SPIMBENCH: A Scalable, Schema-Aware Instance Matching Benchmark for the Semantic Publishing Domain
3 likes617 views

The document introduces Spimbench, a scalable benchmark for instance matching in the semantic publishing domain, aimed at evaluating various matching systems and algorithms. It emphasizes the importance of benchmarking through value-based, structure-based, and semantics-aware transformations, and includes performance metrics and a weighted gold standard for testing. Future work involves utilizing Spimbench in the Ontology Alignment Evaluation Initiative and developing more sophisticated evaluation metrics.



![Semantic Publishing Instance Matching Benchmark (SPIMBENCH) 4
SPIMBENCH
• Based on Semantic Publishing Benchmark (SPB) of Linked
Data Benchmark Council (LDBC)
• Synthetic benchmark for the Semantic Publishing Domain
• Value-based, structure-based and semantics-aware
transformations [FMN+11, FLM08]
• Deterministic, scalable data generation in the order of
billion triples
• Weighted gold standard](https://image.slidesharecdn.com/tucgraphtasaveta-150324063719-conversion-gate01/85/SPIMBENCH-A-Scalable-Schema-Aware-Instance-Matching-Benchmark-for-the-Semantic-Publishing-Domain-4-320.jpg)
![Semantic Publishing Instance Matching Benchmark (SPIMBENCH) 5
Instance Matching Benchmark Ingredients [FLM08]
Benchmark
Datasets
Gold
Standard
Test
Cases
Metrics](https://image.slidesharecdn.com/tucgraphtasaveta-150324063719-conversion-gate01/85/SPIMBENCH-A-Scalable-Schema-Aware-Instance-Matching-Benchmark-for-the-Semantic-Publishing-Domain-5-320.jpg)

![Semantic Publishing Instance Matching Benchmark (SPIMBENCH) 7
Value & Structure Based Transformations
Value: Mainly typographical errors and the use of
different data formats.[FMN+11]
Structure: Changes that occur to the properties.
– Property Addition/Deletion
– Property Aggregation/Extraction
Blank Character Addition/Deletion Change Number
Random Character Addition/Deletion/Modification Synonym/Antonym
Token Addition/Deletion/Shuffle Abbreviation
Multi-linguality (65 supported languages) Stem of a Word
Date Format](https://image.slidesharecdn.com/tucgraphtasaveta-150324063719-conversion-gate01/85/SPIMBENCH-A-Scalable-Schema-Aware-Instance-Matching-Benchmark-for-the-Semantic-Publishing-Domain-7-320.jpg)




![Semantic Publishing Instance Matching Benchmark (SPIMBENCH) 13
Performance of LogMap [JG11]
Performance of LogMap for 10K triples Performance of LogMap for 25K triples
Performance of LogMap for 50K triples](https://image.slidesharecdn.com/tucgraphtasaveta-150324063719-conversion-gate01/85/SPIMBENCH-A-Scalable-Schema-Aware-Instance-Matching-Benchmark-for-the-Semantic-Publishing-Domain-13-320.jpg)

![Semantic Publishing Instance Matching Benchmark (SPIMBENCH) 15
Future Work
• SPIMBENCH will be used as one of the Ontology
Alignment Evaluation Initiative [OAEI]
benchmarks for 2015.
• Domain independent instance matching test
case generator.
• Definition of more sophisticated metrics that
takes into account the
difficulty (weight).](https://image.slidesharecdn.com/tucgraphtasaveta-150324063719-conversion-gate01/85/SPIMBENCH-A-Scalable-Schema-Aware-Instance-Matching-Benchmark-for-the-Semantic-Publishing-Domain-15-320.jpg)

![Semantic Publishing Instance Matching Benchmark (SPIMBENCH) 17
References
# Reference Abbreviation
1
A. Ferrara and D. Lorusso and S. Montanelli and G. Varese.
Towards a Benchmark for Instance Matching. In OM, 2008.
[FLM08]
2
A. Ferrara and S. Montanelli and J. Noessner and H. Stuckenschmidt.
Benchmarking Matching Applications on the Semantic Web. In ESWC, 2011.
[FMN+11]
3
M. Nickel and V. Tresp. Tensor Factorization for Multi-relational Learning.
Machine Learning and Knowledge Discovery in Databases. Springer Berlin
Heidelberg, 2013. 617-621.
[NV13]
4
J. M. Joyce . Kullback-Leibler Divergence. International Encyclopedia of
Statistical Science. Springer Berlin Heidelberg, 2011. 720-722.
[J11]
5
E. Jimenez-Ruiz and B. C. Grau. Logmap: Logic-based and scalable ontology
matching. In ISWC, 2011.
[JG11]
6
B. Fuglede and F. Topsoe. Jensen-Shannon divergence and Hilbert space
embedding, in IEEE International Symposium on Information Theory, 2004.
[FT04]
7
Ontology Alignment Evaluation Initiative, find at
http://oaei.ontologymatching.org/
[OAEI]](https://image.slidesharecdn.com/tucgraphtasaveta-150324063719-conversion-gate01/85/SPIMBENCH-A-Scalable-Schema-Aware-Instance-Matching-Benchmark-for-the-Semantic-Publishing-Domain-17-320.jpg)

