Spark SQL Tutorial | Spark Tutorial for Beginners | Apache Spark Training | Edureka
12 likes2,562 views

The document provides an extensive overview of Spark SQL, including its advantages over Apache Hive, features, architecture, and libraries. It discusses how Spark SQL improves performance through real-time querying and integration with various data formats, while offering practical use cases like Twitter sentiment analysis and stock market data analysis. Additionally, it outlines the steps for initializing a Spark shell, creating datasets, and executing SQL operations within Spark.






























![www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING
Creating Dataset – Reading File
//Setting the path to our JSON file ’employee.json’.
val path = "examples/src/main/resources/employee.json"
//Creating a Dataset and from the file.
val employeeDS = spark.read.json(path).as[Employee]
//Displaying the contents of ’employeeDS’ Dataset.
employeeDS.show()](https://image.slidesharecdn.com/sparksql-sparktutorial-edureka-170424094429/85/Spark-SQL-Tutorial-Spark-Tutorial-for-Beginners-Apache-Spark-Training-Edureka-33-320.jpg)




).show()
//Using the mapEncoder from Implicits class to map the names to the ages.
implicit val mapEncoder =
org.apache.spark.sql.Encoders.kryo[Map[String, Any]]
//Mapping the names to the ages of our ‘youngstersDF’ DataFrame. The result is an array with names
mapped to their respective ages.
youngstersDF.map(youngster =>
youngster.getValuesMap[Any](List("name", "age"))).collect()](https://image.slidesharecdn.com/sparksql-sparktutorial-edureka-170424094429/85/Spark-SQL-Tutorial-Spark-Tutorial-for-Beginners-Apache-Spark-Training-Edureka-38-320.jpg)













































Spark SQL Tutorial | Spark Tutorial for Beginners | Apache Spark Training | Edureka
- 1. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING 5 Best Practices in DevOps Culture
- 2. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING What to expect? Why Spark SQL 1 Use Case 5 Hands-On Examples 4 Spark SQL Features 3 Spark SQL Libraries 2
- 3. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Why Spark SQL?
- 4. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Why Do We Need Spark SQL? Spark SQL was built to overcome the limitations of Apache Hive running on top of Spark. Limitations of Apache Hive Hive uses MapReduce which lags in performance with medium and small sized datasets ( <200 GB) No resume capability Hive cannot drop encrypted databases
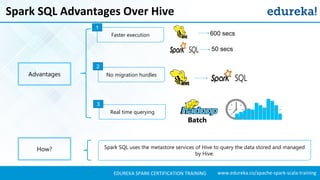
- 5. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark SQL Advantages Over Hive Spark SQL uses the metastore services of Hive to query the data stored and managed by Hive. Advantages How? Faster execution 600 secs 50 secs 1 No migration hurdles 2 Real time querying 3 Batch
- 6. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark SQL Success Story
- 7. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark SQL Success Story Twitter Sentiment Analysis With Spark SQL Trending Topics can be used to create campaigns and attract larger audience Sentiment helps in crisis management, service adjusting and target marketing NYSE: Real Time Analysis of Stock Market Data Banking: Credit Card Fraud Detection Genomic Sequencing
- 8. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark SQL Features SQL Integration With Spark Uniform Data Access Seamless Support Transformations Performance Standard Connectivity User Defined Functions
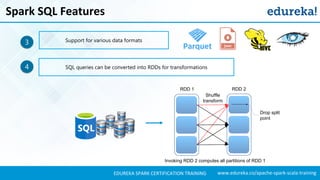
- 9. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark SQL Features Spark SQL is used for the structured/semi structured data analysis in Spark. Spark SQL integrates relational processing with Spark’s functional programming.1 2
- 10. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark SQL Features SQL queries can be converted into RDDs for transformations Support for various data formats3 4 RDD 1 RDD 2 Shuffle transform Drop split point Invoking RDD 2 computes all partitions of RDD 1
- 11. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING 5 Performance And Scalability Spark SQL Overview
- 12. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark SQL Features Standard JDBC/ODBC Connectivity6 7 User Defined Functions lets users define new Column-based functions to extend the Spark vocabulary User
- 13. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING UDF Example Creating a UDF ‘toUpperCase’ to convert a string to upper case Registering our UDF in the list of functions
- 14. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark SQL Architecture
- 15. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark SQL Architecture Architecture Of Spark SQL DataFrame DSL Spark SQL & HQL DataFrame API Data Source API CSV JDBCJSON
- 16. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark SQL Libraries
- 17. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark SQL Libraries Spark SQL has the following libraries: 1 Data Source API DataFrame API Interpreter & Optimizer SQL Service 2 3 4
