Solr vs. Elasticsearch - Case by Case
Download as PPTX, PDF94 likes90,154 views

The document compares Solr and Elasticsearch, highlighting their similarities and differences, including aspects like full-text search capabilities, configuration methods, and plugin usage. It discusses specific technical details about their setups, indexing processes, and search functionalities, illustrating the strengths and weaknesses of both systems. Additionally, it covers topics such as nested documents, cloud deployment strategies, and explicit versus dynamic mapping in each tool.






![Index a document - Elasticsearch
1. Setup an index/collection
2. Define fields and types
3. Index content (using Marvel sense):
POST /test1/hello
{
"msg": "Happy birthday",
"names": ["Alex", "Mark"],
"when": "2014-11-01T10:09:08"
}
Alternative:
PUT /test1/hello/id1
{
"msg": "Happy birthday",
"names": ["Alex", "Mark"],
"when": "2014-11-01T10:09:08"
}
An index, type and definitions are created automatically
So, where is our document:
GET /test1/hello/_search
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 1,
"hits": [
{
"_index": "test1",
"_type": "hello",
"_id": "AUmIk4LDF4XvfpxnVJ2g",
"_score": 1,
"_source": {
"msg": "Happy birthday",
"names": [
"Alex",
"Mark"
],
"when": "2014-11-01T10:09:08"
}}
]
}}](https://image.slidesharecdn.com/lw14revolution-rafalovitch-presentation-notes-141115170557-conversion-gate02/85/Solr-vs-Elasticsearch-Case-by-Case-7-320.jpg)
![Behind the scenes
GET /test1/hello/_search
…..
{
"_index": "test1",
"_type": "hello",
"_id": "AUmIk4LDF4XvfpxnVJ2g",
"_score": 1,
"_source": {
"msg": "Happy birthday",
"names": [
"Alex",
"Mark"
],
"when": "2014-11-01T10:09:08"
}
….
GET /test1/hello/_mapping
{
"test1": {
"mappings": {
"hello": {
"properties": {
"msg": {
"type": "string"
},
"names": {
"type": "string"
},
"when": {
"type": "date",
"format": "dateOptionalTime"
}}}}}}](https://image.slidesharecdn.com/lw14revolution-rafalovitch-presentation-notes-141115170557-conversion-gate02/85/Solr-vs-Elasticsearch-Case-by-Case-8-320.jpg)
![Basic search in Elasticsearch
GET /test1/hello/_search
…..
{
"_index": "test1",
"_type": "hello",
"_id": "AUmIk4LDF4XvfpxnVJ2g",
"_score": 1,
"_source": {
"msg": "Happy birthday",
"names": [
"Alex",
"Mark"
],
"when": "2014-11-01T10:09:08"
}
….
• GET /test1/hello/_search?q=foobar – no results
• GET /test1/hello/_search?q=Alex – YES on names?
• GET /test1/hello/_search?q=alex – YES lower case
• GET /test1/hello/_search?q=happy – YES on msg?
• GET /test1/hello/_search?q=2014 – YES???
• GET /test1/hello/_search?q="birthday alex" – YES
• GET /test1/hello/_search?q="birthday mark" – NO
Issues:
1. Where are we actually searching?
2. Why are lower-case searches work?
3. What's so special about Alex?](https://image.slidesharecdn.com/lw14revolution-rafalovitch-presentation-notes-141115170557-conversion-gate02/85/Solr-vs-Elasticsearch-Case-by-Case-9-320.jpg)

![Can Solr do the same kind of magic?
• curl 'http://localhost:8983/solr/collection1/update/json/docs' -H 'Content-type:
application/json' -d @msg.json
curl 'http://localhost:8983/solr/collection1/select'
{
"responseHeader":{
"status":0,
"QTime":18,
"params":{}},
"response":{"numFound":1,"start":0,"docs":[
{
"msg":["Happy birthday"],
"names":["Alex", "Mark"],
"when":["2014-11-01T10:09:08Z"],
"_id":"e9af682d-e775-42f2-90a5-c932b5fbb691",
"_version_":1484096406012559360}]
}}
curl 'http://localhost:8983/solr/collection1/schema/fields'
{
"responseHeader":{
"status":0,
"QTime":1},
"fields":[
{"name":"_all", "type":"es_string",
"multiValued":true,
"indexed":true, "stored":false},
{"name":"_id", "type":"string",
"multiValued":false,
"indexed":true, "required":true,
"stored":true, "uniqueKey":true},
{"name":"_version_", "type":"long",
"indexed":true, "stored":true},
{"name":"msg", "type":"es_string"},
{"name":"names", "type":"es_string"},
{"name":"w • Output slightly re-formated hen", "type":"tdates"}]}](https://image.slidesharecdn.com/lw14revolution-rafalovitch-presentation-notes-141115170557-conversion-gate02/85/Solr-vs-Elasticsearch-Case-by-Case-11-320.jpg)

![Explicit mapping - Elasticsearch
• Created through PUT command
• Also can be stored in config/default-mapping.json or
config/mappings/[index_name]
• Mappings for all types in one index should be compatible to avoid problems
• Usually uses predefined mapping names. Has many names, including for
languages
• Explicit mapping is through named cross-references, rather than duplicated in-place
stack (like Solr)
• Related content is usually also in the definition. Sometimes in file (e.g.
