



















Testing Distributed Query Engine as a Service
- 1. Naoki Takezoe Presto Conference Tokyo 2020 Nov 20, 2020 Testing Distributed Query Engine as a Service Deliver our service to customers as safe as possible
- 2. © 2020 Treasure Data Who am I? • Naoki Takezoe • Joined Treasure Data in 2018 • Work for Presto / Apache Spark • Open Source • GitBucket • Scalatra • Apache PredictionIO • Books • Japanese translation of Scala Puzzlers • Scala 300 recipes, etc Twitter: @takezoen GitHub: https://github.com/takezoe
- 3. © 2020 Treasure Data Treasure Data Logs Device Data Batch Data PlazmaDB Table Schema Data Collection Cloud Storage Distributed Data Processing Jobs Job Management SQL Editor Scheduler Workflows Machine Learning Treasure Data OSS Third Party OSS Data Ready to use Cloud Data Platform
- 4. © 2020 Treasure Data Presto at Treasure Data • 2010 • Presto, developed at Facebook, was open-sourced • Treasure Data was providing Impala As A Service • 2014 • Launched Presto As A Service as a replacement of Impala • 2015 • 20,000 queries / day • 2019 • Reached 1,000,000 queries / day • Presto creators (Martin, Dain and David) left Facebook and founded an NPO Presto Software Foundation (prestosql), then joined Starburst • Hosted Presto Conference in Tokyo
- 5. © 2020 Treasure Data
- 6. © 2020 Treasure Data Deliver our service to customers as safe as possible
- 7. © 2020 Treasure Data Testing distributed database is challenging • Variety of workload • Possible performance degradation • Cluster status • Many corner cases
- 8. © 2020 Treasure Data Test can be more important when upgrading Presto • Presto development is super active • 27 releases in 2019 • 18 releases in 2020 at this point (Nov 14) • No stable version • Incompatible updates come with bug fixes • Sticking to one version cannot be an option • Backport bug fixes and new features from newer version also gets challenging over time How we can upgrade Presto safely...?
- 9. © 2020 Treasure Data In order to minimize the risk Unit test Integration test System test Regular performance proving Gradual migration for big updateInternal dogfooding Cluster status monitoring Test Release process Monitoring
- 10. © 2020 Treasure Data What are missing? • Covering variety of use cases • Performance degradation in corner cases • Unknown compatibility issues • Production-scale environment • Data size and characteristics • Number of queries, cluster size, etc
- 11. © 2020 Treasure Data What’s a solution?
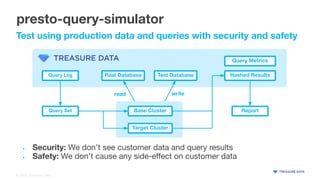
- 12. © 2020 Treasure Data presto-query-simulator Test using production data and queries with security and safety Base Cluster Target Cluster Query Log Hashed Results ReportQuery Set Real Database Test Database read write • Security: We don’t see customer data and query results • Safety: We don’t cause any side-effect on customer data Query Metrics
- 13. © 2020 Treasure Data Challenges in query-simulator • Query simulation takes very long time • Testing 1-day queries will take 1 day at least, theoretically • Not only time, but also cost of test clusters is the matter • Result verification is not straightforward • Many false positives and duplications • Result analysis tends to depend on personal knowledge
- 14. © 2020 Treasure Data Make query simulation faster • Reduce number of queries by grouping by query signature (up to -90%) • Reduce amount of data by narrowing table scan ranges (up to -80%) • Use multiple Presto clusters • Test only long-running queries
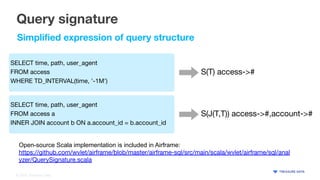
- 15. © 2020 Treasure Data Query signature SELECT time, path, user_agent FROM access WHERE TD_INTERVAL(time, '-1M') SELECT time, path, user_agent FROM access a INNER JOIN account b ON a.account_id = b.account_id S(T) access-># S(J(T,T)) access->#,account-># Simplified expression of query structure Open-source Scala implementation is included in Airframe: https://github.com/wvlet/airframe/blob/master/airframe-sql/src/main/scala/wvlet/airframe/sql/anal yzer/QuerySignature.scala
- 16. © 2020 Treasure Data Narrowing scan ranges Time distribution of records Use only x% of total records by adding a time range predicate SELECT time, parh, user_agent FROM access SELECT time, path, user_agent FROM ( SELECT time, path, user_agent FROM access ) WHERE TD_TIME_RANGE(time, from, to) Original scan range Use this range only
- 17. © 2020 Treasure Data We choose these options depending on the purpose of query simulation • Reduce number of queries by grouping by query signature (up to -90%) • Reduce amount of data by narrowing table scan ranges (up to -80%) • Use multiple Presto clusters • Test only long-running queries for checking compatibility? or for checking performance difference?
- 18. © 2020 Treasure Data Make result verification easier • Auto detect non-deterministic query results • Running query multiple times to see if results are the same • Grouping similar errors • Fuzzy comparison of error messages • • List problematic queries based on internal metrics • Performance, resource usage, scan ranges, worker distribution, etc • Finally, check problematic queries by human
- 19. © 2020 Treasure Data We just need to check queries listed on the report Give a possible reason of the inconsistent result Failures are grouped by the similarity of error messages List only queries more than 5 min slower
- 20. © 2020 Treasure Data Future work for further improvement • Run query simulation more frequently (hopefully regularly) • Further speed up is required • Maintain small but effective query sets for quick test • Automate test environment provisioning • Improve test coverage • Overcome some system-level restriction • Test with schema and data of that time (like time travel) • Improve the resolution of query grouping • ...and more!!
- 21. © 2020 Treasure Data Related Work
- 22. © 2020 Treasure Data Related Work • Snowtrail: Testing with Production Queries on a Cloud Database • https://resources.snowflake.com/report/snowtrail-testing-with-producti on-series-on-a-cloud-database • クエリログを使ったAurora MySQLの負荷テスト • https://techlife.cookpad.com/entry/2020/10/13/090000 • Building an Automated Testing Framework Based on Chaos Mesh and Argo • https://pingcap.com/blog/building-automated-testing-framework-base d-on-chaos-mesh-and-argo