- 18. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Data Source API DataFrame API Interpreter & Optimizer SQL Service Data Source API
- 19. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Data Source API Data Source API is used to read and store structured and semi- structured data into Spark SQL Features: Structured/ Semi-structured data Multiple formats 3rd party integration Data Source API
- 20. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Data Source API DataFrame API Interpreter & Optimizer SQL Service DataFrame API
- 21. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING DataFrame API DataFrame API converts the data that is read through Data Source API into tabular columns to help perform SQL operations Features: Distributed collection of data organized into named columns Equivalent to a relational table in SQL Lazily evaluated DataFrame API Named Columns Data Source API
- 22. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Data Source API DataFrame API Interpreter & Optimizer SQL Service SQL Interpreter & Optimizer
- 23. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING SQL Interpreter & Optimizer SQL Interpreter & Optimizer handles the functional programming part of Spark SQL. It transforms the DataFrames RDDs to get the required results in the required formats. Features: Functional programming Transforming trees Faster than RDDs Processes all size data e.g. Catalyst: A modular library for distinct optimization Interpreter & Optimizer Resilient Distributed Dataset
- 24. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Data Source API DataFrame API Interpreter & Optimizer SQL Service SQL Service
- 25. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING SQL Service Spark SQL Service Interpreter & Optimizer Resilient Distributed Dataset SQL Service is the entry point for working along structured data in Spark SQL is used to fetch the result from the interpreted & optimized data We have thus used all the four libraries in sequence. This completes a Spark SQL process
- 26. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Starting Up Spark Shell Creating Dataset Adding Schema To RDD JSON Dataset Hive Tables Querying Using Spark SQL
- 27. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Starting Up Spark Shell Creating Dataset Adding Schema To RDD JSON Dataset Hive Tables Starting Up Spark Shell
- 28. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Starting Up Spark Shell - Intialization //We first import a Spark Session into Apache Spark. import org.apache.spark.sql.SparkSession //Creating a Spark Session ‘spark’ using the ‘builder()’ function. val spark = SparkSession.builder().appName("Spark SQL basic example").config("spark.some.config.option", "some-value").getOrCreate() //Importing the Implicts class into our ‘spark’ Session. import spark.implicits._ //We now create a DataFrame ‘df’ and import data from the ’employee.json’ file. val df = spark.read.json("examples/src/main/resources/employee.json") //Displaying the DataFrame ‘df’. The result is a table of ages and names from our ’employee.json’ file. df.show()
- 29. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Starting Up Spark Shell – Spark Session
- 30. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Starting Up Spark Shell Creating Dataset Adding Schema To RDD JSON Dataset Hive Tables Creating Datasets
- 31. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Creating Dataset - Case Class & Dataset After understanding DataFrames, let us now move on to Dataset API. The below code creates a Dataset class in SparkSQL. //Creating a class ‘Employee’ to store name and age of an employee. case class Employee(name: String, age: Long) //Assigning a Dataset ‘caseClassDS’ to store the record of Andrew. val caseClassDS = Seq(Employee("Andrew", 55)).toDS() //Displaying the Dataset ‘caseClassDS’. caseClassDS.show() //Creating a primitive Dataset to demonstrate mapping of DataFrames into Datasets. val primitiveDS = Seq(1, 2, 3).toDS() //Assigning the above sequence into an array. primitiveDS.map(_ + 1).collect()
- 32. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Creating Dataset - Case Class & Dataset
- 33. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Creating Dataset – Reading File //Setting the path to our JSON file ’employee.json’. val path = "examples/src/main/resources/employee.json" //Creating a Dataset and from the file. val employeeDS = spark.read.json(path).as[Employee] //Displaying the contents of ’employeeDS’ Dataset. employeeDS.show()
- 34. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Creating Dataset – Reading File
- 35. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Starting Up Spark Shell Creating Dataset Adding Schema To RDD JSON Dataset Hive Tables Adding Schema To RDDs
