Start with version control and experiments management in machine learning
1 like102 views

The document outlines a workflow for managing version control and reproducible experiments in machine learning projects, emphasizing the importance of automated pipelines, artifact versioning, and environment control. It includes practical steps and a checklist for achieving reproducibility, alongside a use case for a dog and cat classifier project. The document also highlights the benefits of discipline and organization within teams for enhancing project performance.

![ML reproducibility is a dimension of quality
4
What is Reproducibility?
using the original methods applied to
the original data to produce the
original results [Gardner]
Why should you care?
● Trust
● Consistent Results
● Versioned History
● Team Performance
● Pain Less Production
Josh Gardner, Yuming Yang, Ryan S. Baker, Christopher Brooks. Enabling End-To-End Machine
Learning Replicability: A Case Study in Educational Data Mining](https://image.slidesharecdn.com/rozhkovstartwithversioncontrolandexperimentsmanagementinmachinelearningminskdatafest2019en-190728080300/85/Start-with-version-control-and-experiments-management-in-machine-learning-4-320.jpg)















![Metrics tracking in mlflow UI
21
from mlflow import log_metric, log_param,
log_artifact
log_artifact(args.config)
log_param('batch_size', config['batch_size'])
log_metric('f1', f1)
log_metric('roc_auc', roc_auc)](https://image.slidesharecdn.com/rozhkovstartwithversioncontrolandexperimentsmanagementinmachinelearningminskdatafest2019en-190728080300/85/Start-with-version-control-and-experiments-management-in-machine-learning-21-320.jpg)




Start with version control and experiments management in machine learning
- 1. Start with version control and experiments management in ML: reproducible experiments Data Fest3 Minsk, 2019 1 Mikhail Rozhkov
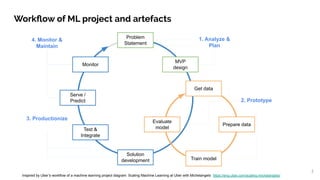
- 2. 2 Workflow of ML project and artefacts Problem Statement MVP design Get data Prepare data Train model Evaluate modelTest & Integrate Serve / Predict Monitor 1. Analyze & Plan 2. Prototype 4. Monitor & Maintain 3. Productionize Inspired by Uber’s workflow of a machine learning project diagram. Scaling Machine Learning at Uber with Michelangelo https://eng.uber.com/scaling-michelangelo/ Solution development
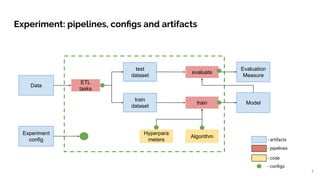
- 3. Experiment: pipelines, configs and artifacts Algorithm Data Hyperpara meters Evaluation Measure Model ETL tasks test dataset train dataset evaluate train Experiment config - artifacts - pipelines - code - configs 3
- 4. ML reproducibility is a dimension of quality 4 What is Reproducibility? using the original methods applied to the original data to produce the original results [Gardner] Why should you care? ● Trust ● Consistent Results ● Versioned History ● Team Performance ● Pain Less Production Josh Gardner, Yuming Yang, Ryan S. Baker, Christopher Brooks. Enabling End-To-End Machine Learning Replicability: A Case Study in Educational Data Mining
- 5. Is a “magic button”? 5
- 6. ML Reproducibility 1. Automated pipelines 2. Control run params 3. Control execution DAG 4. Code version control 5. Artifacts version control (models, datasets, etc.) 6. Use shared/cloud storage for artifacts 7. Environment dependencies control 6
- 7. How to start? step 1 step 2 step 3 step 4 Manual work Automated work Time on DS task 100% 0% 10% 90% 10% 90% 90% 7
- 8. Start with artifacts versioning! Algorithm Data Hyperpara meters Evaluation Measure Model ETL tasks test dataset train dataset evaluate train Experiment config 8
- 9. Use Case: dogs and cats classifier ● Project ○ Classify dogs and cats by photo ○ Datat ■ object: cats, dogs ■ dogs: 12500 ■ cats: 12500 ○ Metrics: accuracy, ROC-AUC 9 ● Team ○ > 2 members ○ different machines/servers ○ different OS ○ git-flow dev process ○ run on one machine
- 10. Step 1: Jupyter Notebook ● code in Jupyter Notebook ● everything in Docker 10
- 11. ML Reproducibility checklist 11 1. Automated pipelines 2. Control run params 3. Control execution DAG 4. Code version control 5. Artifacts version control (models, datasets, etc.) 6. Use shared/cloud storage for artifacts 7. Environment dependencies control 8. Experiments results tracking
- 12. Step 2: build pipelines ● move common code into .py modules ● build pipelines ● everything in Docker ● run experiments in terminal or Jupyter Notebook 12
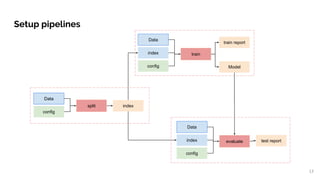
- 13. Model train train report index Data config evaluate test reportindex Data config split index Data config Setup pipelines 13
- 14. ML Reproducibility checklist 14 1. Automated pipelines 2. Control run params 3. Control execution DAG 4. Code version control 5. Artifacts version control (models, datasets, etc.) 6. Use shared/cloud storage for artifacts 7. Environment dependencies control 8. Experiments results tracking
- 15. Step 3: add version control for artifacts 15 ● add models/data/congis under DVC control ● same code in .py modules ● same pipelines ● everything in Docker ● run experiments in terminal or Jupyter Notebook
- 16. ML Reproducibility checklist 16 1. Automated pipelines 2. Control run params 3. Control execution DAG 4. Code version control 5. Artifacts version control (models, datasets, etc.) 6. Use shared/cloud storage for artifacts 7. Environment dependencies control 8. Experiments results tracking
- 17. Step 4: add execution DAG control ● add pipelines dependencies under DVC control ● models/data/congis under DVC control ● same code in .py modules ● same pipelines ● everything in Docker ● run experiments in terminal or Jupyter Notebook 17
- 18. Experiment config train config eval config split config prepare config Model train train report index Data config evaluate test reportindex Data config split index Data config Setup pipelines 18
- 19. ML Reproducibility checklist 19 1. Automated pipelines 2. Control run params 3. Control execution DAG 4. Code version control 5. Artifacts version control (models, datasets, etc.) 6. Use shared/cloud storage for artifacts 7. Environment dependencies control 8. Experiments results tracking
- 20. Step 5: add experiments control ● add experiments benchmark (DVC, mlflow) ● pipelines dependencies under DVC control ● models/data/congis under DVC control ● same code in .py modules ● same pipelines ● everything in Docker ● run experiments in terminal or Jupyter Notebook 20
- 21. Metrics tracking in mlflow UI 21 from mlflow import log_metric, log_param, log_artifact log_artifact(args.config) log_param('batch_size', config['batch_size']) log_metric('f1', f1) log_metric('roc_auc', roc_auc)
- 23. ML Reproducibility checklist 23 1. Automated pipelines 2. Control run params 3. Control execution DAG 4. Code version control 5. Artifacts version control (models, datasets, etc.) 6. Use shared/cloud storage for artifacts 7. Environment dependencies control 8. Experiments results tracking
- 24. Conclusions 1. pipelines - not difficult 2. start where you detect a “copy-paste” pattern 3. artifacts version control - MUST 4. discipline in a team is important 5. more benefits for high complexity and large team projects 24
- 25. Contact me 25 Mikhail Rozhkov mail: [email protected] ods: @Mikhail Rozhkov