TensorFlow.Data 및 TensorFlow Hub
11 likes1,682 views

The document outlines multiple methods for loading, processing, and training datasets using TensorFlow's data pipeline features, particularly with TFRecord datasets and CSV datasets. It describes techniques for shuffling, repeating, and batching datasets for model training, as well as using pre-trained models from TensorFlow Hub. Additionally, it highlights best practices for high performance and offers code snippets for implementing input functions and training estimators.






























![tf.enable_eager_execution()
# In a terminal, run the following commands, e.g.:
# $ pip install kaggle
# $ kaggle datasets download -d therohk/million-headlines -p .
dataset = tf.contrib.data.make_csv_dataset(
"*.csv", BATCH_SIZE, num_epochs=NUM_EPOCHS)
for batch in dataset:
train_model(batch["publish_date"], batch["headline_text"])](https://image.slidesharecdn.com/20180414-180419053531/85/TensorFlow-Data-TensorFlow-Hub-31-320.jpg)










![saeta@saeta:~$ capture_tpu_profile --tpu_name=saeta --logdir=myprofile/ --duration_ms=10000
Welcome to the Cloud TPU Profiler v1.5.1
Starting to profile TPU traces for 10000 ms. Remaining attempt(s): 3
Limiting the number of trace events to 1000000
2018-03-21 01:13:12.350004: I tensorflow/contrib/tpu/profiler/dump_tpu_profile.cc:155] Converting trace events to TraceViewer JSON.
2018-03-21 01:13:12.392162: I tensorflow/contrib/tpu/profiler/dump_tpu_profile.cc:69] Dumped raw-proto trace data to profiles/5/plugins/profile/2018-03-21_01:13:12/tr
ace
Trace contains 998114 events.
Dumped JSON trace data to myprofile/plugins/profile/2018-03-21_01:13:12/trace.json.gz
Dumped json op profile data to myprofile/plugins/profile/2018-03-21_01:13:12/op_profile.json
Dumped tool data for input_pipeline.json to myprofile/plugins/profile/2018-03-21_01:13:12/input_pipeline.json
Dumped tool data for overview_page.json to myprofile/plugins/profile/2018-03-21_01:13:12/overview_page.json
NOTE: using the trace duration 10000ms.
Set an appropriate duration (with --duration_ms) if you don't see a full step in your trace or the captured trace is too large.
saeta@saeta:~$ tensorboard --logdir=myprofile/
TensorBoard 1.6.0 at <redacted> (Press CTRL+C to quit)
/: // # / : # : /: : -/
/: // - .# /#- . - - . - :/ : -/](https://image.slidesharecdn.com/20180414-180419053531/85/TensorFlow-Data-TensorFlow-Hub-42-320.jpg)


































![# Use pre-trained universal sentence encoder to build text vector column.
review = hub.text_embedding_column(
"review", "https://tfhub.dev/google/universal-sentence-encoder/1")
features = {
"review": np.array(["an arugula masterpiece", "inedible shoe leather", ...])
}
labels = np.array([[1], [0], ...])
input_fn = tf.estimator.input.numpy_input_fn(features, labels, shuffle=True)
estimator = tf.estimator.DNNClassifier(hidden_units, [review])
estimator.train(input_fn, max_steps=100)](https://image.slidesharecdn.com/20180414-180419053531/85/TensorFlow-Data-TensorFlow-Hub-78-320.jpg)
![# Use pre-trained universal sentence encoder to build text vector column.
review = hub.text_embedding_column(
"review", "https://tfhub.dev/google/universal-sentence-encoder/1",
trainable=True)
features = {
"review": np.array(["an arugula masterpiece", "inedible shoe leather", ...])
}
labels = np.array([[1], [0], ...])
input_fn = tf.estimator.input.numpy_input_fn(features, labels, shuffle=True)
estimator = tf.estimator.DNNClassifier(hidden_units, [review])
estimator.train(input_fn, max_steps=100)](https://image.slidesharecdn.com/20180414-180419053531/85/TensorFlow-Data-TensorFlow-Hub-79-320.jpg)
![# Use pre-trained universal sentence encoder to build text vector column.
review = hub.text_embedding_column(
"review", "https://tfhub.dev/google/universal-sentence-encoder/1")
features = {
"review": np.array(["an arugula masterpiece", "inedible shoe leather", ...])