- 36. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Adding Schema To RDDs – Initialization //Importing Expression Encoder for RDDs, Encoder library and Implicts class into the shell. import org.apache.spark.sql.catalyst.encoders.ExpressionEncoder import org.apache.spark.sql.Encoder import spark.implicits._ //Creating an ’employeeDF’ DataFrame from ’employee.txt’ and mapping the columns based on delimiter comma ‘,’ into a temporary view ’employee’. val employeeDF = spark.sparkContext.textFile("examples/src/main/resources/employee.txt").map(_.split(",")).ma p(attributes => Employee(attributes(0), attributes(1).trim.toInt)).toDF() //Creating the temporary view ’employee’. employeeDF.createOrReplaceTempView("employee") //Defining a DataFrame ‘youngstersDF’ which will contain all the employees between the ages of 18 and 30. val youngstersDF = spark.sql("SELECT name, age FROM employee WHERE age BETWEEN 18 AND 30") //Mapping the names from the RDD into ‘youngstersDF’ to display the names of youngsters. youngstersDF.map(youngster => "Name: " + youngster(0)).show()
- 37. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Adding Schema To RDDs – Initialization
- 38. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Adding Schema To RDDs - Transformation //Converting the mapped names into string for transformations. youngstersDF.map(youngster => "Name: " + youngster.getAs[String]("name")).show() //Using the mapEncoder from Implicits class to map the names to the ages. implicit val mapEncoder = org.apache.spark.sql.Encoders.kryo[Map[String, Any]] //Mapping the names to the ages of our ‘youngstersDF’ DataFrame. The result is an array with names mapped to their respective ages. youngstersDF.map(youngster => youngster.getValuesMap[Any](List("name", "age"))).collect()
- 39. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Adding Schema To RDDs - Transformation
- 40. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Adding Schema – Reading File & Adding Schema //Importing the ‘types’ class into the Spark Shell. import org.apache.spark.sql.types._ //Importing ‘Row’ class into the Spark Shell. Row is used in mapping RDD Schema. import org.apache.spark.sql.Row //Creating a RDD ’employeeRDD’ from the text file ’employee.txt’. val employeeRDD = spark.sparkContext.textFile("examples/src/main/resources/employee.txt") //Defining the schema as “name age”. This is used to map the columns of the RDD. val schemaString = "name age" //Defining ‘fields’ RDD which will be the output after mapping the ’employeeRDD’ to the schema ‘schemaString’. val fields = schemaString.split(" ").map(fieldName => StructField(fieldName, StringType, nullable = true)) //Obtaining the type of ‘fields’ RDD into ‘schema’. val schema = StructType(fields)
- 41. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Adding Schema – Reading File & Adding Schema
- 42. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Adding Schema – Transformation Result //We now create a RDD called ‘rowRDD’ and transform the ’employeeRDD’ using the ‘map’ function into ‘rowRDD’. val rowRDD = employeeRDD.map(_.split(",")).map(attributes => Row(attributes(0), attributes(1).trim)) //We define a DataFrame ’employeeDF’ and store the RDD schema into it. val employeeDF = spark.createDataFrame(rowRDD, schema) //Creating a temporary view of ’employeeDF’ into ’employee’. employeeDF.createOrReplaceTempView("employee") //Performing the SQL operation on ’employee’ to display the contents of employee. val results = spark.sql("SELECT name FROM employee") //Displaying the names of the previous operation from the ’employee’ view. results.map(attributes => "Name: " + attributes(0)).show()
- 43. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Adding Schema – Transformation Result
- 44. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Starting Up Spark Shell Creating Dataset Adding Schema To RDD JSON Dataset Hive Tables JSON Dataset
- 45. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING JSON Data – Loading File //Importing Implicits class into the shell. import spark.implicits._ //Creating an ’employeeDF’ DataFrame from our ’employee.json’ file. val employeeDF = spark.read.json("examples/src/main/resources/employee.json")
- 46. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING JSON Data – Loading File
- 47. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING JSON Data – Parquet File //Creating a ‘parquetFile’ temporary view of our DataFrame. employeeDF.write.parquet("employee.parquet") val parquetFileDF = spark.read.parquet("employee.parquet") parquetFileDF.createOrReplaceTempView("parquetFile") //Selecting the names of people between the ages of 18 and 30 from our Parquet file. val namesDF = spark.sql("SELECT name FROM parquetFile WHERE age BETWEEN 18 AND 30") //Displaying the result of the Spark SQL operation. namesDF.map(attributes => "Name: " + attributes(0)).show()
- 48. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING JSON Data – Parquet File
