SQL Performance Improvements At a Glance in Apache Spark 3.0
2 likes905 views

Apache Spark 3.0 introduces significant SQL performance improvements, including dynamic optimizations, new join hints, and enhancements in query execution and data pruning. Key features such as a new explain format, adaptive query execution, and improved aggregation code generation are designed to enhance performance and usability. These updates aim to simplify query optimization, allowing for more efficient data processing and reduced resource consumption.
















![Not Easy to Read a Query Plan on Spark 2.4
▪ Not easy to understand how a query is optimized
17 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki SPARK-27395
scala> val query = “SELECT key, Max(val) FROM temp WHERE key > 0 GROUP BY key HAVING max(val) > 0”
scala> sql(“EXPLAIN “ + query).show(false)
From #24759
Output is too long!!
!== Physical Plan ==
*(2) Project [key#2, max(val)#15]
+- *(2) Filter (isnotnull(max(val#3)#18) AND (max(val#3)#18 > 0))
+- *(2) HashAggregate(keys=[key#2], functions=[max(val#3)], output=[key#2, max(val)#15,
max(val#3)#18])
+- Exchange hashpartitioning(key#2, 200)
+- *(1) HashAggregate(keys=[key#2], functions=[partial_max(val#3)], output=[key#2,
max#21])
+- *(1) Project [key#2, val#3]
+- *(1) Filter (isnotnull(key#2) AND (key#2 > 0))
+- *(1) FileScan parquet default.temp[key#2,val#3] Batched: true,
DataFilters: [isnotnull(key#2), (key#2 > 0)], Format: Parquet, Location:
InMemoryFileIndex[file:/user/hive/warehouse/temp], PartitionFilters: [], PushedFilters:
[IsNotNull(key), GreaterThan(key,0)], ReadSchema: struct<key:int,val:int>](https://image.slidesharecdn.com/sais2020ishizakipublic-200626042902/85/SQL-Performance-Improvements-At-a-Glance-in-Apache-Spark-3-0-17-320.jpg)
![Easy to Read a Query Plan on Spark 3.0
▪ Show a query in a terse format with detail information
18 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki SPARK-27395
!== Physical Plan ==
Project (8)
+- Filter (7)
+- HashAggregate (6)
+- Exchange (5)
+- HashAggregate (4)
+- Project (3)
+- Filter (2)
+- Scan parquet default.temp1 (1)
(1) Scan parquet default.temp [codegen id : 1]
Output: [key#2, val#3]
(2) Filter [codegen id : 1]
Input : [key#2, val#3]
Condition : (isnotnull(key#2) AND (key#2 > 0))
(3) Project [codegen id : 1]
Output : [key#2, val#3]
Input : [key#2, val#3]
(4) HashAggregate [codegen id : 1]
Input: [key#2, val#3]
(5) Exchange
Input: [key#2, max#11]
(6) HashAggregate [codegen id : 2]
Input: [key#2, max#11]
(7) Filter [codegen id : 2]
Input : [key#2, max(val)#5, max(val#3)#8]
Condition : (isnotnull(max(val#3)#8) AND
(max(val#3)#8 > 0))
(8) Project [codegen id : 2]
Output : [key#2, max(val)#5]
Input : [key#2, max(val)#5, max(val#3)#8]
scala> sql(“EXPLAIN FORMATTED “ + query).show(false)](https://image.slidesharecdn.com/sais2020ishizakipublic-200626042902/85/SQL-Performance-Improvements-At-a-Glance-in-Apache-Spark-3-0-18-320.jpg)















![Example of Dynamic Partitioning Pruning
34 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki SPARK-11150
scala> spark.range(7777).selectExpr("id", "id AS key").write.partitionBy("key").saveAsTable("tableLarge")
scala> spark.range(77).selectExpr("id", "id AS key").write.partitionBy("key").saveAsTable("tableSmall")
