This document summarizes Elena Simperl's presentation on "The web of data: how are we doing so far?". Some key points:
- The web has shaped our understanding and interactions with data in many ways like answering questions, sharing data online, and publishing data for others to use.
- However, the theory and practice of the web of data are different, and we are at a crucial moment in how data is published and used on the web.
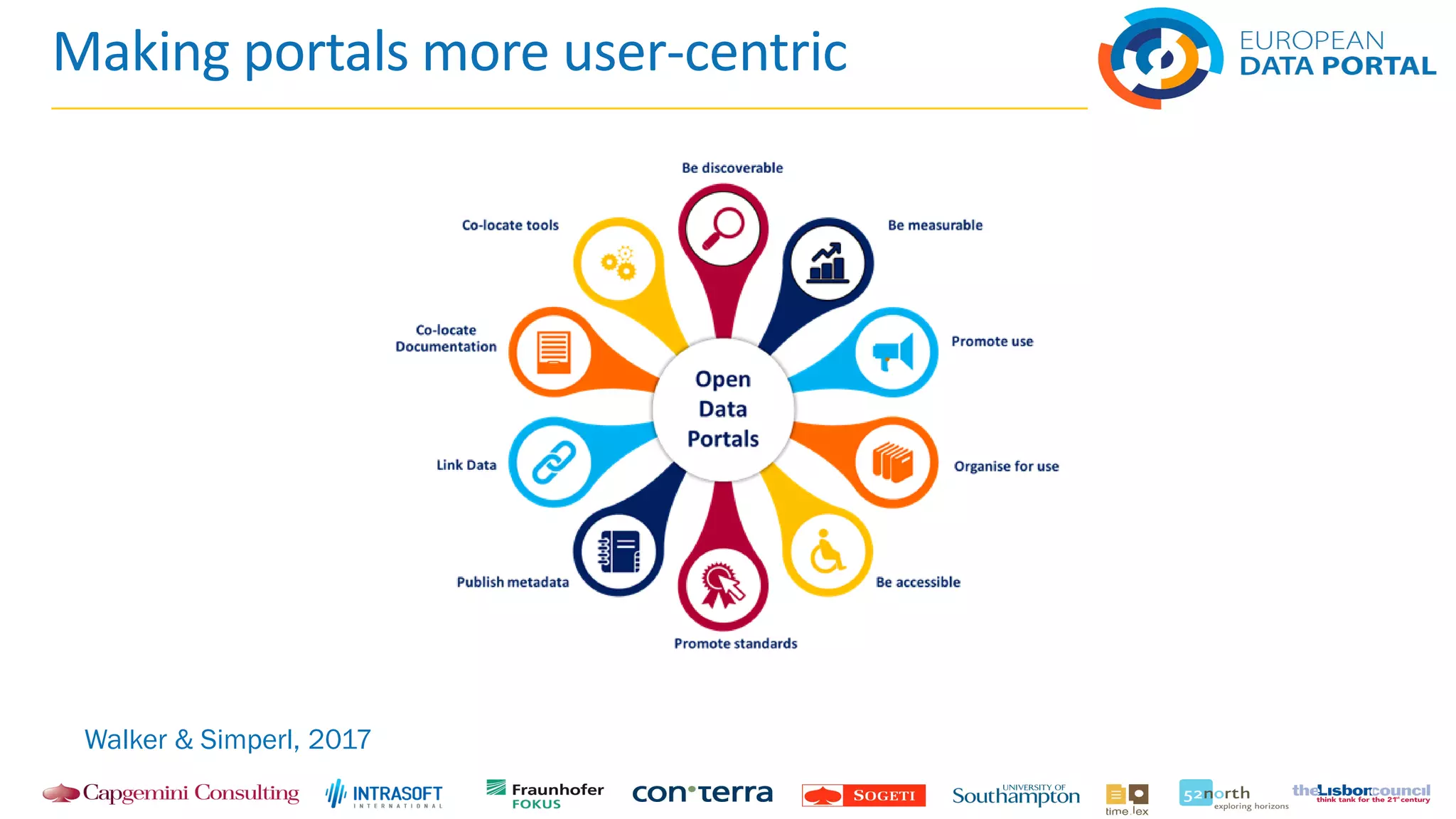
- Open data portals need to improve in areas like adopting standards, co-locating documentation, and making data more usable and discoverable in order to increase data reuse.