- 49. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING JSON Dataset – Creating DataFrame //Setting to path to our ’employee.json’ file. val path = "examples/src/main/resources/employee.json" //Creating a DataFrame ’employeeDF’ from our JSON file. val employeeDF = spark.read.json(path) //Printing the schema of ’employeeDF’. employeeDF.printSchema() //Creating a temporary view of the DataFrame into ’employee’. employeeDF.createOrReplaceTempView("employee") //Defining a DataFrame ‘youngsterNamesDF’ which stores the names of all the employees between the ages of 18 and 30 present in ’employee’. val youngsterNamesDF = spark.sql("SELECT name FROM employee WHERE age BETWEEN 18 AND 30") //Displaying the contents of our DataFrame. youngsterNamesDF.show()
- 50. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING JSON Dataset – Creating DataFrame
- 51. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING JSON Dataset – RDD Operation //Creating a RDD ‘otherEmployeeRDD’ which will store the content of employee George from New Delhi, Delhi. val otherEmployeeRDD = spark.sparkContext.makeRDD("""{"name":"George","address":{" city":"New Delhi","state":"Delhi"}}""" :: Nil) //Assigning the contents of ‘otherEmployeeRDD’ into ‘otherEmployee’. val otherEmployee = spark.read.json(otherEmployeeRDD) //Displaying the contents of ‘otherEmployee’. otherEmployee.show()
- 52. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING JSON Dataset – RDD Operation
- 53. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Starting Up Spark Shell Creating Dataset Adding Schema To RDD JSON Dataset Hive Tables Hive Tables
- 54. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Hive Tables – Case Class & Spark Session //Importing ‘Row’ class and Spark Session into the Spark Shell. import org.apache.spark.sql.Row import org.apache.spark.sql.SparkSession //Creating a class ‘Record’ with attributes Int and String. case class Record(key: Int, value: String) //Setting the location of ‘warehouseLocation’ to Spark warehouse. val warehouseLocation = "spark-warehouse" //We now build a Spark Session ‘spark’ to demonstrate Hive example in Spark SQL. val spark = SparkSession.builder().appName("Spark Hive Example").config("spark.sql.warehouse.dir", warehouseLocation).enableHiveSupport().getOrCreate() //Importing Implicits class and SQL library into the shell. import spark.implicits._ import spark.sql //Creating a table ‘src’ with columns to store key and value. sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING)")
- 55. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Hive Tables – Case Class & Spark Session
- 56. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Hive Tables – SQL Operation //We now load the data from the examples present in Spark directory into our table ‘src’. sql("LOAD DATA LOCAL INPATH 'examples/src/main/resources/kv1.txt' INTO TABLE src") //The contents of ‘src’ is displayed below. sql("SELECT * FROM src").show()
- 57. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Hive Tables – SQL Operation
- 58. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Hive Tables – SQL & DataFrame Transformation //We perform the ‘count’ operation to select the number of keys in ‘src’ table. sql("SELECT COUNT(*) FROM src").show() //We now select all the records with ‘key’ value less than 10 and store it in the ‘sqlDF’ DataFrame. val sqlDF = sql("SELECT key, value FROM src WHERE key < 10 ORDER BY key") //Creating a Dataset ‘stringDS’ from ‘sqlDF’. val stringsDS = sqlDF.map {case Row(key: Int, value: String) => s"Key: $key, Value: $value"} //Displaying the contents of ‘stringDS’ Dataset. stringsDS.show()
- 59. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Hive Tables – SQL & DataFrame Transformation
- 60. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Hive Tables - Result //We create a DataFrame ‘recordsDF’ and store all the records with key values 1 to 100. val recordsDF = spark.createDataFrame((1 to 100).map(i => Record(i, s"val_$i"))) //Create a temporary view ‘records’ of ‘recordsDF’ DataFrame. recordsDF.createOrReplaceTempView("records") //Displaying the contents of the join of tables ‘records’ and ‘src’ with ‘key’ as the primary key. sql("SELECT * FROM records r JOIN src s ON r.key = s.key").show()
- 61. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Hive Tables - Result
- 62. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Use Case: Stock Market Analysis With Spark SQL
- 63. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Use Case: Problem Statement Computations to be done: Compute the average closing price List the companies with highest closing prices Compute average closing price per month List the number of big price rises and falls Compute Statistical correlation We will use Spark SQL to retrieve trends in the stock market data and thus establish a financial strategy to avoid risky investment Stock Market trading generates huge real time data. Analysis of this data is the key to winning over losing. This real time data is often present in multiple formats. We need to compute the analysis with ease.
