Spark Streaming @ Scale (Clicktale)
Download as PPTX, PDF0 likes237 views

The document discusses sessionization at scale using Spark Streaming for processing large volumes of real-time user data while addressing challenges related to stability, resiliency, and scalability. It highlights the differences between Spark Streaming and Structured Streaming, emphasizing the latter's improvements in state management and efficiency for high-throughput requirements. The authors recommend using Structured Streaming for scalable applications and mention potential alternatives like Apache Flink for state management.













![15Confidential
(“dardasaba”, “hello”),
(“dardasaba”,
“goodbye”),
(“hathatul”, “w00t”),
(“hathatul”, “nope”),
(“gargamel”, “muhaha”)
Executor 1
Executor 2
Executor 3
Key Value
“dardasaba” [“hello”,
“goodbye”]
Key Value
“hathatul” [“w00t”,
“nope”]
Key Value
“gargamel” [“muhaha”]
OpenHashMap[String, List[String]]
DStream[(String, String)]
Key Value](https://image.slidesharecdn.com/meetupsparkstreamingv21-170919123558/85/Spark-Streaming-Scale-Clicktale-15-320.jpg)


















Spark Streaming @ Scale (Clicktale)
- 1. Sessionization At Scale Using Spark Streaming in production and staying sane Marina Grechuhin & Yuval Itzchakov 12/09/2017
- 2. YuvalItzchakov 2Confidential • Developer @ Clicktale for the past 3 years • Previously developer @ IDF (8200) • @yuvalitzchakov • https://stackoverflow.com/users/1870803/yuval-itzchakov • http://asyncified.io
- 3. MarinaGrechuhin 3Confidential • Team Leader @ Clicktale • Previously co-founder and VP R&D @ SureVisit • Previously – many more
- 4. Yes No Agenda 4Confidential • Introduction to Spark • Spark In Depth • What Is Sessionization? • Spark Brief Overview • Sessionization With Spark Streaming • Scale Challenges • Structured Streaming with Stateful Aggregations
- 5. 5Confidential Architecture – Pipeline CEC Elastic Load Balancing Auto Scaling group Ingest Servers
- 6. { "version": 1, "location":"http://adobe.com/shoe.html", "projectId": 10, "documentReferrer": "", "visitId": 6403608503386111, "domContentLoaded": 324, "visitorId": 3246944914767871, "pageviewId": 1199465738272767, "engagementTime": 2336, "messageId": 0 } 6Confidential Pipeline CEC – Data Types • Init Message • Chunk Messages 0-N • End Message
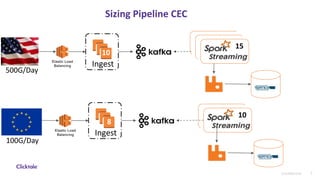
- 7. 14 7Confidential Sizing Pipeline CEC Elastic Load Balancing 10 500G/Day 100G/Day Ingest 1415 Elastic Load Balancing 8 Ingest 10
- 8. 8Confidential What is Sessionization? Session: “A sequence of requests made by a single end-user during a visit to a particular site” (Wikipedia) • To be able to aggregate user actions over time • All data doesn’t arrive at once, but piece by piece
- 9. 9Confidential Pipeline CEC – Data Types PageView End Chunk Init PageView End Chunk Init PageView Chunk Chunk Init Visit PageView PageView PageView PageView – User’s Journey on a single web page Visit – User’s journey on site
- 10. 10Confidential Requirements overview • Data size ranging between 200B – 1K (may grow over time) • Process incoming user messages up to 100,000 messages per second • Handle traffic peaks up to 1,000,000 messages/second (common with Fortune 500 companies) • Scale out as needed without user intervention (hopefully linearly) • Save user state until a session is complete, and only then send it down the pipeline • Latency - up to 10 seconds from ingestion to processing (make data available as soon as it’s ready)
- 11. 11Confidential
- 13. 13Confidential Spark Streaming • Discretized Stream (DStream) • Micro batching • One RDD every batch Where is the state kept between batches?
- 14. 14Confidential mapWithState Source: https://databricks.com/wp-content/uploads/2016/01/blog-faster-stateful-streaming-figure-1-1024x562.png Init Chunk End Page View Visit PageView • Partial Updates • Timeout • Initial State
- 15. 15Confidential (“dardasaba”, “hello”), (“dardasaba”, “goodbye”), (“hathatul”, “w00t”), (“hathatul”, “nope”), (“gargamel”, “muhaha”) Executor 1 Executor 2 Executor 3 Key Value “dardasaba” [“hello”, “goodbye”] Key Value “hathatul” [“w00t”, “nope”] Key Value “gargamel” [“muhaha”] OpenHashMap[String, List[String]] DStream[(String, String)] Key Value
- 16. 16Confidential What Could Possibly Go Wrong?
- 17. 17Confidential Scale Challenges • Stability • Resiliency • Scalability (scale up / down) • Monitoring
- 18. 18Confidential Spark Streaming Challenges 1. Stability & Resiliency -> Checkpointing • S3 • Task failure - Eventual consistency on read • AWS EFS (?) • Not suited for small file systems (limited IOPS) • HDFS • Best overall write performance out of the three • Can be installed on the same node as Spark Workers • Relatively low maintenance (if used only for checkpoint)
- 19. 19Confidential Spark Streaming Challenges 1. Stability & Resiliency -> Checkpointing (cont.) • Problem: • State not always recoverable • No matter the DFS, limits your throughput: • 1KB message size • 100,000 messages/sec • 1 minute checkpoint time (occurs every 40 seconds) • Workaround: • None (in Spark Streaming ) Checkpointing – This is the cost???
