

























































![Word Embeddings
v(paris) = [0.13, -0.4, 0.22, …., -0.45]
v(lion) = [-0.23, -0.1, 0.98, …., 0.65]
v(quark) = [1.4, 0.32, -0.01, …, 0.023]
...](https://image.slidesharecdn.com/5bbhaskarordentlich-160614184838/85/Scaling-Machine-Learning-To-Billions-Of-Parameters-60-320.jpg)









![Word2vec Application at Yahoo
• Example training data:
gas_cap_replacement_for_car
slc_679f037df54f5d9c41cab05bfae0926
gas_door_replacement_for_car
slc_466145af16a40717c84683db3f899d0a fuel_door_covers
adid_c_28540527225_285898621262
slc_348709d73214fdeb9782f8b71aff7b6e autozone_auto_parts
adid_b_3318310706_280452370893 auoto_zone
slc_8dcdab5d20a2caa02b8b1d1c8ccbd36b
slc_58f979b6deb6f40c640f7ca8a177af2d
[ Grbovic, et. al. SIGIR 2015 and SIGIR 2016 (to appear) ]](https://image.slidesharecdn.com/5bbhaskarordentlich-160614184838/85/Scaling-Machine-Learning-To-Billions-Of-Parameters-70-320.jpg)

























Scaling Machine Learning To Billions Of Parameters
- 1. Scaling Machine Learning To Billions of Parameters Badri Bhaskar, Erik Ordentlich (joint with Andy Feng, Lee Yang, Peter Cnudde) Yahoo, Inc.
- 2. Outline • Large scale machine learning (ML) • Spark + Parameter Server – Architecture – Implementation • Examples: - Distributed L-BFGS (Batch) - Distributed Word2vec (Sequential) • Spark + Parameter Server on Hadoop Cluster
- 4. 1.2 1.2 -78 6.3 -8.1 5.4 -8 4.2 2.3 -3.4 -1.1 2.3 4.9 7.4 4.5 2.1 -15 2.3 2.3 0.5 1.2 -0.9 -24 -1.3 -2.2 1.8 -4.9 -2.1 1.2 Web Scale ML Billions of features Hundredsofbillionsofexamples Big Model BigData Ex: Yahoo word2vec - 120 billion parameters and 500 billion samples
- 5. 1.2 1.2 -78 6.3 -8.1 5.4 -8 4.2 2.3 -3.4 -1.1 2.3 4.9 7.4 4.5 2.1 -15 2.3 2.3 0.5 1.2 -0.9 -24 -1.3 -2.2 1.8 -4.9 -2.1 1.2 Web Scale ML Billions of features Hundredsofbillionsofexamples Big Model BigData Ex: Yahoo word2vec - 120 billion parameters and 500 billion samples Store Store Store
- 6. 1.2 1.2 -78 6.3 -8.1 5.4 -8 4.2 2.3 -3.4 -1.1 2.3 4.9 7.4 4.5 2.1 -15 2.3 2.3 0.5 1.2 -0.9 -24 -1.3 -2.2 1.8 -4.9 -2.1 1.2 Web Scale ML Billions of features Hundredsofbillionsofexamples Big Model BigData Ex: Yahoo word2vec - 120 billion parameters and 500 billion samples Worker Worker Worker Store Store Store
- 7. 1.2 1.2 -78 6.3 -8.1 5.4 -8 4.2 2.3 -3.4 -1.1 2.3 4.9 7.4 4.5 2.1 -15 2.3 2.3 0.5 1.2 -0.9 -24 -1.3 -2.2 1.8 -4.9 -2.1 1.2 Web Scale ML Billions of features Hundredsofbillionsofexamples Big Model BigData Ex: Yahoo word2vec - 120 billion parameters and 500 billion samples Worker Worker Worker Store Store Store Each example depends only on a tiny fraction of the model
- 8. Two Optimization Strategies Model Multiple epochs… BATCH Example: Gradient Descent, L-BFGS Model Model Model SEQUENTIAL Multiple random samples… Example: (Minibatch) stochastic gradient method, perceptron Examples
- 9. Two Optimization Strategies Model Multiple epochs… BATCH Example: Gradient Descent, L-BFGS Model Model Model SEQUENTIAL Multiple random samples… Example: (Minibatch) stochastic gradient method, perceptron • Small number of model updates • Accurate • Each epoch may be expensive. • Easy to parallelize. Examples
- 10. Two Optimization Strategies Model Multiple epochs… BATCH Example: Gradient Descent, L-BFGS Model Model Model SEQUENTIAL Multiple random samples… Example: (Minibatch) stochastic gradient method, perceptron • Small number of model updates • Accurate • Each epoch may be expensive. • Easy to parallelize. • Requires lots of model updates. • Not as accurate, but often good enough • A lot of progress in one pass* for big data. • Not trivial to parallelize. *also optimal in terms of generalization error (often with a lot of tuning) Examples
- 11. Requirements
- 12. Requirements ✓ Support both batch and sequential optimization
- 13. Requirements ✓ Support both batch and sequential optimization ✓ Sequential training: Handle frequent updates to the model
- 14. Requirements ✓ Support both batch and sequential optimization ✓ Sequential training: Handle frequent updates to the model ✓ Batch training: 100+ passes each pass must be fast.