stopwords_path – needs to be on all nodes)
• French example (next slide):](https://image.slidesharecdn.com/lw14revolution-rafalovitch-presentation-notes-141115170557-conversion-gate02/85/Solr-vs-Elasticsearch-Case-by-Case-14-320.jpg)
![Explicit mapping – Elasticsearch - French
{
"settings": {
"analysis": {
"filter": {
"french_elision": {
"type": "elision",
"articles": [ "l", "m", "t", "qu",
"n", "s", "j", "d", "c", "jusqu", "quoiqu",
"lorsqu", "puisqu"
]
},
"french_stop": {
"type": "stop",
"stopwords": "_french_"
},
"french_keywords": {
"type": "keyword_marker",
"keywords": []
},
"french_stemmer": {
"type": "stemmer",
"language": "light_french"
}
},
….
"analyzer": {
"french": {
"tokenizer": "standard",
"filter": [
"french_elision",
"lowercase",
"french_stop",
"french_keywords",
"french_stemmer"
]
}
}
}
}
}](https://image.slidesharecdn.com/lw14revolution-rafalovitch-presentation-notes-141115170557-conversion-gate02/85/Solr-vs-Elasticsearch-Case-by-Case-15-320.jpg)

![Index many documents – Elasticsearch
POST /test3/entries/_bulk
{ "index": {"_id": "1" } }
{"msg": "Hello", "names": ["Jack", "Jill"]}
{ "index": {"_id": "2" } }
{"msg": "Goodbye", "names": "Jason"}
{ "delete" : {"_id" : "3" } }
NOTE: Rivers (similar to DIH) MAY be deprecated.
Use Logstash instead (180Mb on disk, including 2 jRuby runtimes !!!)](https://image.slidesharecdn.com/lw14revolution-rafalovitch-presentation-notes-141115170557-conversion-gate02/85/Solr-vs-Elasticsearch-Case-by-Case-17-320.jpg)
![Index many documents - Solr
JSON - simple
[
{
"_id": "1",
"msg": "Hello",
"names": ["Jack", "Jill"]
},
{
"_id": "2",
"msg": "Goodbye",
"names": "Jason"
}
]
JSON – with commands
{
"add": { "doc": {
"_id": "1",
"msg": "Hello",
"names": ["Jack", "Jill"]
} },
"add": { "doc": {
"_id": "2",
"msg": "Goodbye",
"names": "Jason"
} },
"delete": { "_id":3 }
}
Also:
• CSV
• XML
• XML+XSLT
• JSON+transform (4.10)
• DataImportHandler
• Map-Reduce
External tools
• Logstash (owned by ES)](https://image.slidesharecdn.com/lw14revolution-rafalovitch-presentation-notes-141115170557-conversion-gate02/85/Solr-vs-Elasticsearch-Case-by-Case-18-320.jpg)

![Search compared – Simple searches
{
"msg": "Happy birthday",
"names": ["Alex", "Mark"],
"when": "2014-11-01T10:09:08"
}
{
"msg": "Happy New Year",
"names": ["Jack", "Jill"],
"when": "2015-01-01T00:00:01"
}
{
"msg": "Goodbye",
"names": ["Jack", "Jason"],
"when": "2015-06-01T00:00:00"
}
Elasticsearch (Marvel Sense GET):
• /test1/hello/_search – all
• /test1/hello/_search?q=happy birthday Alex– 2
• /test1/hello/_search?q=names:Alex – 1
Solr (GET http://localhost:8983/solr/…):
• /collection1/select – all
• /collection1/select?q=happy birthday Alex – 2
• /test1/hello/_search?q=names:Alex – 1](https://image.slidesharecdn.com/lw14revolution-rafalovitch-presentation-notes-141115170557-conversion-gate02/85/Solr-vs-Elasticsearch-Case-by-Case-20-320.jpg)
![Search Compared – Query DSL
Elasticsearch
GET /test1/hello/_search
{
"query": {
"query_string": {
"fields": ["msg^5", "names"],
"query": "happy birthday Alex",
"minimum_should_match": "100%"
}
}
}
Solr
…/collection1/select
?q=happy birthday Alex
&defType=dismax
&qf=msg^5 names
&mm=100%](https://image.slidesharecdn.com/lw14revolution-rafalovitch-presentation-notes-141115170557-conversion-gate02/85/Solr-vs-Elasticsearch-Case-by-Case-21-320.jpg)
![Search Compared – Query DSL - combo
Search future entries about Jack. Return only the best one.
