Storing and processing data with the wso2 platform
1 like3,267 views

The document discusses data storage and processing challenges posed by large amounts of data, and different solutions for structuring and scaling data, including: 1) Relational databases face scaling issues, while NoSQL databases like key-value and column-family stores are more scalable. 2) The type of data determines the best solution - for example, using graph databases for relationship data and distributed file systems for unstructured data. 3) Highly scalable systems require loosening consistency requirements and cannot support transactions or joins across thousands of nodes according to the CAP theorem. Hybrid approaches may be needed for complex data needs.











































Storing and processing data with the wso2 platform
- 1. Storing and processing data with the WSO2 Platform Deependra Ariyadewa Wathsala Vithanage
- 2. WSO2 • Founded in 2005 by acknowledged leaders in XML, Web Services Technologies & Standards and Open Source • Producing entire middleware platform 100% open source under Apache license • Business model is to sell comprehensive support & maintenance for our products • Venture funded by Intel Capital and Quest Software. • Global corporation with offices in USA, UK & Sri Lanka • 150+ employees and growing.
- 3. Introduction to Data Problem • Information explosion o Rapid growth of published data. o Managing large amounts of data is difficult (this leads to an information overload) o Difficulties include Capture Storage Search Sharing Analytics Visualization o We need new tools to deal with BIG DATA.
- 4. The Well Known Data Solution RDBMS • For many years this has been the choice • Scaling up RDBMS o Put it in a bigger computer o Replicate database over 2 - 3 nodes. This does not work well with more than 2 - 3 nodes. o Partition data over several nodes. Although JOIN queries are hard across many nodes, may require custom code and configuration. Transactions may not scale well.
- 5. CAP Theorem and RDBMS • RDBMS has two key features o Relational Model with SQL o ACID transactions (Atomic, Consistent, Isolation & Durable) • CAP theorem states that in distributed systems it is only possible to have two properties out of the properties Consistency, Availability & Partition Tolerance at any given time. o Once you have picked two properties you will loose the remaining one. • But there are some applications that do not need all the properties of RDBMS. Once these are dropped system scales. (e.g. Google Big Tables)
- 6. Rise of NoSQL • Large internet companies hit the problem first, they build systems that are specific to their problem, and they did scale. o Google Big table o Amazon Dynamo • Soon many others followed, and most of them are free and open source. • Among advantages of NoSQL are o Scalability o Flexible schema o Designed to scale and support fault tolerance out of the Box
- 7. Finding the right Data Solution • Data Types o Unstructured Data Files o Semi Structured Data XML Databases, Queues, Graphs and Lists o Structured Data DBMS
- 8. Handling Unstructured Data • Storage Options o Key - Value storages for small data items o Distributed file systems for other cases o Metadata Registries (Nirvana, SDSC Resource broker) • Scalability o Key - Value storages are highly Scalable (e.g. Amazon Dynamo) o Distributed File Systems are generally scalable (HDFS, Lustre) o Metadata Registries are also highly scalable • Search o Each of above provide key based retrieval o Metadata registries provide property based search. o It is possible to build a index for content using tools like Lucence and use that for search.
