Testing data streaming applications
2 likes3,986 views

The document outlines the importance of stream processing in data engineering, emphasizing its advantages over traditional batch processing, such as faster reaction times and better handling of diverse data sources. It presents various stream processing technologies, concepts, and structures, along with recommended testing practices to ensure robust data pipelines. Key topics include the challenges associated with synchronous systems, recovery from failure, and the significance of modular design and regression testing.
























Testing data streaming applications
- 1. www.mapflat.com Testing data streaming applications Lars Albertsson, independent consultant Øyvind Løkling, Schibsted Media Group
- 2. www.mapflat.com Who’s talking? ● Swedish Institute of Computer Science (distributed system test+debug tools) ● Sun Microsystems (very large machines) ● Google (Hangouts, productivity) ● Recorded Future (NLP startup) ● Cinnober Financial Tech. (trading systems) ● Spotify (data processing & modelling) ● Schibsted Media Group (data processing & modelling) ● Mapflat - independent data engineering consultant
- 3. www.mapflat.com Why stream processing? ● Increasing number of data-driven features ● 90+% fed by batch processing ○ Simpler, better tooling ○ 1+ hour data reaction time ● Stream processing for ○ 100ms - 1 hour reaction ○ Decoupled, asynchronous microservices User content Professional content Ads / partners User behaviour Systems Ads System diagnostics Recommendations Data-based features Curated content Pushing Business intelligence Experiments Exploration
- 4. www.mapflat.com The organic past ● Many paths ● Synchronous ● Link failure -> chain failure ● Heterogeneous ● Difficult to recover from transformation bugs Service Service Service App App App DB Poll Queue Aggregate logs NFS Hourly dump Data warehouse ETL Queue NFS scp DB HTTP
- 5. www.mapflat.com ● Publish data in streams ● Replicated, sharded append-only log ● Pub / sub with history ○ Kafka, Google Pub/Sub, AWS Kinesis ● Tap to data lake for batch processing Unified log The unified log Ads Search Feed App App App StreamStream Stream Data lake
- 6. www.mapflat.com ● Decoupled producers/consumers ○ In source/deployment ○ In space ○ In time ● Publish results to log ● Recovers from link failures ● Replay on job bug fix Stream processing Job Ads Search Feed App App App StreamStream Stream Stream Stream Stream Job Job Stream Stream Stream Job Job Data lake Business intelligence Job
- 7. www.mapflat.com Stream processing building blocks ● Aggregate ○ Calculate time windows ○ Aggregate state (in memory / local database / shared database) ● Filter ○ Slim down stream ○ Privacy, security concerns ● Join ○ Enrich by joining with datasets, e.g. geo IP lookup, demographics ○ Join streams within time windows, e.g. click-through rate ● Transform ○ Bring data into same “shape”, schema
- 8. www.mapflat.com Stream processing technologies ● Spark Streaming ○ Ideal if you are already using Spark, same model ○ Bridges gap between data science / data engineers, batch and stream ● Kafka Streams ○ Library - new, positions itself as a lightweight alternative ○ Tightly coupled to Kafka ● Others ○ Storm, Heron, Flink, Samza, Google Dataflow, AWS Lambda
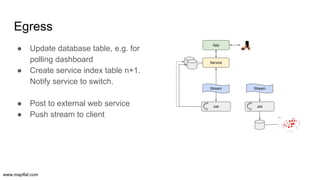
- 9. www.mapflat.com ● Update database table, e.g. for polling dashboard ● Create service index table n+1. Notify service to switch. ● Post to external web service ● Push stream to client Egress Service Stream Stream Job Job App
- 10. www.mapflat.com Test concepts Test harness Test fixture System under test (SUT) 3rd party component (e.g. DB) 3rd party component 3rd party component Test input Test oracle Test framework (e.g. JUnit, Scalatest) Seam IDEs Build tools
- 11. www.mapflat.com ● Unit ● Single job ● Multiple jobs ● Pipeline, including service ● Full system, including client Choose stable interfaces Each scope has a cost Potential test scopes Job Service App Stream Stream Job Stream Job
