![[1] Cho, Kyunghyun, et al. "Learning phrase representations using RNN encoder-decoder for statistical
machine translation." arXiv preprint arXiv:1406.1078 (2014).
[2] Sutskever, Ilya, Oriol Vinyals, and Quoc V. Le. "Sequence to sequence learning with neural
networks." Advances in neural information processing systems. 2014.
01
Seq2Seq (Encoder-Decoder) Model
Olivia Ni](https://image.slidesharecdn.com/seq2seqencoder-decodermodel-191108161701/85/Seq2Seq-encoder-decoder-model-1-320.jpg)


![04
Introduction (2/2)
編碼器 (Encoder)
Use one RNN to analyze input sequence
• In thesis [1], this encoder RNN = GRU
• In thesis [2], this encoder RNN = LSTM
解碼器 (Decoder)
Use another RNN to generate output sequence
• In thesis [1], this encoder RNN = GRU
• In thesis [2], this encoder RNN = LSTM
上下文向量 (context vector)
A fixed-length vector representations for
the input sentence](https://image.slidesharecdn.com/seq2seqencoder-decodermodel-191108161701/85/Seq2Seq-encoder-decoder-model-4-320.jpg)















![• Cho, Kyunghyun, et al. "Learning phrase representations using RNN encoder-decoder for statistical
machine translation." arXiv preprint arXiv:1406.1078 (2014).
• Sutskever, Ilya, Oriol Vinyals, and Quoc V. Le. "Sequence to sequence learning with neural
networks." Advances in neural information processing systems. 2014.
• Xu, Kelvin, et al. "Show, attend and tell: Neural image caption generation with visual
attention." International conference on machine learning. 2015.
• Bengio, Samy, et al. "Scheduled sampling for sequence prediction with recurrent neural
networks." Advances in Neural Information Processing Systems. 2015.
• Wiseman, Sam, and Alexander M. Rush. "Sequence-to-sequence learning as beam-search
optimization." arXiv preprint arXiv:1606.02960 (2016).
• 台大 李宏毅 教授 [Machine Learning and having it deep and structured (2018,Spring)]
• 台大 陳縕儂 教授 [Applied Deep Learning(2019,Spring)]
22
Reference](https://image.slidesharecdn.com/seq2seqencoder-decodermodel-191108161701/85/Seq2Seq-encoder-decoder-model-22-320.jpg)

Seq2Seq (encoder decoder) model
- 1. [1] Cho, Kyunghyun, et al. "Learning phrase representations using RNN encoder-decoder for statistical machine translation." arXiv preprint arXiv:1406.1078 (2014). [2] Sutskever, Ilya, Oriol Vinyals, and Quoc V. Le. "Sequence to sequence learning with neural networks." Advances in neural information processing systems. 2014. 01 Seq2Seq (Encoder-Decoder) Model Olivia Ni
- 2. • Introduction • Seq2Seq (Encoder-Decoder) Model • Preliminary: LSTM & GRU • Notation • Encoder • Decoder • Training Process • Tips for Seq2Seq (Encoder-Decoder) Model • Attention • Scheduled Sampling • Beam Search • Appendix (Word Embedding/ Representation) • Reference 02 Outline
- 3. 03 Introduction (1/2) One-to-One Many-to-One One-to-Many Many-to-Many Many-to-Many Standard NN model w/o recurrent structure, from fixed-sized input to fixed- sized output. RNN-based model w/ recurrent structure, from non-fixed-sized sequence input to fixed-sized output. RNN-based model w/ recurrent structure, from fixed-sized input to non- fixed-sized sequence output. RNN-based model w/ recurrent structure, from non-fixed-sized sequence input to non-fixed-sized sequence output. RNN-based model w/ recurrent structure, from non-fixed-sized synced sequence input to non- fixed-sized sequence output. Image classification Sentiment analysis where a given sentence is classified as expressing positive or negative sentiment. Image captioning takes an image and outputs a sentence of words. Machine translation: a RNN reads a sentence in English and then outputs a sentence in French. Video classification where we wish to label each frame of the video. # Each rectangle vector; Each arrow function (matrix multiplication) # Red Input vectors; Blue Output vectors; Green RNN’s hidden states
- 4. 04 Introduction (2/2) 編碼器 (Encoder) Use one RNN to analyze input sequence • In thesis [1], this encoder RNN = GRU • In thesis [2], this encoder RNN = LSTM 解碼器 (Decoder) Use another RNN to generate output sequence • In thesis [1], this encoder RNN = GRU • In thesis [2], this encoder RNN = LSTM 上下文向量 (context vector) A fixed-length vector representations for the input sentence
- 5. 05 Seq2Seq Model - Preliminary: LSTM (1/5) • The cell state runs straight down the entire chain, with only some minor linear interactions. Easy for information to flow along it unchanged • The LSTM does have the ability to remove or add information to the cell state, carefully regulated by structures called gates.
