





















![Timelapse API
B C
A D
F E
A DD
B C
D
E
AA
F
B C
A D
F E
A DD
B C
D
E
AA
F
Transition
(0.977, 0.968)
(X ,Y): X is 10 iteration PageRank
Y is 23 iteration PageRank
After 11 iteration on graph 2,
Both converge to 3-digit precision
(0.977, 0.968)(0.571, 0.556)
1.224
0.8490.502
(2.33, 2.39)
2.07
0.8490.502
(0.571, 0.556)(0.571, 0.556)
8: Example showing the benefit of PSR computation.
ing master program. For each iteration of Pregel,
ck for the availability of a new graph. When it
able, we stop the iterations on the current graph,
ume resume it on the new graph after copying
e computed results. The new computation will
ve vertices in the new active set continue message
. The new active set is a function of the old active
the changes between the new graph and the old
For a large class of algorithms (e.g. incremental
nk [19]), the new active set includes vertices from
active set, any new vertices and vertices with
dditions and deletions. Listing 2 shows a simple
class Graph[V, E] {
// Collection views
def vertices(sid: Int): Collection[(Id, V)]
def edges(sid: Int): Collection[(Id, Id, E)]
def triplets(sid: Int): Collection[Triplet]
// Graph-parallel computation
def mrTriplets(f: (Triplet) => M,
sum: (M, M) => M,
sids: Array[Int]): Collection[(Int, Id, M)]
// Convenience functions
def mapV(f: (Id, V) => V,
sids: Array[Int]): Graph[V, E]
def mapE(f: (Id, Id, E) => E
sids: Array[Int]): Graph[V, E]
def leftJoinV(v: Collection[(Id, V)],
f: (Id, V, V) => V,
sids: Array[Int]): Graph[V, E]
def leftJoinE(e: Collection[(Id, Id, E)],
f: (Id, Id, E, E) => E,
sids: Array[Int]): Graph[V, E]
def subgraph(vPred: (Id, V) => Boolean,
ePred: (Triplet) => Boolean,
sids: Array[Int]): Graph[V, E]
def reverse(sids: Array[Int]): Graph[V, E]
}
Listing 3: GraphX [24] operators modified to support Tegra’s](https://image.slidesharecdn.com/4panandiyer-160614191710/85/Time-Evolving-Graph-Processing-On-Commodity-Clusters-25-320.jpg)











Time-Evolving Graph Processing On Commodity Clusters
- 1. Tegra: Time-evolving Graph Processing on Commodity Clusters Anand Iyer, Ion Stoica Presented by Ankur Dave
- 2. Graphs are everywhere… Social Networks
- 3. Graphs are everywhere… Gnutella network subgraph
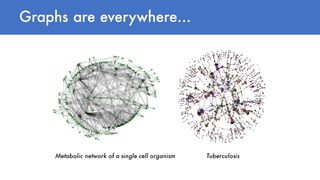
- 5. Graphs are everywhere… Metabolic network of a single cell organism Tuberculosis
- 6. Plenty of interest in processing them • Graph DBMS 25% of all enterprises by 20171 • Many open-source and research prototypes on distributed graph processing frameworks: Giraph, Pregel, GraphLab, Chaos, GraphX, … 1Forrester Research
- 7. Real-world Graphs are Dynamic Many interesting business and research insights possible by processing them… …but little work on incrementally updating computation results or on window-based operations
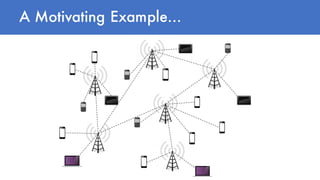
- 10. A Motivating Example… Retrieve the network state when a disruption happened Analyze the evolution of hotspot groups in the last day by hour Track regions of heavy load in the last 10 minutes What factors explain the performance in the network?
- 11. Tegra How do we perform efficient computations on time-evolving, dynamically changing graphs?