}
labels = np.array([[1], [0], ...])
input_fn = tf.estimator.input.numpy_input_fn(features, labels, shuffle=True)
estimator = tf.estimator.DNNClassifier(hidden_units, [review])
estimator.train(input_fn, max_steps=100)](https://image.slidesharecdn.com/20180414-180419053531/85/TensorFlow-Data-TensorFlow-Hub-80-320.jpg)

TensorFlow.Data 및 TensorFlow Hub
- 1. . 1 1 2 1 0/ .
- 9. . .
- 11. § G
- 14. files = tf.data.Dataset.list_files(file_pattern) dataset = tf.data.TFRecordDataset(files) dataset = dataset.shuffle(10000) dataset = dataset.repeat(NUM_EPOCHS) dataset = dataset.map(lambda x: tf.parse_single_example(x, features)) dataset = dataset.batch(BATCH_SIZE) iterator = dataset.make_one_shot_iterator() features = iterator.get_next() E T L
- 16. § tf.data0 : 1 § 38 , / . . . / . / . § C 0 G tf.contrib.data.prefetch_to_device() .
- 17. files = tf.data.Dataset.list_files(file_pattern) dataset = tf.data.TFRecordDataset(files) dataset = dataset.shuffle(10000) dataset = dataset.repeat(NUM_EPOCHS) dataset = dataset.map(lambda x: tf.parse_single_example(x, features)) dataset = dataset.batch(BATCH_SIZE) iterator = dataset.make_one_shot_iterator() features = iterator.get_next()
- 18. files = tf.data.Dataset.list_files(file_pattern) dataset = tf.data.TFRecordDataset(files, num_parallel_reads=32) dataset = dataset.shuffle(10000) dataset = dataset.repeat(NUM_EPOCHS) dataset = dataset.map(lambda x: tf.parse_single_example(x, features)) dataset = dataset.batch(BATCH_SIZE) iterator = dataset.make_one_shot_iterator() features = iterator.get_next()
- 19. files = tf.data.Dataset.list_files(file_pattern) dataset = tf.data.TFRecordDataset(files, num_parallel_reads=32) dataset = dataset.apply( tf.contrib.data.shuffle_and_repeat(10000, NUM_EPOCHS)) dataset = dataset.apply( tf.contrib.data.map_and_batch(lambda x: ..., BATCH_SIZE)) iterator = dataset.make_one_shot_iterator() features = iterator.get_next()
- 20. files = tf.data.Dataset.list_files(file_pattern) dataset = tf.data.TFRecordDataset(files, num_parallel_reads=32) dataset = dataset.apply( tf.contrib.data.shuffle_and_repeat(10000, NUM_EPOCHS)) dataset = dataset.apply( tf.contrib.data.map_and_batch(lambda x: ..., BATCH_SIZE)) dataset = dataset.apply(tf.contrib.data.prefetch_to_device("/gpu:0")) iterator = dataset.make_one_shot_iterator() features = iterator.get_next()
- 21. files = tf.data.Dataset.list_files(file_pattern) dataset = tf.data.TFRecordDataset(files, num_parallel_reads=32) dataset = dataset.apply( tf.contrib.data.shuffle_and_repeat(10000, NUM_EPOCHS)) dataset = dataset.apply( tf.contrib.data.map_and_batch(lambda x: ..., BATCH_SIZE)) dataset = dataset.apply(tf.contrib.data.prefetch_to_device("/gpu:0")) iterator = dataset.make_one_shot_iterator() features = iterator.get_next() = C = = ! ==: B = = ? / .
- 23. Dataset.map
- 24. § tf.SparseTensor § Dataset.from_generator() + Python § DatasetOpKernel
- 26. § ( .8 S 1 8 E K § 8 . . C K § ( 8 C ).8 P ).8 !
- 27. tf.enable_eager_execution() files = tf.data.Dataset.list_files(file_pattern) dataset = tf.data.TFRecordDataset(files) dataset = dataset.shuffle(10000) dataset = dataset.repeat(NUM_EPOCHS) dataset = dataset.map(lambda x: tf.parse_single_example(x, features)) dataset = dataset.batch(BATCH_SIZE) # Eager execution makes dataset a normal Python iterable. for batch in dataset: train_model(batch)
- 28. § ( .8 S 1 8 E K § 8 . . C K § ( 8 C ).8 P ).8 !