SPIMBENCH: A Scalable, Schema-Aware Instance Matching Benchmark for the Semantic Publishing Domain
- 1. SPIMBENCH: A Scalable, Schema-Aware Instance Matching Benchmark for the Semantic Publishing Domain T. Saveta1, E. Daskalaki1, G. Flouris1, I. Fundulaki1, M. Herschel2, A.-C. Ngonga Ngomo3 #1 FORTH-ICS, #2 University of Stuttgart, #3 University of Leipzig
- 2. Semantic Publishing Instance Matching Benchmark (SPIMBENCH) 2 Instance Matching in Linked Data Data acquisition Data evolution Data integration Open/social data How can we automatically recognize multiple mentions of the same entity across or within sources? = Instance Matching
- 3. Semantic Publishing Instance Matching Benchmark (SPIMBENCH) 3 Benchmarking Instance matching research has led to the development of various systems and algorithms. How to compare these? How can we assess their performance? How can we push the systems to get better? These systems need to be benchmarked
- 4. Semantic Publishing Instance Matching Benchmark (SPIMBENCH) 4 SPIMBENCH • Based on Semantic Publishing Benchmark (SPB) of Linked Data Benchmark Council (LDBC) • Synthetic benchmark for the Semantic Publishing Domain • Value-based, structure-based and semantics-aware transformations [FMN+11, FLM08] • Deterministic, scalable data generation in the order of billion triples • Weighted gold standard
- 5. Semantic Publishing Instance Matching Benchmark (SPIMBENCH) 5 Instance Matching Benchmark Ingredients [FLM08] Benchmark Datasets Gold Standard Test Cases Metrics
- 6. Semantic Publishing Instance Matching Benchmark (SPIMBENCH) 6 SPIMBENCH Model
- 7. Semantic Publishing Instance Matching Benchmark (SPIMBENCH) 7 Value & Structure Based Transformations Value: Mainly typographical errors and the use of different data formats.[FMN+11] Structure: Changes that occur to the properties. – Property Addition/Deletion – Property Aggregation/Extraction Blank Character Addition/Deletion Change Number Random Character Addition/Deletion/Modification Synonym/Antonym Token Addition/Deletion/Shuffle Abbreviation Multi-linguality (65 supported languages) Stem of a Word Date Format
- 8. Semantic Publishing Instance Matching Benchmark (SPIMBENCH) 8 Semantics-Aware Transformations Test if matching systems consider schema information to discover instance matches. • Instance (in)equality constructs • owl:sameAs, owl:differentFrom • Equivalence classes, properties • owl:equivalentClass, owl:equivalentProperty • Disjointness classes, properties • owl:disjointWith, owl:propertyDisjointWith • RDFS hierarchies • rdfs:subClassOf, rdfs:subPropertyOf • Property constraints • owl:FunctionalProperty, owl:InverseFunctionalProperty • Complex class definitions • owl:unionOf, owl:intersectionOf
- 9. Semantic Publishing Instance Matching Benchmark (SPIMBENCH) 9 SPIMBENCH Model
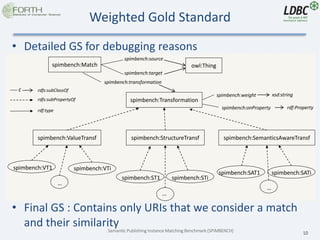
- 10. Semantic Publishing Instance Matching Benchmark (SPIMBENCH) 10 Weighted Gold Standard • Detailed GS for debugging reasons • Final GS : Contains only URIs that we consider a match and their similarity spimbench:Match owl:Thing spimbench:ValueTransf spimbench:StructureTransf spimbench:SemanticsAwareTransf spimbench:Transformation spimbench:VT1 spimbench:VTi spimbench:ST1 spimbench:STi spimbench:SAT1 … spimbench:SATi … … rdfs:subPropertyOf rdfs:subClassOf rdf:type c spimbench:source spimbench:target spimbench:weight xsd:string spimbench:onProperty rdf:Property spimbench:transformation
- 11. Semantic Publishing Instance Matching Benchmark (SPIMBENCH) 11 Scalability Experiments (1/2) • Scalability experiments for datasets up to 500M triples • 1000 triples ~ 36 entities • Data generation along with data transformation is linear to the size of triples • Transformation overhead is negligible for value-based, structure- based, semantics-aware and simple combinations • Overhead for complex combinations is higher by one magnitude
