Tuning Apache Spark for Large-Scale Workloads Gaoxiang Liu and Sital Kedia
37 likes12,098 views

The document discusses tuning Apache Spark at Facebook for large-scale workloads, addressing key areas such as driver and executor scaling, memory configuration, and fetch failure handling. It emphasizes optimizing performance through dynamic resource allocation, effective memory management, and configuring disk I/O settings. Additionally, it introduces tools for monitoring and analyzing task metrics to improve usability and automate tuning for job performance.






![Multi-threaded Event Processor
[SPARK-18838]
Task
Scheduler
Single
threaded
event
processor
Event
listeners
Event
Queue
Single threaded event processor
architecture
Task
Scheduler
Single threaded
Executor service
per listener
Multi-threaded event processor
architecture](https://image.slidesharecdn.com/074kedialiu-170614194440/85/Tuning-Apache-Spark-for-Large-Scale-Workloads-Gaoxiang-Liu-and-Sital-Kedia-7-320.jpg)
![Better Fetch Failure handling
[SPARK-19753] Avoid multiple retries of stages in case of Fetch Failure
Single fetch failure causing
single retriesSingle fetch failure causing
multiple retries](https://image.slidesharecdn.com/074kedialiu-170614194440/85/Tuning-Apache-Spark-for-Large-Scale-Workloads-Gaoxiang-Liu-and-Sital-Kedia-8-320.jpg)








![Eliminating disk I/O bottleneck
Temporary spill
files on disk
[SPARK-20014] Optimize spill files merging
In-memory spill
file buffers
In-memory
spill merge
Shuffle
Partition
Final shuffle
file on disk
spark.file.transferTo = false
spark.shuffle.file.buffer = 1 MB
spark.shuffle.unsafe.file
.output.buffer = 5 MB](https://image.slidesharecdn.com/074kedialiu-170614194440/85/Tuning-Apache-Spark-for-Large-Scale-Workloads-Gaoxiang-Liu-and-Sital-Kedia-17-320.jpg)