scala> val query = "SELECT * FROM tableLarge JOIN tableSmall ON tableLarge.key = tableSmall.key AND tableSmall.id < 3"
scala> sql("EXPLAIN FORMATTED " + query).show(false)
|== Physical Plan ==
* BroadcastHashJoin Inner BuildRight (8)
:- * ColumnarToRow (2)
: +- Scan parquet default.tablelarge (1)
+- BroadcastExchange (7)
+- * Project (6)
+- * Filter (5)
+- * ColumnarToRow (4)
+- Scan parquet default.tablesmall (3)
(1) Scan parquet default.tablelarge
Output [2]: [id#19L, key#20L]
Batched: true
Location: InMemoryFileIndex [file:/home/ishizaki/Spark/300RC1/spark-3.0.0-bin-hadoop2.7/spark-
warehouse/tablelarge/key=0, ... 7776 entries]
PartitionFilters: [isnotnull(key#20L), dynamicpruningexpression(key#20L IN dynamicpruning#56)]
ReadSchema: struct<id:bigint>
Source: Quick Overview of Upcoming Spark 3.0](https://image.slidesharecdn.com/sais2020ishizakipublic-200626042902/85/SQL-Performance-Improvements-At-a-Glance-in-Apache-Spark-3-0-34-320.jpg)




![Example of Nested Column Pruning
▪ Parquet only reads col2._1, as shown in ReadSchema
39 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki SPARK-25603 & 25556
== Physical Plan ==
Exchange RoundRobinPartitioning(1)
+- *(1) Project [col2#5._1 AS _1#11L]
+- *(1) FileScan parquet [col2#5] ..., PushedFilters: [], ReadSchema: struct<col2:struct<_1:bigint>>
scala> sql("SELECT col2._1 FROM (SELECT /*+ REPARTITION(1) */ col2 FROM temp)").explain
Source: #23964
scala> spark.range(1000).map(x => (x, (x, s"$x" * 10))).toDF("col1", "col2").write.parquet("/tmp/p")
scala> spark.read.parquet("/tmp/p").createOrReplaceTempView("temp")
scala> sql("SELECT col2._1 FROM (SELECT col2 FROM tp LIMIT 1000000)").explain
== Physical Plan ==
CollectLimit 1000000
+- *(1) Project [col2#22._1 AS _1#28L]
+- *(1) FileScan parquet [col2#22] ..., ReadSchema: struct<col2:struct<_1:bigint>>
LIMIT
Repartition](https://image.slidesharecdn.com/sais2020ishizakipublic-200626042902/85/SQL-Performance-Improvements-At-a-Glance-in-Apache-Spark-3-0-39-320.jpg)
![No Nested Column Pushdown on Spark 2.4
▪ Parquet cannot apply predication pushdown
40 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki SPARK-25603 & 25556
scala> spark.range(1000).map(x => (x, (x, s"$x" * 10))).toDF("col1", "col2").write.parquet("/tmp/p")
scala> spark.read.parquet(“/tmp/p”).filter(“col2._1 = 100").explain
== Physical Plan ==
*(1) Project [col1#12L, col2#13]
+- *(1) Filter (isnotnull(col2#13) && (col2#13._1 = 100))
+- *(1) FileScan parquet [col1#12L,col2#13] ..., PushedFilters: [IsNotNull(nested)], ...
Spark 2.4
Project
col1 col2
_1 _2 Filter
Source: #28319
All data rows only if
col2._1=100](https://image.slidesharecdn.com/sais2020ishizakipublic-200626042902/85/SQL-Performance-Improvements-At-a-Glance-in-Apache-Spark-3-0-40-320.jpg)
![Nested Column Pushdown on Spark 3.0
▪ Parquet can apply pushdown filter and can read part of columns
41 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki SPARK-25603 & 25556
scala> spark.range(1000).map(x => (x, (x, s"$x" * 10))).toDF("col1", "col2").write.parquet("/tmp/p")
scala> spark.read.parquet(“/tmp/p”).filter(“col2._1 = 100").explain
Spark 3.0
== Physical Plan ==
*(1) Project [col1#0L, col2#1]
+- *(1) Filter (isnotnull(col2#1) AND (col2#1._1 = 100))
+- FileScan parquet [col1#0L,col2#1] ..., DataFilters: [isnotnull(col2#1), (col2#1.x = 100)],
..., PushedFilters: [IsNotNull(col2), EqualTo(col2._1,100)], ...