- 29. tf.enable_eager_execution() files = tf.data.Dataset.list_files(file_pattern) dataset = tf.data.TFRecordDataset(files) dataset = dataset.shuffle(10000) dataset = dataset.repeat(NUM_EPOCHS) dataset = dataset.map(lambda x: tf.parse_single_example(x, features)) dataset = dataset.batch(BATCH_SIZE) for batch in dataset: train_model(batch)
- 30. tf.enable_eager_execution() # Also implements best practices for high performance! # (See optional args for details.) dataset = tf.contrib.data.make_batched_features_dataset( file_pattern, BATCH_SIZE, features, num_epochs=NUM_EPOCHS) for batch in dataset: train_model(batch)
- 31. tf.enable_eager_execution() # In a terminal, run the following commands, e.g.: # $ pip install kaggle # $ kaggle datasets download -d therohk/million-headlines -p . dataset = tf.contrib.data.make_csv_dataset( "*.csv", BATCH_SIZE, num_epochs=NUM_EPOCHS) for batch in dataset: train_model(batch["publish_date"], batch["headline_text"])
- 32. § ( .8 S 1 8 E K § 8 . . C K § ( 8 C ).8 P ).8 !
- 33. dataset = tf.contrib.data.make_csv_dataset( "*.csv", BATCH_SIZE, num_epochs=NUM_EPOCHS) for batch in dataset: train_model(batch)
- 34. # Wrap the dataset in an input function, and return it directly. def input_fn(): dataset = tf.contrib.data.make_csv_dataset( "*.csv", BATCH_SIZE, num_epochs=NUM_EPOCHS) return dataset # Train an Estimator on the dataset. tf.estimator.Estimator(model_fn=train_model).train(input_fn=input_fn)
- 35. § G
- 37. § . // . / / § / . / / . / .
- 39. . 2 ) , 1. 3 2 3 3 . ( 1 1
- 40. def input_fn(batch_size): files = tf.data.Dataset.list_files(FLAGS.data_dir) dataset = tf.data.TFRecordDataset(files) dataset = dataset.shuffle(2048) # Sliding window of 2048 records dataset = dataset.repeat(NUM_EPOCHS) dataset = dataset.map(parser_fn).batch(batch_size) return dataset 0- E 4. 5,231 03 ( )
- 41. § § §
- 42. saeta@saeta:~$ capture_tpu_profile --tpu_name=saeta --logdir=myprofile/ --duration_ms=10000 Welcome to the Cloud TPU Profiler v1.5.1 Starting to profile TPU traces for 10000 ms. Remaining attempt(s): 3 Limiting the number of trace events to 1000000 2018-03-21 01:13:12.350004: I tensorflow/contrib/tpu/profiler/dump_tpu_profile.cc:155] Converting trace events to TraceViewer JSON. 2018-03-21 01:13:12.392162: I tensorflow/contrib/tpu/profiler/dump_tpu_profile.cc:69] Dumped raw-proto trace data to profiles/5/plugins/profile/2018-03-21_01:13:12/tr ace Trace contains 998114 events. Dumped JSON trace data to myprofile/plugins/profile/2018-03-21_01:13:12/trace.json.gz Dumped json op profile data to myprofile/plugins/profile/2018-03-21_01:13:12/op_profile.json Dumped tool data for input_pipeline.json to myprofile/plugins/profile/2018-03-21_01:13:12/input_pipeline.json Dumped tool data for overview_page.json to myprofile/plugins/profile/2018-03-21_01:13:12/overview_page.json NOTE: using the trace duration 10000ms. Set an appropriate duration (with --duration_ms) if you don't see a full step in your trace or the captured trace is too large. saeta@saeta:~$ tensorboard --logdir=myprofile/ TensorBoard 1.6.0 at <redacted> (Press CTRL+C to quit) /: // # / : # : /: : -/ /: // - .# /#- . - - . - :/ : -/
- 43. def input_fn(batch_size): files = tf.data.Dataset.list_files(FLAGS.data_dir) dataset = tf.data.TFRecordDataset(files) dataset = dataset.shuffle(2048) # Sliding window of 2048 records dataset = dataset.repeat(NUM_EPOCHS) dataset = dataset.map(parser_fn, num_parallel_calls=64) dataset = dataset.batch(batch_size) return dataset - 0 0 !