- 15. Parameter Server (PS) Client Data Client Data Client Data Client Data Training state stored in PS shards, asynchronous updates PS Shard PS ShardPS Shard ΔM Model Update M Model Early work: Yahoo LDA by Smola and Narayanamurthy based on memcached (2010), Introduced in Google’s Distbelief (2012), refined in Petuum / Bösen (2013), Mu Li et al (2014)
- 16. SPARK + PARAMETER SERVER
- 17. ML in Spark alone Executor Executor CoreCore Core Core Core Driver Holds model
- 18. ML in Spark alone Executor Executor CoreCore Core Core Core Driver Holds model MLlib optimization
- 19. ML in Spark alone • Sequential: – Driver-based communication limits frequency of model updates. – Large minibatch size limits model update frequency, convergence suffers. Executor Executor CoreCore Core Core Core Driver Holds model MLlib optimization
- 20. ML in Spark alone • Sequential: – Driver-based communication limits frequency of model updates. – Large minibatch size limits model update frequency, convergence suffers. • Batch: – Driver bandwidth can be a bottleneck – Synchronous stage wise processing limits throughput. Executor Executor CoreCore Core Core Core Driver Holds model MLlib optimization
- 21. ML in Spark alone • Sequential: – Driver-based communication limits frequency of model updates. – Large minibatch size limits model update frequency, convergence suffers. • Batch: – Driver bandwidth can be a bottleneck – Synchronous stage wise processing limits throughput. Executor Executor CoreCore Core Core Core Driver Holds model MLlib optimization PS Architecture circumvents both limitations…
- 22. Spark + Parameter Server
- 23. • Leverage Spark for HDFS I/O, distributed processing, fine-grained load balancing, failure recovery, in-memory operations Spark + Parameter Server
- 24. • Leverage Spark for HDFS I/O, distributed processing, fine-grained load balancing, failure recovery, in-memory operations • Use PS to sync models, incremental updates during training, or sometimes even some vector math. Spark + Parameter Server
- 25. • Leverage Spark for HDFS I/O, distributed processing, fine-grained load balancing, failure recovery, in-memory operations • Use PS to sync models, incremental updates during training, or sometimes even some vector math. Spark + Parameter Server HDFS Training state stored in PS shards Driver Executor ExecutorExecutor CoreCore Core Core PS Shard PS ShardPS Shard control control
- 26. Yahoo PS
- 29. Yahoo PS Server Client API GC Preallocated arrays • In-memory • Lock per key / Lock-free • Sync / Async K-V
- 30. Yahoo PS Server Client API GC Preallocated arrays • In-memory • Lock per key / Lock-free • Sync / Async K-V • Column- partitioned • Supports BLAS
- 31. Yahoo PS Server Client API GC Preallocated arrays • In-memory • Lock per key / Lock-free • Sync / Async K-V • Column- partitioned • Supports BLAS • Export Model • Checkpoint HDFS
- 32. Yahoo PS Server Client API GC Preallocated arrays • In-memory • Lock per key / Lock-free • Sync / Async K-V • Column- partitioned • Supports BLAS • Export Model • Checkpoint HDFS UDF • Client supplied aggregation • Custom shard operations
- 33. Map PS API • Distributed key-value store abstraction • Supports batched operations in addition to usual get and put • Many operations return a future – you can operate asynchronously or block
- 34. Matrix PS API • Vector math (BLAS style operations), in addition to everything Map API provides • Increment and fetch sparse vectors (e.g., for gradient aggregation) • We use other custom operations on shard (API not shown)
- 35. EXAMPLES
- 38. Sponsored Search Advertising query user ad context Features Model Example Click Model: (Logistic Regression)
- 40. L-BFGS Background Newton’s method Gradient Descent Using curvature information, you can converge faster…
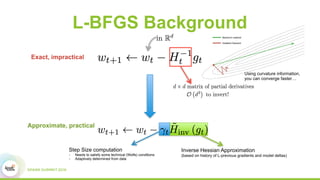
- 41. L-BFGS Background Exact, impractical Newton’s method Gradient Descent Using curvature information, you can converge faster…
- 42. L-BFGS Background Exact, impractical Step Size computation - Needs to satisfy some technical (Wolfe) conditions - Adaptively determined from data Inverse Hessian Approximation (based on history of L-previous gradients and model deltas) Approximate, practical Newton’s method Gradient Descent Using curvature information, you can converge faster…
