incomplete) – Developed on Sockets (prototype in SDK3) – Developed on PCI-e (Tri-blade) SDK3.0 – internal, SDK4.0 GA
- 122. 122 Roadrunner Tutorial February 7, 2008 DaCS Components Overview ƒ Process Management – Supports remote launching of an accelerator’s process from a host process ƒ Topology Management – Identify the number of Accelerators of a certain type – Reserve a number of Accelerators of a certain type ƒ Data Movement Primitives – Remote Direct Memory Access (rDMA) – put/get – put_list/get_list – Message Passing – send/receive – Mailbox – write to mailbox/read from mailbox ƒ Synchronization – Mutex / Barrier ƒ Error Handling HE (x86_64) AE (CBE) AE (CBE) AE (SPE) AE (SPE)
- 123. 123 Roadrunner Tutorial February 7, 2008 DaCS Component – Topology Management ƒ Identify the topology of Accelerator Elements for a specified Host Element ƒ Reserve a specific Accelerator Element ƒ Reserve a number of Accelerators of a certain type ƒ Release Accelerator Elements ƒ Heartbeat Accelerators for Availability HE (Opteron) AE (CBE) AE (CBE) AE (CBE) AE (CBE) AE (SPE) AE (SPE)
- 124. 124 Roadrunner Tutorial February 7, 2008 DaCS Components – Process Management ƒ Remote launching and termination of an accelerator’s process from a host process ƒ DaCS provides a method to start accelerator by sending executables and associated libraries ƒ DaCS utilizes a DaCS Daemon to facilitate process launching, error detection, and orphan process cleanup ƒ One DaCS Daemon (dacsd) per reserved accelerator
- 125. 125 Roadrunner Tutorial February 7, 2008 DaCS APIs ƒ Init / Term – dacs_runtime_init – dacs_runtime_exit ƒ Reservation Service – dacs_get_num_ avail_children – dacs_reserve_children – dacs_release_de_list ƒ Process Management – dacs_de_start – dacs_num_processes_supported – dacs_num_processes_running – dacs_de_wait – dacs_de_test ƒ Group Functions – dacs_group_init – dacs_group_add_member – dacs_group_close – dacs_group_destroy – dacs_group_accept – dacs_group_leave – dacs_barrier_wait ƒ Locking Primitives – dacs_mutex_init – dacs_mutex_share – dacs_mutex_accept – dacs_mutex_lock – dacs_mutex_try_lock – dacs_mutex_unlock – dacs_mutex_release – dacs_mutex_destroy ƒ Error Handling – dacs_errhandler_reg – dacs_strerror – dacs_error_num – dacs_error_code – dacs_error_str – dacs_error_de – dacs_error_pid ƒ Data Communication – dacs_remote_mem_create – dacs_remote_mem_share – dacs_remote_mem_accept – dacs_remote_mem_release – dacs_remote_mem_destroy – dacs_remote_mem_query – dacs_put – dacs_get – dacs_put_list – dacs_get_list – dacs_send – dacs_recv – dacs_mailbox_write – dacs_mailbox_read – dacs_mailbox_test – dacs_wid_reserve – dacs_wid_release – dacs_test – dacs_wait
- 126. 126 Roadrunner Tutorial February 7, 2008 ALF ƒ Division of labor approach – ALF provides wrappers for computational kernels; synthesize kernels with data partitioning ƒ Initialization and cleanup of a group of accelerators – Groups are dynamic – Mutex locks provide synchronization mechanism for data and processing ƒ Remote error handling ƒ Data partitioning and list creation – Efficient scatter/gather implementations – Stateless embarrassingly parallel processing, strided partitioning, butterfly communications, etc. – Extensible to variety of data partitioning patterns ƒ SPMD – SDK2.1 , MPMD – SDK3.0 ƒ Target prototypes: FFT, TRE, Sweep3D, Black Scholes, Linear Algebra
