Spark SQL In Depth www.syedacademy.com
2 likes239 views

Spark SQL allows users to perform relational operations on Spark's RDDs using a DataFrame API. It addresses challenges in existing systems like limited optimization and data sources by providing a DataFrame API that can query both external data and RDDs. Spark SQL leverages a highly extensible optimizer called Catalyst to optimize logical query plans into efficient physical query plans using features of Scala. It has been part of the Spark core distribution since version 1.0 in 2014.





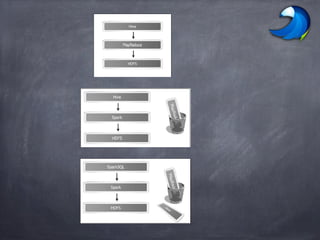



















![Write Less Code: Compute an Average
Using RDDs
data = sc.textFile(...).split("t")
data.map(lambda x: (x[0], [int(x[1]), 1]))
.reduceByKey(lambda x, y: [x[0] + y[0], x[1] + y[1]])
.map(lambda x: [x[0], x[1][0] / x[1][1]])
.collect()
Using DataFrames
sqlCtx.table("people")
.groupBy("name")
.agg("name", avg("age"))
.collect()
Using SQL
SELECT name, avg(age)
FROM people
GROUP BY name
Using Pig
P = load '/people' as (name, name);
G = group P by name;
R = foreach G generate … AVG G.age ;](https://image.slidesharecdn.com/sparksqlsyedacademyv1-170801134417/85/Spark-SQL-In-Depth-www-syedacademy-com-28-320.jpg)