- 43. L-BFGS Background Exact, impractical Step Size computation - Needs to satisfy some technical (Wolfe) conditions - Adaptively determined from data Inverse Hessian Approximation (based on history of L-previous gradients and model deltas) Approximate, practical Newton’s method Gradient Descent Using curvature information, you can converge faster…
- 44. L-BFGS Background Exact, impractical Step Size computation - Needs to satisfy some technical (Wolfe) conditions - Adaptively determined from data Inverse Hessian Approximation (based on history of L-previous gradients and model deltas) Approximate, practical Newton’s method Gradient Descent Using curvature information, you can converge faster…
- 45. L-BFGS Background Exact, impractical Step Size computation - Needs to satisfy some technical (Wolfe) conditions - Adaptively determined from data Inverse Hessian Approximation (based on history of L-previous gradients and model deltas) Approximate, practical Newton’s method Gradient Descent Using curvature information, you can converge faster… dotprod axpy (y ← ax + y) copy axpy scal scal Vector Math dotprod
- 46. L-BFGS Background Exact, impractical Step Size computation - Needs to satisfy some technical (Wolfe) conditions - Adaptively determined from data Inverse Hessian Approximation (based on history of L-previous gradients and model deltas) Approximate, practical Newton’s method Gradient Descent Using curvature information, you can converge faster…
- 47. Executor ExecutorExecutor HDFS HDFSHDFS Driver PS PS PS PS Distributed LBFGS* Compute gradient and loss 1. Incremental sparse gradient update 2. Fetch sparse portions of model Coordinates executor Step 1: Compute and update Gradient *Our design is very similar to Sandblaster L-BFGS, Jeff Dean et al, Large Scale Distributed Deep Networks (2012) state vectors
- 48. Executor ExecutorExecutor HDFS HDFSHDFS Driver PS PS PS PS Distributed LBFGS* Compute gradient and loss 1. Incremental sparse gradient update 2. Fetch sparse portions of model Coordinates executor Step 1: Compute and update Gradient *Our design is very similar to Sandblaster L-BFGS, Jeff Dean et al, Large Scale Distributed Deep Networks (2012) state vectors
- 49. Executor ExecutorExecutor HDFS HDFSHDFS Driver PS PS PS PS Distributed LBFGS Coordinates PS for performing L-BFGS updates Actual L-BFGS updates (BLAS vector math) Step 2: Build inverse Hessian Approximation
- 50. Executor ExecutorExecutor HDFS HDFSHDFS Driver PS PS PS PS Distributed LBFGS Coordinates executor Compute directional derivatives for parallel line search Fetch sparse portions of modelStep 3: Compute losses and directional derivatives
- 51. Executor ExecutorExecutor HDFS HDFSHDFS Driver PS PS PS PS Distributed LBFGS Performs line search and model update Model update (BLAS vector math)Step 4: Line search and model update
- 52. Speedup tricks
- 53. Speedup tricks • Intersperse communication and computation
- 54. Speedup tricks • Intersperse communication and computation • Quicker convergence – Parallel line search for step size – Curvature for initial Hessian approximation* *borrowed from vowpal wabbit
- 55. Speedup tricks • Intersperse communication and computation • Quicker convergence – Parallel line search for step size – Curvature for initial Hessian approximation* • Network bandwidth reduction – Compressed integer arrays – Only store indices for binary data *borrowed from vowpal wabbit
- 56. Speedup tricks • Intersperse communication and computation • Quicker convergence – Parallel line search for step size – Curvature for initial Hessian approximation* • Network bandwidth reduction – Compressed integer arrays – Only store indices for binary data • Matrix math on minibatch *borrowed from vowpal wabbit
- 57. Speedup tricks • Intersperse communication and computation • Quicker convergence – Parallel line search for step size – Curvature for initial Hessian approximation* • Network bandwidth reduction – Compressed integer arrays – Only store indices for binary data • Matrix math on minibatch 0 750 1500 2250 3000 10 20 100 221612 2880 1260 96 MLlib PS + Spark 1.6 x 108 examples, 100 executors, 10 cores time(inseconds)perepoch feature size (millions) *borrowed from vowpal wabbit
- 58. Word Embeddings
- 59. Word Embeddings
- 60. Word Embeddings v(paris) = [0.13, -0.4, 0.22, …., -0.45] v(lion) = [-0.23, -0.1, 0.98, …., 0.65] v(quark) = [1.4, 0.32, -0.01, …, 0.023] ...
