SparkNet presentation
Download as PPTX, PDF1 like206 views

SparkNet is a scalable framework for training deep networks on Apache Spark and Caffe, allowing asynchronous, distributed processing with minimal hardware needs. It utilizes a parameter server model for efficient gradient computation across worker nodes while addressing the challenges of conventional parallelization. Training benchmarks demonstrate significant speedup over baseline methods like Caffe, achieving better training times and maintaining competitive accuracy.
















SparkNet presentation
- 1. SparkNet: Training Deep Networks in Spark Authors: Philipp Moritz, Robert Nishihara, Ion Stoica, Michael I. Jordan (EECS, University of California, Berkeley) Paper Presentation By: Sneh Pahilwani (T-13) (CISE, University of Florida, Gainesville)
- 2. Motivation ● Much research in making deep learning models more accurate. ● With deeper models, comes better performance responsibility. ● Existing frameworks cannot handle asynchronous and communication-intensive workloads. ● Claim: SparkNet implements a scalable, distributed algorithm for training deep networks that can be applied to existing batch-processing frameworks like MapReduce and Spark, with minimal hardware requirements.
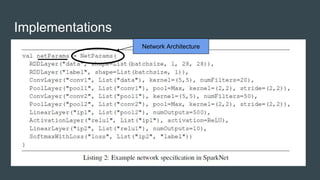
- 3. SparkNet Features ● Provides a convenient interface to be able to access Spark RDDs. ● Provides Scala interface to call Caffe. ● Has a lightweight multi-dimensional tensor library. ● SparkNet can scale well to the cluster size and can tolerate a high communication delay. ● Easy to deploy and no parameter adjustment. ● Compatible with existing Caffe models.
- 4. Parameter Server Model ● One or more master nodes hold the latest model parameters in memory and serve them to worker nodes upon request. ● The nodes then compute gradients with respect to these parameters on a minibatch drawn from the local dataset copy. ● These gradients are sent back to the server, which updates the model parameters. SparkNet architecture
- 5. Implementations ● SparkNet is built on top of Apache Spark and Caffe deep learning library. ● Uses Java to access the Caffe data. ● Uses Scala to access the parameters of the Caffe. ● Uses ScalaBuff to make the Caffe network to maintain a dynamic structure at run time. ● SparkNet can be compatible with some of the Caffe model definition files, and supports the Caffe model parameters of the load.
- 6. Implementations Map from layer names to weights Lightweight multi-dimensional tensor library implementation.
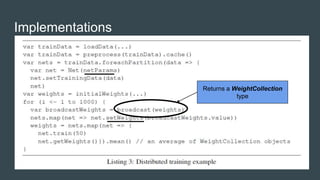
- 9. Stochastic Gradient Descent Comparison ● Conventional: ○ A conventional approach to parallelize gradient computation requires a lot of broadcasting and communication overhead between the workers and parameter server after every Stochastic Gradient Descent(SGD) iteration. ● SparkNet: ○ In this model, a fixed parameter is set for every worker in the Spark cluster (number of iterations or time limit), after which the params are sent to the master and averaged.
- 10. SGD Parallelism ● Spark consists of a single master node and a number of worker nodes. ● The data is split among the Spark workers. ● In every iteration, the Spark master broadcasts the model parameters to each worker. ● Each worker then runs SGD on the model with its subset of data for a fixed number of iterations (say, 50), after which the resulting model parameters on each worker are sent to the master and averaged to form the new model parameters.
- 11. Naive Parallelization Number of serial iterations
- 12. Practical Limitations of Naive Parallelization ● Naive parallelization would distribute minibatch ‘b’ over ‘K’ machines, computing gradients separately and aggregating results on one node. ● Cost of computation on single node in single iteration: C(b/K) and satisfies C(b/K) >= C(b)/K. Hence, total running time to achieve test accuracy ‘a’: Na(b)C(b)/K (in theory) ● Limitation #1: For approximation, C(b)/K ~ C(b/K) to hold, K<<b , limits number of machines in cluster for effective parallelization. ● Limitation #2: To overcome above limitation, minibatch size could be increased but does not decrease Na(b) enough to justify the increment.
- 13. SparkNet ParallelizationNumber of iterations on every machine Number of rounds
- 14. SparkNet parallelization ● Proceeds in rounds, where for each round, each machine runs SGD for ‘T’ iterations with batch size ‘b’. ● Between rounds, params on workers are gathered on master, averaged and broadcasted to workers. ● Basically, synchronization happens every ‘T’ iterations. ● Total number of iterations: TMa(b,k,T). ● Total time taken: (TC(b) + S)Ma(b,k,T).
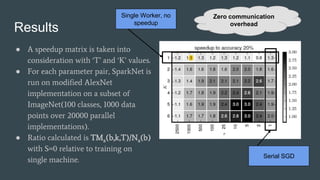
- 15. Results ● A speedup matrix is taken into consideration with ‘T’ and ‘K’ values. ● For each parameter pair, SparkNet is run on modified AlexNet implementation on a subset of ImageNet(100 classes, 1000 data points over 20000 parallel implementations). ● Ratio calculated is TMa(b,k,T)/Na(b) with S=0 relative to training on single machine. Serial SGD Single Worker, no speedup Zero communication overhead
- 16. Results Speedup measured as a function of communication overhead ‘S’. (5-node cluster) Non-Zero communication overhead
- 17. Training Benchmarks ● AlexNet on ImageNet training. ● T = 50. ● Single GPU nodes. ● Accuracy measured: 45% ● Time measured: ○ Caffe: 55.6 hours (baseline) ○ SparkNet 3: 22.9 hours (2.4) ○ SparkNet 5: 14.5 hours (3.8) ○ SparkNet 10: 12.8 hours (4.4)
- 18. Training Benchmarks ● GoogLeNet on ImageNet training. ● T = 50. ● Multi-GPU nodes. ● Accuracy measured: 40% ● Speedup measured (compared to Caffe 4-GPU): ○ SparkNet 3-node 4-GPU: 2.7 ○ SparkNet 6-node 4-GPU: 3.2 ● On top of Caffe 4-GPU speedup of 3.5.
- 19. THANK YOU!