- 20. 20Confidential Spark Streaming Challenges 2. Resiliency -> Managing user state between application upgrades • Problems: • Can’t change the graph • Can’t change your data structures • Workaround: • Roll your own using `stateSnapshot()` • Provide on start up using `StateSpec.initialState()` * Can potentially double overhead of the job time (critical with high throughput).
- 21. 21Confidential Spark Streaming Challenges • Problem: • Spark Streaming defaults to one job (batch) at a time • If a particular job is stuck, all others wait indefinitely • Workaround: • Monitor job status using Sparks driver REST API (http://<driver ip>:4040/api/v1/applications) • Consider using Speculation (should be done carefully) • Enable Blacklisting if a particular node is faulty. • If you like to live dangerously, consider modifying “spark.streaming.concurrentJobs” 3. Stability -> Frozen Jobs
- 22. 22Confidential Spark Streaming Challenges • Scale Up – Just works* • Scale Down – Who takes over the worker’s state? 4. Scalability No One!
- 23. 23Confidential Spark Streaming Challenges • Logging mechanism – Log only small and random percent of traffic 4. Monitoring
- 24. 25Confidential Is there a better alternative?
- 25. 26Confidential Structured Streaming “The key idea in Structured Streaming is to treat a live data stream as a table that is being continuously appended” (Structured Streaming Documentation) Source: https://spark.apache.org/docs/latest/img/structured-streaming-stream-as-a-table.png
- 26. 27Confidential Structured Streaming (Cont.) Source: https://spark.apache.org/docs/latest/img/structured-streaming-model.png
- 27. 28Confidential mapGroupsWithState A second iteration at stateful aggregations in Spark Resiliency & Stability -> Checkpointing • Checkpoints are incremental, only deltas! • Allows state recovery between upgrades * *According to a set of tests made by us, may not apply to all cases and isn’t documented behavior
- 28. 29Confidential Spark Structured Streaming • More new features and cool stuff • Event based timeouts (previously only processing based) • Watermarking (New) • Deduplication (New) • Timeout per state item (Enhancement)
- 29. 30Confidential Our experience so far Running ~ 1 month in production with Spark 2.2 and mapGroupsWithState: Pros: • Queries seem to take less time on average than Spark Streaming * • No need to save state manually • Deduplication out of the box is awesome • Event based timeouts + Watermarking for late data is also awesome * In peak hours, from ~ 3 seconds per batch to 0.6 seconds per query (x5)
- 30. 31Confidential Our experience so far (Cont.) Neutral: • Kafka users: Spark now maps a TopicPartition to a particular Executor, improving data locality (less shuffling). • This means that in order to scale up, you must have at least a 1:1 mapping between number of Kafka partitions and Spark Executors. Cons: • Creates a significantly larger memory overhead (due to internal state implementation) • Makes heavier use of HDFS (many small file writes) • Doesn’t support multiple states (yet) • UI not as good as Streaming
- 31. 32Confidential Wrapping up • Overall, Spark Streaming is a great candidate for small-medium loads or none Stateful aggregations streams. • If you’re considering Spark as an option for your business, start with Structured Streaming from the get go. • Do consider Apache Flink and it’s similar state management module which allows pluggable state stores as an alternative.
- 32. 33Confidential • Real-time Streaming ETL with Structured Streaming: https://databricks.com/blog/2017/01/19/real-time-streaming-etl-structured- streaming-apache-spark-2-1.html • Making Structured Streaming Ready for Production: https://www.youtube.com/watch?v=UQiuyov4J-4&feature=youtu.be • Arbitrary Stateful Aggregations in Structured Streaming in Apache Spark: https://www.youtube.com/watch?v=JAb4FIheP28 • Exploring Spark Stateful Streaming: http://asyncified.io/2016/07/31/exploring-stateful- streaming-with-apache-spark • Exploring Stateful Streaming with Spark Structured Streaming: http://asyncified.io/2017/07/30/exploring-stateful-streaming-with-spark-structured-streaming Resources
- 33. Thank you for listening! Questions?
Editor's Notes
- #6: Monitor message sending mechanism 1 kafka topic
- #8: Monitor message sending mechanism 1 kafka topic
- #10: How do we aggregate user messages over time in a Streaming application??
- #11: Do a brief overview of all points, 15-20 seconds per point. At the end of the slide do an intro to Spark and talk a little about why we chose it over alternatives
- #13: Ask a question: How many people use Spark in production? How many people use Spark Streaming in production? How many do Sessionization?
- #14: Spark is not real time streaming, but micro batching Where is the state held?
- #19: Talk about each file system briefly