Spark SQL In Depth www.syedacademy.com
- 1. Apache Spark Syed Solutions Engineer - Big Data [email protected] [email protected] +91-9030477368
- 2. Spark SQL: Relational Data Processing in Spark Challenges and Solutions Challenges Solutions • Perform ETL to and from various (semi- or unstructured) data sources • Perform advanced analytics (e.g. machine learning, graph processing) that are hard to express in relational systems. • A DataFrame API that can perform relational operations on both external data sources and Spark’s built-in RDDs. • A highly extensible optimizer, Catalyst, that uses features of Scala to add composable rule, control code gen., and define extensions.
- 3. 3 Spark SQL • Part of the core distribution since Spark 1.0 (April 2014) About SQL 0 50 100 150 200 250 # Of Commits Per Month 0 50 100 150 200 # of Contributors
- 4. Spark SQL Part of the core distribution since Spark 1.0 (April 2014) Runs SQL / HiveQL queries, optionally alongside or replacing existing Hive deployments About
- 5. Improvement upon Existing Art Engine does not understand the structure of the data in RDDs or the semantics of user functions limited optimization. Can only be used to query external data in Hive catalog limited data sources Can only be invoked via SQL string from Spark error prone Hive optimizer tailored for MapReduce difficult to extend
- 9. DataFrame • A distributed collection of rows with the same schema (RDDs suffer from type erasure) • Can be constructed from external data sources or RDDs into essentially an RDD of Row objects (SchemaRDDs as of Spark < 1.3) • Supports relational operators (e.g. where, groupby) as well as Spark operations. • Evaluated lazily unmaterialized logical plan
- 10. Data Model • Nested data model • Supports both primitive SQL types (boolean, integer, double, decimal, string, data, timestamp) and complex types (structs, arrays, maps, and unions); also user defined types. • First class support for complex data types
- 11. DataFrame Operations • Relational operations (select, where, join, groupBy) via a DSL • Operators take expression objects • Operators build up an abstract syntax tree (AST), which is then optimized by Catalyst. • Alternatively, register as temp SQL table and perform traditional SQL query strings
- 12. Advantages over Relational Query Languages • Holistic optimization across functions composed in different languages. • Control structures (e.g. if, for) • Logical plan analyzed eagerly identify code errors associated with data schema issues on the fly.
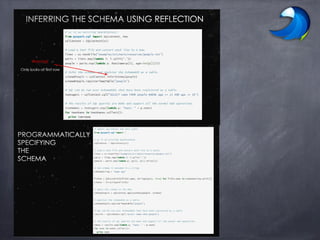
- 13. Querying Native Datasets • Infer column names and types directly from data objects (via reflection in Java and Scala and data sampling in Python, which is dynamically typed) • Native objects accessed in-place to avoid expensive data format transformation. • Benefits: • Run relational operations on existing Spark programs. • Combine RDDs with external structured data Columnar storage with hot columns cached in memory
- 14. 1 2 3 4
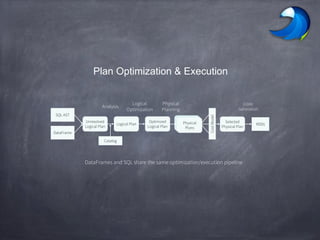
- 15. Plan Optimization & Execution SQL AST DataFrame Unresolved Logical Plan Logical Plan Optimized Logical Plan RDDs Selected Physical Plan Analysis Logical Optimization Physical Planning CostModel Physical Plans Code Generation Catalog DataFrames and SQL share the same optimization/execution pipeline
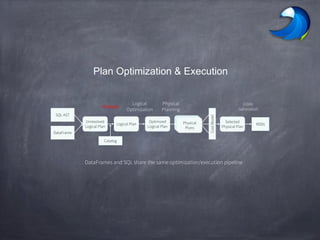
- 16. Plan Optimization & Execution SQL AST DataFrame Unresolved Logical Plan Logical Plan Optimized Logical Plan RDDs Selected Physical Plan Analysis Logical Optimization Physical Planning CostModel Physical Plans Code Generation Catalog DataFrames and SQL share the same optimization/execution pipeline
- 17. • An attribute is unresolved if its type is not known or it’s not matched to an input table. • To resolve attributes: • Look up relations by name from the catalog. • Map named attributes to the input provided given operator’s children. • UID for references to the same value • Propagate and coerce types through expressions (e.g. 1 + col) Unresolved Logical Plan Logical Plan Analysis Catalog SELECT col FROM sales
- 18. Plan Optimization & Execution SQL AST DataFrame Unresolved Logical Plan Logical Plan Optimized Logical Plan RDDs Selected Physical Plan Analysis Logical Optimization Physical Planning CostModel Physical Plans Code Generation Catalog DataFrames and SQL share the same optimization/execution pipeline
- 19. Plan Optimization & Execution SQL AST DataFrame Unresolved Logical Plan Logical Plan Optimized Logical Plan RDDs Selected Physical Plan Analysis Logical Optimization Physical Planning CostModel Physical Plans Code Generation Catalog DataFrames and SQL share the same optimization/execution pipeline
- 20. • Applies standard rule-based optimization (constant folding, predicate-pushdown, projection pruning, null propagation, boolean expression simplification, etc) • 800LOC Logical Plan Optimized Logical Plan Logical Optimization
- 21. Plan Optimization & Execution SQL AST DataFrame Unresolved Logical Plan Logical Plan Optimized Logical Plan RDDs Selected Physical Plan Analysis Logical Optimization Physical Planning CostModel Physical Plans Code Generation Catalog DataFrames and SQL share the same optimization/execution pipeline
- 22. Plan Optimization & Execution SQL AST DataFrame Unresolved Logical Plan Logical Plan RDDs Selected Physical Plan Analysis Logical Optimization CostModel Code Generation Catalog DataFrames and SQL share the same optimization/execution pipeline Optimized Logical Plan Physical Planning Physical Plans e.g. Pipeline projections and filters into a single map
- 23. Physical Plan with Predicate Pushdown and Column Pruning join optimized scan (events) optimized scan (users) Logical Plan filter join events file users table Physical Plan join scan (events) filter scan (users)
- 24. An Example Catalyst Transformation 1. Find filters on top of projections. 2. Check that the filter can be evaluated without the result of the project. 3. If so, switch the operators. Project name Project id,name Filter id = 1 People Original Plan Project name Project id,name Filter id = 1 People Filter Push-Down
- 25. Plan Optimization & Execution SQL AST DataFrame Unresolved Logical Plan Logical Plan Optimized Logical Plan RDDs Selected Physical Plan Analysis Logical Optimization Physical Planning CostModel Physical Plans Code Generation Catalog DataFrames and SQL share the same optimization/execution pipeline
- 26. Code Generation • Relies on Scala’s quasiquotes to simplify code gen. • Catalyst transforms a SQL tree into an abstract syntax tree (AST) for Scala code to eval expr and generate code
- 27. : Declarative BigData Processing Let Developers Create and Run Spark Programs Faster: • Write less code • Read less data • Let the optimizer do the hard work SQL
- 28. Write Less Code: Compute an Average Using RDDs data = sc.textFile(...).split("t") data.map(lambda x: (x[0], [int(x[1]), 1])) .reduceByKey(lambda x, y: [x[0] + y[0], x[1] + y[1]]) .map(lambda x: [x[0], x[1][0] / x[1][1]]) .collect() Using DataFrames sqlCtx.table("people") .groupBy("name") .agg("name", avg("age")) .collect() Using SQL SELECT name, avg(age) FROM people GROUP BY name Using Pig P = load '/people' as (name, name); G = group P by name; R = foreach G generate … AVG G.age ;
- 30. Extensible Input & Output Spark’s Data Source API allows optimizations like column pruning and filter pushdown into custom data sources. 30 { JSON } Built-In External JDBC and more…
- 34. A Dataset is a strongly typed collection of domain-specific objects that can be transformed in parallel using functional or relational operations. Each Dataset also has an untyped view called a DataFrame, which is a Dataset of Row. Operations available on Datasets are divided into transformations and actions. Transformations are the ones that produce new Datasets, and actions are the ones that trigger computation and return results. Example transformations include map, filter, select, and aggregate (groupBy). Example actions count, show, or writing data out to file systems. Datasets are "lazy", i.e. computations are only triggered when an action is invoked. Internally, a Dataset represents a logical plan that describes the computation required to produce the data. When an action is invoked, Spark's query optimizer optimizes the logical plan and generates a physical plan for efficient execution in a parallel and distributed manner. To explore the logical plan as well as optimized physical plan, use the explain function. To efficiently support domain-specific objects, an Encoder is required. The encoder maps the domain specific type T to Spark's internal type system. For example, given a class Person with two fields, name (string) and age (int), an encoder is used to tell Spark to generate code at runtime to serialize the Person object into a binary structure. This binary structure often has much lower memory footprint as well as are optimized for efficiency in data processing (e.g. in a columnar format). To understand the internal binary representation for data, use the schema function. DataSet