Scala Data Pipelines for Music Recommendations
194 likes163,758 views

The document discusses the architecture and design of music recommendation systems at Spotify, emphasizing the use of machine learning techniques like collaborative filtering and matrix factorization. It details the data pipelines for processing user listening data and generating genre-specific artist toplists using tools such as Scalding and Apache Parquet. Additionally, the document covers various methodologies for efficiently handling and analyzing large datasets to improve music recommendations.








![The Genre Toplist Problem 9
•Assume we have access to daily log data for all plays on Spotify.
•Goal: Calculate the top 1k artists on for each genre based on total daily plays
{"User": “userA”, "Date": “2015-01-10", "Artist": “Beyonce", "Track": "Halo", "Genres": ["Pop", "R&B", "Soul"]}
{"User": “userB”, "Date": “2015-01-10”, "Artist": "Led Zeppelin”, "Track": "Achilles Last Stand", "Genres": ["Rock",
"Blues Rock", "Hard Rock"]}
……….](https://image.slidesharecdn.com/ddtx15-150112083927-conversion-gate01/85/Scala-Data-Pipelines-for-Music-Recommendations-9-320.jpg)





(implicit ord :
Ordering[K]) extends Monoid[PriorityQueue[K]]](https://image.slidesharecdn.com/ddtx15-150112083927-conversion-gate01/85/Scala-Data-Pipelines-for-Music-Recommendations-16-320.jpg)
![sortWithTake 17
•Uses PriorityQueueMonoid from Algebird
•PriorityQueue aggregations form a commutative monoid!
1. Associative:
PQ1 = [ (Jay Z, 545), (Miles Davis, 272), …]
PQ2 = [ (Beyonce, 731), (Kurt Vile, 372), …]
PQ3 = [ (Twin Shadow, 87), … ]
PQ1 ++ (PQ2 ++ PQ3) = (PQ1 ++ PQ2) ++ PQ3
2.Commutative:
PQ1 ++ PQ2 = PQ2 ++ PQ1
3.Identity:
PQ1 ++ EmptyPQ = PQ1
class PriorityQueueMonoid[K](max : Int)(implicit ord :
Ordering[K]) extends Monoid[PriorityQueue[K]]](https://image.slidesharecdn.com/ddtx15-150112083927-conversion-gate01/85/Scala-Data-Pipelines-for-Music-Recommendations-17-320.jpg)
(implicit ord :
Ordering[K]) extends Monoid[PriorityQueue[K]]
reduced traffic](https://image.slidesharecdn.com/ddtx15-150112083927-conversion-gate01/85/Scala-Data-Pipelines-for-Music-Recommendations-18-320.jpg)
































Scala Data Pipelines for Music Recommendations
- 1. January 6, 2015 Scala Data Pipelines for Music Recommendations Chris Johnson @MrChrisJohnson
- 2. Who am I?? •Chris Johnson – Machine Learning guy from NYC – Focused on music recommendations – Formerly a PhD student at UTAustin
- 3. Spotify in Numbers 3 •Started in 2006, now available in 58 markets •50+ million active users, 15 million paying subscribers •30+ million songs, 20,000 new songs added per day •1.5 billion playlists •1 TB user data logged per day •900 node Hadoop cluster •10,000+ Hadoop jobs run every day
- 4. 4 Music Recommendations at Spotify •Discover •Radio •Related Artists
- 5. How can we find good recommendations? 5 •Manual Curation •Manually Tag Attributes •Audio Content •News, Blogs, Text analysis •Collaborative Filtering
- 6. Music Recommendations Data Flow 6
- 7. Why ? 7
- 8. Why ? 8 Interview Question
- 9. The Genre Toplist Problem 9 •Assume we have access to daily log data for all plays on Spotify. •Goal: Calculate the top 1k artists on for each genre based on total daily plays {"User": “userA”, "Date": “2015-01-10", "Artist": “Beyonce", "Track": "Halo", "Genres": ["Pop", "R&B", "Soul"]} {"User": “userB”, "Date": “2015-01-10”, "Artist": "Led Zeppelin”, "Track": "Achilles Last Stand", "Genres": ["Rock", "Blues Rock", "Hard Rock"]} ……….