- 127. 127 Roadrunner Tutorial February 7, 2008 ALF – Core Concepts ƒ Accelerator Host - PPE Compute Task Work Queue Main Application Acceleration Library Accelerated Library Framework Runtimeƒ ( Host) Computation Kernel ƒ ( ƒ s Accelerated Library Framework Runtimeƒ ( Accelerator) Accelerator API Host API Input Data Output Data Input Data Partition Output Data Partition Work Block Broadband Engine Bus Accelerators - SPEs
- 128. 128 Roadrunner Tutorial February 7, 2008 ƒ Model 1: At an API level, the Opteron is acting as host and SPEs are accelerators. The PPE is a facilitator only. Programmers do not interact with the PPEs directly. ƒ Model 2: At an API level, the Opteron is acting as hosts and CellBE processors are accelerators. The PPE runs as ALF Accelerator and ALF host to the SPE accelerators. Opteron programmers do not interact with the SPEs directly. ƒ ALF is being implemented using DaCS as the basic data mover and process management layer. ALF / DaCS Hybrid Implementation
- 129. 129 Roadrunner Tutorial February 7, 2008 Overview - ALF on Data Parallel Problem Input Output
- 130. 130 Roadrunner Tutorial February 7, 2008 Output Input ALF on Data Parallel Problem
- 131. 131 Roadrunner Tutorial February 7, 2008 Work Block ƒ Workblock is the basic data unit of ALF ƒ Workblock = Partition Information ( Input Data, Output Data ) + Parameters Parameters Input Desc Output Desc Output Input ƒ Input Data and Output Data for a work load can be divided into many work blocks ALF - Workblock
- 132. 132 Roadrunner Tutorial February 7, 2008 Work Block ƒ Compute Task processes a Work Block ƒ A task takes in the input data, context. parameters and produces the output data Context Input Description Output Description Output Input Task ALF – Compute Task
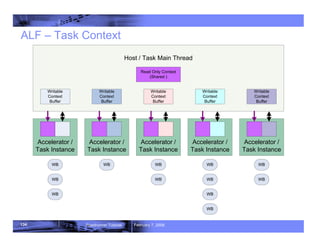
- 133. 133 Roadrunner Tutorial February 7, 2008 ALF - Task Context ƒ Provides persistent data buffer across work blocks ƒ Can be used for all-reduce operations such as min, max, sum, average, etc. ƒ Can have both read-only section and writable section – Writable section can be returned to host memory once the task is finished – ALF runtime does not provide data coherency support if there is conflict in writing the section back to host memory – Programmers should create unique task context for each instance of a compute kernel on an accelerator
- 134. 134 Roadrunner Tutorial February 7, 2008 Accelerator / Task Instance Accelerator / Task Instance Accelerator / Task Instance Accelerator / Task Instance Host / Task Main Thread Writable Context Buffer Writable Context Buffer Writable Context Buffer Writable Context Buffer Writable Context Buffer Accelerator / Task Instance WB WB WB WB WB WB WB WB WB WB WB WB Read Only Context (Shared ) ALF – Task Context
- 135. 135 Roadrunner Tutorial February 7, 2008 ƒ Work Block input and output data descriptions are stored as Data Transfer List ƒ Input data transfer list is used to gather data from host memory ƒ Output data transfer list is used to scatter data to host memory Work Block Parameters Input Description Output Description Host Memory C A E D B B A C D E G F H I J A B C D E H I J F G F G I H J Accelerator Memory Data Transfer List ALF – Data Transfer List
- 136. 136 Roadrunner Tutorial February 7, 2008 ALF – Accelerator side data partitioning ƒ Two approaches to generate data transfer list – Generate on the host side 9 Straight forward and easier to program 8 Host might not be able to support all accelerators – Generate on the accelerator side 8 Indirect and harder to program (parameters will be passed in) 9 Many accelerators are stronger than a single control node Work Block Parameters Host Memory C A E D B B A C D E G F H I J A B C D E H I J F G F G I H J Accelerator Memory Data Transfer List