Tuning Apache Spark for Large-Scale Workloads Gaoxiang Liu and Sital Kedia
- 1. Tuning Apache Spark for large- scale workloads Sital Kedia Gaoxiang Liu Facebook
- 2. Agenda • Apache Spark at Facebook • Scaling Spark Driver • Scaling Spark Executor • Scaling External Shuffle • Application tuning • Tools
- 3. • Used for large scale batch workload • Tens of thousands of jobs/day and growing • Running on in the order of thousands of nodes • Job scalability - • Processes hundreds of TBs of compressed input data and shuffle data • Runs hundreds of thousands of tasks Apache Spark at Facebook
- 6. Dynamic Executor Allocation Cluster Manager Task Queue Scheduler Worker Node shuffle service shuffle service shuffle service Executor Request Executor Release Executor • Better Resource utilization • Good for multi-tenant environment spark.dynamicAllocation.enabled = true spark.dynamicAllocation.executorIdleTimeout = 2m spark.dynamicAllocation.minExecutors = 1 spark.dynamicAllocation.maxExecutors = 2000
- 7. Multi-threaded Event Processor [SPARK-18838] Task Scheduler Single threaded event processor Event listeners Event Queue Single threaded event processor architecture Task Scheduler Single threaded Executor service per listener Multi-threaded event processor architecture
- 8. Better Fetch Failure handling [SPARK-19753] Avoid multiple retries of stages in case of Fetch Failure Single fetch failure causing single retriesSingle fetch failure causing multiple retries
- 9. • Avoid duplicate task run in case of Fetch Failure (SPARK-20163) • Configurable max number of Fetch Failures (SPARK-13369) • Ongoing effort (SPARK-20178) Better Fetch Failure handling spark.max.fetch.failures.per.stage = 10
- 10. • Frequent driver OOM when running many tasks in parallel • Huge backlog of RPC requests built on Netty server of the driver • Increase RPC server thread to fix OOM Tune RPC Server threads Scaling Spark Driver spark.rpc.io.serverThreads = 64
- 12. Executor memory layout Shuffle Memory User Memory Reserved Memory (300 MB) Memory Buffer } } } spark.memory.fraction * (spark.executor.memory - 300 MB) (1- spark.memory.fraction) * (spark.executor.memory - 300 MB) spark.yarn.executor.memoryOverhead = 0.1 * (spark.executor.memory)
- 13. Tuning memory configurations Shuffle Memory User Memory Reserved Memory (300 MB) Memory Buffer } } } spark.memory.offHeap.enabled = true spark.memory.offHeap.size = 3g spark.executor.memory = 3g spark.yarn.executor.memoryOverhead = 0.1 * (spark.executor.memory + spark.memory.offHeap.size) Enable off-heap memory
- 14. Tuning memory configurations • Large contiguous in-memory buffers allocated by Spark's shuffle internals. • G1GC suffers from fragmentation due to Humongous Allocations, if object size is more than 32 MB (Maximum region size of G1GC) • Use parallel GC instead of G1GC Garbage collection tuning spark.executor.extraJavaOptions = -XX:ParallelGCThreads=4 -XX:+UseParallelGC
- 15. Eliminating disk I/O bottleneck Sort & Spill to disk Temporary spill files on disk Shuffle Partition Final shuffle files on disk In-memory records
- 16. Eliminating disk I/O bottleneck • Disk access is 10 - 100K times slower than memory access • Make write buffer sizes for disk I/O configurable (SPARK-20074) • Amortize disk I/O cost by doing buffered read/write Tune Shuffle file buffer spark.shuffle.file.buffer = 1 MB spark.unsafe.sorter.spill.reader.buffer.size = 1MB
- 17. Eliminating disk I/O bottleneck Temporary spill files on disk [SPARK-20014] Optimize spill files merging In-memory spill file buffers In-memory spill merge Shuffle Partition Final shuffle file on disk spark.file.transferTo = false spark.shuffle.file.buffer = 1 MB spark.shuffle.unsafe.file .output.buffer = 5 MB
- 18. Eliminating disk I/O bottleneck Tune compression block size Compression block size vs size of shuffle files SizeofShufflefiles(inTB) 130 155 180 205 230 Compression block size 32kb 128kb 512kb 1mb • Default compression block size of 32 kb is sub- optimal • Upto 20% reduction in shuffle/spill file size by increasing the block size spark.io.compression.lz4.blockSize = 512KB
- 19. Various Memory leak fixes and improvements • Memory leak fixes (SPARK-14363, SPARK-17113, SPARK-18208) • Snappy optimization (SPARK-14277) • Reduce update frequency of shuffle bytes written metrics (SPARK-15569) • Configurable initial buffer size for Sorter(SPARK-15958)
- 20. Scaling External Shuffle Service
- 21. Cache Index files on Shuffle Server SPARK-15074 index file partition partition partition Shuffle service Reducer Reducer Shuffle fetch Shuffle fetch Read index file Read partition Read partition Read index file index file partition partition partition Shuffle service Reducer Reducer Shuffle fetch Shuffle fetch Read and cache index file Read partition Read partition spark.shuffle.service.index.cache.entries = 2048
- 22. Scaling External Shuffle Service • Tune shuffle service worker thread and backlog • Configurable shuffle registration timeout and retry (SPARK-20640) spark.shuffle.io.serverThreads = 128 spark.shuffle.io.backLog = 8192 spark.shuffle.registration.timeout = 2m spark.shuffle.registration.maxAttempts = 5
- 23. https://code.facebook.com/posts/1671373793181703
- 25. • Improve performance of job latency (under same amount of resource) • Improve usability - eliminate manual tuning as much as possible to achieve comparable job performance with manually tuned parameters Motivation
- 26. • Heuristics-based approach based on table input size Auto tuning of mapper and reducer • Max cap due to the constrain of the scalability of shuffle service and drivers • Min cap due to the minimum guarantee of resource to user's job
- 27. Tools
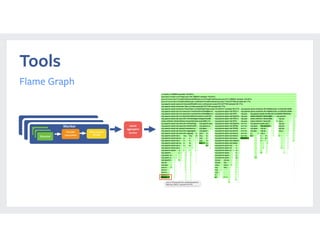
- 29. Tools Flame Graph Executo Periodic Jstack/PerfExecutoExecutor Filter executor threads Worker Jstack aggregator service
- 30. Tools Analysis of Task metrics using Facebook's Scuba Task Scheduler Scuba Event listeners Event Queue • Enables us to do complex queries like - • How many job failed because of OOM in ExternalSorter in last 1 hour? • What percentage of total execution time is being spent in shuffle read? • Did fetch failure rate go up after the last Spark release? • Set up monitoring and alerting to catch regression
- 31. Resources • Scuba: Diving into Data at Facebook • Apache Spark @Scale: A 60 TB+ production use case
- 32. Questions?