- 10. Genre Toplists with Python MapReduce 10
- 11. 11 Scalding is a Scala library that makes it easy to specify Hadoop MapReduce jobs. Scalding is built on top of Cascading, a Java library that abstracts away low-level Hadoop details. Scalding is comparable to Pig, but offers tight integration with Scala, bringing advantages of Scala to your MapReduce jobs. -Twitter
- 12. Genre Toplists with Scalding 12
- 13. Why ? 13 •Data pipeline flows naturally follow the functional paradigm •Productivity without sacrificing performance •Active community and ecosystem -Scalding -Summingbird -Algebird -Spark -Breeze •Many data storage solutions integrate well with JVM -Cassandra -HBase -Voldemort -Datomic
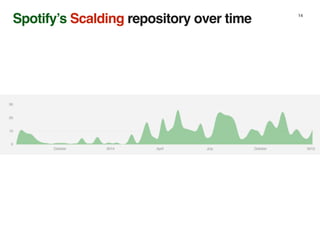
- 14. Spotify’s Scalding repository over time 14
- 15. Genre Toplists with Scalding 15
- 16. sortWithTake doesn’t fully sort 16 •Uses PriorityQueueMonoid from Algebird library •What is a Monoid?? -Definition: A Set S and a binary operation • : S x S —> S such that 1. Associativity: For all a, b, and c in S the equation (a • b) • c = a • (b • c) holds 2. Identity Element: There exists an element e in S such that for every element a in S, the equations e • a = a • e = a hold •Example: The natural numbers N under the addition operation. (1 + 2) + 3 = 1 + (2 + 3) 0 + 1 = 1 + 0 = 1 class PriorityQueueMonoid[K](max : Int)(implicit ord : Ordering[K]) extends Monoid[PriorityQueue[K]]
- 17. sortWithTake 17 •Uses PriorityQueueMonoid from Algebird •PriorityQueue aggregations form a commutative monoid! 1. Associative: PQ1 = [ (Jay Z, 545), (Miles Davis, 272), …] PQ2 = [ (Beyonce, 731), (Kurt Vile, 372), …] PQ3 = [ (Twin Shadow, 87), … ] PQ1 ++ (PQ2 ++ PQ3) = (PQ1 ++ PQ2) ++ PQ3 2.Commutative: PQ1 ++ PQ2 = PQ2 ++ PQ1 3.Identity: PQ1 ++ EmptyPQ = PQ1 class PriorityQueueMonoid[K](max : Int)(implicit ord : Ordering[K]) extends Monoid[PriorityQueue[K]]
- 18. sortWithTake 18 •Uses PriorityQueueMonoid from Algebird •Ok, great observation… but what’s the point of all this!?? -All monoid aggregations and reduces can begin on the Mapper side and finish on the Reducer side since the order doesn’t matter! -Scalding implicitly takes care of Mapper side combining and custom combiner -Reduces network traffic to reducers class PriorityQueueMonoid[K](max : Int)(implicit ord : Ordering[K]) extends Monoid[PriorityQueue[K]] reduced traffic
- 19. Section name 19
- 20. How do we store track metadata? 20 •Lots of metadata associated with tracks (100+ columns!) -artist, album, record label, genres, audio features, … •Options: 1. Store each track as one long row with many columns -Sending lots of data over network when you only need 1 or 2 columns 2. Store each column as a separate data source -Jobs require costly joins, especially when requiring many columns •Can we do better?..
