Supercharging your Apache OODT deployments with the Process Control System
Download as PPT, PDF2 likes1,581 views

The document discusses the Process Control System (PCS), a component of the Apache OODT framework. PCS provides capabilities for data management, pipeline processing, and resource management. It has been deployed for several NASA Earth science missions to automate processing and manage large volumes of science data. Customizing PCS for a new mission involves configuring servers, specifying product metadata and processing rules, and defining compute resource policies.
![Supercharging your Apache OODT deployments with the Process Control System Chris A. Mattmann NASA JPL/Univ. Southern California/ASF [email_address] November 9, 2011](https://image.slidesharecdn.com/mattmannsuperchargingpcs-111111002205-phpapp02/85/Supercharging-your-Apache-OODT-deployments-with-the-Process-Control-System-1-320.jpg)

















































![OODT Project Contact Info Learn more and track our progress at: http://oodt.apache.org WIKI: https://cwiki.apache.org/OODT / JIRA: https://issues.apache.org/jira/browse/OODT Join the mailing list: [email_address] Chat on IRC: #oodt on irc.freenode.net Acknowledgements Key Members of the OODT teams: Chris Mattmann, Daniel J. Crichton, Steve Hughes, Andrew Hart, Sean Kelly, Sean Hardman, Paul Ramirez, David Woollard, Brian Foster, Dana Freeborn, Emily Law, Mike Cayanan, Luca Cinquini, Heather Kincaid Projects, Sponsors, Collaborators: Planetary Data System, Early Detection Research Network, Climate Data Exchange, Virtual Pediatric Intensive Care Unit, NASA SMAP Mission, NASA OCO-2 Mission, NASA NPP Sounder Peate, NASA ACOS Mission, Earth System Grid Federation](https://image.slidesharecdn.com/mattmannsuperchargingpcs-111111002205-phpapp02/85/Supercharging-your-Apache-OODT-deployments-with-the-Process-Control-System-53-320.jpg)
![Alright, I ’ll shut up now Any questions? THANK YOU! [email_address] @chrismattmann on Twitter](https://image.slidesharecdn.com/mattmannsuperchargingpcs-111111002205-phpapp02/85/Supercharging-your-Apache-OODT-deployments-with-the-Process-Control-System-54-320.jpg)
Supercharging your Apache OODT deployments with the Process Control System
- 1. Supercharging your Apache OODT deployments with the Process Control System Chris A. Mattmann NASA JPL/Univ. Southern California/ASF [email_address] November 9, 2011
- 2. Apache Member involved in OODT (VP, PMC), Tika (VP,PMC), Nutch (PMC), Incubator (PMC), SIS (Mentor), Lucy (Mentor) and Gora (Champion), MRUnit (Mentor), Airavata (Mentor) Senior Computer Scientist at NASA JPL in Pasadena, CA USA Software Architecture/Engineering Prof at Univ. of Southern California And you are?
- 3. Welcome to the Apache in Space! (OODT) Track
- 4. Agenda Overview of OODT and its history What is the Process Control System (PCS)? PCS Architecture Some hands on examples Health Monitoring Pedigree/Provenance Deploying PCS Where we’re headed
- 5. Lessons from 90’s era missions Increasing data volumes (exponential growth) Increasing complexity of instruments and algorithms Increasing availability of proxy/sim/ancillary data Increasing rate of technology refresh … all of this while NASA Earth Mission funding was decreasing A data system framework based on a standard architecture and reusable software components for supporting all future missions.
