Text mining introduction-1
Download as PPTX, PDF0 likes152 views

The document discusses various topics related to unstructured data analytics including text mining, web mining, and big data. It provides details on text mining tasks like information extraction, topic tracking, summarization, classification, clustering, and association. The key aspects of text mining discussed are preprocessing text data through tokenization, part-of-speech tagging, and semantic analysis. Text mining aims to extract useful information and discover patterns from large collections of unstructured text documents.




















































Text mining introduction-1
- 2. Text Mining Web Mining Big Data? Use of Software packages
- 3. Evaluation Criteria: Student Presentations : 30% Two presentations Midterm – in class exam: 30% Project: 40% 10% for dataset 10% for presentation
- 4. Text Mining Discovery of new, previously unknown information by extracting information from different written sources By computer?
- 5. What is Text-Mining? Finding interesting regularities in large textual datasets…” (Usama Fayad, adapted) where interesting means: non-trivial, hidden, previously unknown and potentially useful Finding semantic and abstract information from the surface form of textual data…”
- 6. What is Text Data Mining? The metaphor of extracting ore from rock: Does make sense for extracting documents of interest from a huge pile. But does not reflect notions of DM in practice: finding patterns across large collections discovering heretofore unknown information
- 7. Real Text DM The point: Discovering heretofore unknown information is not what we usually do with text. (If it weren’t known, it could not have been written by someone!) However: There is a field whose goal is to learn about patterns in text for their own sake ...
- 8. Computational Linguistics (CL)! Goal: automated language understanding this isn’t possible instead, go for subgoals, e.g., word sense disambiguation phrase recognition semantic associations Common current approach: statistical analyses over very large text collections
- 9. Why CL Isn’t TDM A linguist finds it interesting that “cloying” co- occurs significantly with “Jar Jar Binks” ... … But this doesn’t really answer a question relevant to the world outside the text itself.
- 10. Why CL Isn’t TDM We need to use the text indirectly to answer questions about the world Direct: Analyze patent text; determine which word patterns indicate various subject categories. Indirect: Analyze patent text; find out whether private or public funding leads to more inventions.
- 11. Why CL Isn’t TDM Direct: Cluster newswire text; determine which terms are predominant Indirect: Analyze newswire text; gather evidence about which countries/alliances are dominating which financial sectors
- 12. Nuggets vs. Patterns TDM: we want to discover new information … … As opposed to discovering which statistical patterns characterize occurrence of known information. Example: WSD (Word Sense Disambiguation) not TDM: computing statistics over a corpus to determine what patterns characterize Sense S. TDM: discovering the meaning of a new sense of a word.
- 13. Nuggets vs. Patterns Nugget: a new, heretofore unknown item of information. Pattern: distributions or rules that characterize the occurrence (or non- occurrence) of a known item of information. Application of rules can create nuggets in some circumstances.
- 14. Text Mining Large amount of information Document databases Research papers News articles Books Email message Blogs
- 15. Text Mining is Difficult! Abstract concepts are difficult to represent “Countless” combinations of subtle, abstract relationships among concepts Many ways to represent similar concepts E.g. space ship, flying saucer, UFO Concepts are difficult to visualize High dimensionality Tens or hundreds of thousands of features
- 16. Why Text Mining is NOT Difficult Highly Redundant data most of the data mining methods count on this property Just about any simple algorithm can get “good” results for simple tasks: Pull out “important” phrases Find “meaningfully” related words Create some sort of summary from documents
- 17. Data Mining and Text Mining Data Mining extracts knowledge from structured data Credit card, Insurance records, Call records etc. Text Mining works with unstructured, text documents Written language is not structured
- 18. Applications Information Retrieval Search and Database operations Semantic Web Knowledge Representation and Reasoning Natural Language Processing Computational Linguistics Machine Learning and Text Mining Data Analysis
- 19. Challenges Humans cannot sift through ever increasing amount of textual documents Written language is easily understood by humans (?) My feet are killing me; My head is on fire This box weighs a ton; You have been so so incredibly helpful and thanks (for nothing) Extremely difficult to make a computer understand this language
- 20. Machine Translation "the spirit is willing but the flesh is weak." Translated into Russian and Translated back to English: "The vodka is good, but the meat is rotten“ "out of sight, out of mind" translating back as "invisible insanity” A Chinese translation of The Grapes of Wrath was called "The Angry Raisins."