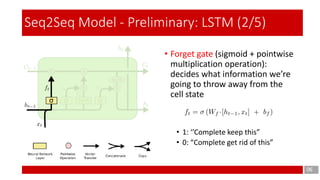
- 6. 06 Seq2Seq Model - Preliminary: LSTM (2/5) • Forget gate (sigmoid + pointwise multiplication operation): decides what information we’re going to throw away from the cell state • 1: ‘’Complete keep this” • 0: “Complete get rid of this”
- 7. 07 Seq2Seq Model - Preliminary: LSTM (3/5) • Input gate (sigmoid + pointwise multiplication operation): decides what new information we’re going to store in the cell state Vanilla RNN
- 8. 08 Seq2Seq Model - Preliminary: LSTM (4/5) • Cell state update: forgets the things we decided to forget earlier and add the new candidate values, scaled by how much we decided to update • 𝑓𝑡: decide which to forget • 𝑖 𝑡: decide which to update ⟹ 𝐶𝑡 has been updated at timestamp 𝑡, which change slowly!
- 9. 09 Seq2Seq Model - Preliminary: LSTM (5/5) • Output gate (sigmoid + pointwise multiplication operation): decides what new information we’re going to output ⟹ ℎ 𝑡 has been updated at timestamp 𝑡, which change faster!
- 10. 10 Seq2Seq Model - Preliminary: GRU Update gate: Reset gate: State Candidate: Current State: • Gated Recurrent Unit (GRU) • Idea: • combine the forget and input gates into a single “update gate” • merge the cell state and hidden state
- 11. 11 Seq2Seq Model - Notation 𝑽(𝒔) The vocabulary size of the input 𝒙𝒊 The one-hot vector of i-th word in the input sentence ഥ𝒙𝒊 The embedding vector of i-th word in the input sentence 𝑬(𝒔) Embedding matrix of the encoder 𝒉𝒊 𝒔 The i-th hidden vector of the encoder 𝑽(𝒕) The vocabulary size of the output 𝒚𝒋 The one-hot vector of j-th word in the output sentence ഥ𝒚𝒋 The embedding vector of j-th word in the output sentence 𝑬(𝒕) Embedding matrix of the decoder 𝒉𝒋 𝒕 The j-th hidden vector of the decoder
- 12. 12 Seq2Seq Model - Encoder Encoder Embedding Layer The encoder embedding layer converts each word in the input sentence to the embedding vector, when processing the i-th word in the input sentence, the input and the output of the layer are the following: The input is 𝒙𝒊: the one-hot vector which represent i-th word The output is ഥ𝒙𝒊: the embedding vector which represent i-th word Each embedding vector is calculated by the following process: ഥ𝒙𝒊 = 𝑬(𝒔) 𝒙𝒊 , where 𝑬(𝒔) ∈ ℝ 𝑫× 𝑽 𝒔 is the embedding matrix of the encoder. Encoder Recurrent Layer The encoder recurrent layer generates the hidden vectors from the embedding vectors, when processing the i-th embedding vector, the input and the output of the layer are the following: The input is ഥ𝒙𝒊: the embedding vector which represent i-th word The output is 𝒉𝒊 𝒔 : the hidden vector of the i-th position Each hidden vector 𝒉𝒊 𝒔 is calculated by the following process: 𝒉𝒊 𝒔 = 𝝍(𝒔) ഥ𝒙𝒊, 𝒉𝒊−𝟏 𝒔 , where 𝝍(𝒔) could be an LSTM, GRU model, etc.