Project
col1 col2
_1 _2 Filter
Source: #28319
chunks including
col2._1=100
rows only if
col2._1=100](https://image.slidesharecdn.com/sais2020ishizakipublic-200626042902/85/SQL-Performance-Improvements-At-a-Glance-in-Apache-Spark-3-0-41-320.jpg)











SQL Performance Improvements At a Glance in Apache Spark 3.0
- 1. SQL Performance Improvements At a Glance in Apache Spark 3.0 Kazuaki Ishizaki IBM Research
- 2. About Me – Kazuaki Ishizaki ▪ Researcher at IBM Research – Tokyo https://ibm.biz/ishizaki – Compiler optimization, language runtime, and parallel processing ▪ Apache Spark committer from 2018/9 (SQL module) ▪ Work for IBM Java (Open J9, now) from 1996 – Technical lead for Just-in-time compiler for PowerPC ▪ ACM Distinguished Member ▪ SNS – @kiszk – https://www.slideshare.net/ishizaki/ 2 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki
- 3. Spark 3.0 ▪ The long wished-for release… – More than 1.5 years passed after Spark 2.4 has been released 3 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki
- 4. Spark 3.0 ▪ Four Categories of Major Changes for SQL 4 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki Interactions with developers Dynamic optimizations Catalyst improvements Infrastructure updates
- 5. When Spark 2.4 was released? ▪ The long wished-for release… – More than 1.5 years passed after Spark 2.4 has been released 5 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki 2018 November
- 6. What We Expected Last Year? ▪ The long wished-for release… – More than 1.5 years passed after Spark 2.4 has been released 6 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki Keynote at Spark+AI Summit 2019 2019 April
- 7. Spark 3.0 Looks Real ▪ The long wished-for release… – More than 1.5 years passed after Spark 2.4 has been released 7 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki Keynote at Spark+AI Summit 2019 2019 November
- 8. Spark 3.0 has been released!! ▪ The long wished-for release… – More than 1.5 years passed after Spark 2.4 has been released 8 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki Keynote at Spark+AI Summit 2019 (April, 2019)3.0.0 has released early June, 2020
- 9. Community Worked for Spark 3.0 Release ▪ 3464 issues (as of June 8th, 2020) – New features – Improvements – Bug fixes 9 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki Source https://issues.apache.org/jira/projects/SPARK/versions/12339177
- 10. Many Many Changes for 1.5 years ▪ 3369 issues (as of May 15, 2020) – Features – Improvements – Bug fixes 10 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki Hard to understand what’s new due to many many changes
- 11. Many Many Changes for 1.5 years ▪ 3369 issues (as of May 15, 2020) – Features – Improvements – Bug fixes 11 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki Hard to understand what’s new due to many many changes This session guides you to understand what’s new for SQL performance
- 12. Seven Major Changes for SQL Performance 1. New EXPLAIN format 2. All type of join hints 3. Adaptive query execution 4. Dynamic partitioning pruning 5. Enhanced nested column pruning & pushdown 6. Improved aggregation code generation 7. New Scala and Java 12 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki
- 13. Seven Major Changes for SQL Performance 1. New EXPLAIN format 2. All type of join hints 3. Adaptive query execution 4. Dynamic partitioning pruning 5. Enhanced nested column pruning & pushdown 6. Improved aggregation code generation 7. New Scala and Java 13 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki Interactions with developers Dynamic optimizations Catalyst improvements Infrastructure updates