- 61. Word2vec
- 62. Word2vec
- 63. Word2vec • new techniques to compute vector representations of words from corpus
- 64. Word2vec • new techniques to compute vector representations of words from corpus • geometry of vectors captures word semantics
- 65. Word2vec
- 66. Word2vec • Skipgram with negative sampling:
- 67. Word2vec • Skipgram with negative sampling: – training set includes pairs of words and neighbors in corpus, along with randomly selected words for each neighbor
- 68. Word2vec • Skipgram with negative sampling: – training set includes pairs of words and neighbors in corpus, along with randomly selected words for each neighbor – determine w → u(w),v(w) so that sigmoid(u(w)•v(w’)) is close to (minimizes log loss) the probability that w’ is a neighbor of w as opposed to a randomly selected word.
- 69. Word2vec • Skipgram with negative sampling: – training set includes pairs of words and neighbors in corpus, along with randomly selected words for each neighbor – determine w → u(w),v(w) so that sigmoid(u(w)•v(w’)) is close to (minimizes log loss) the probability that w’ is a neighbor of w as opposed to a randomly selected word. – SGD involves computing many vector dot products e.g., u(w)•v(w’) and vector linear combinations e.g., u(w) += α v(w’).
- 70. Word2vec Application at Yahoo • Example training data: gas_cap_replacement_for_car slc_679f037df54f5d9c41cab05bfae0926 gas_door_replacement_for_car slc_466145af16a40717c84683db3f899d0a fuel_door_covers adid_c_28540527225_285898621262 slc_348709d73214fdeb9782f8b71aff7b6e autozone_auto_parts adid_b_3318310706_280452370893 auoto_zone slc_8dcdab5d20a2caa02b8b1d1c8ccbd36b slc_58f979b6deb6f40c640f7ca8a177af2d [ Grbovic, et. al. SIGIR 2015 and SIGIR 2016 (to appear) ]
- 72. Distributed Word2vec • Needed system to train 200 million 300 dimensional word2vec model using minibatch SGD
- 73. Distributed Word2vec • Needed system to train 200 million 300 dimensional word2vec model using minibatch SGD • Achieved in a high throughput and network efficient way using our matrix based PS server:
- 74. Distributed Word2vec • Needed system to train 200 million 300 dimensional word2vec model using minibatch SGD • Achieved in a high throughput and network efficient way using our matrix based PS server: – Vectors don’t go over network.
- 75. Distributed Word2vec • Needed system to train 200 million 300 dimensional word2vec model using minibatch SGD • Achieved in a high throughput and network efficient way using our matrix based PS server: – Vectors don’t go over network. – Most compute on PS servers, with clients aggregating partial results from shards.
- 76. Distributed Word2vec Word2vec learners PS Shards V1 row V2 row … Vn row HDFS . . .
- 77. Distributed Word2vec Word2vec learners PS Shards V1 row V2 row … Vn row Each shard stores a part of every vector HDFS . . .
- 78. Distributed Word2vec Send word indices and seeds Word2vec learners PS Shards V1 row V2 row … Vn row HDFS . . .
- 79. Distributed Word2vec Negative sampling, compute u•v Word2vec learners PS Shards V1 row V2 row … Vn row HDFS . . .
- 80. Distributed Word2vec Word2vec learners PS Shards Aggregate results & compute lin. comb. coefficients (e.g., α…) V1 row V2 row … Vn row HDFS . . .
- 81. Distributed Word2vec Word2vec learners PS Shards V1 row V2 row … Vn row Update vectors (v += αu, …) HDFS . . .
- 83. Distributed Word2vec • Network lower by factor of #shards/dimension compared to conventional PS based system (1/20 to 1/100 for useful scenarios).
- 84. Distributed Word2vec • Network lower by factor of #shards/dimension compared to conventional PS based system (1/20 to 1/100 for useful scenarios). • Trains 200 million vocab, 55 billion word search session in 2.5 days.
- 85. Distributed Word2vec • Network lower by factor of #shards/dimension compared to conventional PS based system (1/20 to 1/100 for useful scenarios). • Trains 200 million vocab, 55 billion word search session in 2.5 days. • In production for regular training in Yahoo search ad serving system.
- 86. Other Projects using Spark + PS • Online learning on PS – Personalization as a Service – Sponsored Search • Factorization Machines – Large scale user profiling
- 87. SPARK+PS ON HADOOP CLUSTER
- 88. Training Data on HDFS HDFS
- 89. Launch PS Using Apache Slider on YARN HDFS YARN Apache Slider Parameter Servers
- 90. Launch Clients using Spark or Hadoop Streaming API HDFS YARN Apache Slider Parameter Servers Apache Spark Clients
- 92. Model Export HDFS YARN Apache Slider Parameter Server Apache Spark Clients
- 93. Model Export HDFS YARN Apache Slider Parameter Server Apache Spark Clients
- 94. Summary • Parameter server indispensable for big models • Spark + Parameter Server has proved to be very flexible platform for our large scale computing needs • Direct computation on the parameter servers accelerate training for our use-cases
- 95. Thank you! For more, contact [email protected].