- 6. Enter OODT Object Oriented Data Technology http://oodt.apache.org Funded initially in 1998 by NASA ’s Office of Space Science Envisaged as a national software framework for sharing data across heterogeneous, distributed data repositories OODT is both an architecture and a reference implementation providing Data Production Data Distribution Data Discovery Data Access OODT is Open Source and available from the Apache Software Foundation
- 7. Apache OODT Originally funded by NASA to focus on distributed science data system environments science data generation data capture, end-to-end Distributed access to science data repositories by the community A set of building blocks/services to exploit common system patterns for reuse Supports deployment based on a rich information model Selected as a top level Apache Software Foundation project in January 2011 Runner up for NASA Software of the Year Used for a number of science data system activities in planetary, earth, biomedicine, astrophysics http://oodt.apache.org
- 9. Why Apache and OODT? OODT is meant to be a set of tools to help build data systems It ’s not meant to be “turn key” It attempts to exploit the boundary between bringing in capability vs. being overly rigid in science Each discipline/project extends Apache is the elite open source community for software developers Less than 100 projects have been promoted to top level (Apache Web Server, Tomcat, Solr, Hadoop) Differs from other open source communities; it provides a governance and management structure
- 10. Apache OODT Community Includes PMC members from NASA JPL, Univ. of Southern California, Google, Children’s Hospital Los Angeles (CHLA), Vdio, South African SKA Project Projects that are deploying it operationally at Decadal-survey recommended NASA Earth science missions, NIH, and NCI, CHLA, USC, South African SKA project Use in the classroom My graduate-level software architecture and seach engines courses
- 11. OODT Framework and PCS OBJECT ORIENTED DATA TECHNOLOGY FRAMEWORK OODT/Science Web Tools Archive Client Profile XML Data Data System 1 Data System 2 Archive Service Profile Service Product Service Query Service Bridge to External Services Navigation Service Other Service 1 Other Service 2 Process Control System (PCS) Catalog & Archive Service (CAS) CAS has recently become known as Process Control System when applied to mission work. Catalog & Archive Service
- 12. Current PCS deployments Orbiting Carbon Observatory (OCO-2) - spectrometer instrument NASA ESSP Mission, launch date: TBD 2013 PCS supporting Thermal Vacuum Tests, Ground-based instrument data processing, Space-based instrument data processing and Science Computing Facility EOM Data Volume: 61-81 TB in 3 yrs Processing Throughput: 200-300 jobs/day NPP Sounder PEATE - infrared sounder Joint NASA/NPOESS mission, launch date: October 2011 PCS supporting Science Computing Facility (PEATE) EOM Data Volume: 600 TB in 5 yrs Processing Throughput: 600 jobs/day QuikSCAT - scatterometer NASA Quick-Recovery Mission, launch date: June 1999 PCS supporting instrument data processing and science analyst sandbox Originally planned as a 2-year mission SMAP - high-res radar and radiometer NASA decadal study mission, launch date: 2014 PCS supporting radar instrument and science algorithm development testbed
- 13. Other PCS applications Bioinformatics National Institutes of Health (NIH) National Cancer Institute ’s (NCI) Early Detection Research Network (EDRN) Children ’s Hospital LA Virtual Pediatric Intensive Care Unit (VPICU) Technology Demonstration JPL ’s Active Mirror Telescope (AMT) White Sands Missile Range Earth Science NASA ’s Virtual Oceanographic Data Center (VODC) JPL ’s Climate Data eXchange (CDX) Astronomy and Radio Prototype work on MeerKAT with South Africans and KAT-7 telescope Discussions ongoing with NRAO Socorro (EVLA and ALMA)
- 14. PCS Core Components All Core components implemented as web services XML-RPC used to communicate between components Servers implemented in Java Clients implemented in Java, scripts, Python, PHP and web-apps Service configuration implemented in ASCII and XML files
- 15. Core Capabilities File Manager does Data Management Tracks all of the stored data, files & metadata Moves data to appropriate locations before and after initiating PGE runs and from staging area to controlled access storage Workflow Manager does Pipeline Processing Automates processing when all run conditions are ready Monitors and logs processing status Resource Manager does Resource Management Allocates processing jobs to computing resources Monitors and logs job & resource status Copies output data to storage locations where space is available Provides the means to monitor resource usage
- 16. PCS Ingestion Use Case
- 18. PCS Processing Use Case
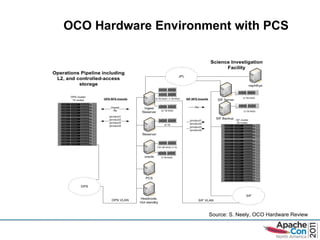
- 21. PCS Support for OCO OCO has three PCS deployments (installation of core components): Thermal Vacuum Instrument Testing deployment A PCS configuration was successfully deployed to process and analyze 100% of all L1a products generated during t-vac testing Space-based Operations & Ground-based FTS processing deployment Automatic processing of all raw instrument data through AOPD L2 algorithm Currently operational, our FTS deployment has processed over 4 TB of FTS spectrum and FTS L1a products for science analysis to data Science Computing Facility (SCF) deployment Supports all L2 full physics algorithm processing for science analysis and cal/val Supports scientists ’ investigations of alternative algorithms & data products Ability to adapt to change Scaled up the database catalog size When size grew > 1 million products, moved from Lucene to Oracle in a weekend! Had to repartition the FTS archive layout and structure 2 years into the mission Recataloged all 1 million FTS products and moved all data within a few weeks! Accommodated Ops/SCF hardware reconfiguration 1 year prior to launch Physically-shared and virtually-separated to virtually-shared and physically-separated at no extra cost!