- 14. What is Important to Improve Performance? ▪ Understand how a query is optimized 14 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki SPARK-27395
- 15. What is Important to Improve Performance? ▪ Understand how a query is optimized 15 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki SPARK-27395 Easy to Read a Query Plan
- 16. Read a Query Plan 16 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki SPARK-27395 “SELECT key, Max(val) FROM temp WHERE key > 0 GROUP BY key HAVING max(val) > 0” From #24759
- 17. Not Easy to Read a Query Plan on Spark 2.4 ▪ Not easy to understand how a query is optimized 17 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki SPARK-27395 scala> val query = “SELECT key, Max(val) FROM temp WHERE key > 0 GROUP BY key HAVING max(val) > 0” scala> sql(“EXPLAIN “ + query).show(false) From #24759 Output is too long!! !== Physical Plan == *(2) Project [key#2, max(val)#15] +- *(2) Filter (isnotnull(max(val#3)#18) AND (max(val#3)#18 > 0)) +- *(2) HashAggregate(keys=[key#2], functions=[max(val#3)], output=[key#2, max(val)#15, max(val#3)#18]) +- Exchange hashpartitioning(key#2, 200) +- *(1) HashAggregate(keys=[key#2], functions=[partial_max(val#3)], output=[key#2, max#21]) +- *(1) Project [key#2, val#3] +- *(1) Filter (isnotnull(key#2) AND (key#2 > 0)) +- *(1) FileScan parquet default.temp[key#2,val#3] Batched: true, DataFilters: [isnotnull(key#2), (key#2 > 0)], Format: Parquet, Location: InMemoryFileIndex[file:/user/hive/warehouse/temp], PartitionFilters: [], PushedFilters: [IsNotNull(key), GreaterThan(key,0)], ReadSchema: struct<key:int,val:int>
- 18. Easy to Read a Query Plan on Spark 3.0 ▪ Show a query in a terse format with detail information 18 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki SPARK-27395 !== Physical Plan == Project (8) +- Filter (7) +- HashAggregate (6) +- Exchange (5) +- HashAggregate (4) +- Project (3) +- Filter (2) +- Scan parquet default.temp1 (1) (1) Scan parquet default.temp [codegen id : 1] Output: [key#2, val#3] (2) Filter [codegen id : 1] Input : [key#2, val#3] Condition : (isnotnull(key#2) AND (key#2 > 0)) (3) Project [codegen id : 1] Output : [key#2, val#3] Input : [key#2, val#3] (4) HashAggregate [codegen id : 1] Input: [key#2, val#3] (5) Exchange Input: [key#2, max#11] (6) HashAggregate [codegen id : 2] Input: [key#2, max#11] (7) Filter [codegen id : 2] Input : [key#2, max(val)#5, max(val#3)#8] Condition : (isnotnull(max(val#3)#8) AND (max(val#3)#8 > 0)) (8) Project [codegen id : 2] Output : [key#2, max(val)#5] Input : [key#2, max(val)#5, max(val#3)#8] scala> sql(“EXPLAIN FORMATTED “ + query).show(false)
- 19. Seven Major Changes for SQL Performance 1. New EXPLAIN format 2. All type of join hints 3. Adaptive query execution 4. Dynamic partitioning pruning 5. Enhanced nested column pruning & pushdown 6. Improved aggregation code generation 7. New Scala and Java 19 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki Interactions with developers
- 20. Only One Join Type Can be Used on Spark 2.4 ▪ 20 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki SPARK-27225 Join type 2.4 Broadcast BROADCAST Sort Merge X Shuffle Hash X Cartesian X
- 21. All of Join Type Can be Used for a Hint ▪ 21 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki SPARK-27225 Join type 2.4 3.0 Broadcast BROADCAST BROADCAST Sort Merge X SHUFFLE_MERGE Shuffle Hash X SHUFFLE_HASH Cartesian X SHUFFLE_REPLICATE_NL Examples SELECT /*+ SHUFFLE_HASH(a, b) */ * FROM a, b WHERE a.a1 = b.b1 val shuffleHashJoin = aDF.hint(“shuffle_hash”) .join(bDF, aDF(“a1”) === bDF(“b1”))