- 137. 137 Roadrunner Tutorial February 7, 2008 ALF - Queues ƒ Two different queues are important to programmers – Work block queue for each task – Pending work blocks will be issued to the work queue – Task instance on each accelerator node will fetch from this queue – Task queue for each ALF runtime – Multiple Tasks executed at one time – except where programmer specifies dependencies – Future tasks can be issued. They will be placed on the task queue awaiting execution. ƒ ALF runtime manages both queues
- 138. 138 Roadrunner Tutorial February 7, 2008 ALF - Buffer management on accelerators ƒ ALF manages buffer allocation on accelerators’ local memory ƒ ALF runtime provides pointers to 5 different buffers to a computational kernel – Task context buffer (RO and RW sections) – Work block parameters – Input Buffer – Input/Output Buffer – Output Buffer ƒ ALF implements a best effort double buffering scheme – ALF determines if there is enough local memory for double buffering ƒ Double buffer scenarios supported by ALF – 4 buffers: [In0, Out0; In1, Out1] – 3 buffers: [In0, Out0; In1] : [Out1; In2, Out2]
- 139. 139 Roadrunner Tutorial February 7, 2008 ALF - Double buffering schemes O0 1 2 3 4 5 6 7 8 9 0 I0 C0 O1 I1 C1 O2 C2 I2 O3 C3 I3 I0 WB0 WB0 O0 I2 WB2 I1 WB1 WB1 O1 WB2 O2 I3 WB3 WB3 O3 I0 WB0 WB0 O0 WB2 I1 WB1 O2 I3 WB3 WB1 I2 O1 WB2 WB3 O3 Buf0 Buf1 Buf2 Buf3 Buf0 Buf1 Buf2 WB0 WB1 WB2 WB3 Buffer Usage of 4 Buffers Buffer Usage of 3 Buffers I/O and Computation Operations Timeline I0 WB0 O0 Buf0 I1 WB1 O1 Buf1 I2 WB2 O2 I3 WB3 O3 Buffer Usage of Overlapped I/O Buffers (a) (b) (c) (d)
- 140. 140 Roadrunner Tutorial February 7, 2008 Synchronization Support ƒ Barrier – All work blocks enqueued before the barrier are guaranteed to be finished before any additional work block added after the barrier can be processed on any of the accelerators – Programmers can register a callback function once the barrier is encountered. The main PPE application thread cannot proceed until the callback function returns. ƒ Notification – Allows programmers query for a specific work block completion – Allows programmers to register a callback function once this particular work block has been finished – Does not provide any ordering
- 141. 141 Roadrunner Tutorial February 7, 2008 ALF - Synchronization constructs 1 1 1 1 3 1 1 1 1 2 2 2 2 Barrier 1 3 3 3 3 Barrier 3 Barrier 5 4 4 4 4 4 4 4 Task Create Notify 4 Callback Callback Task Queue Insert Order Parallel Task Execution Thread Message Invoking Thread Task Wait Notify 2 2 Main Thread Synchronization Point Queries
- 142. 142 Roadrunner Tutorial February 7, 2008 Initialization Create Task ALF Runtime Wait Task Termination Computing Kernel Prepare Input DTL Prepare Output DTL Create Workblock Control Node Control Node Accelerator Accelerator Node Node Basic Structure of an ALF Application