- 22. OCO Hardware Environment with PCS Source: S. Neely, OCO Hardware Review
- 23. How do we deploy PCS for a mission? We implement the following mission-specific customizations Server Configuration Implemented in ASCII properties files Product metadata specification Implemented in XML policy files Processing Rules Implemented as Java classes and/or XML policy files PGE Configuration Implemented in XML policy files Compute Node Usage Policies Implemented in XML policy files Here ’s what we don’t change All PCS Servers (e.g. File Manager, Workflow Manager, Resource Manager) Core data management, pipeline process management and job scheduling/submission capabilities File Catalog schema Workflow Model Repository Schema
- 24. Server and PGE Configuration
- 25. What is the Level of Effort for personalizing PCS? PCS Server Configuration – “days” Deployment specific Addition of New File (Product) Type – “ days” Product metadata specification Metadata extraction (if applicable) Ingest Policy specification (if remote pull or remote push) Addition of a New PGE – (initial integration, ~ weeks) Policy specification Production rules PGE Initiation Estimates based on OCO and NPP experience
- 26. A typical PCS service (e.g., fm, wm, rm)
- 27. What’s PCS configuration? Configuration follows typical Apache-like server configuration A set of properties and flags that are set in an ASCII text file that initialize the service at runtime Properties configure The underlying subsystems of the PCS service For file manager, properties configure e.g., Data transfer chunk size Whether or not the catalog database should use quoted strings for columns What subsystems are actually chosen (e.g, database versus Lucene, remote versus local data transfer) Can we see an example?
- 28. PCS File Manager Configuration File Set runtime properties Choose extension points Sensible defaults if you don’t want to change them
- 29. What’s PCS policy? Policy is the convention in which missions define The products that should be ingested and managed The PGE default input parameters and their required data and metadata inputs (data flow) The PGE pre-conditions and execution sequence (control flow) The underlying hardware/resource environment in which PGEs should run and data/metadata should be captured What nodes are available? How much disk space is available? How should we allocate PGEs to nodes? Can we see an example?
- 30. PCS File Manager Policy for OCO FTS Products The scheme for laying out products in the archive The scheme for extracting metadata from products on the server side A name, ID an description of the each product
- 31. PCS Workflow Manager Policy for OCO FTS Products Define data flow Define control flow
- 32. PCS Overall Architecture What have we told you about so far? What are we going to tell you about now?
- 33. The concept of “production rules” Production rules are common terminology to refer to the identification of the mission specific variation points in PGE pipeline processing Product cataloging and archiving So far, we’ve discussed Configuration Policy Policy is one piece of the puzzle in production rules
- 34. Production rule areas of concerns Policy defining file ingestion What metadata should PCS capture per product? Where do product files go? Policy defining PGE data flow and control flow PGE pre-conditions File staging rules Queries to the PCS file manager service 1-5 are implemented in PCS (depending on complexity) as either: Java Code XML files Some combination of Java code and XML files
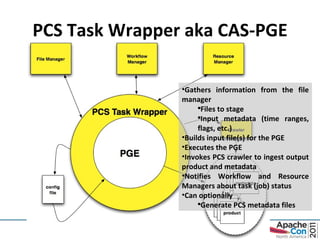
- 35. PCS Task Wrapper aka CAS-PGE Gathers information from the file manager Files to stage Input metadata (time ranges, flags, etc.) Builds input file(s) for the PGE Executes the PGE Invokes PCS crawler to ingest output product and metadata Notifies Workflow and Resource Managers about task (job) status Can optionally Generate PCS metadata files
