Towards Flink 2.0: Unified Batch & Stream Processing - Aljoscha Krettek, Ververica
Download as PPTX, PDF2 likes461 views

The document presents an overview of ongoing developments and future plans for Apache Flink, focusing on the unification of batch and stream processing through APIs and execution models. Key highlights include the introduction of a unified source interface, enhancements to the datastream API, and a vision for optimizing both bounded and unbounded stream processing. It emphasizes the need for improved performance, fault tolerance, and a reduction in complexity for users through a consolidated approach.
























































Towards Flink 2.0: Unified Batch & Stream Processing - Aljoscha Krettek, Ververica
- 1. © 2019 Ververica Aljoscha Krettek – Software Engineer, Flink PMC, Beam PMC Towards Flink 2.0: Unified Batch & Stream Processing
- 2. © 2019 Ververica2 This is joint work with many members of the Apache Flink community
- 3. © 2019 Ververica3 Some of this presents work that is in progress in the Flink community. Other things are planned and/or have design documents. Some were discussed at one point or another on the mailing lists or in person. This represents our understaning of the current state, this is not a fixed roadmap, Flink is an open-source Apache project.
- 4. © 2019 Ververica4 Agenda How does Flink execute Pipelines? How do users write and operate Pipelines? API s Configuration Execution/OpsExecution Operators Connectors
- 5. © 2019 Ververica The Relationship between Batch and Streaming
- 6. © 2019 Ververica6 Batch Processing is a special case of Stream Processing A batch is just a bounded stream. That is about 60% of the truth…
- 7. © 2019 Ververica7 The remaining 40% of the truth *from the excellent Streaming 101 by Tyler Akidau: https://www.oreilly.com/ideas/the-world-beyond-batch-streaming- 101) The (Event-time) Watermark … never seen this in Batch Processing, though.
- 8. © 2019 Ververica8 The remaining 40% of the truth Continuous Streaming Batch Processing Data is incomplete Latency SLAs Completeness and Latency is a tradeoff Data is as complete as it gets within the job No Low Latency SLAs
- 9. © 2019 Ververica9 Real-time Stream Processing older more recent watermark
- 10. © 2019 Ververica10 Stream Re-Processing older more recent watermark unprocesse d
- 11. © 2019 Ververica11 Batch-style Processing older more recent watermark unprocesse d
- 12. © 2019 Ververica12 Batch and Streaming Processing Styles S S S M M M R R R S S S S S S M M M R R R S S S more batch-y more stream-y running not running can do things one-by-one everything is always-on running
- 13. © 2019 Ververica13 Batch vs. Stream Processing Continuous Streaming Batch Processing Watermarks to model Completeness/Latency tradeoff No Watermarks Incremental results & Proc.-Time Timers Results at end-of- program only In-receive-order ingestion with low parallelism Massively parallel out-of-order ingestion
- 14. © 2019 Ververica14 In Flink DataSet API DataStream API
- 15. © 2019 Ververica Unify what? And why should I care?