- 12. Goals • Create and manage time-evolving graphs • Retrieve the network state when a disruption happened • Temporal analytics on windows • Analyze the evolution of hotspot groups in the last day by hour • Sliding window computations • Track regions of heavy load in the last 10 minutes interval • Mix graph and data parallel computing • What factors explain the performance in the network
- 13. Tegra Graph Snapshot Index Timelapse Abstraction Lightweight Incremental Computations → → Pause-Shift-Resume Computations → →
- 14. Goals • Create and manage time-evolving graphs using Graph Snapshot Index • Retrieve the network state when a disruption happened • Temporal analytics on windows • Analyze the evolution of hotspot groups in the last day by hour • Sliding window computations • Track regions of heavy load in the last 10 minutes interval • Mix graph and data parallel computing • What factors explain the performance in the network
- 15. Representing Evolving Graphs Time A B C G1 A B C δg1 A D δg2 C D E δg3 A B C D G2 A B C D E G3 Snapshots Updates
- 16. E D D A D C E C D A remove add add add add Graph Composition Updating graphs depend on application semantics A B C D G2 A B C D E G3’ C D E δg A + =
- 17. Maintaining Multiple Snapshots Store entire snapshots A B C G1 A B C D G2 A B C D E G3 + Efficient retrieval - Storage overhead Store only deltas A B C δg1 A D δg2 C D E δg3 + Efficient storage - Retrieval overhead
- 18. Maintaining Multiple Snapshots Snapshot 2Snapshot 1 t1 t2 Use a structure-sharing persistent data-structure. Persistent Adaptive Radix Tree (PART) is one solution available for Spark.
- 19. Graph Snapshot Index Snapshot 2Snapshot 1 Vertex t1 t2 Snapshot 2Snapshot 1 t1 t2 Edge Partition Snapshot ID Management
- 20. Graph Windowing A B C G1 A B C D G2 A B C D E G3 A C D E G4 G’1= G3 G’2= G4- G1 Equivalent to GraphReduce() in GraphLINQ, GraphReduceByWindow()in CellIQ G’2= G’1+ δg4 - δg1 G’1= δg1 + δg2 + δg3 A B C δg1 A D δg2 C D E δg3 B δg4
- 21. Goals • Create and manage time-evolving graphs using Distributed Graph Snapshot Index • Retrieve the network state when a disruption happened • Temporal analytics on windows using Timelapse Abstraction • Analyze the evolution of hotspot groups in the last day by hour • Sliding window computations • Track regions of heavy load in the last 10 minutes interval • Mix graph and data parallel computing • What factors explain the performance in the network
- 22. Graph Parallel Computation Many approaches • Vertex centric, edge centric, subgraph centric, …
- 23. Timelapse Operations on windows of snapshots result in redundant computation A B C A B C D A B C D E Time G1 G2 G3
- 24. Timelapse A B C A B C D A B C D E Time G1 G2 G3 D BCBA AAA B C D E • Significant reduction in messages exchanged between graph nodes • Avoids redundant computations Instead, expose the temporal evolution of a node
- 25. Timelapse API B C A D F E A DD B C D E AA F B C A D F E A DD B C D E AA F Transition (0.977, 0.968) (X ,Y): X is 10 iteration PageRank Y is 23 iteration PageRank After 11 iteration on graph 2, Both converge to 3-digit precision (0.977, 0.968)(0.571, 0.556) 1.224 0.8490.502 (2.33, 2.39) 2.07 0.8490.502 (0.571, 0.556)(0.571, 0.556) 8: Example showing the benefit of PSR computation. ing master program. For each iteration of Pregel, ck for the availability of a new graph. When it able, we stop the iterations on the current graph, ume resume it on the new graph after copying e computed results. The new computation will ve vertices in the new active set continue message . The new active set is a function of the old active the changes between the new graph and the old For a large class of algorithms (e.g. incremental nk [19]), the new active set includes vertices from active set, any new vertices and vertices with dditions and deletions. Listing 2 shows a simple class Graph[V, E] { // Collection views def vertices(sid: Int): Collection[(Id, V)] def edges(sid: Int): Collection[(Id, Id, E)] def triplets(sid: Int): Collection[Triplet] // Graph-parallel computation def mrTriplets(f: (Triplet) => M, sum: (M, M) => M, sids: Array[Int]): Collection[(Int, Id, M)] // Convenience functions def mapV(f: (Id, V) => V, sids: Array[Int]): Graph[V, E] def mapE(f: (Id, Id, E) => E sids: Array[Int]): Graph[V, E] def leftJoinV(v: Collection[(Id, V)], f: (Id, V, V) => V, sids: Array[Int]): Graph[V, E] def leftJoinE(e: Collection[(Id, Id, E)], f: (Id, Id, E, E) => E, sids: Array[Int]): Graph[V, E] def subgraph(vPred: (Id, V) => Boolean, ePred: (Triplet) => Boolean, sids: Array[Int]): Graph[V, E] def reverse(sids: Array[Int]): Graph[V, E] } Listing 3: GraphX [24] operators modified to support Tegra’s
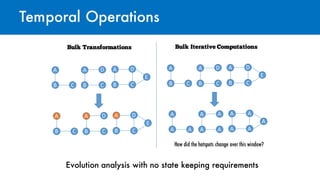
- 26. Temporal Operations Evolution analysis with no state keeping requirements Bulk Transformations A B C A B C D A B C D E A B C A B C D A B C D E Bulk Iterative Computations A B C A B C D A B C D E A A A A A A A A A A A A How did the hotspots change over this window?