- 21. Information Retrieval Get me the average Compensation of all the employees stationed in Pune Get me all the documents that contain the word “Education” and “Compensation” published in the last 4 years Find the association patterns between “Education” and “Compensation” First is SQL; Second is IR, third is TM
- 22. Levels of Text Processing Word Level Sentence Level Document Level Document-Collection Level Linked-Document-Collection Level Application Level
- 23. Text Mining Tasks Information Extraction Topic Tracking Summarization Classification Clustering Association
- 24. Evolution of Text Mining In general, two processes are used to access information from a series of documents Information Retrieval Retrieves a set of documents as an answer to a logical query using a set of key words Information Extraction Aims to EXTRACT specific information from documents which is further analyzed for trends
- 25. Approaches to Access Textual Information Library science Information science Natural language processing
- 26. Library Book Summarization and Classification Earliest library catalog by Thomas Hyde (Bodelian Library at Oxford) Creation of science abstracts using IBM 701 (Luhn, 1958) A word frequency analysis was performed A number of relatively significant words were counted for each sentence Linear distances between significant words was calculated as a metric of sentence significance The most significant sentences were extracted to form the abstract Doyle (1961) suggested classification based on word frequencies and associations!
- 27. Information Science Bibliometrics developed to provide numerical means to study and measure texts and information – Ex: Citation Index Groups of important articles can be used to track the development of pathways of a particular development Produced various indexing systems, document storage and manipulating applications and search systems
- 29. Natural Language Processing Stages in NLP Document Tokenization Lexical analysis Semantic analysis Information extraction Author’s intended meaning
- 30. Role of Message Understanding Conferences Initiated by Naval Ocean Systems Center (DARPA) Initially to analyze military messages Defined “Named Entity Recognition” Formalized test metrics – “Recall and Precision” Identified importance of robustness in Machine Learning models (ML Models) Need for minimizing over-training of ML models Importance of word-sense disambiguation
- 31. Some Definitions Document A unit of discrete textual data within a collection that usually, but not necessarily, correlates with some real-world document such as a business report, legal memorandum, e-mail, research paper, manuscript, article, press release, or news story
- 32. Some Definitions Document Collection Any grouping of text-based documents. The number of documents in such collections can range from the many thousands to the tens of millions can be either static, (the initial complement of documents remains unchanged), or dynamic (characterized by their inclusion of new or updated documents over time)
- 33. Weakly-structured documents A document is actually a “Structured Object”! Has a rich amount of semantic and syntactical structure Contains typographical elements such as punctuation marks, capitalization, numbers, and special characters such as white spacing, carriage returns, underlining, asterisks, tables, columns etc. Help identify important document subcomponents such as paragraphs, titles, publication dates, author names, table records, headers, and footnotes
- 34. Semi-Structured documents Documents with extensive and consistent format elements in which field-type metadata can be more easily inferred – such as some e-mail, HTML Web pages, PDF files, and word- processing files with document templating or style-sheet constraints Some journal articles/ conference proceedings
- 35. What is Unique to Text Data? Large number of zero attributes Each word is an attribute. Each document has only a few words. Phenomenon called high-dimensional sparsity. There may also be a wide variation in the number of nonzero values across different documents. Distance computation. For example, while it is possible, in theory, to use the Euclidean function for measuring distances, the results are usually not very effective from a practical perspective. This is because Euclidean distances are extremely sensitive to the varying document lengths (the number of nonzero attributes).
- 36. What is Unique to Text Data? Non-negativity: The frequencies of words take on nonnegative values only. Combined with high-dimensional sparsity, it enables the use of specialized methods for document analysis. The presence of a word in a document is statistically more significant than its absence. Unlike traditional multidimensional techniques, incorporating the global statistical characteristics of the data set in pairwise distance computation is crucial.
- 37. What is Unique to Text Data? Side information: In some domains, such as the Web, additional side information is available. Examples include hyperlinks or other metadata associated with the document. These additional attributes can be leveraged to enhance the text mining process further.
