Tuning For Deep Learning Inference with Intel® Processor Graphics | SIGGRAPH 2018 Tech Session
Download as PPTX, PDF2 likes1,240 views

This document discusses optimizing deep learning inference on Intel processor graphics using the OpenVINOTM toolkit. Some key points include: - Running inference on client devices provides advantages over cloud like privacy, bandwidth savings, and responsiveness. - OpenVINOTM provides tools to optimize models for Intel hardware and achieve 5-10x speedups on Intel GPUs compared to CPU baselines. - A case study demonstrates optimizing a deep image matting model, reducing inference time from 2.35 seconds to 291 milliseconds on Intel GPU using OpenVINOTM. - Emerging technologies like federated learning are discussed which could improve privacy for on-device inference.












![17
Tech Transfer Challenges
• Resolution (320 x 320)
• Model size (80 MB)
• Memory
• Run time performance
• Cross platform support
Image Credits: Deep Image Matting [Xu et. al; CVPR 2017]](https://image.slidesharecdn.com/manujsabharwalandsaliltambeaiedgeinteladobe100-181002230457/85/Tuning-For-Deep-Learning-Inference-with-Intel-Processor-Graphics-SIGGRAPH-2018-Tech-Session-17-320.jpg)
![Inference per Tile
Conv2
[160 x 160 x 128]
Conv1
[320 x 320 x 64]
Conv4
[40 x 40 x 512]
Alpha
Prediction
[320 x 320 x 1]
Conv3
[80 x 80 x 256] Deconv4
[40 x 40 x 256]
Deconv3
[80 x 80 x 128]
Deconv1
[320 x 320 x 64]
Conv5
[20 x 20 x 512]
Deconv5
[20 x 20 x 512]
Deconv2
[160 x 160 x 64]](https://image.slidesharecdn.com/manujsabharwalandsaliltambeaiedgeinteladobe100-181002230457/85/Tuning-For-Deep-Learning-Inference-with-Intel-Processor-Graphics-SIGGRAPH-2018-Tech-Session-18-320.jpg)




![23
Supporting custom layers
Custom layers are the layers that are not included into a list of known layers.
If your topology contains any layers that are not in the list, the Model Optimizer classifies them as custom
Solution
Register those layers as extensions to the Model Optimize
Registering rules to pass Extension Layer properties from model to IR
New primitives are now part of OpenVINO™
Step-1 convert model to intermediate
representation (ir)
class pooling(Op):
op = 'Pooling'
def __init__(self, graph, attrs):
super().__init__(graph, {
'type': __class__.op,
'op': __class__.op,
'infer': pooling.pooling_infer},
attrs)
def supported_attrs(self):
return ['stride-y','stride-x','pad-y','pad-
x','kernel-y','kernel-x','pool-method','rounding-type']
class CustomPoolingFrontExtractor(FrontExtractorOp):
op = 'Pooling'
@staticmethod
def extract(node):
proto_layer = node.pb
param = proto_layer.pooling_param
mapping_rule = {
'stride-y':param.stride,
'stride-x':param.stride,
'type':'Pooling',
'pool':param.pool,
'kernel-y': param.kernel_size,
'kernel-x': param.kernel_size,
'pool-method':"max",
'rounding-type':"ceil",
}](https://image.slidesharecdn.com/manujsabharwalandsaliltambeaiedgeinteladobe100-181002230457/85/Tuning-For-Deep-Learning-Inference-with-Intel-Processor-Graphics-SIGGRAPH-2018-Tech-Session-23-320.jpg)
![24
Step-2 : integrating code into
inference engine
InferenceEngine::CNNNetReader net_reader;
net_reader.ReadNetwork(model.data(), model.length())); Read model from memory or directly load file
// 256 is a size in bytes!