- 64. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Use Case: Requirements Process huge data Process data in real-time Easy to use and not very complex Requirements: Handle input from multiple sources
- 65. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Use Case: Why Spark SQL? Process huge data Process data in real-time Easy to use and not very complex Requirements: Handle input from multiple sources
- 66. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Use Case: Stock Market Analysis We will use stock data from yahoo finance for the following stocks: AAON Inc., AAON ABAXIS Inc., ABAX Fastenal Company, FAST F5 Networks, FFIV Gilead Sciences, GILD Microsoft Corporation, MSFT O'Reilly Automotive, ORLY PACCAR Inc., PCAR A. Schulman, SHLM Wynn Resorts Limited, WYNN Our Dataset has data from 10 companies trading in NASDAQ
- 67. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Use Case: Dataset The Microsoft stocks MSFT.csv file has the following format :
- 68. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Implementing Stock Analysis Using Spark SQL
- 69. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Use Case: Flow Diagram Huge amount of real time stock data 1 DataFrame API for Relational Processing 2 RDD for Functional Programming 3 Calculate Company with Highest Closing Price / Year Calculate Average Closing Price / Year Calculate Statistical Correlation between Companies Calculate Dates with Deviation in Stock Price 5 Spark SQL Query Spark SQL Query 4 4 Query 3 Query 4 Query 1 Query 2
- 70. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Spark SQL Query Use Case: Flow Example Calculate Average Closing Price / Year 4 Real Time Stock Market Data 1 AAON Company DataFrame 2 JoinClose RDD 3 Result Table 5
- 71. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Use Case: Starting Spark Shell Initialization of Spark SQL in Spark Shell Starting a Spark Session
- 72. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Use Case: Creating Case Class 1. Creating Case Class 2. Defining parseStock schema 3. Defining parseRDD 4. Reading AAON.csv into stocksAAONDF DataFrame
- 73. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Use Case: Display DataFrame Displaying DataFrame stocksAAONDF Similarly we create DataFrames for every other company
- 74. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Use Case: Average Monthly Closing Display the Average of Adjacent Closing Price for AAON for every month
- 75. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Use Case: Steep Change In Graph When did the closing price for Microsoft go up or down by more than 2 dollars in a day? 1. Create ‘result’ to select days when the difference was greater than 2 2. Displaying the result
- 76. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Use Case: Join AAON, ABAX & FAST Stocks We now join AAON, ABAX & FAST stocks in order to compare closing prices 1. Create a Union of AAON, ABAX & FAST stocks as joinclose 2. Display joinclose
- 77. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Use Case: Storing joinclose As Parquet 1. Store joinclose as a Parquet file joinstock.parquet 2. We can then create a DataFrame to work on the table 3. Display the DataFrame ‘df’.
- 78. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Use Case: Average Closing Per Year 1. Create newTables containing the Average Closing Prices of AAON, ABAX and FAST per year 2. Display ‘newTables’ 3. Register ‘newTable’ as a temporary table
- 79. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Use Case: Transformation Transformation of ‘newTables’ with Year and corresponding 3 companies’ data into CompanyAll table 1. Create transformed table ‘CompanyAll’ 2. Display ‘CompanyAll’
- 80. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Use Case: Best Of Average Closing 1. Create ‘BestCompany’ containing the Best Average Closing Prices of AAON, ABAX and FAST per year 2. Display ‘BestCompany’ 3. Register ‘BestCompany’ as a temporary table
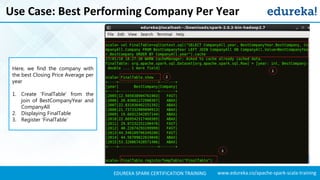
- 81. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Use Case: Best Performing Company Per Year Here, we find the company with the best Closing Price Average per year 1. Create ‘FinalTable’ from the join of BestCompanyYear and CompanyAll 2. Displaying FinalTable 3. Register ‘FinalTable’
- 82. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Use Case: Correlation We use Statistics library to find the correlation between AAON and ABAX companies closing prices. Correlation, in the finance and investment industries, is a statistic that measures the degree to which two securities move in relation to each other. The closer the correlation is to 1, the graph of the stocks follow a similar trend.
- 83. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Conclusion Congrats! We have hence demonstrated the power of Spark SQL in Real Time Data Analytics for Stock Market. The hands-on examples will give you the required confidence to work on any future projects you encounter in Spark SQL.
- 84. www.edureka.co/apache-spark-scala-trainingEDUREKA SPARK CERTIFICATION TRAINING Thank You … Questions/Queries/Feedback