- 38. Document Features Basic idea is to transform a document from an irregular and implicitly structured representation into an explicitly structured representation. Identification of a simplified subset of document features that can be used to represent a particular document as a whole It is called the representational model of a document and individual documents are represented by the set of features that their representational models contain
- 39. Commonly Used Document Features Characters, Words, Terms, Concepts Leads to Categories and Sentiments
- 40. Characters The individual component-level letters, numerals, special characters and spaces are the building blocks of higher-level semantic features such as words, terms, and concepts. A character-level representation can include the full set of all characters for a document or some filtered subset. Character-based representations that include some level of positional information are more useful and common. character-based representations can be unwieldy for some types of text processing techniques
- 41. Words Specific words from a “native” document present the basic level of semantics and referred to as existing in the native feature space of a document A single word-level feature is one linguistic token. Phrases, multiword expressions, multiword hyphenates do not constitute single word-level features. It is necessary to filter these features for items such as stop words, symbolic characters, and meaningless numerics.
- 42. Terms Single and multiword phrases selected from the corpus of a native document. These can only be made up of specific words and expressions found within the native document Hence, a term-based representation is composed of a subset of the terms in that document. “President Kalam moved from a hut in the fishing village to the Rashtrapathi Bhavan”
- 43. Concepts Features generated for a document by means of manual, statistical, rule-based, or hybrid methodologies. Extracted from documents using complex preprocessing routines that identify syntactical units that are related to specific concept identifiers. A document collection of reviews of sports cars may not actually include the specific word “automotive” or the specific phrase “test drives,” but the concepts “automotive” and “test drives” might be the set of concepts used to identify and represent the collection.
- 44. Concepts Many methodologies involve a degree of cross- referencing against an external knowledge source. For manual and rule-based categorization methods, the cross-referencing and validation involves interaction with a preexisting domain ontology, lexicon, or formal concept hierarchy May use the mind of a human domain expert.
- 45. Efficient and Effective Representation Terms and concepts reflect the features with the most condensed and expressive levels of semantic value. They represent the same efficiency as character- or word- based models but more efficient Term-level representations can sometimes be easily and automatically generated from the original source text Concept-level representations, as a practical matter, often involve some level of human interaction.
- 46. Words-Properties Homonomy: same form, but different meaning (e.g. bank: river bank, financial institution) Polysemy: same form, Related meaning (e.g. bank: blood bank, financial institution; FIX) http://www.wordnet-online.com/fix.shtml usually regarded as distinct from homonymy, in which the multiple meanings of a word may be unconnected or unrelated Synonymy: different form, same meaning (e.g. singer, vocalist) Hyponymy: one word denotes a subclass of an another (e.g. breakfast, meal) Hypernym: also known as a superordinate, is broader than that of a hyponym. A hypernym consists of hyponyms
- 47. Concepts Concept-level representations are better at handling synonymy and polysemy. Also, best at relating a given feature to its various hyponyms and hypernyms. Can be processed to support very sophisticated concept hierarchies. Best for leveraging the domain knowledge afforded by ontologies and knowledge bases.
- 48. Concepts Require complex heuristics, during preprocessing operations required to extract and validate concept-type features They are often domain dependent manually generated concepts are fixed and labor intensive to assign
- 49. Domain Knowledge Concepts belong to the descriptive attributes of a document as well as to domains. A domain is a specialized area of interest with dedicated ontologies, lexicons, and taxonomies of information Domains can be very broad areas of subject matter (Financial Services) or narrowly defined specialisms (securities trading, derivatives, MFs etc.) Domain knowledge is more important in Text mining as compared to data mining
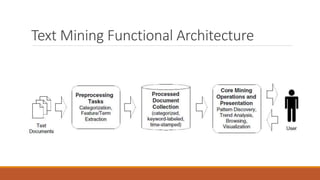
- 50. Text Mining Functional Architecture
- 51. System architecture for generic text mining system
- 52. Questions?
- 53. Components and Tasks of IE engines Zoning POS Tagging Sense Disambiguation Shallow Parsing Deep Parsing Anaphora Resolution Integration Tokenization Morphological and Lexical Analysis Semantic Analysis Domain Analysis Components Tasks