- 21. Apache Parquet to the rescue! 21 •Apache Parquet is a columnar storage format available to any project in the Hadoop ecosystem, regardless of the choice of data processing framework, data model or programming language. •Efficiently read a subset of columns without scanning the entire dataset •Row group: A logical horizontal partitioning of the data into rows. There is no physical structure that is guaranteed for a row group. A row group consists of a column chunk for each column in the dataset. •Column chunk: A chunk of the data for a particular column. These live in a particular row group and is guaranteed to be contiguous in the file. •Predicate push-down: Define predicates (<, >, <=, …) to filter out column chunks or even full row groups, evaluated at Hadoop InputFormat layer before Avro conversion
- 22. Genre Toplists with Scalding + Parquet 22
- 23. Driven - job visualization and performance analytics 23
- 24. Luigi - data plumbing since 2012 24 •Workflow management framework developed by Spotify •Python luigi configuration takes care of dependency resolution, job scheduling, fault tolerance, etc. •Support for Hive queries, MapReduce jobs, python snippets, Scalding, Crunch, Spark, and more! •Like Oozie but without all of the messy XML https://github.com/spotify/luigi
- 25. Luigi 25
- 26. Section name 26
- 27. So…. back to music recommendations! 27 •Manual Curation •Manually Tag Attributes •Audio Content •News, Blogs, Text analysis •Collaborative Filtering
- 28. Collaborative Filtering 28 Hey, I like tracks P, Q, R, S! Well, I like tracks Q, R, S, T! Then you should check out track P! Nice! Btw try track T! Image via Erik Bernhardsson
- 29. Implicit Matrix Factorization 29 1 0 0 0 1 0 0 1 0 0 1 0 0 1 0 0 1 0 1 0 0 0 1 1 0 1 0 0 0 1 0 0 0 0 1 0 0 1 0 0 1 0 0 0 1 0 0 1 •Aggregate all (user, track) streams into a large matrix •Goal: Approximate binary preference matrix by the inner product of 2 smaller matrices by minimizing the weighted RMSE (root mean squared error) using a function of total plays as weight •Why?: Once learned, the top recommendations for a user are the top inner products between their latent factor vector in X and the track latent factor vectors in Y. X YUsers Songs • = bias for user • = bias for item • = regularization parameter • = 1 if user streamed track else 0 • • = user latent factor vector • = item latent factor vector
- 30. Alternating Least Squares 30 1 0 0 0 1 0 0 1 0 0 1 0 0 1 0 0 1 0 1 0 0 0 1 1 0 1 0 0 0 1 0 0 0 0 1 0 0 1 0 0 1 0 0 0 1 0 0 1 X YUsers Songs • = bias for user • = bias for item • = regularization parameter • = 1 if user streamed track else 0 • • = user latent factor vector • = item latent factor vector Fix tracks •Aggregate all (user, track) streams into a large matrix •Goal: Approximate binary preference matrix by the inner product of 2 smaller matrices by minimizing the weighted RMSE (root mean squared error) using a function of total plays as weight •Why?: Once learned, the top recommendations for a user are the top inner products between their latent factor vector in X and the track latent factor vectors in Y.
- 31. 31 1 0 0 0 1 0 0 1 0 0 1 0 0 1 0 0 1 0 1 0 0 0 1 1 0 1 0 0 0 1 0 0 0 0 1 0 0 1 0 0 1 0 0 0 1 0 0 1 X YUsers Songs • = bias for user • = bias for item • = regularization parameter • = 1 if user streamed track else 0 • • = user latent factor vector • = item latent factor vector Fix tracks Solve for users •Aggregate all (user, track) streams into a large matrix •Goal: Approximate binary preference matrix by the inner product of 2 smaller matrices by minimizing the weighted RMSE (root mean squared error) using a function of total plays as weight •Why?: Once learned, the top recommendations for a user are the top inner products between their latent factor vector in X and the track latent factor vectors in Y. Alternating Least Squares
