Sequence Model pytorch at colab with gpu.pdf
0 likes77 views

The document provides an overview of sequence models used in machine learning, detailing types like RNNs, LSTMs, GRUs, and transformer models. It highlights their applications in processing sequential data, addressing issues like the vanishing gradient problem, and the significance of self-attention mechanisms in transformers. Additionally, it includes tutorial content and homework assignments related to implementing these models in PyTorch.





























Sequence Model pytorch at colab with gpu.pdf
- 2. About me • Education • NCU (MIS)、NCCU (CS) • Experiences • Telecom big data Innovation • Retail Media Network (RMN) • Customer Data Platform (CDP) • Know-your-customer (KYC) • Digital Transformation • Research • Data Ops (ML Ops) • Business Data Analysis, AI 2
- 3. Tutorial Content 3 Homework Sequence Models Sequence Data & Sequence Models • Vanilla RNN (Recurrent Neural Network) • LSTM (Long short term memory) • GRU (Gated recurrent unit) • Transformer Model
- 4. Pytorch tutorial • Pytorch Tutorials • Welcome to PyTorch Tutorials — PyTorch Tutorials 2.2.1+cu121 documentation 4
- 5. Sequence Data: Types • Sequence Data: • The order of elements is significant. • It can have variable lengths. In natural language, sentences can be of different lengths, and in genomics, DNA sequences can vary in length depending on the organism. 5
- 6. Sequence Data: Examples • Examples: • Image Captioning. 6
- 7. Sequence Data: Examples • Examples: • Speech Signals. 7
- 8. Sequence Data: Examples • Examples: • Time Series Data, such as time stamped transactional data. 8 Lagged features can help you capture the patterns, trends, and seasonality in your time series data, as well as the effects of external factors or events.
- 9. • Examples: • Language Translation (Natural Language Text). • Chatbot. • Text summarization. • Text categorization. • Parts of speech tagging. • Stemming. • Text mining. Sequence Data: Examples 9
- 10. 補充 • Pytorch 模型 forward 練習 10
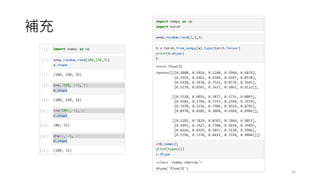
- 11. 補充 • RNNs 輸入輸出 11 RNN — PyTorch 2.2 documentation
- 12. 補充 • 激活值計算 12
- 13. Sequence Models: applications • Sequence models are a class of machine learning models designed for tasks that involve sequential data, where the order of elements in the input is important. • Model applications: 13 one to one: Fixed length input/output, a general neural network model. one to many: Image captioning. many to one: Sentiment analysis. many to many: machine translation.
- 14. Sequence Model: Recurrent Neural Networks (RNNs) • RNNs are a fundamental type of sequence model. • They process sequences one element at a time sequentially while maintaining an internal hidden state that stores information about previous elements in the sequence. • Traditional RNNs suffer from the Vanishing gradient problem, which limits their ability to capture long-range dependencies. 14
- 15. Sequence Model: Recurrent Neural Networks (RNNs) 15
- 16. • Stacked RNNs also called Deep RNNs. • The hidden state is responsible for memorizing the information from the previous timestep and using that for further adjustment of weights in Training a model. 16 Sequence Model: Recurrent Neural Networks (RNNs) If your data sequence is short then don’t use more that 2-3 layers because un-necessarily extra training time may lead to make your model un-optimized. Vanilla_RNN02.ipynb (調整參數 (num_layers),比較收斂的結果 )
- 17. Sequence Model: Long Short-Term Memory Networks (LSTM) • They are a type of RNNs designed to overcome the Vanishing gradient problem. • They introduce specialized memory cells and gating mechanisms that allow them to capture and preserve information over long sequences. • Gates (input, forget, and output) to regulate the flow of information. • They usually perform better than Hidden Markov Models (HMM). 17 (梯度消失問題仍存在,只是相較 RNNs 會好一些而已)
- 18. Sequence Model: Long Short-Term Memory Networks (LSTM) 18 Pytorch_lstm_02.ipynb
- 19. Sequence Model: Gated Recurrent Units (GRUs) • They are another variant of RNNs that are similar to LSTM but with a simplified structure. • They also use gating mechanisms to control the flow of information within the network. • Gates (rest and update) to regulate the flow of information • They are computationally more efficient than LSTM while still being able to capture dependencies in sequential data. 19 pytorch_gru_01.ipynb (權重參數的數量比較小一些,所以收斂速度上會比較快)
- 21. Sequence Model: Transformer Models • They are a more recent and highly effective architecture for sequence modeling. • They move away from recurrence and rely on a self-attention mechanism to process sequences in parallel and capture long-term dependencies in data, making them more efficient than traditional RNNs. • Self-attention mechanisms to weight the importance of different parts of input data. • They have been particularly successful in NLP tasks and have led to models like BERT, GPT, and others. 21
- 22. Sequence Model: Transformer Models • In the paper Attention is all you need (2017). • It abandons traditional CNNs and RNNs and entire network structure composed of Attention mechanisms and FNNs. 22 https://arxiv.org/abs/1706.03762 • It includes Encoder and Decoder.
- 23. • Bidirectional Encoder Representations from Transformers • 使用 Encoder 進行編碼,採用 self-attention 機制在編碼 token 同時考 慮上下文的 token,上下文的意思就是雙向的意思 (bidirectional)。 • 採用 Self-Attention多頭機制提取全面性信息。 • 是一種 pre-trained模型,可視為一種特徵提取器。 • 使用 Transformer 的 Encoder 進行特徵提取,可說 Encoder 就是 BERT 模型。 23 Sequence Model: Transformer Models (BERT)
- 24. Sequence Model: Transformer Models (Encoder) • How are you? • 你好嗎? Tokenizer <start> “How” “are” “you” “?” <end> Vocabulary How 1 are 10 you 300 ? 4 Word to index mapping d=512 Add PE (Positional Encoding) Multi-Head- Attention (HMA) In parallel Feed forward Residual N O R M Residual N O R M Block Block Block vectors
- 25. Sequence Model: Multi-head-attention • Attention mechanism: • Select more useful information from words. • Q, K and V are obtained by applying a linear transformation to the input word vector x. • Each matrix W can be learned through training. 25 Q: Information to be queried K: Vectors being queried V: Values obtained from the query (多頭的意思,想像成 CNN 中多個卷積核的作用) 1. MLP/CNN的情況不同,不同層有不同的參數,因此有各自的梯度。 2. RNN權重參數是共享,最終的計算方式是梯度總和下更新;而梯度不會消失,只是距 離遠的梯度會消失而已,所以梯度被近距離的主導,缺乏遠距離的依賴關係。 3. 難以學到遠距離的依賴關係,因此需要導入 attention 機制。
- 26. Sequence Model: Transformer Models (Decoder) 26 vectors Q,K,V B O S 你 好 嗎 你 好 嗎 ? max max max max 你 0.8 好 0 嗎 0.1 … … END 0 Size V (Common characters) ? E N D max Add PE Masked MHA Cross Attention Feed Forward 你 1 好 0 嗎 0 … … … 0 Ground truth Minimize cross entropy
- 28. Sequence Model: Transformer Models 28
- 29. Homework • 改寫 HW02.ipynb,新增 LSTM、GRU 兩種模型,比較 RMSE 變化與您使用的參數 29 RNN Types Train Score Test Score Parameters Vanilla RNN 4.25 7.3 hidden_size=32, seq_length=19, num_layers=1, num_epochs=500 LSTM GRU
- 30. 補充 30