- 143. 143 Roadrunner Tutorial February 7, 2008 Comp. Core Data Mv. Mem. Mg. SPU Comp. Core Data Mv. Mem. Mg. SPU … … Acceleration Library Sched. Tsk. Mg. Msg. Interface Main Application Computing Core: Highly optimized for specific library Acceleration Library: specifies methods for cooperating with computing kernels on SPUs Task Queue Load Balancer Local Memory Manage: Single or Double Buffering Task Management: Tasks generate, management Msg. interface: Message, Synchronization Scheduling: Task dispatch and load balance Data Dispatcher Data Movement: DMA, Scattering / Gathering Comp. Core Data Mv. Mem. Mg. SPU Comp. Core Data Mv. Mem. Mg. SPU Comp. Core Data Mv. Mem. Mg. SPU Comp. Core Data Mv. Mem. Mg. SPU PPU PPU OS Previous Development Environment
- 144. 144 Roadrunner Tutorial February 7, 2008 Comp. Core ALF (SPU) SPU Comp. Core ALF (SPU) SPU … … Main Application Task Queue Load Balancer Local Memory Manage: Single or Double Buffering Task Management: Tasks generate, management Msg. interface: Message, Synchronization Scheduling: Task dispatch and load balance Data Dispatcher Data Movement: DMA, Scattering / Gathering PPU PPU OS Accelerated Library Framework Accelerated Library Framework Acceleration Library: specifies methods for cooperating with computing kernels on SPEs Computational kernel: Highly optimized for specific library Comp. Core ALF (SPU) SPU Comp. Core ALF (SPU) SPU Comp. Core ALF (SPU) SPU Comp. Core ALF (SPU) SPU Acceleration Library ALF (PPU) Development Environment with ALF
- 145. 145 Roadrunner Tutorial February 7, 2008 Contents ƒ Roadrunner Project ƒ Roadrunner Architecture ƒ Cell Processor Architecture ƒ Cell SDK ƒ DaCS and ALF ƒ Accelerating an Existing Application ƒ References
- 146. 146 Roadrunner Tutorial February 7, 2008 Preliminaries ƒ Assumption: you have a working MPI code in some language. ƒ Strategy: acceleration takes place within an MPI rank. ƒ Under these conditions, acceleration can happen incrementally…
- 147. 147 Roadrunner Tutorial February 7, 2008 Incremental Acceleration 1. Identify portions of code to accelerate. 2. Move them to another MPI rank. 3. Move them to Cell PPE. 4. Move them to Cell SPEs. 5. Vectorize.
- 148. 148 Roadrunner Tutorial February 7, 2008 Acceleration Opportunities ƒ Large portions of code… not necessarily “hot” loops. ƒ Ideals: – Compact data – Embarrassingly parallel – Single-precision always runs faster
- 149. 149 Roadrunner Tutorial February 7, 2008 Move to another MPI rank. ƒ Send your data to another MPI rank for remote processing. ƒ Ensures you know your data requirements. – Beware COMMON or member data ƒ Allows you to debug using familiar tools.
- 150. 150 Roadrunner Tutorial February 7, 2008 Move to Cell PPE ƒ Replace your MPI communications with DaCS, execute routines on PPE. ƒ Need to address byte-swapping. ƒ This is just a PowerPC, no “fancy” programming required.
- 151. 151 Roadrunner Tutorial February 7, 2008 Move to Cell SPE ƒ Compile same code on SPEs. ƒ Requires starting and managing N asynchronous SPE threads. ƒ Requires DMAs between Cell main memory and SPE local stores.
- 152. 152 Roadrunner Tutorial February 7, 2008 “Vectorize” SPE code ƒ Take advantage of the SPE SIMD operations and data structures. – Every SPE instruction operates on 128-bit values (including load/store!). – Scalar code is converted into vectors and back: lots of extra instructions. – Like SSE or AltiVec: back-port what you did!
- 153. 153 Roadrunner Tutorial February 7, 2008 Hints ƒ Abstract your communication mechanisms. ƒ Be more concerned with minimizing data motion than instructions. ƒ Let the Opterons do some of the work in cooperation with the accelerators. ƒ Switch to C/C++ for your Cell implementation. ƒ Allow the accelerator to rotate through different algorithms.