Elasticsearch
GET /test1/hello/_search
{
"size" : 1,
"query": {
"filtered": {
"query": {
"query_string": {
"query": "jack"
}},
"filter": {
"range": {
"when": {
"gte": "now"
}}}}}}
Solr
…/collection1/select
?q=jack
&fq=when:[NOW TO *]
&rows=1](https://image.slidesharecdn.com/lw14revolution-rafalovitch-presentation-notes-141115170557-conversion-gate02/85/Solr-vs-Elasticsearch-Case-by-Case-22-320.jpg)
![Parent/Child structures
Inner objects
• Mapping: Object
• Dynamic mapping (default)
• NOT separate Lucene docs
• Map to flattened
multivalued fields
• Search matches against
value from ANY of inner
objects
{
"followers.age": [19, 26],
"followers.name":
[alex, lisa]
}
Elasticsearch
Nested objects
• Mapping: nested
• Explicit mapping
• Lucene block storage
• Inner documents are hidden
• Cannot return inner docs only
• Can do nested & inner
Parent and Child
• Mapping: _parent
• Explicit references
• Separate documents
• In-memory join
• SLOW
Solr
Nested objects
• Lucene block storage
• All documents are visible
• Child JSON is less natural](https://image.slidesharecdn.com/lw14revolution-rafalovitch-presentation-notes-141115170557-conversion-gate02/85/Solr-vs-Elasticsearch-Case-by-Case-23-320.jpg)





Solr vs. Elasticsearch - Case by Case
- 1. Solr vs. Elasticsearch Case by Case Alexandre Rafalovitch @arafalov @SolrStart www.solr-start.com
- 2. Meet the FRENEMIES Friends (common) • Based on Lucene • Full-text search • Structured search • Queries, filters, caches • Facets/stats/enumerations • Cloud-ready Elasticsearch* * Elasticsearch is a trademark of Elasticsearch BV, registered in the U.S. and in other countries. Enemies (differences) • Download size • AdminUI vs. Marvel • Configuration vs. Magic • Nested documents • Chains vs. Plugins • Types and Rivers • OpenSource vs. Commercial • Etc.
- 3. This used to be Solr (now in Lucene/ES) • Field types • Dismax/eDismax • Many of analysis filters (WordDelimiterFilter, Soundex, Regex, HTML, kstem, Trim…) • Multi-valued field cache • …. (source: http://heliosearch.org/lucene-solr-history/ ) • Disclaimer: Nowadays, Elasticsearch hires awesome Lucene hackers
- 4. Basically - sisters Source: https://www.flickr.com/photos/franzfume/11530902934/ First run Expanded Download 300 250 200 150 100 50 0 Solr Elasticsearch
- 5. Solr: Chubby or Rubenesque? 0.00 50.00 100.00 150.00 200.00 250.00 300.00 Elasticsearch+plugins Solr Code Examples Documentation ES-Admin ES-ICU Extract/Tika UIMA Map-Reduce Test Framework
- 6. Elasticsearch setup Source: https://www.flickr.com/photos/deborah-is-lola/6815624125/ • Admin UI: bin/plugin -i elasticsearch/marvel/latest • Tika/Extraction: bin/plugin -install elasticsearch/elasticsearch-mapper-attachments/ 2.4.1 • ICU (Unicode components): bin/plugin -install elasticsearch/elasticsearch-analysis-icu/ 2.4.1 • JDBC River (like DataImportHandler subset): bin/plugin --install jdbc --url http://xbib.org/repository/org/xbib/elasticsearch/plugin/e lasticsearch-river-jdbc/1.3.4.4/elasticsearch-river-jdbc- 1.3.4.4-plugin.zip • JavaScript scripting support: bin/plugin -install elasticsearch/elasticsearch-lang-javascript/ 2.4.1 • On each node…. • Without dependency management (jars = rabbits)
- 7. Index a document - Elasticsearch 1. Setup an index/collection 2. Define fields and types 3. Index content (using Marvel sense): POST /test1/hello { "msg": "Happy birthday", "names": ["Alex", "Mark"], "when": "2014-11-01T10:09:08" } Alternative: PUT /test1/hello/id1 { "msg": "Happy birthday", "names": ["Alex", "Mark"], "when": "2014-11-01T10:09:08" } An index, type and definitions are created automatically So, where is our document: GET /test1/hello/_search { "took": 1, "timed_out": false, "_shards": { "total": 5, "successful": 5, "failed": 0 }, "hits": { "total": 1, "max_score": 1, "hits": [ { "_index": "test1", "_type": "hello", "_id": "AUmIk4LDF4XvfpxnVJ2g", "_score": 1, "_source": { "msg": "Happy birthday", "names": [ "Alex", "Mark" ], "when": "2014-11-01T10:09:08" }} ] }}