- 44. § § §
- 47. § § §
- 48. (., (., Extract I Transform Load ) / ) / HGA C D M HGA
- 49. 1 1 3 2 3 3
- 50. 0 0 0 % 5 7 % 5 5 % 0 5 0 0 5 7 7 % 7 0 1 31 C 4 6 2 2 2
- 51. def input_fn(batch_size): files = tf.data.Dataset.list_files(FLAGS.data_dir) dataset = tf.data.TFRecordDataset(files, num_parallel_reads=32) dataset = dataset.shuffle(10000) dataset = dataset.repeat(NUM_EPOCHS) dataset = dataset.map(parser_fn, num_parallel_calls=64) dataset = dataset.batch(batch_size) dataset = dataset.prefetch(2) return dataset . . T bi n D c i Fd_ e a lfR D
- 52. § . § §
- 53. def input_fn(batch_size): files = tf.data.Dataset.list_files(FLAGS.data_dir) dataset = tf.data.TFRecordDataset(files, num_parallel_reads=32) dataset = dataset.shuffle(10000) dataset = dataset.repeat(NUM_EPOCHS) dataset = dataset.map(parser_fn, num_parallel_calls=64) dataset = dataset.batch(batch_size) dataset = dataset.prefetch(2) return dataset !
- 54. § § §
- 55. 6 6 53 4 6 53 53 6 53 6 6 53 4 4 4 4 1 7 2
- 56. § - § ? F ) § § ( )
- 57. def input_fn(batch_size): files = tf.data.Dataset.list_files(FLAGS.data_dir) def tfrecord_dataset(filename): buffer_size = 8 * 1024 * 1024 # 8 MiB per file return tf.data.TFRecordDataset(filename, buffer_size=buffer_size) dataset = files.apply(tf.contrib.data.parallel_interleave( tfrecord_dataset, cycle_length=32, sloppy=True)) dataset = dataset.apply(tf.contrib.data.shuffle_and_repeat(10000, NUM_EPOCHS)) dataset = dataset.apply(tf.contrib.data.map_and_batch(parser_fn, batch_size, num_parallel_batches=4)) dataset = dataset.prefetch(4) return dataset !
- 59. ) ( ) +
- 61. Repositories
- 62. TensorFlow Hub
- 66. , ,
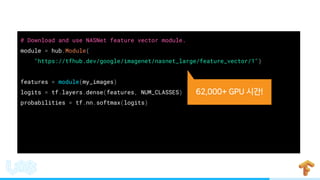
- 70. # Download and use NASNet feature vector module. module = hub.Module( "https://tfhub.dev/google/imagenet/nasnet_large/feature_vector/1") features = module(my_images) logits = tf.layers.dense(features, NUM_CLASSES) probabilities = tf.nn.softmax(logits) + !
- 71. # Download and use NASNet feature vector module. module = hub.Module( "https://tfhub.dev/google/imagenet/nasnet_large/feature_vector/1", trainable=True, tags={“train”}) features = module(my_images) logits = tf.layers.dense(features, NUM_CLASSES) probabilities = tf.nn.softmax(logits)
- 72. § /,2/ A , 5 § 0/,2/ A § 5 / A 3) § - A 3( 3) 3 § - A 1 / A 3) § 1 / A 3( 3) &( (&( ) § 5 / A 3(
- 74. “The quick brown fox”
- 75. “The shallots were simply underwhelming” POSITIVE NEGATIVE
- 76. § L § M ( , § E 2 ,, 2 ) ) ,
- 78. # Use pre-trained universal sentence encoder to build text vector column. review = hub.text_embedding_column( "review", "https://tfhub.dev/google/universal-sentence-encoder/1") features = { "review": np.array(["an arugula masterpiece", "inedible shoe leather", ...]) } labels = np.array([[1], [0], ...]) input_fn = tf.estimator.input.numpy_input_fn(features, labels, shuffle=True) estimator = tf.estimator.DNNClassifier(hidden_units, [review]) estimator.train(input_fn, max_steps=100)
- 79. # Use pre-trained universal sentence encoder to build text vector column. review = hub.text_embedding_column( "review", "https://tfhub.dev/google/universal-sentence-encoder/1", trainable=True) features = { "review": np.array(["an arugula masterpiece", "inedible shoe leather", ...]) } labels = np.array([[1], [0], ...]) input_fn = tf.estimator.input.numpy_input_fn(features, labels, shuffle=True) estimator = tf.estimator.DNNClassifier(hidden_units, [review]) estimator.train(input_fn, max_steps=100)
- 80. # Use pre-trained universal sentence encoder to build text vector column. review = hub.text_embedding_column( "review", "https://tfhub.dev/google/universal-sentence-encoder/1") features = { "review": np.array(["an arugula masterpiece", "inedible shoe leather", ...]) } labels = np.array([[1], [0], ...]) input_fn = tf.estimator.input.numpy_input_fn(features, labels, shuffle=True) estimator = tf.estimator.DNNClassifier(hidden_units, [review]) estimator.train(input_fn, max_steps=100)
- 82. § ( § ( ), , ) , , ) § A D F E