- 154. 154 Roadrunner Tutorial February 7, 2008 Plan! ƒ Think all the way through the process before starting to implement. ƒ The ability to achieve acceptable levels of acceleration may depend on decisions made early in the process. – Especially data structures and communication costs!
- 155. 155 Roadrunner Tutorial February 7, 2008 Contents ƒ Roadrunner Project ƒ Roadrunner Architecture ƒ Cell Processor Architecture ƒ Cell SDK ƒ DaCS and ALF ƒ Accelerating an Existing Application ƒ References
- 156. 156 Roadrunner Tutorial February 7, 2008 References ƒ Roadrunner Web Site – http://lanl.gov/roadrunner/ – See “Roadrunner Technical Assessments” ƒ Roadrunner Applications Portal – http://rralgs.lanl.gov/portal ƒ Cell Resource Center – http://www.ibm.com/developerworks/power/cell/ – Select “Docs” tab – Introduction to Cell Programming: – Cell Broadband Engine Programmer's Guide – Cell Broadband Engine Programming Tutorial – Cell Broadband Engine Programming Handbook – Programming Reference: – C/C++ Language Extensions for Cell Broadband Engine Architecture – Data Communication and Synchronization Library for Hybrid-x86 Programmer's Guide and API Reference – Hardware Reference: – Cell Broadband Engine Architecture – Synergistic Processor Unit Instruction Set Architecture ƒ See me for a tarball of all Cell Docs
- 157. 157 Roadrunner Tutorial February 7, 2008 Thank You Questions . . .
- 158. 158 Roadrunner Tutorial February 7, 2008 This document was developed for IBM offerings in the United States as of the date of publication. IBM may not make these offerings available in other countries, and the information is subject to change without notice. Consult your local IBM business contact for information on the IBM offerings available in your area. In no event will IBM be liable for damages arising directly or indirectly from any use of the information contained in this document. Information in this document concerning non-IBM products was obtained from the suppliers of these products or other public sources. Questions on the capabilities of non-IBM products should be addressed to the suppliers of those products. IBM may have patents or pending patent applications covering subject matter in this document. The furnishing of this document does not give you any license to these patents. Send license inquires, in writing, to IBM Director of Licensing, IBM Corporation, New Castle Drive, Armonk, NY 10504-1785 USA. All statements regarding IBM future direction and intent are subject to change or withdrawal without notice, and represent goals and objectives only. The information contained in this document has not been submitted to any formal IBM test and is provided "AS IS" with no warranties or guarantees either expressed or implied. All examples cited or described in this document are presented as illustrations of the manner in which some IBM products can be used and the results that may be achieved. Actual environmental costs and performance characteristics will vary depending on individual client configurations and conditions. IBM Global Financing offerings are provided through IBM Credit Corporation in the United States and other IBM subsidiaries and divisions worldwide to qualified commercial and government clients. Rates are based on a client's credit rating, financing terms, offering type, equipment type and options, and may vary by country. Other restrictions may apply. Rates and offerings are subject to change, extension or withdrawal without notice. IBM is not responsible for printing errors in this document that result in pricing or information inaccuracies. All prices shown are IBM's United States suggested list prices and are subject to change without notice; reseller prices may vary. IBM hardware products are manufactured from new parts, or new and serviceable used parts. Regardless, our warranty terms apply. Many of the features described in this document are operating system dependent and may not be available on Linux. For more information, please check: http://www.ibm.com/systems/p/software/whitepapers/linux_overview.html Any performance data contained in this document was determined in a controlled environment. Actual results may vary significantly and are dependent on many factors including system hardware configuration and software design and configuration. Some measurements quoted in this document may have been made on development-level systems. There is no guarantee these measurements will be the same on generally- available systems. Some measurements quoted in this document may have been estimated through extrapolation. Users of this document should verify the applicable data for their specific environment. Revised January 19, 2006 Special Notices -- Trademarks