- 9. Handling Semi-Structured Data • Storage Options o Answer depends on the type of structure. (e.g. XML = XML Databases, Graphs = Graph Databases, List = Data structure servers, work items = Queue) o If there is a server optimized for a given type, it is often much more efficient than using a DB. (e.g. Graph databases can support fast relationship search) • Scalabilty o XML databases can shared data across nodes, so usually scalable, but others are not that scalable • Search o Very much custom. E.g. XML or any tree = XPath o Graph can support very fast relationship search
- 10. Handling Structured Data (1-3 nodes) • In general using DB here Small (1-3 nodes) for every case might Loose Operation Transactions Consistency Consistency work. Primary Key DB/ KV/ CF DB/ KV/ CF DB • Reason for using options other than DB Where DB/ CF/Doc DB/ CF/Doc DB • When there is JOIN DB DB DB potential need to scale Offline DB/CF/Doc DB/CF/Doc DB/CF/Doc later. • High write throughput • KV is 1-D where as other two are 2D *KV: Key-Value Systems, CF: Column Families, Doc: document based Systems
- 11. Handling Structured Data (10 nodes) • KV, CF, and Doc can easily handle Scalable (10 nodes) this case. Loose Operation Transactions Consistency Consistency • If DBs used with data shredded across many nodes. Primary Key KV/CF KV/CF Partitioned DB? • Transactions might work with Where CF/Doc CF/Doc Partitioned given that participants on one DB? transaction are not too many. JOIN ?? ?? Partitioned • JOINs might need to transfer too DB?? much data between nodes. Offline CF/Doc CF/Doc No • Also should consider in Memory DBs like Vault DB • Offline mode will work • Most systems let users choose *KV: Key-Value Systems, CF: Column consistency, and loose consistency Families, Doc: document based can scale more. (e.g. Cassandra) Systems
- 12. Highly Scalable System • Transactions does not work in this scale. Highly Scalable (1000s nodes) (CAP theorem). • Same for the JOIN. Problem is sometime Loose Operation Transactions Consistency Consistency too much data needs to be transferred Primary KV/CF KV/CF No between nodes to perform the JOIN. Key • Offline case handled through Map- Where CF/Doc CF/Doc No Reduce. Even JOIN case is OK since there is time. JOIN No No No Offline CF/Doc CF/Doc No *KV: Key-Value Systems, CF: Column Families, Doc: document based Systems
- 13. Highly Scalable Systems + Primary Key Retrieval • This is (comparatively) the easy one. Highly Scalable (1000s nodes) Loose Operation Transactions • Can be solved through DHT Consistency Consistency (Distributed Hash table) based solutions Primary KV/CF KV/CF No or architectures like OceanStore. Key Where CF/Doc(?) CF/Doc(?) No • Both Key-Value Storages(KV) and JOIN No No No Column Families (CF) can be used. But Key-Value model is preferred as it is Offline CF/Doc CF/Doc No more scalable. *KV: Key-Value Systems, CF: Column Families, Doc: document based Systems
- 14. Highly scalable systems + WHERE • This Generally OK, but tricky. Highly Scalable (1000s nodes) Loose Operation Transactions • CF work through a Secondary index that Consistency Consistency do Scatter-gather (e.g. Cassandra). Primary KV/CF KV/CF No Key • Doc work through Map-Reduce views Where CF/Doc(?) CF/Doc(?) No (e.g. CouchDB). JOIN No No No • There is Bissa, which build a index for all possible queries (No range queries) Offline CF/Doc CF/Doc No • If you are doing this, you should do pilot runs and make sure things work. *KV: Key-Value Systems, CF: Column Families, Doc: document based Systems
- 15. Hybrid Approaches • Some solution have many types of data and hence need more than one data solution (hybrid architectures). • For example o Using DB for transactional data and CF for other data. o Keeping metadata and actual data separate for large data archives. o Use GraphDB to store relationship data while other while other data is in Column family storage. • However, if transactions are needed, transactions have to be handled outside storages (e.g. using Atomicas, Zookeeper ).
- 16. Other Parameters • Above list is not exhaustive, and there are other parameters o Read/Write ratio - when high, easy to scale. o High write throughput. o Very large data products - you will need a file system. May be keep metadata in Data registry and store data in a file system. o Flexible schema. o Archival usecases o Analytical usecases o Others ...