InferenceEngine::TBlob<uint8_t> *weights = new InferenceEngine::TBlob<uint8_t>(InferenceEngine::Precision::U8, InferenceEngine::C, {256});
weights->allocate();
fill_data((float *) weights->buffer(), weights->size() / sizeof(float)); // Fill weights from model
InferenceEngine::TBlob<uint8_t>::Ptr weights_ptr = InferenceEngine::TBlob<uint8_t>::Ptr(weights);
net_reader.SetWeights(weights_ptr);
net_reader.getNetwork();
InputsDataMap inputInfo(network.getInputsInfo()); // Stores all input blobs data
BlobMap inputBlobs;
ExecutableNetwork executable_network = plugin.LoadNetwork(network, {});
InferRequest infer_request = executable_network.CreateInferRequest();
// Fill input image to data buffer
data[image_id * image_size * num_channels + ch * image_size + pid] = imagesData.at(image_id).get()[pid*num_channels + ch];
// Start Infer (This can be Async infer too)
Infer_request.Infer();
const Blob::Ptr output_blob = infer_request.GetBlob(firstOutputName);
const auto output_data = output_blob->buffer().as<float*>();](https://image.slidesharecdn.com/manujsabharwalandsaliltambeaiedgeinteladobe100-181002230457/85/Tuning-For-Deep-Learning-Inference-with-Intel-Processor-Graphics-SIGGRAPH-2018-Tech-Session-24-320.jpg)










Tuning For Deep Learning Inference with Intel® Processor Graphics | SIGGRAPH 2018 Tech Session
- 1. Salil Tambe, Adobe Manuj Sabharwal, Intel
- 2. 2 Agenda • Why Deep Learning inference on Client – Advantages of running Intelligence on Client – Inference use cases on edge platform • Tools to get the best from Intel® Processor Graphics • Case Study • Emerging Deep Learning Technologies • Summary
- 3. 3 Advantage of running intelligence on client Trust & privacy Network Bandwidth Responsi veness Service Cost 30% 5%20%
- 4. 4 Intelligence use cases on client - Examples Cyberlink* PowerDirector – Style Transfer2 Unity* ML Agents - Bringing intelligence to game on client4 1https://theblog.adobe.com/premiere-pro-updates-spring-2018/ 2https://www.cyberlink.com/products/creative-design-packs/ai_en_US.html 3 https://github.com/msmsajjadi/frvsr 4https://github.com/Unity-Technologies/ml-agents 1Color Match powered by Adobe® Sensei™ 3State of Art – Frame Recurrent Video super resolution – Sajjadi etl. *Other names and brands may be claimed as the property of others.
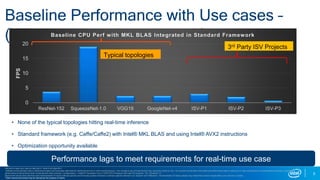
- 5. 5 Baseline Performance with Use cases – (What you may have heard ) • None of the typical topologies hitting real-time inference • Standard framework (e.g. Caffe/Caffe2) with Intel® MKL BLAS and using Intel® AVX2 instructions • Optimization opportunity available 0 5 10 15 20 ResNet-152 SqueezeNet-1.0 VGG19 GoogleNet-v4 ISV-P1 ISV-P2 ISV-P3 FPS Baseline CPU Perf with MKL BLAS Integrated in Standard Framework Typical topologies 3rd Party ISV Projects Standard image input used as describe in “state of art algorithm”. Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors.. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. Configurations: - Intel® 6th Generation Core i7-6700 CPU Processor with Intel HD Graphics. OS : Windows* 10 Benchmark results were obtained post implementation of recent software patches and firmware updates intended to address exploits referred to as “Spectre” and “Meltdown.” Implementation of these updates may make these results inapplicable to your device or system. Performance lags to meet requirements for real-time use case *Other names and brands may be claimed as the property of others.
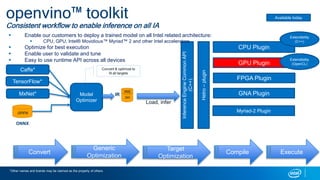
- 6. 6 openvino™ toolkit Consistent workflow to enable inference on all IA Caffe* TensorFlow* MxNet* Convert & optimize to fit all targets InferenceEngineCommonAPI (C++) Load, infer CPU Plugin GPU Plugin FPGA Plugin Myriad-2 Plugin Hetro–plugin Model Optimizer GNA Plugin Extendibility (C++) Extendibility (OpenCL) Available today .bin IR .XML Convert Generic Optimization Target Optimization Compile Execute Enable our customers to deploy a trained model on all Intel related architecture: CPU, GPU, Intel® Movidious™ Myriad™ 2 and other Intel accelerators Optimize for best execution Enable user to validate and tune Easy to use runtime API across all devices ONNX .onnx *Other names and brands may be claimed as the property of others.
- 7. 7 Why Intel® processor Graphics ? https://software.intel.com/sites/default/files/managed/c5/9a/The-Compute-Architecture-of-Intel-Processor-Graphics-Gen9-v1d0.pdf On millions of SoC Free for consumers No need to buy special HW Better battery life based on use case Better performance based on use case
- 8. 8 Using the Inference Engine API (this is working code!) IRSerializer reader; reader.Open("GoogleNet.xml"); reader.ReadWeights("GoogleNet.bin"); Network net = reader.GetNetwork(); InfEng engine(TargetDevice::GPU); auto exec = engine.Compile(net); // optionally compilation can be saved: exec.save(“GoogleNet.nnx”); auto inData = make_shared_blob<float>({ 0.1f,0.2f,0.3f,0.4f,0.5f }); auto outData = exec.Infer(inData); const LockedMemory<const float> pfOut = outData->readOnly(); // read output … 1. Read network from IR 2. Select Target 3. Compile & Load 4. Execute…
- 9. 9 Advantage of using OpenVINO™ • Easy installation on Windows* and Linux* • Visual Studio* integration • C++ Support • Extensibility support • Developers can add new primitives to support new operators • One API support across different hardware • Size overhead < 10MB additional file for enabling for Intel GPU • Model optimizer can fuse layers to give significant improvement on file size *Other names and brands may be claimed as the property of others.
