











![CSharpRDD
• C# operations use CSharpRDD which needs CLR to execute
• If no C# transformation or UDF is involved, CLR is not needed – execution is
purely JVM-based
• RDD<byte[]>
• Data is stored as serialized objects and sent to C# worker process
• Transformations are pipelined when possible
• Avoids unnecessary serialization & deserialization within a stage](https://image.slidesharecdn.com/seattle-spark-meetup-mobius-csharp-api-160316050736/85/Seattle-Spark-Meetup-Mobius-CSharp-API-13-320.jpg)





































![DStream sample
// write code here to drop text files under <directory>test
… … …
StreamingContext ssc = StreamingContext.GetOrCreate(checkpointPath,
() =>
{
SparkContext sc = SparkCLRSamples.SparkContext;
StreamingContext context = new StreamingContext(sc, 2000);
context.Checkpoint(checkpointPath);
var lines = context.TextFileStream(Path.Combine(directory, "test"));
var words = lines.FlatMap(l => l.Split(' '));
var pairs = words.Map(w => new KeyValuePair<string, int>(w, 1));
var wordCounts = pairs.ReduceByKey((x, y) => x + y);
var join = wordCounts.Join(wordCounts, 2);
var state = join.UpdateStateByKey<string, Tuple<int, int>, int>((vs, s) => vs.Sum(x => x.Item1 + x.Item2) + s);
state.ForeachRDD((time, rdd) =>
{
object[] taken = rdd.Take(10);
});
return context;
});
ssc.Start();
ssc.AwaitTermination();](https://image.slidesharecdn.com/seattle-spark-meetup-mobius-csharp-api-160316050736/85/Seattle-Spark-Meetup-Mobius-CSharp-API-53-320.jpg)
Seattle Spark Meetup Mobius CSharp API
- 1. Mobius: C# API for Spark Seattle Spark Meetup – Feb 2016 Speakers: Kaarthik Sivashanmugam, linkedin.com/in/kaarthik Renyi Xiong, linkedin.com/in/renyi-xiong-95597628
- 2. Agenda • Background • Architecture • Sample Code • Demo (if time permits) • Early lessons on Spark Streaming with Mobius
- 3. Joining the Community • Consider joining the C# API dev community for Spark to • Develop Spark applications in C# and provide feedback • Contribute to the open source project @ github.com/Microsoft/Mobius
- 4. Target Scenario • Near real time processing of Bing logs (aka “Fast SML”) • Size of raw logs - hundreds of TB per hour • Downstream scenarios • NRT click signal & improved relevance on fresh results • Operational Intelligence • Bad flight detection • … Another team we partnered with had an interactive scenario need for querying Cosmos logs
- 5. Implementations of FastSML 1. Microsoft’s internal low-latency, transactional storage and processing platform 2. Apache Storm (SCP.Net) + Kafka + Microsoft’s internal in-memory streaming analytics engine • Can Apache Spark help implement a better solution? • How can we reuse existing investments in FastSML?
- 6. C# API - Motivations • Enable organizations invested deeply in .NET to start building Spark apps and not have to do development in Scala, Java, Python or R • Enable reuse of existing .NET libraries in Spark applications
- 7. C# API - Goal Make C# a first-class citizen for building Apache Spark apps for the following job types • Batch jobs (RDD API) • Streaming jobs (Streaming API) • Structured data processing or SQL jobs (DataFrame API)
- 8. Design Considerations • JVM – CLR (.NET VM) interop • Spark runs on JVM • C# operations to process data needs CLR for execution • Avoid re-implementing Spark’s functionality for data input, output, persistence etc. • Re-use design & code from Python & R Spark language bindings
- 9. C# API for Spark Scala/Java API SparkR PySpark C# API Apache Spark Spark Apps in C#
- 11. C# Worker CLR IPC Sockets C# Worker CLR IPC Sockets C# Worker CLR IPC Sockets Interop C# Driver CLR IPC Sockets SparkExecutor SparkExecutor SparkExecutor SparkContext JVM JVM JVM JVM Workers Driver
- 12. Reuse • Driver-side interop uses Netty server as a proxy to JVM – similar to SparkR • Worker-side interop reuses PySpark implementation • CSharpRDD inherits from PythonRDD reusing the implementation to launch external process, pipe in/out serialized data
- 13. CSharpRDD • C# operations use CSharpRDD which needs CLR to execute • If no C# transformation or UDF is involved, CLR is not needed – execution is purely JVM-based • RDD<byte[]> • Data is stored as serialized objects and sent to C# worker process • Transformations are pipelined when possible • Avoids unnecessary serialization & deserialization within a stage
- 14. Linux Support • Mono (open source implementation of .NET framework) used for C# with Spark in Linux • GitHub project uses Travis for CI in Ubuntu 14.04.3 LTS • Unit tests and samples (functional tests) are run • More info @ linux-instructions.md
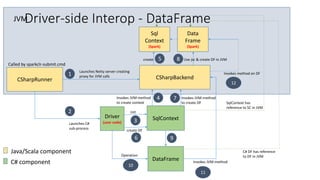
