Scala, Apache Spark, The PlayFramework and Docker in IBM Platform As A Service
2 likes1,074 views

This document discusses technologies for building reactive web services and performing data analytics. It describes using NodeJS, NodeRED, Scala, Play Framework, Apache Spark, Docker, Docker Compose, and IBM Bluemix Platform as a Service. An example use case is presented that collects tweets using NodeRED, performs sentiment analysis on tweets with IBM Watson, stores tweets in OpenStack Swift and HDFS, performs retrospective analysis on tweets with Apache Spark, and visualizes results in real-time with Play Framework.














![PlayFramework REST Service
def data = Action.async {
var statement = connection.createStatement
val resultSet = statement.executeQuery("select count(*) as
total, (select count(*) as IBM from tweetsift where UCASE(tweet)
like '%IBM%'), (select count(*) as softlayer from tweetsift where
UCASE(tweet) like '%SOFTLAYER%') from tweetsift")
resultSet.next() // we expect exactly one row
val total = resultSet.getInt("TOTAL")
val ibm = resultSet.getInt("IBM")
val softlayer = resultSet.getInt("SOFTLAYER")
val result = "["+total+","+ibm+","+softlayer+"]"
Ok(result)
}](https://image.slidesharecdn.com/scalaapachesparktheplayframeworkdockerandplatformasaservicesoftshake20151022-151026125034-lva1-app6892/85/Scala-Apache-Spark-The-PlayFramework-and-Docker-in-IBM-Platform-As-A-Service-16-320.jpg)