- 8. Behind the scenes GET /test1/hello/_search ….. { "_index": "test1", "_type": "hello", "_id": "AUmIk4LDF4XvfpxnVJ2g", "_score": 1, "_source": { "msg": "Happy birthday", "names": [ "Alex", "Mark" ], "when": "2014-11-01T10:09:08" } …. GET /test1/hello/_mapping { "test1": { "mappings": { "hello": { "properties": { "msg": { "type": "string" }, "names": { "type": "string" }, "when": { "type": "date", "format": "dateOptionalTime" }}}}}}
- 9. Basic search in Elasticsearch GET /test1/hello/_search ….. { "_index": "test1", "_type": "hello", "_id": "AUmIk4LDF4XvfpxnVJ2g", "_score": 1, "_source": { "msg": "Happy birthday", "names": [ "Alex", "Mark" ], "when": "2014-11-01T10:09:08" } …. • GET /test1/hello/_search?q=foobar – no results • GET /test1/hello/_search?q=Alex – YES on names? • GET /test1/hello/_search?q=alex – YES lower case • GET /test1/hello/_search?q=happy – YES on msg? • GET /test1/hello/_search?q=2014 – YES??? • GET /test1/hello/_search?q="birthday alex" – YES • GET /test1/hello/_search?q="birthday mark" – NO Issues: 1. Where are we actually searching? 2. Why are lower-case searches work? 3. What's so special about Alex?
- 10. All about _all and why strings are tricky • By default, we search in the field _all • What's an _all field in Solr terms? <field name="_all" type="es_string" multiValued="true" indexed="true" stored="false"/> <copyField source="*" dest="_all"/> • And the default mapping for Elasticsearch "string" type is like: <fieldType name="es_string" class="solr.TextField" multiValued="true" positionIncrementGap="0" > <analyzer> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType> • Elasticsearch equivalent to Solr's solr.StrField is: {"type" : "string", "index" : "not_analyzed"}
- 11. Can Solr do the same kind of magic? • curl 'http://localhost:8983/solr/collection1/update/json/docs' -H 'Content-type: application/json' -d @msg.json curl 'http://localhost:8983/solr/collection1/select' { "responseHeader":{ "status":0, "QTime":18, "params":{}}, "response":{"numFound":1,"start":0,"docs":[ { "msg":["Happy birthday"], "names":["Alex", "Mark"], "when":["2014-11-01T10:09:08Z"], "_id":"e9af682d-e775-42f2-90a5-c932b5fbb691", "_version_":1484096406012559360}] }} curl 'http://localhost:8983/solr/collection1/schema/fields' { "responseHeader":{ "status":0, "QTime":1}, "fields":[ {"name":"_all", "type":"es_string", "multiValued":true, "indexed":true, "stored":false}, {"name":"_id", "type":"string", "multiValued":false, "indexed":true, "required":true, "stored":true, "uniqueKey":true}, {"name":"_version_", "type":"long", "indexed":true, "stored":true}, {"name":"msg", "type":"es_string"}, {"name":"names", "type":"es_string"}, {"name":"w • Output slightly re-formated hen", "type":"tdates"}]}
- 12. Nearly the same magic <updateRequestProcessorChain name="add-unknown-fields-to-the-schema"> <!-- UUIDUpdateProcessorFactory will generate an id if none is present in the incoming document --> <processor class="solr.UUIDUpdateProcessorFactory" /> <processor class="solr.LogUpdateProcessorFactory"/> <processor class="solr.DistributedUpdateProcessorFactory"/> <processor class="solr.RemoveBlankFieldUpdateProcessorFactory"/> <processor class="solr.ParseBooleanFieldUpdateProcessorFactory"/> <processor class="solr.ParseLongFieldUpdateProcessorFactory"/> <processor class="solr.ParseDoubleFieldUpdateProcessorFactory"/> <processor class="solr.ParseDateFieldUpdateProcessorFactory"> <arr name="format"> <str>yyyy-MM-dd'T'HH:mm:ss</str> <str>yyyyMMdd'T'HH:mm:ss</str> </arr> </processor> <processor