- 15. CSharpRunner Called by sparkclr-submit.cmd JVM Java/Scala component C# component CSharpBackend Launches Netty server creating proxy for JVM calls1 Driver (user code)Launches C# sub-process 2 SqlContext Init 3 Invokes JVM-method to create context 4 Sql Context (Spark) create 5 create DF 6 Invokes JVM-method to create DF 7 Data Frame (Spark) Use jsc & create DF in JVM8 10 Operation DataFrame 9 C# DF has reference to DF in JVM 11 Invokes JVM-method SqlContext has reference to SC in JVM 12 Invokes method on DF Driver-side Interop - DataFrame
- 16. C# Worker Launch executable as sub-process Serialize data & user-implemented C# lambda and send through socket Serialize processed data and send through socket CSharpRDDSpark calls Compute() Scala component C# component CSharpRDD implementation extends PythonRDD Note that CSharpRDD is not used when there is no user-implemented custom C# code. In such cases CSharpWorker is not involved in execution. Executor-side Interop - RDD
- 17. Performance Considerations • Map & Filter RDD operations in C# require serialization & deserialization of data – impacts performance • C# operations are pipelined when possible - minimizes unnecessary Ser/De • Persistence is handled by JVM - checkpoint/cache on a RDD impacts pipelining for CLR operations • DataFrame operations without C# UDFs do not require Ser/De • Perf will be same as native Spark application • Execution plan optimization & code generation perf improvements in Spark leveraged
- 18. Status • Past Releases • V1.5.200 (supports Spark 1.5.2) • V.1.6.000-PREVIEW1 (supports Spark 1.6.0) • Upcoming Release • V1.6.100 (with support for Spark 1.6.1, in April’16) • In the works • Support for interactive scenarios (Zeppelin/Jupyter integration) • MapWithState API for streaming • Perf benchmarking
- 19. Project Info • Repo - https://github.com/Microsoft/Mobius. Contributions welcome! • Services integrated with the repo • AppVeyor – Windows builds, unit and functional tests, NuGet & Maven deployment • Travis CI – Linux builds, unit and functional tests • CodeCov – unit test code coverage measurement & analysis • License – code is released under MIT license • Discussions • StackOverflow – tag “SparkCLR” • Gitter - https://gitter.im/Microsoft/Mobius
- 20. API Reference Mobius API usage samples are available in the repo at: • Samples - comprehensive set of C# APIs & functional tests • Examples - standalone C# projects demonstrating C# API • Pi • EventHub • SparkXml • JdbcDataFrame • … (could be your contribution!) • Performance tests – side by side comparison of Scala & C# drivers API documentation
- 21. JDBC Example
- 23. EventHub Example
- 24. Log Processing Sample Walkthrough Requests log Guid Datacenter ABTestId TrafficType Metrics log Unused Date Time Guid Lang Country Latency Scenario – Join data in two log files using guid and compute max and avg latency metrics grouped by datacenter
- 25. Log Processing Steps Load Request log Load Metrics log
- 26. Log Processing Load Request log Load Metrics log Get columns in each row Get columns in each row
- 27. Log Processing Load Request log Load Metrics log Get columns in each row Get columns in each row Join by “Guid” column
- 28. Log Processing Load Request log Load Metrics log Get columns in each row Get columns in each row Join by “Guid” column Compute Max(latency) by Datacenter
- 29. Log Processing Load Request log Load Metrics log Get columns in each row Get columns in each row Join by “Guid” column Compute Avg(latency) by Datacenter
- 30. Log Processing using DataFrame DSL
- 31. Log Processing using DataFrame TempTable
- 32. Log Processing – Schema Specification Schema spec in JSON is also supported
- 33. Early Lessons on Spark Streaming with Mobius
- 34. Lesson 1: Use UpdateStateByKey to join DStreams • Use Case - merge click and impression streams within an application time window • Why not Stream-stream joins? • Application time is not supported in Spark 1.6. Window Operations is based on wall-clock. • Solution – UpdateStateByKey • UpdateStateByKey takes a custom JoinFunction as input parameter; • Custom JoinFunction enforces time window based on Application Time; • UpdateStabeByKey maintains partially joined events as the state Impression DStream Click DStream Batch job 1 RDD @ time 1 Batch job 2 RDD @ time 2 State DStream UpdateStateByKey Batch job 3 RDD @ time 3
- 35. • Recommend Direct Approach for reading from Kafka !!! • Kafka issues 1. Unbalanced partition 2. Insufficient partitions • Solution – Dynamic Repartition 1. Repartition data from one Kafka partition into multiple RDDs 2. How to repartition is configurable 3. JIRA to be filed soon Lesson 2: Dynamic Repartition for Kafka Direct After Dynamic Repartition Before Dynamic Repartition2-minute interval
- 36. How you can engage • Develop Spark applications in C# and provide feedback • Contributions are welcome to the open source project @ https://github.com/Microsoft/Mobius