- 16. © 2019 Ververica17 Unify what? And why would I care? API: - DataSet - DataStream Connectors: - Source/FinkFunction - Input/OutputFormat Table API/SQL: - Unified APIs - Connectors Runtime: - Operators - Optimization
- 17. © 2019 Ververica18 A Typical “Unified” Use Case: Bootstrapping State “stream ” source “batch” source Stateful operatio n batch-y partstream-y part • We have a streaming use case • We want to bootstrap the state of some operations from a historical source • First execute bounded parts of the graph, then start the rest
- 18. © 2019 Ververica19 Future of the DataStream API • DataStream is already supporting Bounded and Unbounded Streams • Not exploiting batch optimizations so far – Bounded batch-style execution still faster on DataSet API • After Flink 1.10: – Introduce BoundedDataStream and non-incremental mode to exploit optimizations for bounded data – Watermarks "jump" from -∞ to +∞ at end of program – Processing time timers deactivated or deferred (end of key) – DataStream translation and runtime (operators) need to be enhanced to use the added optimization potential
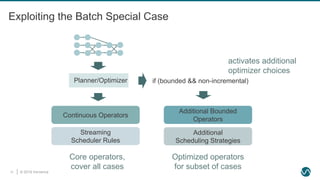
- 19. © 2019 Ververica20 Exploiting the Batch Special Case Planner/Optimizer Continuous Operators Streaming Scheduler Rules Additional Bounded Operators Additional Scheduling Strategies if (bounded && non-incremental) activates additional optimizer choices Core operators, cover all cases Optimized operators for subset of cases
- 20. © 2019 Ververica21 Unify what? And why would I care? API: - DataSet - DataStream Connectors: - Source/FinkFunction - Input/OutputFormat Table API/SQL: - Unified APIs - Connectors Runtime: - Operators - Optimization
- 21. © 2019 Ververica22 Current Source Interfaces Batch: InputFormat Enumerate splits pull() read splits pull() Streaming: SourceFunction JobManager Source Thread push()
- 22. © 2019 Ververica23 A New (unified) Source Interface FLIP-27 Enumerate splits read splits/ thread mgmt ?() JobManager
- 23. © 2019 Ververica24 Unify what? And why would I care? API: - DataSet - DataStream Connectors: - Source/FinkFunction - Input/OutputFormat Table API/SQL: - Unified APIs - Connectors Runtime: - Operators - Optimization
- 24. © 2019 Ververica25 Table API / SQL • Unified API: yes • Unified runtime: yes, with the new Blink-based Table Runner: FLINK- 11439 – but: still runs in either “batch” or “streaming” mode – More work required to make the system automatically decide and optimize • Unified sources: no, eventually yes with FLIP-27
- 25. © 2019 Ververica26 Table API / SQL in Flink 1.9 Table API / SQL Classic Query Processor Flink Task Runtime DataSet StreamTransformation Driver (Pull) StreamOperator (selectable push) New Query Processor* batch env. stream env. batch & stream * Based on the Blink query processor FLINK-11439
- 26. © 2019 Ververica27 Unify what? And why would I care? API: - DataSet - DataStream Connectors: - Source/FinkFunction - Input/OutputFormat Table API/SQL: - Unified APIs - Connectors Runtime: - Operators - Optimization
- 27. © 2019 Ververica28 Push-based and Pull-based Operators accept data from any input immediately (like actor messages) minimize latency supports checkpoint alignment pull data from one input at a time (like reading streams) control over data flow, high-latency, breaks checkpoints pull() pull() Push Operators Pull Operators
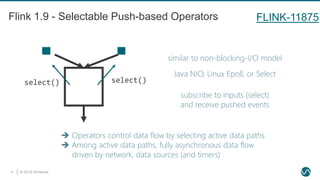
- 28. © 2019 Ververica29 Flink 1.9 - Selectable Push-based Operators subscribe to inputs (select) and receive pushed events Operators control data flow by selecting active data paths Among active data paths, fully asynchronous data flow driven by network, data sources (and timers) similar to non-blocking-I/O model Java NIO, Linux Epoll, or Select select() select() FLINK-11875
- 29. © 2019 Ververica30 Scheduling Strategies • Build pipelined regions – Incremental results: everything pipelines – Non-incremental results: break pipelines once in a while • Recovery: Restart the pipelined region from latest checkpoint (or beginning) – replay input since checkpoint or beginning ✘✘
- 30. © 2019 Ververica Configuration/Ops Vision
- 31. © 2019 Ververica32 How can I enable checkpointing? Only via StreamExecutionEnv.enableCheckpointing() How can I restore from a Savepoint/Checkpoint? Only via bin/flink run -s … How can I run a job on a “remote” cluster? Either bin/flink run or RemoteEnvironment How can I run a job on YARN? Only via bin/flink run* * you could hand-roll other stuff but that’s complicated Let’s do a Quiz
- 32. © 2019 Ververica33 Configuration All the Way Down bin/flink run -c com.mystuff.MyProgram myjar.jar --config my-config.yaml --checkpointing.enabled true --state.backend rocksdb FLIP-59 is the beginning of this effort
- 33. © 2019 Ververica34 A new Executor Abstraction for Executing Jobs bin/flink run -c com.mystuff.MyProgram myjar.jar --executor yarn-per-job --executor.yarn.some-option true FLIP-73 tracks this effort, and then FLIP-74 for the JobClient API java -jar myjar.jar --executor kubernetes-per-job --executor.kubernetes.discombobulator true Using Flink as a library
- 34. © 2019 Ververica Wrapping Up
- 35. © 2019 Ververica36 Preview of new Blink SQL Engine Python Table API Hive support …and lot's more Analytics over Checkpoints/Savepoints Atomic stop-with-savepoint What else is new in Flink 1.9? 🥳
- 36. © 2019 Ververica37 Cross-Batch-Streaming Machine Learning Unaligned Checkpoints Python Table UDFs …and lot's more Interactive multi-job programs a big documentation overhaul What else is the community working on? DDL and Clients for Streaming SQL Full support of Blink SQL Engine and TPC-DS coverage
- 37. © 2019 Ververica38 Thank you! • Try Flink and help us improve it • Contribute docs, code, tutorials • Share your use cases and ideas • Join a Flink Meetup [email protected] @ApacheFlink @VervericaData https://flink.apache.org/
- 38. © 2019 Ververica Thank you! Questions?