class="solr.AddSchemaFieldsUpdateProcessorFactory"> <str name="defaultFieldType">es_string</str> <lst name="typeMapping"> <str name="valueClass">java.lang.Boolean</str> <str name="fieldType">booleans</str> </lst> <lst name="typeMapping"> <str name="valueClass">java.util.Date</str> <str name="fieldType">tdates</str> </lst> <processor class="solr.RunUpdateProcessorFactory"/> </updateRequestProcessorChain> Not quite the same magic: • URP chain happens before copyField • Date/Ints are converted first • copyText converts content back to string • _all field also gets copy of _id and _version • All auto-mapped fields HAVE to be multivalued • No (ES-Style) types, just collections • Unable to reproduce cross-field search • Still rough around the edges • Requires dynamic schema, so adding new types becomes a challenge • Auto-mapping is NOT recommended for production • Dynamic fields solution is still more mature
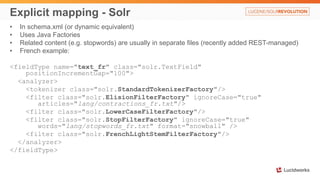
- 13. Explicit mapping - Solr • In schema.xml (or dynamic equivalent) • Uses Java Factories • Related content (e.g. stopwords) are usually in separate files (recently added REST-managed) • French example: <fieldType name="text_fr" class="solr.TextField" positionIncrementGap="100"> <analyzer> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.ElisionFilterFactory" ignoreCase="true" articles="lang/contractions_fr.txt"/> <filter class="solr.LowerCaseFilterFactory"/> <filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_fr.txt" format="snowball" /> <filter class="solr.FrenchLightStemFilterFactory"/> </analyzer> </fieldType>
- 14. Explicit mapping - Elasticsearch • Created through PUT command • Also can be stored in config/default-mapping.json or config/mappings/[index_name] • Mappings for all types in one index should be compatible to avoid problems • Usually uses predefined mapping names. Has many names, including for languages • Explicit mapping is through named cross-references, rather than duplicated in-place stack (like Solr) • Related content is usually also in the definition. Sometimes in file (e.g. stopwords_path – needs to be on all nodes) • French example (next slide):
- 15. Explicit mapping – Elasticsearch - French { "settings": { "analysis": { "filter": { "french_elision": { "type": "elision", "articles": [ "l", "m", "t", "qu", "n", "s", "j", "d", "c", "jusqu", "quoiqu", "lorsqu", "puisqu" ] }, "french_stop": { "type": "stop", "stopwords": "_french_" }, "french_keywords": { "type": "keyword_marker", "keywords": [] }, "french_stemmer": { "type": "stemmer", "language": "light_french" } }, …. "analyzer": { "french": { "tokenizer": "standard", "filter": [ "french_elision", "lowercase", "french_stop", "french_keywords", "french_stemmer" ] } } } } }
- 16. Default analyzer - Elasticsearch Indexing 1. the analyzer defined in the field mapping, else 2. the analyzer defined in the _analyzer field of the document, else 3. the default analyzer for the type, which defaults to 4. the analyzer named default in the index settings, which defaults to 5. the analyzer named default at node level, which defaults to 6. the standard analyzer Query 1. the analyzer defined in the query itself, else 2. the analyzer defined in the field mapping, else 3. the default analyzer for the type, which defaults to 4. the analyzer named default in the index settings, which defaults to 5. the analyzer named default at node level, which defaults to 6. the standard analyzer
- 17. Index many documents – Elasticsearch POST /test3/entries/_bulk { "index": {"_id": "1" } } {"msg": "Hello", "names": ["Jack", "Jill"]} { "index": {"_id": "2" } } {"msg": "Goodbye", "names": "Jason"} { "delete" : {"_id" : "3" } } NOTE: Rivers (similar to DIH) MAY be deprecated. Use Logstash instead (180Mb on disk, including 2 jRuby runtimes !!!)