- 22. Seven Major Changes for SQL Performance 1. New EXPLAIN format 2. All type of join hints 3. Adaptive query execution 4. Dynamic partitioning pruning 5. Enhanced nested column pruning & pushdown 6. Improved aggregation code generation 7. New Scala and Java 22 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki Dynamic optimizations
- 23. Automatically Tune Parameters for Join and Reduce ▪ Three parameters by using runtime statistics information (e.g. data size) 1. Set the number of reducers to avoid wasting memory and I/O resource 2. Select better join strategy to improve performance 3. Optimize skewed join to avoid imbalance workload 23 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki SPARK-23128 & 30864 Yield 8x performance improvement of Q77 in TPC-DS Source: Adaptive Query Execution: Speeding Up Spark SQL at Runtime Without manual tuning properties run-by-run
- 24. Used Preset Number of Reduces on Spark 2.4 ▪ The number of reducers is set based on the property spark.sql.shuffle.partitions (default: 200) 24 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki SPARK-23128 & 30864 One task includes five types to be grouped Five reducers for five partitions Reducer 0 Reducer 1 Reducer 2 Reducer 3 Reducer 4
- 25. Tune the Number of Reducers on Spark 3.0 ▪ Select the number of reducers to meet the given target partition size at each reducer 25 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki SPARK-23128 & 30864 spark.sql.adaptive.enabled -> true (false in Spark 3.0) spark.sql.adaptive.coalescePartitions.enabled -> true (false in Spark 3.0) Three reducers for five partitions
- 26. Statically Selected Join Strategy on Spark 2.4 ▪ Spark 2.4 decided sort merge join strategy using statically available information (e.g. 100GB and 80GB) 26 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki SPARK-23128 & 30864 Filter Shuffle Sort merge Join 80GB ??? Sort Scan table2 Shuffle Scan table1 Sort 100GB
- 27. Dynamically Change Join Strategy on Spark 3.0 ▪ Spark 3.0 dynamically select broadcast hash join strategy using runtime information (e.g. 80MB) 27 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki SPARK-23128 & 30864 Shuffle Scan table1 Filter ShuffleSort Sort merge Join 100GB 80GB 80MB Sort Scan table2 Shuffle Scan table1 Filter Broadcast Broadcast hash Join Scan table2 spark.sql.adaptive.enabled -> true (false in Spark 3.0)
- 28. Skewed Join is Slow on Spark 2.4 ▪ The join time is dominated by processing the largest partition 28 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki SPARK-23128 & 30864 Table BTable A Partition 2 Partition 0 Partition 1 Join table A and table B
- 29. Skewed Join is Faster on Spark 3.0 ▪ The large partition is split into multiple partitions 29 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki SPARK-23128 & 30864 Table BTable A Partition 2 Partition 0 Partition 1 Join table A and table B spark.sql.adaptive.enabled -> true (false in Spark 3.0) spark.sql.adaptive.skewJoin.enabled-> true (false in Spark 3.0) Partition 3 Split Duplicate
- 30. Seven Major Changes for SQL Performance 1. New EXPLAIN format 2. All type of join hints 3. Adaptive query execution 4. Dynamic partitioning pruning 5. Enhanced nested column pruning & pushdown 6. Improved aggregation code generation 7. New Scala and Java 30 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki
- 31. Dynamic Partitioning Pruning ▪ Avoid to read unnecessary partitions in a join operation – By using results of filter operations in another table ▪ Dynamic filter can avoid to read unnecessary partition 31 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki SPARK-11150 Source: Dynamic Partition Pruning in Apache Spark Yield 85x performance improvement of Q98 in TPC-DS 10TB