- 40. © 2019 Ververica41 Latency vs. Completeness (for geeks) 1977 1980 1983 1999 2002 2005 2015 Processing Time Episode IV Episode V Episode VI Episode I Episode II Episode III Episode VII Event Time 2016 Rogue One III.5 2017 Episode VIII
- 41. © 2019 Ververica FLIP-27: New Source Interface
- 42. © 2019 Ververica43 Current Source Interfaces InputFormat createInputSplits(): splits openSplit(split) assignInputSplit() nextRecord(): T closeCurrentSplit() SourceFunction run(OutputContext) close() batch streaming
- 43. © 2019 Ververica44 Batch InputFormat Processing TaskManager TaskManager TaskManager JobManager (1) request split (2) send split (3) process split • Splits are assigned to TaskManagers by the JobManager, which runs a copy of the InputFormat Flink knows about splits and can be clever about scheduling, be reactive • Splits can be processed in arbitrary order • Split processing pulls records from the InputFormat • InputFormat knows nothing about watermarks, timestamps, checkpointing bad for streaming
- 44. © 2019 Ververica45 Stream SourceFunction Processing • Source have a run-loop that they manage completely on their own • Sources have flexibility and can efficiently work with the source system: batch accesses, dealing with multiple topics from one consumer, threading model, etc… • Flink does not know what’s going on inside and can’t be clever about it • Sources have to implement their own per-partition watermarking, idleness tracking, what have you TaskManagerTaskManager TaskManager (1) do your thing
- 45. © 2019 Ververica46 A New (unified) Source Interface • This must support both batch and streaming use cases, allow Flink to be clever, be able to deal with event-time, watermarks, source idiosyncrasies, and enable snapshotting • This should enable new features: generic idleness detection, event-time alignment* FLIP-27 Source createSplitEnumerator() createSplitReader SplitEnumerator discoverNewSplits() nextSplit() snapshotState() isDone() SplitReader addSplit() hasAvailable(): Future snapshotState() emitNext(Context): Status * FLINK-10886: Event-time alignment for sources; Jamie Grier (Lyft) contributed the first parts of this
- 46. © 2019 Ververica47 A New (unified) SourceInterface: Execution Style I TaskManager TaskManager TaskManager JobManager (1) request split (2) send split (3) process split • Splits are assigned to TaskManagers by the JobManager, which runs a copy of the SplitEnumerator Flink knows about splits and can be clever about scheduling, be reactive • Splits can be processed in arbitrary order • Split processing is driven by the TaskManager working with SplitReader • SplitReader emits watermarks but Flink deals with idleness, per-split watermarking
- 47. © 2019 Ververica48 A New (unified) SourceInterface: Execution Style II
- 48. © 2019 Ververica Current Stack
- 49. © 2019 Ververica50 Runtime Tasks / JobGraph / Network Interconnect / Fault Tolerance DataSet “Operators“ and Drivers / Operator Graph / Visitors DataStream StreamOperators / StreamTransformation Graph* / Monolithic Translators Table API / SQL Logical Nodes* / Different translation paths
- 50. © 2019 Ververica51 What could be improved? • Each API has its own internal graph representation code duplication • Multiple translation components between the different graphs code duplication – DataStream API has an intermediate graph structure: StreamTransformation StreamGraph JobGraph • Separate (incompatible) operator implementations – DataStream API has StreamOperator, DataSet API has Drivers two map operators, two flatMap operators – These are run by different lower-level Tasks – DataSet operators are optimized for different requirements than DataSet operators • Table API is translated to two distinct lower-level APIs two different translation stacks – ”project operator” for DataStream and for DataSet • Connectors for each API are separate a whole bunch of connectors all over the From a system design/code quality/architecture/development perspective