- 17. WSO2 Data Solutions • Data Service Server - DSS • Relational Storage Service - RSS • Column Store Service - CSS • File System as a service ( FSaaS) - HDFS • DSS and RSS • DSS and CSS
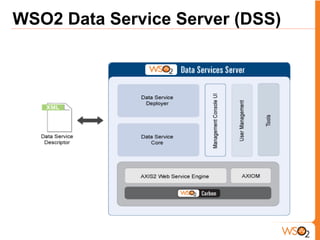
- 18. WSO2 Data Service Server (DSS)
- 19. WSO2 Data Service Server (DSS) Support for large XML outputs Content Filtering based on User's role Support for named parameters Ability to configure schema type for output elements Mixing multiple data sources in nested queries Distributed transaction support Oracle Ref Cursor support Support for multiple data source types Clustering support for High Availability and High Scalability Full support for WS-Security, WS-Trust, WS-Policy and WS-Secure Conversation and XKMS JMX and Web interface based monitoring and management WS-* and REST support Data validations UDT (User Defined Type) Support Complex Results Auto Generated Keys Support Boxcarring Support Batch Request Support Scheduled Tasks Registry Integration for Excel,CSV,XSLT Web Scraping Support Multiple SQL Dialect Support DB -> DS Generation Service Group/Hierarchy Support Database Explorer Data as a Service Features - DSS Stratos Service o Cassandra Integration o RDS Provisioning
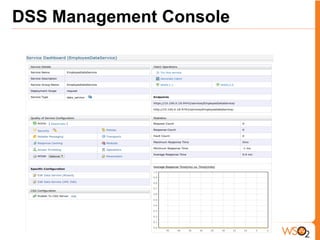
- 20. WSO2 Data Service Server (DSS)
- 21. Data Services Description Language - DSDL
- 23. WSO2 Stratos Support for Relational Data • Offering a “database as as service” for tenants WSO2 Relational Storage Service • Users create database and receive JDBC URL • Database is allocated from Amazon RDS (MySQL) horizontal cluster • Tenants are isolated from each other and integrated with platform security model
- 24. WSO2 Relational Storage Service • Use your own database server (anywhere) • Register database connection as a datasource Use RSS to allocate a database
- 25. Stratos RSS
- 26. Stratos RSS
- 27. Stratos RSS
- 28. RSS Sample
- 29. WSO2 Column Store Service - CSS Users can log in to the Web Console and create Cassandra key spaces.
- 30. Column Store Service (Contd.) • Key spaces will be allocated from a Cassandra clusters • Users can manage and share his key spaces through Stratos Web Console and use those key spaces through Hector Client (Java Client for Cassandra) • In essence we provide Cassandra as a part of Stratos as a Service with Multi-tenancy support and Security integration with WSO2 security model
- 31. WSO2 CSS Admin Console Left Menu Keyspace View
- 32. WSO2 CSS Admin Console Keyspace Connection Details
- 33. WSO2 CSS Sample
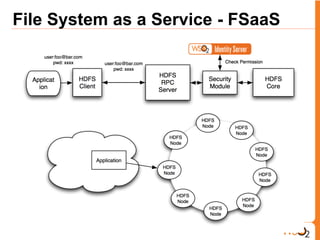
- 34. File System as a Service - FSaaS
- 35. File System as a Service - FSaaS The volume will be allocated from a HDFS cluster they are isolated from other tenants in Stratos it is integrated with WSO2 Security model. Users can manage and share his File system through Stratos Web Console and use the file system like any other file system.
- 36. FSaaS Sample
- 37. Data Processing - Mapreduce • Mapreduce is inspired by map and reduce functions used in functional programming. o Initially introduced by Google with some parts being patented. • Hadoop is a Mapreduce implementation that comes under Apache license agreement. • WSO2 provides Mapreduce as a service. • WSO2 Business Activity Monitor (BAM2) is an example use- case for WSO2's Mapreduce as a service.
- 38. WSO2 Mapreduce • WSO2 Mapreduce is secure. • WSO2 Mapreduce can use both FSaaS and DSS. o HDFS (FSaaS) o Cassendra (DSS)
- 39. WSO2 Mapreduce
- 40. WSO2 Mapreduce
- 41. WSO2 Mapreduce
- 42. WSO2 Mapreduce
- 43. WSO2 Mapreduce
- 44. WSO2 Mapreduce
- 45. Q&A
- 46. WSO2 • Founded in 2005 by acknowledged leaders in XML, Web Services Technologies & Standards and Open Source • Producing entire middleware platform 100% open source under Apache license • Business model is to sell comprehensive support & maintenance for our products • Venture funded by Intel Capital and Quest Software. • Global corporation with offices in USA, UK & Sri Lanka • 150+ employees and growing.
- 47. Selected Customers https://ail.google.com/mail/u/0/?ui=2&i k=ad9ae58f41&view=att&th=1331a70 983344a32&attid=0.1&disp=thd&reala ttid=f_gtxto6mk0&zw
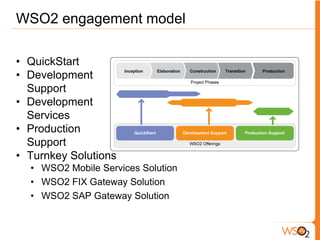
- 48. WSO2 engagement model • QuickStart • Development Support • Development Services • Production Support • Turnkey Solutions • WSO2 Mobile Services Solution • WSO2 FIX Gateway Solution • WSO2 SAP Gateway Solution