- 32. Naïve Broadcast Hash Join on Spark 2.4 ▪ All of the data in Large table is read 32 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki SPARK-11150 Broadcast Table small Table large filter Broadcast hash join FileScan
- 33. Prune Data with Dynamic Filter on Spark 3.0 ▪ Large table can reduce the amount of data to be read using pushdown with dynamic filter 33 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki SPARK-11150 Broadcast Table small Table large filter FileScan with pushdown Broadcast hash join FileScan
- 34. Example of Dynamic Partitioning Pruning 34 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki SPARK-11150 scala> spark.range(7777).selectExpr("id", "id AS key").write.partitionBy("key").saveAsTable("tableLarge") scala> spark.range(77).selectExpr("id", "id AS key").write.partitionBy("key").saveAsTable("tableSmall") scala> val query = "SELECT * FROM tableLarge JOIN tableSmall ON tableLarge.key = tableSmall.key AND tableSmall.id < 3" scala> sql("EXPLAIN FORMATTED " + query).show(false) |== Physical Plan == * BroadcastHashJoin Inner BuildRight (8) :- * ColumnarToRow (2) : +- Scan parquet default.tablelarge (1) +- BroadcastExchange (7) +- * Project (6) +- * Filter (5) +- * ColumnarToRow (4) +- Scan parquet default.tablesmall (3) (1) Scan parquet default.tablelarge Output [2]: [id#19L, key#20L] Batched: true Location: InMemoryFileIndex [file:/home/ishizaki/Spark/300RC1/spark-3.0.0-bin-hadoop2.7/spark- warehouse/tablelarge/key=0, ... 7776 entries] PartitionFilters: [isnotnull(key#20L), dynamicpruningexpression(key#20L IN dynamicpruning#56)] ReadSchema: struct<id:bigint> Source: Quick Overview of Upcoming Spark 3.0
- 35. Seven Major Changes for SQL Performance 1. New EXPLAIN format 2. All type of join hints 3. Adaptive query execution 4. Dynamic partitioning pruning 5. Enhanced nested column pruning & pushdown 6. Improved aggregation code generation 7. New Scala and Java 35 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki Catalyst improvements
- 36. Nested Column Pruning on Spark 2.4 ▪ Column pruning that read only necessary column for Parquet – Can be applied to limited operations (e.g. LIMIT) 36 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki SPARK-25603 & 25556 Source: #23964 Project Limit col1 col2 _1 _2
- 37. Limited Nested Column Pruning on Spark 2.4 ▪ Column pruning that read only necessary column for Parquet – Can be applied to limited operations (e.g. LIMIT) – Cannot be applied other operations (e.g. REPARTITION) 37 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki SPARK-25603 & 25556 Source: #23964 Project Limit col1 col2 _1 _2 Project Repartition col1 col2 _1 _2 Project
- 38. Generalize Nested Column Pruning on Spark 3.0 ▪ Nested column pruning can be applied to all operators – e.g. LIMITS, REPARTITION, … 38 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki SPARK-25603 & 25556 Project Repartition col1 col2 _1 _2 Source: #23964
- 39. Example of Nested Column Pruning ▪ Parquet only reads col2._1, as shown in ReadSchema 39 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki SPARK-25603 & 25556 == Physical Plan == Exchange RoundRobinPartitioning(1) +- *(1) Project [col2#5._1 AS _1#11L] +- *(1) FileScan parquet [col2#5] ..., PushedFilters: [], ReadSchema: struct<col2:struct<_1:bigint>> scala> sql("SELECT col2._1 FROM (SELECT /*+ REPARTITION(1) */ col2 FROM temp)").explain Source: #23964 scala> spark.range(1000).map(x => (x, (x, s"$x" * 10))).toDF("col1", "col2").write.parquet("/tmp/p") scala> spark.read.parquet("/tmp/p").createOrReplaceTempView("temp") scala> sql("SELECT col2._1 FROM (SELECT col2 FROM tp LIMIT 1000000)").explain == Physical Plan == CollectLimit 1000000 +- *(1) Project [col2#22._1 AS _1#28L] +- *(1) FileScan parquet [col2#22] ..., ReadSchema: struct<col2:struct<_1:bigint>> LIMIT Repartition