- 51. © 2019 Ververica52 What does this mean for users? • You have to decide between DataSet and DataStream when writing a job – Two (slightly) different APIs, with different capabilities – Different set of supported connectors: no Kafka DataSet connector, no HBase DataStream connector – Different performance characteristics – Different fault-tolerance behavior – Different scheduling logic • With Table API, you only have to learn one API – Still, the set of supported connectors depends on the underlying execution API – Feature set depends on whether there is an implementation for your underlying API • You cannot combine more batch-y with more stream-y sources/sinks • A “soft problem”: with two stacks of everything, less developer power will go into each one individual stack less features, worse performance, more bugs that are fixed slower
- 52. © 2019 Ververica Future Stack
- 53. © 2019 Ververica54 DataSet “Operators“ and Drivers / Operator Graph / Visitors DataStream StreamOperator / StreamTransformation Graph* / Monolithic Translators Batch is a subset of streaming! Can’t we just? ✅❌ Done! 🥳
- 54. © 2019 Ververica55 Unifying the Batch and Streaming APIs • DataStream API functionality is already a superset of DataSet API functionality • We need to introduce BoundedStream to harness optimization potential, semantics are clear from earlier: –No processing-time timers –Watermark “jumps” from –Infinity to +Infinity at end of processing • DataStream translation and runtime (operators) need to be enhanced to use the added optimization potential • Streaming execution is the generic case that always works, “batch” enables additional “optimization rules”: bounded operators, different scheduling we get feature parity automatically ✅ • Sources need to be unified as well see later
- 55. © 2019 Ververica56 Under-the-hood Changes • StreamTransformation/StreamGraph need to be beefed up to carry the additional information about boundedness • Translation, scheduling, deployment, memory management and network stack needs to take this into account Graph Representation / DAG Operator / Task • StreamOperator needs to support batch-style execution see next slide • Network stack must eventually support blocking inputs
- 56. © 2019 Ververica57 Selective Push Model Operator FLINK-11875 batch: pull-based operator (or Driver) streaming: push-based StreamOperator • StreamOperator needs additional API to tell the runtime which input to consume • Network stack/graph needs to be enhanced to deal with blocking inputs, 😱
- 57. © 2019 Ververica58 Table API / SQL • API: easy, it’s already unified ✅ • Translation and runtime (operators) need to be enhanced to use the added optimization potential but use the StreamOperator for both batch and streaming style execution • Streaming execution is the generic case that always works, “batch” enables additional “optimization rules”: bounded operators, different scheduling we get feature parity automatically ✅ • Sources will be unified from the unified source interface ✅ • This is already available in the Blink fork (by Alibaba), FLINK-11439 is the effort of getting that into Flink
- 58. © 2019 Ververica59 StreamTransformation DAG / StreamOperator DataStream “Physical“ Application API Table API / SQL Declarative API Runtime The Future Stack
Editor's Notes
- #11: Time in data stream must be quasi monotonous to produce time progress (watermarks) Always have close-to-latest incremental results Resource requirements change over time Recovery must catch up very fast
- #12: Order of time in data does not matter (parallel unordered reads) Bulk operations (2 phase hash/sort) Longer time for recovery (no low latency SLA) Resource requirements change fast throughout the execution of a single job
- #13: Understanding this difference will help later, when we discuss scheduling changes.