- 13. 13 Seq2Seq Model - Decoder Decoder Embedding Layer The decoder embedding layer converts each word in the output sentence to the embedding vector. When processing the j-th word in the output sentence, the input and the output of the layer are the following: The input is 𝒚𝒋−𝟏: the one-hot vector which represent (j-1)- th word generated by the decoder output layer The output is ഥ𝒚𝒋: the embedding vector which represent (j-1)-th word Each embedding vector is calculated by the following process: ഥ𝒚𝒋 = 𝑬(𝒕) 𝒚𝒋−𝟏 , where 𝑬(𝒕) ∈ ℝ 𝑫× 𝑽 𝒕 is the embedding matrix of the encoder. Decoder Recurrent Layer The decoder recurrent layer generates the hidden vectors from the embedding vectors, when processing the j-th embedding vector, the input and the output of the layer are the following: The input is ഥ𝒚𝒋: the embedding vector The output is 𝒉𝒋 𝒕 : the hidden vector of the j-th position Each hidden vector 𝒉𝒋 𝒕 is calculated by the following process: 𝒉𝒋 𝒕 = 𝝍(𝒕) ഥ𝒙𝒋, 𝒉𝒋−𝟏 𝒕 , where 𝝍(𝒕) could be an LSTM, GRU model, etc. And, we must use the encoder’s hidden vector of the last position as the decoder’s hidden vector of the first position as following: 𝒉 𝟎 𝒕 = 𝒛 = 𝒉 𝑰 𝒔 Decoder Output Layer The decoder output layer generates the probability of the j-th word of the output sentence from the hidden vector, when processing the j-th embedding vector, the input and the output of the layer are the following: The input is 𝒉𝒋 𝒕 : the hidden vector of the j-th position The output is 𝒑𝒋: the probability of generating the one-hot vector 𝒚𝒋 of the j-th word Each probabilities is calculated by the following process: 𝒑𝒋 = 𝑷 𝜽 𝒚𝒋|𝒀<𝒋 = 𝐬𝐨𝐟𝐭𝐦𝐚𝐱 𝒐𝒋 = 𝐬𝐨𝐟𝐭𝐦𝐚𝐱 𝐖(𝟎) 𝒉𝒋 𝒕 + 𝐛(𝟎)
- 14. • MLE (Maximum Likelihood Estimation) for the following conditional probability: 𝑃 𝜃 𝒀|𝑿 = 𝑃 𝜃 𝑦𝑗 𝑗=0 𝐽+1 |𝑿 = ෑ 𝑗=1 𝐽+1 𝑃 𝜃 𝑦𝑗|𝒀<𝒋, 𝑿 = ෑ 𝑗=1 𝐽+1 𝑃 𝜃 𝑦𝑗|𝒀<𝒋, 𝒛 • Minimize the following lost function: −log 𝑃 𝜃 𝒀|𝑿 = −log𝑃 𝜃 𝑦𝑗 𝑗=0 𝐽+1 |𝑿 = − 𝑗=1 𝐽+1 𝑃 𝜃 𝑦𝑗|𝒀<𝒋, 𝑿 = − 𝑗=1 𝐽+1 𝑃 𝜃 𝑦𝑗|𝒀<𝒋, 𝒛 14 Seq2Seq Model – Training Process
- 15. 15 Tips for Seq2Seq Model - Attention 𝛼1 1 𝛼2 1 𝛼3 1 𝛼4 1 𝛼1 2 𝛼2 2 𝛼3 2 𝛼4 2 𝛼1 3 𝛼2 3 𝛼3 3 𝛼4 3 𝛼1 4 𝛼2 4 𝛼3 4 𝛼4 4 • Good Attention: Each input component has approximately the same attention weight (e.g.) Regularization term on attention The generated sentence will be like w1 w2(woman)w3 w4(woman) ⟹ no cooking information ⟹ bad attention! 𝑖 𝜏 − 𝑡 𝛼 𝑡 𝑖 2 For each component Over the generation
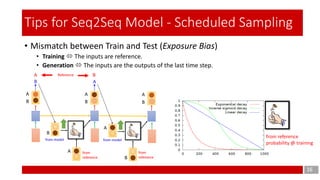
- 16. • Mismatch between Train and Test (Exposure Bias) • Training The inputs are reference. • Generation The inputs are the outputs of the last time step. 16 Tips for Seq2Seq Model - Scheduled Sampling from reference probability @ training
- 17. • Beam search (vs. Greedy Search) • Core idea: Keep several best path at each step • Not possible to check all the paths ⟹ Pre-define parameter: Beam size = 2 17 Tips for Seq2Seq Model - Beam Search A B A AB B A B A B A B A B 0.4 0.9 0.9 0.6 0.4 0.4 0.6 0.6 Beam searchGreedy Search