- 12. Semantic Publishing Instance Matching Benchmark (SPIMBENCH) 12 Scalability Experiments (2/2)
- 13. Semantic Publishing Instance Matching Benchmark (SPIMBENCH) 13 Performance of LogMap [JG11] Performance of LogMap for 10K triples Performance of LogMap for 25K triples Performance of LogMap for 50K triples
- 14. Semantic Publishing Instance Matching Benchmark (SPIMBENCH) 14 Conclusions • Schema aware variations – Complex class definitions – Property constraints – Equivalence, Disjointness, etc. • Combination of transformations • Scalable data generation in order of billion triples – Uses sampling • Weighted gold standard – Final gold standard – Detailed gold standard for debugging reasons
- 15. Semantic Publishing Instance Matching Benchmark (SPIMBENCH) 15 Future Work • SPIMBENCH will be used as one of the Ontology Alignment Evaluation Initiative [OAEI] benchmarks for 2015. • Domain independent instance matching test case generator. • Definition of more sophisticated metrics that takes into account the difficulty (weight).
- 16. Semantic Publishing Instance Matching Benchmark (SPIMBENCH) 16 Acknowledgments This work was partially supported by the ongoing FP7 European Project LDBC (Linked Data Benchmark Council) (317548) and is done in collaboration with I. Fundulaki, M. Herschel (University of Stuttgart), G. Flouris, E. Daskalaki and A. C. Ngonga Ngomo (University of Leipzig)
- 17. Semantic Publishing Instance Matching Benchmark (SPIMBENCH) 17 References # Reference Abbreviation 1 A. Ferrara and D. Lorusso and S. Montanelli and G. Varese. Towards a Benchmark for Instance Matching. In OM, 2008. [FLM08] 2 A. Ferrara and S. Montanelli and J. Noessner and H. Stuckenschmidt. Benchmarking Matching Applications on the Semantic Web. In ESWC, 2011. [FMN+11] 3 M. Nickel and V. Tresp. Tensor Factorization for Multi-relational Learning. Machine Learning and Knowledge Discovery in Databases. Springer Berlin Heidelberg, 2013. 617-621. [NV13] 4 J. M. Joyce . Kullback-Leibler Divergence. International Encyclopedia of Statistical Science. Springer Berlin Heidelberg, 2011. 720-722. [J11] 5 E. Jimenez-Ruiz and B. C. Grau. Logmap: Logic-based and scalable ontology matching. In ISWC, 2011. [JG11] 6 B. Fuglede and F. Topsoe. Jensen-Shannon divergence and Hilbert space embedding, in IEEE International Symposium on Information Theory, 2004. [FT04] 7 Ontology Alignment Evaluation Initiative, find at http://oaei.ontologymatching.org/ [OAEI]
Editor's Notes
- #16: We are currently working on a domain-independent instance matching test case generator for Linked Data, whose aim is to take any ontology and RDF dataset as source and produce a target dataset that will implement the test cases discussed earlier. We are also studying how we can dene more sophisticated metrics that take into account the difficulty (weight) of the correctly identified matches, to be used in tandem with the standard precision and recall metrics. Also SPIMBENCH will be used as one of the OAEI benchmarks for 2015. --------------------------------------------------------------------------------------------------------------- Όσο αφορά την μελλοντική ανάπτυξη του συστήματος θα προσπαθήσουμε να κάνουμε τον SPIMBench τελείως ανεξάρτητο από οποιοδήποτε τομέα (domain). Ακόμα θα μπορεί να υποστηρίζει περισσοτέρους συνδυασμούς μετατροπών με πιο αυτόματο τρόπο. Ακόμα θα πρέπει να επανεξετάσουμε τις μετρικές (precision- recall) ώστε να μπορουν να λάβουν υπόψη και τα βάρη. Wald method[ref] for sampling ?? -> provlepei kai poso tha einai to sfalma analoga to k ++++ koitaksame ola ta vasika tis owl lite kai owl rl kai auta pou kaname eixan mono noima alliws tha itan polu duskolo gia ta sustimata mpla mpla