- 27. Goals • Create and manage time-evolving graphs using Distributed Graph Snapshot Index • Retrieve the network state when a disruption happened • Temporal analytics on windows using Timelapse Abstraction • Analyze the evolution of hotspot groups in the last day by hour • Sliding window computations • Track regions of heavy load in the last 10 minutes interval • Mix graph and data parallel computing • What factors explain the performance in the network
- 28. Incremental Computation • If results from a previous snapshot is available, how can we reuse them? • Three approaches in the past: • Restart the algorithm • Redundant computations • Memoization (GraphInc1) • Too much state • Operator-wise state (Naiad2,3) • Too much overhead 1Facilitating real- time graph mining, CloudDB ’12 2 Naiad: A timely dataflow system, SOSP ’13 3 Differential dataflow, CIDR ‘13
- 29. Incremental Computation A B C D G1 A B C D E G2 A B C D A A B A A A A A A B C D E A A B A C A A A A A Time → → • Can keep state as an efficient time-evolving graph • Not limited to vertex-centric computations
- 30. Incremental Computation • Some iterative graph algorithms are robust to graph changes • Allow them to proceed without keeping any state A D E B C 0.5570.557 0.5570.557 2.37 A D E B C B 0.5570.557 0.5570.557 2.37 0 A D E B C 0.8470.507 0.8470.507 2.07 B 1.2 →
- 31. Goals • Create and manage time-evolving graphs using Distributed Graph Snapshot Index • Retrieve the network state when a disruption happened • Temporal analytics on windows using Timelapse Abstraction • Analyze the evolution of hotspot groups in the last day by hour • Sliding window computations • Track regions of heavy load in the last 10 minutes interval • Mix graph and data parallel computing • What factors explain the performance in the network
- 32. Implementation & Evaluation • Implemented as a major enhancement to GraphX • Evaluated on two open source real-world graphs • Twitter: 41,652,230 vertices, 1,468,365,182 edges • uk-2007: 105,896,555 vertices, 3,738,733,648 edges
- 33. Preliminary Evaluation ���� �� ���� �� ���� �� ���� �� ���� �� �� �� �� �� �� �� �� �� ��� ������������������� ������������� ����������������������������� ������� ���������� Tegra can pack more snapshots in memory Linear reduction Graph difference significant
- 34. Preliminary Evaluation �� ���� �� ���� �� ���� �� �� �� �� �� �� ����������������� ������������� ������������������������� ������� ���������� Timelapse results in run time reduction
- 35. Preliminary Evaluation Effectiveness of incremental computation 220 45 34 35 37 0 50 100 150 200 250 1 2 3 4 5 ConvergenceTime(s) Snapshot #
- 36. Summary • Processing time-evolving graph efficiently can be useful. • Efficient storage of multiple snapshots and reducing communication between graph nodes key to evolving graph analysis.
- 37. Ongoing Work • Expand timelapse and its incremental computation model to other graph-parallel paradigms • Other interesting graph algorithms: • Fraud detection/prediction/incremental pattern matching • Add graph querying support • Graph queries and analytics in a single system • Stay tuned for code release!