- 40. No Nested Column Pushdown on Spark 2.4 ▪ Parquet cannot apply predication pushdown 40 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki SPARK-25603 & 25556 scala> spark.range(1000).map(x => (x, (x, s"$x" * 10))).toDF("col1", "col2").write.parquet("/tmp/p") scala> spark.read.parquet(“/tmp/p”).filter(“col2._1 = 100").explain == Physical Plan == *(1) Project [col1#12L, col2#13] +- *(1) Filter (isnotnull(col2#13) && (col2#13._1 = 100)) +- *(1) FileScan parquet [col1#12L,col2#13] ..., PushedFilters: [IsNotNull(nested)], ... Spark 2.4 Project col1 col2 _1 _2 Filter Source: #28319 All data rows only if col2._1=100
- 41. Nested Column Pushdown on Spark 3.0 ▪ Parquet can apply pushdown filter and can read part of columns 41 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki SPARK-25603 & 25556 scala> spark.range(1000).map(x => (x, (x, s"$x" * 10))).toDF("col1", "col2").write.parquet("/tmp/p") scala> spark.read.parquet(“/tmp/p”).filter(“col2._1 = 100").explain Spark 3.0 == Physical Plan == *(1) Project [col1#0L, col2#1] +- *(1) Filter (isnotnull(col2#1) AND (col2#1._1 = 100)) +- FileScan parquet [col1#0L,col2#1] ..., DataFilters: [isnotnull(col2#1), (col2#1.x = 100)], ..., PushedFilters: [IsNotNull(col2), EqualTo(col2._1,100)], ... Project col1 col2 _1 _2 Filter Source: #28319 chunks including col2._1=100 rows only if col2._1=100
- 42. Seven Major Changes for SQL Performance 1. New EXPLAIN format 2. All type of join hints 3. Adaptive query execution 4. Dynamic partitioning pruning 5. Enhanced nested column pruning & pushdown 6. Improved aggregation code generation 7. New Scala and Java 42 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki
- 43. Complex Aggregation is Slow on Spark 2.4 ▪ A complex query is not compiled to native code 43 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki SPARK-21870 Not good performance of Q66 in TPC-DS Source: #20695
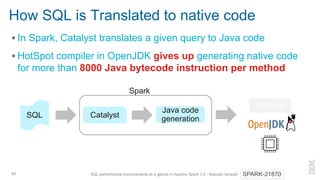
- 44. How SQL is Translated to native code ▪ In Spark, Catalyst translates a given query to Java code ▪ HotSpot compiler in OpenJDK translates Java code into native code 44 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki SPARK-21870 Catalyst Java code generationSQL Spark HotSpot
- 45. How SQL is Translated to native code ▪ In Spark, Catalyst translates a given query to Java code ▪ HotSpot compiler in OpenJDK gives up generating native code for more than 8000 Java bytecode instruction per method 45 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki SPARK-21870 Catalyst Java code generationSQL Spark HotSpot
- 46. Making Aggregation Java Code Small ▪ In Spark, Catalyst translates a given query to Java code ▪ HotSpot compiler in OpenJDK gives up generating native code for more than 8000 Java bytecode instruction per method 46 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki SPARK-21870 Catalyst splits a large Java method into small ones to allow HotSpot to generate native code
- 47. Example of Small Aggregation Code ▪ Average function (100 rows) for 50 columns 47 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki SPARK-21870 scala> val numCols = 50 scala> val colExprs = (0 until numCols).map { i => s"id AS col$i" } scala> spark.range(100).selectExpr(colExprs: _*).createOrReplaceTempView("temp”) scala> val aggExprs = (0 until numCols).map { I => s”AVG(col$i)" } scala> val query = s"SELECT ${aggExprs.mkString(", ")} FROM temp“ scala> import org.apache.spark.sql.execution.debug._ scala> sql(query).debugCodegen() Found 2 WholeStageCodegen subtrees. == Subtree 1 / 2 (maxMethodCodeSize:3679; maxConstantPoolSize:1107(1.69% used); numInnerClasses:0) == ... == Subtree 2 / 2 (maxMethodCodeSize:5581; maxConstantPoolSize:882(1.35% used); numInnerClasses:0) == Source: PR #20965