- 18. Index many documents - Solr JSON - simple [ { "_id": "1", "msg": "Hello", "names": ["Jack", "Jill"] }, { "_id": "2", "msg": "Goodbye", "names": "Jason" } ] JSON – with commands { "add": { "doc": { "_id": "1", "msg": "Hello", "names": ["Jack", "Jill"] } }, "add": { "doc": { "_id": "2", "msg": "Goodbye", "names": "Jason" } }, "delete": { "_id":3 } } Also: • CSV • XML • XML+XSLT • JSON+transform (4.10) • DataImportHandler • Map-Reduce External tools • Logstash (owned by ES)
- 19. Comparing search - Search • Same but different • Same: vast majority of the features come from Lucene • Different: representation of search parameters • Solr: URL query with many – cryptic – parameters • Elasticsearch: • Search lite: URL query with a limited set of parameters (basic Lucene query) • Query DSL: JSON with multi-leveled structure Lucene Impl ES only Solr only
- 20. Search compared – Simple searches { "msg": "Happy birthday", "names": ["Alex", "Mark"], "when": "2014-11-01T10:09:08" } { "msg": "Happy New Year", "names": ["Jack", "Jill"], "when": "2015-01-01T00:00:01" } { "msg": "Goodbye", "names": ["Jack", "Jason"], "when": "2015-06-01T00:00:00" } Elasticsearch (Marvel Sense GET): • /test1/hello/_search – all • /test1/hello/_search?q=happy birthday Alex– 2 • /test1/hello/_search?q=names:Alex – 1 Solr (GET http://localhost:8983/solr/…): • /collection1/select – all • /collection1/select?q=happy birthday Alex – 2 • /test1/hello/_search?q=names:Alex – 1
- 21. Search Compared – Query DSL Elasticsearch GET /test1/hello/_search { "query": { "query_string": { "fields": ["msg^5", "names"], "query": "happy birthday Alex", "minimum_should_match": "100%" } } } Solr …/collection1/select ?q=happy birthday Alex &defType=dismax &qf=msg^5 names &mm=100%
- 22. Search Compared – Query DSL - combo Search future entries about Jack. Return only the best one. Elasticsearch GET /test1/hello/_search { "size" : 1, "query": { "filtered": { "query": { "query_string": { "query": "jack" }}, "filter": { "range": { "when": { "gte": "now" }}}}}} Solr …/collection1/select ?q=jack &fq=when:[NOW TO *] &rows=1
- 23. Parent/Child structures Inner objects • Mapping: Object • Dynamic mapping (default) • NOT separate Lucene docs • Map to flattened multivalued fields • Search matches against value from ANY of inner objects { "followers.age": [19, 26], "followers.name": [alex, lisa] } Elasticsearch Nested objects • Mapping: nested • Explicit mapping • Lucene block storage • Inner documents are hidden • Cannot return inner docs only • Can do nested & inner Parent and Child • Mapping: _parent • Explicit references • Separate documents • In-memory join • SLOW Solr Nested objects • Lucene block storage • All documents are visible • Child JSON is less natural
- 24. Cloud deployment – quick take 1. General concepts are similar: • Node discovery • Sharding • Replication • Routing 1. Implementations are very, very different (layer above Lucene) 2. Solr uses Apache Zookeeper 3. Elasticsearch has its own algorithms 4. No time to discuss 5. Let's focus on the critical path: Node discovery/cloud-state management 6. Use a 3rd party analysis: Kyle Kingsbury's Jepsen tests
- 25. Jepsen test of Zookeper Use Zookeeper. It’s mature, well-designed, and battle-tested.
- 26. Jepsen test of Elasticsearch If you are an Elasticsearch user (as I am): good luck.
