

























Vitalii Bashun "First Spark application in one hour"
- 1. Your First Spark Application In One Hour Hadoop introduction MR vs Spark Spark application from scratch
- 2. Vitaliy Bashun Data Architect SoftServe, London, UK Background: Java, Databases, Micro-Services, Big Data
- 3. Which level are you at? I have heard a bit about Big Data. Want more. I know some Big Data principles. Need some practice. I tried some tools. Want to try Spark. I’m not bad in Big Data. Want to work with Spark. I know Spark a bit. Want to hear more. I’m an active Spark user. Came to show how cool I am. My PM (Tech Lead, etc.) sent me here. Leve me in my quiet corner.
- 5. Agenda Big Data. What and Why Big Data tool groups Why Spark became an industry standard Spark concepts RDD, Data Frame, Data Set The First Spark Application Spark Shell
- 6. Big Data. What and Why?
- 7. Long, long way to Hadoop
- 8. Long, long way to Hadoop Vertical scale
- 9. Long, long way to Hadoop Horizontal scale
- 10. Long, long way to Hadoop
- 11. Long, long way to Hadoop
- 12. Long, long way to Hadoop
- 13. Long, long way to Hadoop
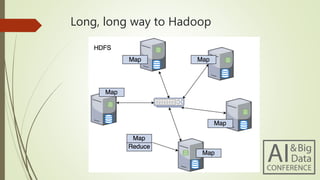
- 14. Long, long way to Hadoop HDFS
- 15. Long, long way to Hadoop HDFS
- 16. Long, long way to Hadoop
- 17. Long, long way to Hadoop
- 18. Long, long way to Hadoop
- 19. Long, long way to Hadoop
- 20. Why Spark became an industry standard All intermediate data is in memory. Faster processing More convenient programming abstraction (over MR) MLib Spark SQL Streaming support
- 23. Big Data Tool Groups
- 24. 2 concepts you need to know about to create a Spark application Spark Session RDD, DataFrame, Dataset
- 25. Spark Session (alternatively SparkContext ) The entry point to programming Spark with the Dataset and DataFrame API. In older Spark versions only SparkConfig and SparkContext can be used instead
- 26. RDD RDD – Resilient Distributed Dataset. Distributed collection. low level type Immutable. Transformations create other RDDs (no real action occur) Actions initiate ”real work”
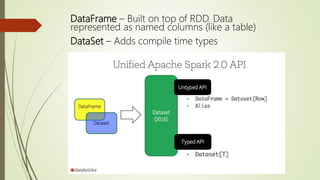
- 27. DataFrame – Built on top of RDD. Data represented as named columns (like a table) DataSet – Adds compile time types
- 28. Let’s make hands dirty Demo time