














![Vectorization
no vectorization (json source)
...
[cropped source code]
vectorization (parquet source)](https://image.slidesharecdn.com/sparksqlunderthehood-datakrk-170907075411/85/Spark-sql-under-the-hood-Data-KRK-meetup-17-320.jpg)

Spark sql under the hood - Data KRK meetup
- 1. Spark SQL under the hood Mikołaj Kromka, VirtusLab [email protected] DataKRK meetup Kraków, 06.09.2017
- 2. Bio ● Software engineer at VirtusLab and Spark trainer at Virtusity ● Focused mostly on the Scala ecosystem ● Currently developing a new Analytics Platform for Tesco
- 3. Brief (and selective) history of structuring data ● Codd's relational model (1969 - 50th anniversary in two years!) ● SQL ○ one of the first commercial implementations at IBM (early 1970s) ○ SQL-based RDBMS developed at Relational Software, Inc (now Oracle Corporation) in the late 1970s ● Apache Hive bringing SQL-like capabilities to the Big Data world (open sourced 2008) ● Shark ● Spark SQL (2014)
- 4. Apache Spark: why the fuss? ● General engine for large-scale data processing ● Resilient Distributed Datasets ● Generating graph of computations automatically ● Scala, Java, Python and R APIs ● A lot of libraries on top of it (SQL, ML, GraphX, Streaming) ● One of the most active open source projects source https://spark.apache.org/docs/latest/cluster-overview.html
- 5. Apache Spark: why the fuss?
- 6. Do we need anything else? YES ● Data is usually structured - but RDDs contain arbitrary Java/Python objects and Transformations of RDDs contain arbitrary code ● Analysts know SQL/Hive ● Large SQL/HiveQL codebases that we would like to reuse ● Connecting to different data sources with (semi-)structured datasets ● Applying advanced and complex algorithms (such as ML)
- 7. Spark SQL to the rescue
- 8. Spark SQL to the rescue source https://databricks.com/blog/2016/07/14/a-tale-of-three-apache-spark-apis-rdds-dataframes-and-datasets.html
- 9. Spark SQL to the rescue
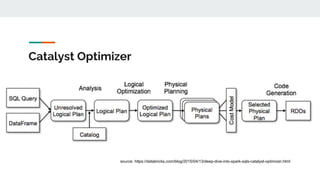
- 11. Analysis Resolves references of attributes (assigns them types or matches them to an input table)
- 13. Physical Planning source http://henning.kropponline.de/2016/12/11/broadcast-join-with-spark/ BroadcastHashJoin source http://www.waitingforcode.com/apache-spark-sql/sort-merge-join-spark-sql/read
- 15. Code generation ● Why do we need it? ○ without it simple expressions such as (x + y) + 1 would be interpreted from scratch for every row in the dataset ● Newer version of spark SQL support Whole-Stage Code Generation (not only expressions)
- 16. Spark UI
- 17. Vectorization no vectorization (json source) ... [cropped source code] vectorization (parquet source)
- 18. Some advice ● Don't stick to the Dataset API blindly - some operations cannot be inlined during codegen and will be slower ● Don't think that Spark SQL has all features of the traditional RDBMS, if you don't handle large amounts of data Postgres will be enough ● If possible don't create DataFrames from RDDs using .toDF() method, use specific DataFrameReader instead ● Analyse plans generated by the Catalyst to see if some optimizations were missed or there is a place to improve ● Spark UI is always useful
- 19. questions?