- 27. Innovator’s dilemma • Solr's usual attitude • An amazingly useful product for many different uses • And wants everybody to know it • …Right in the collection1 example • “You will need all this eventually, might as well learn it first” • Elasticsearch is small and shiny (“trust us, the magic exists”) • Elasticsearch + Logstash + Kibana => power-punch triple combo • Especially when comparing to Solr (and not another commercial solution) • Feature release process • Elasticsearch: kimchy: “LGTM” (Looks good to me) • Solr: full Apache process around it • Solr – needs to buckle down and focus on onboarding experience • Solr is getting better (e.g. listen to SolrCluster podcast of October 24, 2014)
- 28. Solr vs. Elasticsearch Case by Case Alexandre Rafalovitch www.solr-start.com @arafalov @SolrStart
Editor's Notes
- #3: Ladies and Gentlemen, Mademes et Messier, Dami I gospoda, Remote viewers. My name is Alexandre Rafalovitch. I work for the United Nations, but I am not representing it here or at the conference. I am here instead as a SolrStart popularizer. In this session we will compare Solr and ElasticSearch a little deeper than usual. But even then, to give you a real sense would take a two hour workshop. All I got is 30 minutes. So, we are going to go FAST.
- #4: T: So, what's the best way to compare Solr and Elasticsearch. Think of it as Frenemies. Lots of stuff in common since both are based on Lucene, especially the deep features around the actual search But lots of things are different, some due to Elasticsearch's ease-of-use approach and some due to it's commercial nature. Speaking of commercial nature, I have to tell you that Elasticsearch is a trademark….. T: Before we start digging in, it is important to remember a bit of history….
- #5: …. A number of Lucene features used by Elasticsearch have actually came from Solr originally. Now, of course, Elasticsearch are contributing back to Lucene too. But with that history in mind, what kind of Frenemies I think these two search engines represent?
- #6: I think they are sisters. Solr is an older – ahm, more visible – sister, while Elasticsearch is a younger, slimmer one. This size comparison is one of the sticky points about Solr distribution. And it really is an issue. Elasticsearch downloads as 27Mb archive and expands to about 35Mb. Solr downloads – eventually – as a 150Mb archive and expands by two Elasticsearch'es on disk. And then by another Elasticsearch after the first run, when the web archive expands T: So is that a healthy bulk or ???? Downloaded: Solr: 150Mb, Elasticsearch: 27Mb Expanded: Solr: 225Mb, Elasticsearch: 34Mb On first run: Solr 258Mb, Elasticsearch: 34Mb (no change)
- #7: … Is Solr Chubby or just Rubenesque with all the great features? Let's have a look We can see that Solr (at the bottom) of course has core search and libraries, but also examples, documentations, various contributions and such as Tika Rich Content extraction support, UIMA, Map-Reduce and even test framework. It also has an extensive administration UI built in, as well as things like DataImportHandler. Elasticsearch does not come with any of these. It has plugins instead. So, if you start adding that functionality as plugins, it will also grow in side, though still far cry from Solr's bulk. T: Given that Elastisearch does require plugins to effectively function…. Solr: Still Chubby – but not all fat is excess Still, some exercise could really be beneficial. And if Elasticsearch does deprecate it's rivers and replaces with logstash – that's another whopping 85 Mbytes, nearly 3 times Elasticsearch install itself.
- #8: … I think it is fair to say that real Elasticsearch installation "comes with baggage". And, even though Elasticsearch has plugin mechanism, actually using it shows that it is NOT as comprehensive as Ruby's or Node's package management. And, of course, without good dependency management, we get jars breeding like rabbits. To be balanced, Solr ALSO supports plugins/loaders but – at the moment - it does not even have a way to find any of those custom components in the wild. T: Ok. Enough high level view, let's dig into the action. Let's INDEX something.
- #9: In Elasticsearch, there are two ways to index a single document. Both use HTTP verbs: POST will auto generate IDs, PUT expects you to provide them. Neither require you setting up a collection (index in ES terms) or a type (ES-only concept). Same with types and field mappings. Elasticsearch will automagically create whatever is needed behind the scenes. Of course, magic has it's price and you get what you get and you don't complain. If you do want to complain or setup your own mappings, Elasticsearch does let you do it. Solr, of course, is the other way around. T: So, let's see what we actually did get…
- #10: _source – that stores original JSON content. Not searchable. If you want to not store something, you have to explicitly exclude it. Elasticsearch does also support stored fields, so you do have to think of your data on 3 levels of source, stored and indexed, as compared to Solr's 2 levels _id field – actually it is a composite ID, as all different types are are the same index/collection Both msg and names are of type string. ElasticSearch automatically has all fields multivalued, which will automatically return either value or an array. Which may cause problems to the clients that expect specific form Notice magic date parsing T: So, given all that magic mapping, what happens with search?....