- 32. 32 1 0 0 0 1 0 0 1 0 0 1 0 0 1 0 0 1 0 1 0 0 0 1 1 0 1 0 0 0 1 0 0 0 0 1 0 0 1 0 0 1 0 0 0 1 0 0 1 X YUsers Songs • = bias for user • = bias for item • = regularization parameter • = 1 if user streamed track else 0 • • = user latent factor vector • = item latent factor vector Fix users •Aggregate all (user, track) streams into a large matrix •Goal: Approximate binary preference matrix by the inner product of 2 smaller matrices by minimizing the weighted RMSE (root mean squared error) using a function of total plays as weight •Why?: Once learned, the top recommendations for a user are the top inner products between their latent factor vector in X and the track latent factor vectors in Y. Alternating Least Squares
- 33. 33 1 0 0 0 1 0 0 1 0 0 1 0 0 1 0 0 1 0 1 0 0 0 1 1 0 1 0 0 0 1 0 0 0 0 1 0 0 1 0 0 1 0 0 0 1 0 0 1 X YUsers Songs • = bias for user • = bias for item • = regularization parameter • = 1 if user streamed track else 0 • • = user latent factor vector • = item latent factor vector Fix users Solve for tracks •Aggregate all (user, track) streams into a large matrix •Goal: Approximate binary preference matrix by the inner product of 2 smaller matrices by minimizing the weighted RMSE (root mean squared error) using a function of total plays as weight •Why?: Once learned, the top recommendations for a user are the top inner products between their latent factor vector in X and the track latent factor vectors in Y. Alternating Least Squares
- 34. 34 1 0 0 0 1 0 0 1 0 0 1 0 0 1 0 0 1 0 1 0 0 0 1 1 0 1 0 0 0 1 0 0 0 0 1 0 0 1 0 0 1 0 0 0 1 0 0 1 X YUsers Songs • = bias for user • = bias for item • = regularization parameter • = 1 if user streamed track else 0 • • = user latent factor vector • = item latent factor vector Fix users Solve for tracks Repeat until convergence… •Aggregate all (user, track) streams into a large matrix •Goal: Approximate binary preference matrix by the inner product of 2 smaller matrices by minimizing the weighted RMSE (root mean squared error) using a function of total plays as weight •Why?: Once learned, the top recommendations for a user are the top inner products between their latent factor vector in X and the track latent factor vectors in Y. Alternating Least Squares
- 35. 35 1 0 0 0 1 0 0 1 0 0 1 0 0 1 0 0 1 0 1 0 0 0 1 1 0 1 0 0 0 1 0 0 0 0 1 0 0 1 0 0 1 0 0 0 1 0 0 1 X YUsers Songs • = bias for user • = bias for item • = regularization parameter • = 1 if user streamed track else 0 • • = user latent factor vector • = item latent factor vector Fix users Solve for tracks Repeat until convergence… •Aggregate all (user, track) streams into a large matrix •Goal: Approximate binary preference matrix by the inner product of 2 smaller matrices by minimizing the weighted RMSE (root mean squared error) using a function of total plays as weight •Why?: Once learned, the top recommendations for a user are the top inner products between their latent factor vector in X and the track latent factor vectors in Y. Alternating Least Squares
- 36. Matrix Factorization with MapReduce 36 Reduce stepMap step u % K = 0 i % L = 0 u % K = 0 i % L = 1 ... u % K = 0 i % L = L-1 u % K = 1 i % L = 0 u % K = 1 i % L = 1 ... ... ... ... ... ... u % K = K-1 i % L = 0 ... ... u % K = K-1 i % L = L-1 item vectors item%L=0 item vectors item%L=1 item vectors i % L = L-1 user vectors u % K = 0 user vectors u % K = 1 user vectors u % K = K-1 all log entries u % K = 1 i % L = 1 u % K = 0 u % K = 1 u % K = K-1 Figure via Erik Bernhardsson
- 37. Matrix Factorization with MapReduce 37 One map task Distributed cache: All user vectors where u % K = x Distributed cache: All item vectors where i % L = y Mapper Emit contributions Map input: tuples (u, i, count) where u % K = x and i % L = y Reducer New vector! Figure via Erik Bernhardsson
- 38. 38 •Fast and general purpose cluster computing system •Provides high-level apis in Java, Scala, and Python •Takes advantage of in-memory caching to reduce I/O bottleneck of Hadoop MapReduce •MLlib: Scalable Machine Learning library packaged with Spark -Collaborative Filtering and Matrix Factorization -Classification and Regression -Clustering -Optimization Primitives •Spark Streaming: Real time, scalable, fault-tolerant stream processing •Spark SQL: allows relational queries expressed in SQL, HiveQL, or Scala to be executed using Spark