- 48. Example of Small Aggregation Code ▪ Average function (100 rows) for 50 columns 48 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki SPARK-21870 scala> val numCols = 50 scala> val colExprs = (0 until numCols).map { i => s"id AS col$i" } scala> spark.range(100).selectExpr(colExprs: _*).createOrReplaceTempView("temp”) scala> val aggExprs = (0 until numCols).map { I => s”AVG(col$i)" } scala> val query = s"SELECT ${aggExprs.mkString(", ")} FROM temp“ scala> import org.apache.spark.sql.execution.debug._ scala> sql(query).debugCodegen() Found 2 WholeStageCodegen subtrees. == Subtree 1 / 2 (maxMethodCodeSize:3679; maxConstantPoolSize:1107(1.69% used); numInnerClasses:0) == ... == Subtree 2 / 2 (maxMethodCodeSize:5581; maxConstantPoolSize:882(1.35% used); numInnerClasses:0) == ... scala> sql("SET spark.sql.codegen.aggregate.splitAggregateFunc.enabled=false") scala> sql(query).debugCodegen() Found 2 WholeStageCodegen subtrees. == Subtree 1 / 2 (maxMethodCodeSize:8917; maxConstantPoolSize:957(1.46% used); numInnerClasses:0) == ... == Subtree 2 / 2 (maxMethodCodeSize:9862; maxConstantPoolSize:728(1.11% used); numInnerClasses:0) == ... Disable this feature Source: PR #20965
- 49. Seven Major Changes for SQL Performance 1. New EXPLAIN format 2. All type of join hints 3. Adaptive query execution 4. Dynamic partitioning pruning 5. Enhanced nested column pruning & pushdown 6. Improved aggregation code generation 7. New Scala and Java 49 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki Infrastructure updates
- 50. Support New Versions of Languages ▪ Java 11 (the latest Long-Term-Support of OpenJDK from 2018 to 2026) – Further optimizations in HotSpot compiler – Improved G1GC (for large heap) – Experimental new ZGC (low latency) ▪ Scala 2.12 (released on 2016 Nov.) – Newly designed for leveraging Java 8 new features 50 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki SPARK-24417 & 25956 NOTE: Other class libraries are also updated
- 51. Takeaway ▪ Spark 3.0 improves SQL application performance 1. New EXPLAIN format 2. All type of join hints 3. Adaptive query execution 4. Dynamic partitioning pruning 5. Enhanced nested column pruning & pushdown 6. Improved aggregation code generation 7. New Scala and Java 51 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki Please visit https://www.slideshare.net/ishizaki/ tomorrow if you want to see this slide again
- 52. Resources ▪ Introducing Apache Spark 3.0: Now available in Databricks Runtime 7.0 – https://databricks.com/jp/blog/2020/06/18/introducing-apache-spark-3-0- now-available-in-databricks-runtime-7-0.html ▪ Now on Databricks: A Technical Preview of Databricks Runtime 7 Including a Preview of Apache Spark 3.0 – https://databricks.com/blog/2020/05/13/now-on-databricks-a-technical- preview-of-databricks-runtime-7-including-a-preview-of-apache-spark-3- 0.html ▪ Quick Overview of Upcoming Spark 3.0 (in Japanese) – https://www.slideshare.net/maropu0804/quick-overview-of-upcoming- spark-3052 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki
- 53. Resources… ▪ Madhukar’s Blog – https://blog.madhukaraphatak.com/ ▪ Adaptive Query Execution: Speeding Up Spark SQL at Runtime – https://databricks.com/blog/2020/05/29/adaptive-query-execution- speeding-up-spark-sql-at-runtime.html ▪ Dynamic Partition Pruning in Apache Spark – https://databricks.com/session_eu19/dynamic-partition-pruning-in- apache-spark 53 SQL performance improvements at a glance in Apache Spark 3.0 - Kazuaki Ishizaki