- 18. • Recall: There are two embedding layers in the seq2seq model. • How to learn their embedding matrix? Word embedding/ representation! • History: 18 Appendix – Word Embedding/ Representation Issues: (1)newly-invented words, (2)subjective, (3)annotation effort, (4)difficult to compute word similarity Knowledge-based representation Corpus-based representation Atomic symbol (One-hot encoding) Neighbors High-dimensional sparse word vector (window-based co-occurrence matrix) Low-dimensional dense word vector dimension reduction (SVD) direct Learning (word2vec, Glove)
- 19. Knowledge-based representation Corpus-based representation Atomic symbol (One-hot encoding) Neighbors High-dimensional sparse word vector (window-based co-occurrence matrix) Low-dimensional dense word vector dimension reduction (SVD) direct Learning (word2vec, Glove) • Recall: There are two embedding layers in the seq2seq model. • How to learn their embedding matrix? Word embedding/ representation! • History: 19 Appendix – Word Embedding/ Representation Issues: difficult to compute the similarity Idea: words with similar meanings often have similar neighbors
- 20. • Recall: There are two embedding layers in the seq2seq model. • How to learn their embedding matrix? Word embedding/ representation! • History: 20 Appendix – Word Embedding/ Representation Knowledge-based representation Corpus-based representation Atomic symbol (One-hot encoding) Neighbors High-dimensional sparse word vector (window-based co-occurrence matrix) Low-dimensional dense word vector dimension reduction (SVD) direct Learning (word2vec, Glove) Issues: (1)matrix size increases with vocabulary, (2)high dimensional, (3)sparsity → poor robustness Idea: low dimensional word vector
- 21. • Recall: There are two embedding layers in the seq2seq model. • How to learn their embedding matrix? Word embedding/ representation! • History: 21 Appendix – Word Embedding/ Representation Knowledge-based representation Corpus-based representation Atomic symbol (One-hot encoding) Neighbors High-dimensional sparse word vector (window-based co-occurrence matrix) Low-dimensional dense word vector dimension reduction (SVD) direct Learning (word2vec, Glove) Issues: (1)computationally expensive: O(mn^2) when n < m for n x m matrix, (2)difficult to add new words Idea: directly learn low-dimensional word vectors
- 22. • Cho, Kyunghyun, et al. "Learning phrase representations using RNN encoder-decoder for statistical machine translation." arXiv preprint arXiv:1406.1078 (2014). • Sutskever, Ilya, Oriol Vinyals, and Quoc V. Le. "Sequence to sequence learning with neural networks." Advances in neural information processing systems. 2014. • Xu, Kelvin, et al. "Show, attend and tell: Neural image caption generation with visual attention." International conference on machine learning. 2015. • Bengio, Samy, et al. "Scheduled sampling for sequence prediction with recurrent neural networks." Advances in Neural Information Processing Systems. 2015. • Wiseman, Sam, and Alexander M. Rush. "Sequence-to-sequence learning as beam-search optimization." arXiv preprint arXiv:1606.02960 (2016). • 台大 李宏毅 教授 [Machine Learning and having it deep and structured (2018,Spring)] • 台大 陳縕儂 教授 [Applied Deep Learning(2019,Spring)] 22 Reference
- 23. 23 Thanks for your listening.