- 39. Matrix Factorization with Spark 39 streams user vectors item vectors worker 1 worker 2 worker 3 worker 4 worker 5 worker 6 •Partition streams matrix into user (row) and item (column) blocks, partition, and cache -Unlike with the MapReduce implementation, ratings are never shuffled across the network! •For each iteration: 1. Compute YtY over item vectors and broadcast 2. For each item vector, send a copy to each user rating partition that requires it (potentially all partitions) 3. Each partition aggregates intermediate terms and solves for optimal user vectors
- 40. Matrix Factorization with Spark 40 user vectors item vectors worker 1 worker 2 worker 3 worker 4 worker 5 worker 6 •Partition streams matrix into user (row) and item (column) blocks, partition, and cache -Unlike with the MapReduce implementation, ratings are never shuffled across the network! •For each iteration: 1. Compute YtY over item vectors and broadcast 2. For each item vector, send a copy to each user rating partition that requires it (potentially all partitions) 3. Each partition aggregates intermediate terms and solves for optimal user vectors streams
- 41. Matrix Factorization with Spark 41 user vectors item vectors •Partition streams matrix into user (row) and item (column) blocks, partition, and cache -Unlike with the MapReduce implementation, ratings are never shuffled across the network! •For each iteration: 1. Compute YtY over item vectors and broadcast 2. For each item vector, send a copy to each user rating partition that requires it (potentially all partitions) 3. Each partition aggregates intermediate terms and solves for optimal user vectors worker 1 worker 2 worker 3 worker 4 worker 5 worker 6 streams
- 42. Matrix Factorization with Spark 42 user vectors item vectors worker 1 worker 2 worker 3 worker 4 worker 5 worker 6 YtY YtY YtY YtY YtY YtY •Partition streams matrix into user (row) and item (column) blocks, partition, and cache -Unlike with the MapReduce implementation, ratings are never shuffled across the network! •For each iteration: 1. Compute YtY over item vectors and broadcast 2. For each item vector, send a copy to each user rating partition that requires it (potentially all partitions) 3. Each partition aggregates intermediate terms and solves for optimal user vectors streams
- 43. Matrix Factorization with Spark 43 user vectors item vectors worker 1 worker 2 worker 3 worker 4 worker 5 worker 6 YtY YtY YtY YtY YtY YtY •Partition streams matrix into user (row) and item (column) blocks, partition, and cache -Unlike with the MapReduce implementation, ratings are never shuffled across the network! •For each iteration: 1. Compute YtY over item vectors and broadcast 2. For each item vector, send a copy to each user rating partition that requires it (potentially all partitions) 3. Each partition aggregates intermediate terms and solves for optimal user vectors streams
- 44. Matrix Factorization with Spark 44 user vectors item vectors worker 1 worker 2 worker 3 worker 4 worker 5 worker 6 YtY YtY YtY YtY YtY YtY •Partition streams matrix into user (row) and item (column) blocks, partition, and cache -Unlike with the MapReduce implementation, ratings are never shuffled across the network! •For each iteration: 1. Compute YtY over item vectors and broadcast 2. For each item vector, send a copy to each user rating partition that requires it (potentially all partitions) 3. Each partition aggregates intermediate terms and solves for optimal user vectors streams
- 45. 45 Vs http://www.slideshare.net/Hadoop_Summit/spark-and-shark Matrix Factorization with MapReduce Matrix Factorization with Spark
- 46. Scala Breeze 46 •Native Scala numerical processing library •Linear Algebra -Matrix operations -Operator overloading and syntactic sugar •Sampling from Probably Distributions •Numerical Optimization •Plotting and Visualizations •Numpy for Scala
- 47. Zeppelin + Spark + Parquet for ETL 47
- 48. Zeppelin + Spark + Parquet for ETL 48
- 49. What should I be worried about? 49 •Multiple “right” ways to do the same thing •Implicits can make code difficult to navigate •Learning curve can be tough •Avoid flattening before a join •Be aware that Scala default collections are immutable (though mutable versions are also available) •Use monoid reduces and aggregations where possible and avoid folds •Be patient with the compiler