- 36. PCS experience on recent missions How long did it take to build out the PCS configuration and policy? For OCO, once each pipeline was system engineered and PGEs were designed Level of Effort Configuration for file, resource, workflow manager : 1-2 days (1x cost) Policy for file, resource, workflow manager: 1-2 days per new PGE and new Product Type Production rules: 1 week per PGE For NPP Sounder PEATE, once each PGE was system engineered and designed Level of Effort Configuration for file, resource, workflow manager : 1-2 days (1x cost) Policy for file, resource, workflow manager: 1-2 days per new PGE and new Product Type Production rules: 1 week per PGE Total Level of Effort OCO: 1.0 FTEs over 5 years NPP Sounder PEATE: 2.5 FTEs over 3 years
- 37. Some relevant experience with NRAO: EVLA prototype Explore JPL data system expertise Leverage Apache OODT Leverage architecture experience Build on NRAO Socorro F2F given in April 2011 and Innovations in Data-Intensive Astronomy meeting in May 2011 Define achievable prototype Focus on EVLA summer school pipeline Heavy focus on CASApy, simple pipelining, metadata extraction, archiving of directory-based products Ideal for OODT system
- 38. Architecture
- 39. Pre-Requisites Apache OODT Version: 0.3-SNAPSHOT JDK6, Maven2.2.1 Stock Linux box
- 40. Installed Services File Manager http://ska-dc.jpl.nasa.gov:9000 Crawler http://ska-dc.jpl.na.gov:9020 Tomcat5 Curator: http://ska-dc.jpl.nasa.gov:8080/curator/ Browser: http://ska-dc.jpl.nasa.gov/ PCS Services: http://ska-dc.jpl.nasa.gov:8080/pcs/services/ CAS Product Services: http://ska-dc.jpl.nasa.gov:8080/fmprod/ Workflow Monitor: http://ska-dc.jpl.nasa.gov:8080/wmonitor/ Met Extractors /usr/local/ska-dc/pge/extractors (Cube, Cal Tables) PCS package /usr/local/ska-dc/pcs (scripts dir contains pcs_stat, pcs_trace, etc.)
- 41. Demonstration Use Case Run EVLA Spectral Line Cube generation First step is ingest EVLARawDataOutput from Joe Then fire off evlascube event Workflow manager writes CASApy script dynamically Via CAS-PGE CAS-PGE starts CASApy CASApy generates Cal tables and 2 Spectral Line Cube Images CAS-PGE ingests them into the File Manager Gravy: UIs,Cmd Line Tools, Services
- 45. Results: PCS Trace Cmd Line
- 46. Results: PCS Stat Cmd Line
- 47. Results: PCS REST Services: Trace curl http://host/pcs/services/pedigree/report/flux_redo.cal
- 48. Results: PCS REST Service: Health curl http://host/pcs/services/health/report Read up on https://issues.apache.org/jira/browse/OODT-139 Read documentation on PCS services: https://cwiki.apache.org/confluence/display/OODT/OODT+REST+Services
- 49. Results: RSS feed of prods
- 50. Results: RDF of products
- 51. Where are we headed? OPSui work OODT-157 you will have heard about this earlier in the day from Andrew Hart Improved PCS services Integrate more services into OODT-139 including curation services, and workflow services for processing Workflow2 improvements described in OODT-215
- 52. Where are we headed Integration with Hadoop Nextgen M/R http://svn.apache.org/repos/asf/oodt/branches/wengine-branch/ Integration with more catalogs Apache Gora, MongoDB Integration with GIS services GDAL, regridding, etc. Improved science algorithm wrapping
- 53. OODT Project Contact Info Learn more and track our progress at: http://oodt.apache.org WIKI: https://cwiki.apache.org/OODT / JIRA: https://issues.apache.org/jira/browse/OODT Join the mailing list: [email_address] Chat on IRC: #oodt on irc.freenode.net Acknowledgements Key Members of the OODT teams: Chris Mattmann, Daniel J. Crichton, Steve Hughes, Andrew Hart, Sean Kelly, Sean Hardman, Paul Ramirez, David Woollard, Brian Foster, Dana Freeborn, Emily Law, Mike Cayanan, Luca Cinquini, Heather Kincaid Projects, Sponsors, Collaborators: Planetary Data System, Early Detection Research Network, Climate Data Exchange, Virtual Pediatric Intensive Care Unit, NASA SMAP Mission, NASA OCO-2 Mission, NASA NPP Sounder Peate, NASA ACOS Mission, Earth System Grid Federation
- 54. Alright, I ’ll shut up now Any questions? THANK YOU! [email_address] @chrismattmann on Twitter