- 159. 159 Roadrunner Tutorial February 7, 2008 The following terms are trademarks of International Business Machines Corporation in the United States and/or other countries: alphaWorks, BladeCenter, Blue Gene, ClusterProven, developerWorks, e business(logo), e(logo)business, e(logo)server, IBM, IBM(logo), ibm.com, IBM Business Partner (logo), IntelliStation, MediaStreamer, Micro Channel, NUMA-Q, PartnerWorld, PowerPC, PowerPC(logo), pSeries, TotalStorage, xSeries; Advanced Micro- Partitioning, eServer, Micro-Partitioning, NUMACenter, On Demand Business logo, OpenPower, POWER, Power Architecture, Power Everywhere, Power Family, Power PC, PowerPC Architecture, POWER5, POWER5+, POWER6, POWER6+, Redbooks, System p, System p5, System Storage, VideoCharger, Virtualization Engine. A full list of U.S. trademarks owned by IBM may be found at: http://www.ibm.com/legal/copytrade.shtml. Cell Broadband Engine and Cell Broadband Engine Architecture are trademarks of Sony Computer Entertainment, Inc. in the United States, other countries, or both. Rambus is a registered trademark of Rambus, Inc. XDR and FlexIO are trademarks of Rambus, Inc. UNIX is a registered trademark in the United States, other countries or both. Linux is a trademark of Linus Torvalds in the United States, other countries or both. Fedora is a trademark of Redhat, Inc. Microsoft, Windows, Windows NT and the Windows logo are trademarks of Microsoft Corporation in the United States, other countries or both. Intel, Intel Xeon, Itanium and Pentium are trademarks or registered trademarks of Intel Corporation in the United States and/or other countries. AMD Opteron is a trademark of Advanced Micro Devices, Inc. Java and all Java-based trademarks and logos are trademarks of Sun Microsystems, Inc. in the United States and/or other countries. TPC-C and TPC-H are trademarks of the Transaction Performance Processing Council (TPPC). SPECint, SPECfp, SPECjbb, SPECweb, SPECjAppServer, SPEC OMP, SPECviewperf, SPECapc, SPEChpc, SPECjvm, SPECmail, SPECimap and SPECsfs are trademarks of the Standard Performance Evaluation Corp (SPEC). AltiVec is a trademark of Freescale Semiconductor, Inc. PCI-X and PCI Express are registered trademarks of PCI SIG. InfiniBand™ is a trademark the InfiniBand® Trade Association Other company, product and service names may be trademarks or service marks of others. Revised July 23, 2006 Special Notices (Cont.) -- Trademarks
- 160. 160 Roadrunner Tutorial February 7, 2008 (c) Copyright International Business Machines Corporation 2005. All Rights Reserved. Printed in the United Sates September 2005. The following are trademarks of International Business Machines Corporation in the United States, or other countries, or both. IBM IBM Logo Power Architecture Other company, product and service names may be trademarks or service marks of others. All information contained in this document is subject to change without notice. The products described in this document are NOT intended for use in applications such as implantation, life support, or other hazardous uses where malfunction could result in death, bodily injury, or catastrophic property damage. The information contained in this document does not affect or change IBM product specifications or warranties. Nothing in this document shall operate as an express or implied license or indemnity under the intellectual property rights of IBM or third parties. All information contained in this document was obtained in specific environments, and is presented as an illustration. The results obtained in other operating environments may vary. While the information contained herein is believed to be accurate, such information is preliminary, and should not be relied upon for accuracy or completeness, and no representations or warranties of accuracy or completeness are made. THE INFORMATION CONTAINED IN THIS DOCUMENT IS PROVIDED ON AN "AS IS" BASIS. In no event will IBM be liable for damages arising directly or indirectly from any use of the information contained in this document. IBM Microelectronics Division The IBM home page is http://www.ibm.com 1580 Route 52, Bldg. 504 The IBM Microelectronics Division home page is Hopewell Junction, NY 12533-6351 http://www.chips.ibm.com Special Notices - Copyrights