- #12: copyField means we get all the fields as text regardless of magic mapping StandardTokenizer means the date formats break on colons positionIncrementGap=0 means the search phrase will match across the boundaries of the text. Not something we recommend, actually. T: So, can Solr do a similar kind of magic?...
- #13: … Sort of: I can configure Solr to do similar autodetect. (pause) … But
- #14: But it takes a lot of deliberate planning. And the dynamic schema implementation is still rough around the edges. However, Auto-mapping is NOT recommended for production – either for Solr or Elasticsearch. Because "Magic has it's price" and the price for incorrectly mapped definition is actually quite high – you have to reindex everything. So, for production, dynamic fields are still a better choice. T: Ok, so let's look at the non-magical parts of defining a custom type…
- #15: You all know how it is done in Solr. A type definition is a self-contained XML section in schema.xml file. It defines the full stack and refers to the class names and file names of relevant factories in resources. So, here, we have a text_fr (french) type that uses Standard tokenizer and a bunch of filters with relevant word lists. T: In Elasticsearch it is quite a bit different…
- #16: All the examples show how to create mapping using REST interface, though – if you search documentation hard enough – it can also be defined in several places on disk. The mappings are defined per type, though all types within an index better have compatible definitions. That's because "Types" within an index are an elasticsearch transparent aliasing on top of Lucene's hard reality of collection/index implementation. So, there are consequences. Regarding the mapping itself, one thing Elasticsearch did is pre-define a lot – A LOT – of the standard analyzer stacks. So, if you trust Elasticsearch's choices, you don't even need to understand how they are setup and they are never visible. You just map "french" as a type without any extra configuration. T: But if you do need it defined explicitly…
- #17: … It is – of course – in JSON format and uses sort-of cross-reference style where you declare inner components first (on the left here) and then proceed to define the specific stack. This is useful if you leverage existing component-definitions or just reuse them in multiple analyzers. But because Elasticsearch uses files as exception rather than a rule, most of the time, the additional resources, such as elision keywords above may need to be specified inline. Then you can use these types by names either explicitly or by defining it as a default analyzer. T: Trying to give a lot of flexibility, Elasticsearch actually allows to define that analyzer in a lot of places
- #18: … I will let you decide for yourself whether having that much choice is a good thing or a bad thing. I, personally, suspect that this might be great during development but a real pain in the tuches to troubleshoot when it's gone wrong T: Ok, enough with small measures, let's look at indexing content in bulk…
- #19: In Elasticsearch, there is not that much choice on indexing in bulk. Different end point A completely different JSON-line indexing format Careful of new lines (fairly unforgiving) You also have Rivers, but …. T: On the other hand, Solr….
- #20: T: Ok, now that we know how to index a bunch of documents, let's dig a bit deeper into the search
- #22: Three records: 2 – share the word happy in msg 2 – overlapping but not same – share name 'Jack' in Names 1 record is in the past, two are in the future as of today So, basic searches using URL are virtually identical between Elasticsearch and Solr. Just a note, in real URLs, the parameters would be URL-Escaped : spaces, percent symbols Of course, these results are with Solr configuration trying to match Elasticsearch magic, so by default we are searching against an _all field that aggregates all content That's why we get two records for "happy birthday Alex", because it is looking for any term to match. T: So, let's try to change the search to look in the specific fields and require all terms to match
- #23: … Notice how we already run out of steam for Elasticsearch's URL query approach and have to switch to the Query DSL Also notice that in Solr, we have to declare explicitly to now use Dismax. ES does some sort of magic switch when it see you specifying specific "fields" T: Now, we don't have time to slowly build on this, so we jump ahead a couple of levels to a more complex example….
- #24: LISP = Lots of Infuriating & Silly Parentheses Elasticsearch: kind of the same about JSON braces
- #25: ES: Good and bad – 3 different syntaxes or use all of these Solr is kind of in between Nested objects and Parent and Child. They are indexed as a block, but you can get child documents separately from parent ones. T: Finally, let's very briefly touch on the cloud and scaling issues
- #29: Kimchy = Shay Banon, Elasticsearch creator Solr: +1, +1, +1, Let’s fight a bit, +1, +1, Release (lots of cooks => good & bad)
- #30: Conclusion: Frankly, I do not have one. It would take another couple of hours to get to the point of informed choice. For myself, I am return back to Solr only and am about to start writing a Solr book for O'Reilly But if you really need some of the Elasticsearch-only features and do not mind the price you have to pay for it's magic, this is also a viable choice Now, we are out of time for questions, but I will be monitoring the conference application, so you can ask them there. Thank you very much.