- #15: Different requirements Optimization potential for batch and streaming Also: historic developments and slow-changing organizations
- #18: You have to decide between DataSet and DataStream when writing a job Two (slightly) different APIs, with different capabilities Different set of supported connectors: no Kafka DataSet connector, no HBase DataStream connector Different performance characteristics Different fault-tolerance behavior Different scheduling logic With Table API, you only have to learn one API Still, the set of supported connectors depends on the underlying execution API Feature set depends on whether there is an implementation for your underlying API You cannot combine more batch-y with more stream-y sources/sinks A “soft problem”: with two stacks of everything, less developer power will go into each one individual stack less features, worse performance, more bugs that are fixed slower
- #19: Recall the earlier processing-styles slide: batch wants step by step streaming is all at once This has been mentioned a lot. Lyft has given a talk about this at last FF * FLINK-10886: Event-time alignment for sources; Jamie Grier (Lyft) contributed the first parts of this
- #22: You have to decide between DataSet and DataStream when writing a job Two (slightly) different APIs, with different capabilities Different set of supported connectors: no Kafka DataSet connector, no HBase DataStream connector Different performance characteristics Different fault-tolerance behavior Different scheduling logic With Table API, you only have to learn one API Still, the set of supported connectors depends on the underlying execution API Feature set depends on whether there is an implementation for your underlying API You cannot combine more batch-y with more stream-y sources/sinks A “soft problem”: with two stacks of everything, less developer power will go into each one individual stack less features, worse performance, more bugs that are fixed slower
- #23: Batch: random reads Coordinated by JM Streaming: sequential read No coordination between sources
- #24: This must support both batch and streaming use cases, allow Flink to be clever, be able to deal with event-time, watermarks, source idiosyncrasies, and enable snapshotting This should enable new features: generic idleness detection, event-time alignment* * FLINK-10886: Event-time alignment for sources; Jamie Grier (Lyft) contributed the first parts of this Talk about how this will enable event-time alignment for sources in generic way
- #25: You have to decide between DataSet and DataStream when writing a job Two (slightly) different APIs, with different capabilities Different set of supported connectors: no Kafka DataSet connector, no HBase DataStream connector Different performance characteristics Different fault-tolerance behavior Different scheduling logic With Table API, you only have to learn one API Still, the set of supported connectors depends on the underlying execution API Feature set depends on whether there is an implementation for your underlying API You cannot combine more batch-y with more stream-y sources/sinks A “soft problem”: with two stacks of everything, less developer power will go into each one individual stack less features, worse performance, more bugs that are fixed slower
- #28: You have to decide between DataSet and DataStream when writing a job Two (slightly) different APIs, with different capabilities Different set of supported connectors: no Kafka DataSet connector, no HBase DataStream connector Different performance characteristics Different fault-tolerance behavior Different scheduling logic With Table API, you only have to learn one API Still, the set of supported connectors depends on the underlying execution API Feature set depends on whether there is an implementation for your underlying API You cannot combine more batch-y with more stream-y sources/sinks A “soft problem”: with two stacks of everything, less developer power will go into each one individual stack less features, worse performance, more bugs that are fixed slower
- #35: Mention here that you can basically build your Job Jar that includes flink-runtime, and execute that any way you want: Put it in docker, Spring boot, just start multiple of these. As-a-library mode
- #45: Note that this nicely jibes with the pull-based model. Enables the things we need for batch.
- #46: Mention the dog with the hose. Sources just keep spitting out records as fast as they can.
- #52: Possibly put these on separate slides, with fewer words. Or even some graphics.
- #53: Possibly put these on separate slides, with fewer words. Or even some graphics.
- #56: There are some quirks when you use DataStream for batch a groupReduce would be window with a GlobalWindow MapPartition would have to finalizing things in close() Joins would have to specify global window Of course, state requirements are bad for the naïve approach, i.e. large state, inefficient access patterns Joins and grouping can be a lot faster with specific algorithms Hash Join, Merge join, etc…
- #57: For example different window operator Different join implementations The scheduling stuff and networking would be a whole talk on their own. Memory management is another issue.
- #58: Pull-based operator is how most databases were/are implemented. Note how the pull model enables hash join, merge join, … Side inputs benefit from a pull-based model Bring the dog-drinking-from-hose example, also for Join operator This will allow porting batch operators/algorithms to StreamOperator