- 37. Thanks to… • Spark community – for building Spark • Mobius contributors – for their contributions • SparkR and PySpark developers – Mobius reuses design and code from these implementations • Reynold Xin and Josh Rosen from Databricks for the review and feedback on Mobius design doc
- 38. Back-up Slides
- 39. Driver-side IPC Interop Using a Netty server as a proxy to JVM
- 40. Driver-side implementation in SparkCLR • Driver-side interaction between JVM & CLR is the same for RDD and DataFrame APIs -- CLR executes calls on JVM. • For streaming scenarios, CLR executes calls on JVM and JVM calls back to CLR to create C# RDD
- 41. DataFrame
- 42. CSharpRunner Called by sparkclr-submit.cmd Driver (user code)Launches C# sub-process SqlContext Init CSharpBackend Launches Netty server creating proxy for JVM calls Sql Context (Spark) JVM Invokes JVM-method to create context create DataFrame create DF 1 2 3 4 5 6 Invokes JVM-method to create SC 7 Data Frame (Spark) Use jsc & create DF in JVM8 9 10 Operation 11 DF has reference to DF in JVM Java/Scala component C# component Invokes JVM-method SqlContext has reference to SC in JVM All components will be SparkCLR contributions except for user code and Spark components 12 Invokes method on DF
- 43. RDD
- 44. CSharpRunner Called by sparkclr-submit.cmd Driver (user code)Launches C# sub-process SparkContext Init CSharpBackend Launches Netty server creating proxy for JVM calls Spark Context (Spark) JVM Invokes JVM-method to create context create RDD create RDD CSharpRDD Invokes JVM-method to create RDD RDD (Spark) Use jsc & create JRDD 1 2 3 4 5 6 7 8 9 create 10 C# operation PipelinedRDD11 12 RDD has reference to RDD in JVM Java/Scala component C# component Invokes JVM-method to create C#RDD 13 SparkContext has reference to SC in JVM All components will be SparkCLR contributions except for user code and Spark components
- 45. DStream
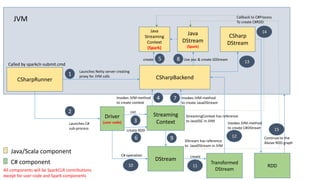
- 46. CSharpRunner Called by sparkclr-submit.cmd Driver (user code)Launches C# sub-process Streaming Context Init CSharpBackend Launches Netty server creating proxy for JVM calls Java Streaming Context (Spark) JVM Invokes JVM-method to create context create DStream create RDD CSharp DStream Invokes JVM-method to create JavaDStream Java DStream (Spark) Use jssc & create JDStream 1 2 3 4 5 6 7 8 9 create 10 C# operation Transformed DStream 11 12 DStream has reference to JavaDStream in JVM Java/Scala component C# component Invokes JVM-method to create C#DStream 13 StreamingContext has reference to JavaSSC in JVM All components will be SparkCLR contributions except for user code and Spark components RDD 14 Callback to C#Process To create C#RDD 15 Continue to the Above RDD graph
- 47. Executor-side IPC Interop Using pipes to send data between JVM & CLR
- 48. C# Lambda in RDD Similar to Python implementation
- 49. CSharpRDDSpark calls Compute() SparkCLR Worker Launch executable as sub-process Serialize data & user-implemented C# lambda and send through socket Serialize processed data and send through socket Java/Scala component C# component CSharpRDD implementation extends PythonRDD Note that CSharpRDD is not used when there is no user-implemented custom C# code. In such cases CSharpWorker is not involved in execution.
- 50. C# UDFs in DataFrame Similar to Python implementation
- 51. Spark UDF Core (Python) C# Driver 1 2 3 4 C# Worker Register UDF Run SQL with UDF Run UDF Pickled data sqlContext.RegisterFunction<bool, string, int>("PeopleFilter", (name, age) => name == "Bill" && age > 40, "boolean"); sqlContext.Sql("SELECT name, address.city, address.state FROM people where PeopleFilter(name, age)")
- 52. SparkCLR Streaming API Similar to Python implementation
- 53. DStream sample // write code here to drop text files under <directory>test … … … StreamingContext ssc = StreamingContext.GetOrCreate(checkpointPath, () => { SparkContext sc = SparkCLRSamples.SparkContext; StreamingContext context = new StreamingContext(sc, 2000); context.Checkpoint(checkpointPath); var lines = context.TextFileStream(Path.Combine(directory, "test")); var words = lines.FlatMap(l => l.Split(' ')); var pairs = words.Map(w => new KeyValuePair<string, int>(w, 1)); var wordCounts = pairs.ReduceByKey((x, y) => x + y); var join = wordCounts.Join(wordCounts, 2); var state = join.UpdateStateByKey<string, Tuple<int, int>, int>((vs, s) => vs.Sum(x => x.Item1 + x.Item2) + s); state.ForeachRDD((time, rdd) => { object[] taken = rdd.Take(10); }); return context; }); ssc.Start(); ssc.AwaitTermination();
Editor's Notes
- #12: Sockets provide point-to-point, two-way communication between two processes. Sockets are very versatile and are a basic component of interprocess and intersystem communication. A socket is an endpoint of communication to which a name can be bound. It has a type and one or more associated processes.