- 12. www.mapflat.com Stream application properties ● Output = function(input, code) ○ Perfect for testing! ○ Avoid: indeterministic processing, reading wall clock ● Pipeline and job endpoints are stable ○ Correspond to business value ● Internal abstractions are volatile ○ Reslicing in different dimensions is common
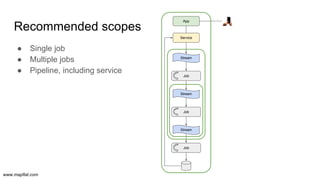
- 13. www.mapflat.com ● Single job ● Multiple jobs ● Pipeline, including service Recommended scopes Job Service App Stream Stream Job Stream Job
- 14. www.mapflat.com ● Unit ○ Few stable interfaces ○ Not necessary ○ Avoid mocks, DI rituals ● Full system, including client ○ Client automation fragile “Focus on functional system tests, complement with smaller where you cannot get coverage.” - Henrik Kniberg Scopes to avoid Job Service App Stream Stream Job Stream Job
- 15. www.mapflat.com Stream application, example harness Scalatest Spark Streaming jobs IDE, CI, debug integration 15 DB Topic Kafka Test input Test oracle Docker IDE / Gradle Polling
- 16. www.mapflat.com Test lifecycle 1. Start fixture containers 2. Await fixture ready 3. Allocate test case resources 4. Start jobs 5. Push input data to Kafka 6. While (!done && !timeout) { pollDatabase(); sleep(1ms) } 7. While (moreTests) { Goto 3 } 8. Tear down fixture For absence test, send dummy sync messages at end. 2, 7. Scalatest 4. Spark 5 6 1. Docker IDE / Gradle
- 17. www.mapflat.com ● Input & output is denormalised & wide ● Fields are frequently changed ○ Additions are compatible ○ Modifications are incompatible => new, similar data type ● Static test input, e.g. JSON files ○ Unmaintainable ● Input generation routines ○ Robust to changes, reusable Input generation
- 18. www.mapflat.com Test oracles ● Compare with expected output ● Check fields relevant for test ○ Robust to field changes ○ Reusable for new, similar types ● Tip: Use lenses ○ JSON: JsonPath (Java), Play JSON (Scala) ○ Case classes: Monocle ● Express invariants for each data type ○ Reuse for production data quality monitoring
- 19. www.mapflat.com Data pipeline = yet another program Don’t veer from best practices ● Regression testing ● Design: Separation of concerns, modularity, etc ● Process: CI/CD, code review, static analysis tools ● Avoid anti-patterns: Global state, hard-coding location, duplication, ... In data engineering, slipping is in the culture... :-( ● Mix in solid backend engineers ● Document “golden path”
- 20. www.mapflat.com Testing with cloud services ● PaaS components do not work locally ○ Cloud providers should provide fake implementations ○ Exceptions: Kubernetes, Cloud SQL, Relational Database Service, (S3) ● Integrate PaaS service as fixture component is challenging ○ Distribute access tokens, etc ○ Pay $ or $$$
- 21. www.mapflat.com Top anti-patterns 1. Test as afterthought or in production Data processing applications are suited for test! 2. Static test input in version control 3. Exact expected output test oracle 4. Unit testing volatile interfaces 5. Using mocks & dependency injection 6. Tool-specific test framework - vendor lock-in 7. Using wall clock time 8. Embedded fixture components
- 22. www.mapflat.com Thank you. Questions? Credits: Øyvind Løkling, Schibsted Media Group ● Content inspiration Confluent, LinkedIn, Google, Netflix, Apache Samza ● Images Tracey Saxby, Integration and Application Network, University of Maryland Center for Environmental Science (ian.umces.edu/imagelibrary/).
- 24. www.mapflat.com Quality testing variants ● Functional regression ○ Binary, key to productivity ● Golden set ○ Extreme inputs => obvious output ○ No regressions tolerated ● (Saved) production data input ○ Individual regressions ok ○ Weighted sum must not decline ○ Beware of privacy 24
- 25. www.mapflat.com Hadoop / Spark counters ● Processing tool (Spark/Hadoop) counters ○ Odd code path => bump counter ● Dedicated quality assessment pipelines ○ Reuse test oracle invariants in production Obtaining quality metrics 25 DB Quality assessment job
- 26. www.mapflat.com Quality testing in the process ● Binary self-contained ○ Validate in CI ● Relative vs history ○ E.g. large drops ○ Precondition for publishing dataset ● Push aggregates to DB ○ Standard ops: monitor, alert 26 DB ∆? Code ∆!