Scala, Apache Spark, The PlayFramework and Docker in IBM Platform As A Service
- 1. Soft-Shake 15 - Geneva @romeokienzler [email protected] Scala, Apache Spark, The PlayFramework, Docker and Platform as a Service
- 2. The Ingredients NodeJS NodeRED Scala The Play Framework Apache Spark Docker, DockerCompose, DockerSwarm Platform as a Service powered by IBM Bluemix 2
- 3. NodeJS Server Side JavaScript Runtime Framework OpenSource Very frequently used by Startups REACTIVE (see explanation on PlayFramework slide) 3
- 4. NodeRED OpenSource Data Integration Framework Supports Visual Programming Very large set of connectors and extensions (> 400) Created by IBM Runs on top of NodeJS Extensible through JavaScript 4
- 5. Scala Invented @EPFL Runs on top of JVM Open but commercialized through Typsafe Strong on functional programming paradigm (nice for data analytics tasks) Supports OOP as well 5
- 6. The PlayFramework Written in Scala Compatible with Scala and Java Meant to build REACTIVE HTTP services by unbinding the requests from the threads through callback handlers Used at LinkedIn for example and at a major company in Valais 6
- 7. Apache Spark Successor of MapReduce Supports various data stores, e.g. HDFS, Swift, S3, ... Forces you to use functional programming Therefore creates highly parallelizable code Programmable in Java, Scala and Python Central Data Structure are RDDs (Resilient Distributed Datasets) virtualizing the underlying storage architecture 7
- 8. Docker Behavior similar to virtual machines Based on cgroups and namespaces Linux kernel extension Uses LXC internally In contrast to virtual machines the runtime instances are called container Operating system processes are running on the host system but within a container they apear to be alone A docker container starts in < 100 ms and you can run 100rds of them on a single host system 8
- 9. DockerCompose A way to define and run a multi container topology Topology defined in a single docker-compose.yml file Individual containers serving different tiers can be scaled up/down 9
- 10. DockerSwarm What if a single machine is to weak to run your topology? Groups multiple nodes together to act as a single docker node Uses same API than DOCKER on a standalone machine In combination with DockerCompose you get a lightweight and ultra fast scaling runtime 10
- 11. Platform as a Service through IBM Bluemix Powerd by CloudFoundry (OpenSource/OpenStandard) Supports Docker, runs on DockerSwarm (with a container placement optimizer) DockerCompose support by end of year Supports virtual machines via OpenStack > 100 services (e.g. Hadoop, Spark, SWIFT, MongoDB, MySQL, Watson, ...) Core runtime for this talk 11
- 12. Usecase Get tweets for the public twitter API (not firehose) Using NodeRED add sentiment analysis through an IBM Watson Service Store tweets plus sentiment score in OpenStack Swift Service on Bluemix Additionally store them in the HDFS Service on Bluemix Using Apache Spark and Scala apply retrospective analysis Using BigSQL, JQuery and the PlayFramework draw a realtime chart 12
- 13. Architecture – Get the tweets NodeRED OpenStack SWIFT HADOOP HDFS 13
- 14. Architecture – down stream analysis OpenStack SWIFT HADOOP HDFS Spark Service BigSQL iPyhton Notebook supporting Scala CloudFoundry Container with PlayFramework running on JVM REST Service Web Browser running AJAX application using JQuery 14
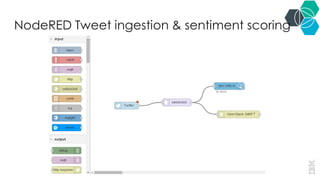
- 15. NodeRED Tweet ingestion & sentiment scoring
- 16. PlayFramework REST Service def data = Action.async { var statement = connection.createStatement val resultSet = statement.executeQuery("select count(*) as total, (select count(*) as IBM from tweetsift where UCASE(tweet) like '%IBM%'), (select count(*) as softlayer from tweetsift where UCASE(tweet) like '%SOFTLAYER%') from tweetsift") resultSet.next() // we expect exactly one row val total = resultSet.getInt("TOTAL") val ibm = resultSet.getInt("IBM") val softlayer = resultSet.getInt("SOFTLAYER") val result = "["+total+","+ibm+","+softlayer+"]" Ok(result) }
- 17. Preprocessed data using R service in Bluemix 17
- 18. JQuery AJAX WebApplication calling REST Service
- 19. View on the SWIFT explorer
- 20. Apache Spark Access to the data in IBM Bluemix var tweets = sc.textFile("swift://softshake.spark/tmp_25573-tweets1126007960.csv"); var companies = sc.textFile("swift://softshake.spark/tmp_25573-companies-384438100.csv"); val tweetsHeaderAndRows = tweets.map(line => line.split(",").map(_.trim)) val tweetsHeader = tweetsHeaderAndRows.first val tweetsData = tweetsHeaderAndRows.filter(_(0) != tweetsHeader(0)) val tweetMaps = tweetsData.map(splits => tweetsHeader.zip(splits).toMap) val companiesData = companies.filter(s => !s.equals("COMPANY_NAME_ID"));
- 21. Calculating tweet frequency per company val tweetsWithCompany = tweetMaps.cartesian(companiesData).filter(t => t._1("TEXT").toLowerCase().contains(t._2.toLowerCase)) val companyAndScore = tweetsWithCompany.map(t => (t._2,t._1("SCORE").toDouble)) val companyFrequency = companyAndScore.map(t => (t._2,1)).reduceByKey(_ + _)
- 22. Wanna do it yourself? IBM Cloud Free Tier (incl. Bluemix): http://ibm.biz/joinIBMCloud 24-120K CHF Cloud credits for startups [email protected] *A*N*Y question [email protected] Free usage for Students and Faculties [email protected]
- 23. Wanna hear more? Nov 2nd. in Zurich: Apache Spark Advanced Meetup http://www.meetup.com/HackSessionsSwitzerland/events/225445919/?oc=evam Nov 3rd. in Berne: - cloud computing - Apache spark - challenges in NG sequencing http://www.meetup.com/SwissLifeScience/events/225836187/?oc=evam Nov 11th. in Lausanne: Introduction to Docker, Streamcomputing on ApacheSpark and InfoSphere Streams http://www.meetup.com/HackSessionsSwitzerland/events/225441845/?oc=evam Some sessions will be streamed at: http://www.meetup.com/Cloud-Scale-Data-Science-virtual-UserGroup- worldwide/