- 10. 10 performance using cldnn kernels through openvino™ 3.8 19.0 2.3 2.3 3.0 2.0 1.0 17.5 173.7 18.1 13.1 27.0 20.5 9.9 0 20 40 60 80 100 120 140 160 180 200 ResNet-152 SqueezeNet-1.0 VGG19 GoogleNet-v4 ISV-P1 ISV-P2 ISV-P3 FPS Performance Increase due to Intel GPU Baseline clDNN (FP16) 5-10x performance increase with optimized software stack Optimized Software + Hardware == Better Performance Intel GPU provides 5-10x performance increase vs. baseline with no extra cost to hardware and low power Standard image input used as describe in “state of art algorithm”. Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors.. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. Configurations: - Intel® 6th Generation Core i7-6700 CPU Processor with Intel HD Graphics. OS : Windows* 10 Benchmark results were obtained post implementation of recent software patches and firmware updates intended to address exploits referred to as “Spectre” and “Meltdown.” Implementation of these updates may make these results inapplicable to your device or system. *Other names and brands may be claimed as the property of others.
- 11. 11 Adobe® deep matte Proof of concept optimizations on intel GPU using openvino™ *Other names and brands may be claimed as the property of others.
- 12. 12 Select & Mask in Photoshop* *Other names and brands may be claimed as the property of others.
- 13. 13 Select & Mask in Photoshop* *Other names and brands may be claimed as the property of others.
- 14. 14 Matting in Photoshop* *Other names and brands may be claimed as the property of others.
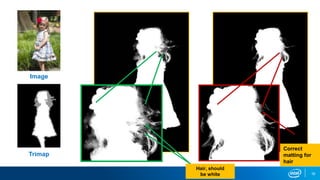
- 15. 15 Deep Matting Image Input Output Xu et al. Deep Image Matting. CVPR 2017.
- 17. 17 Tech Transfer Challenges • Resolution (320 x 320) • Model size (80 MB) • Memory • Run time performance • Cross platform support Image Credits: Deep Image Matting [Xu et. al; CVPR 2017]
- 18. Inference per Tile Conv2 [160 x 160 x 128] Conv1 [320 x 320 x 64] Conv4 [40 x 40 x 512] Alpha Prediction [320 x 320 x 1] Conv3 [80 x 80 x 256] Deconv4 [40 x 40 x 256] Deconv3 [80 x 80 x 128] Deconv1 [320 x 320 x 64] Conv5 [20 x 20 x 512] Deconv5 [20 x 20 x 512] Deconv2 [160 x 160 x 64]
- 21. 21 Initial implementation performance Common issues Threading is not optimal Reordering of data structure between layers increases compute time 2.35 seconds One Frame Standard image input used as describe in “state of art algorithm”. Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors.. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. Configurations: - Intel® 8th Generation 8250U (4C:8T) CPU Processor with Intel HD Graphics. OS : Windows* 10 • Memory Utilized ~3GB
- 22. 22 Optimizing for intel® Processor graphics
- 23. 23 Supporting custom layers Custom layers are the layers that are not included into a list of known layers. If your topology contains any layers that are not in the list, the Model Optimizer classifies them as custom Solution Register those layers as extensions to the Model Optimize Registering rules to pass Extension Layer properties from model to IR New primitives are now part of OpenVINO™ Step-1 convert model to intermediate representation (ir) class pooling(Op): op = 'Pooling' def __init__(self, graph, attrs): super().__init__(graph, { 'type': __class__.op, 'op': __class__.op, 'infer': pooling.pooling_infer}, attrs) def supported_attrs(self): return ['stride-y','stride-x','pad-y','pad- x','kernel-y','kernel-x','pool-method','rounding-type'] class CustomPoolingFrontExtractor(FrontExtractorOp): op = 'Pooling' @staticmethod def extract(node): proto_layer = node.pb param = proto_layer.pooling_param mapping_rule = { 'stride-y':param.stride, 'stride-x':param.stride, 'type':'Pooling', 'pool':param.pool, 'kernel-y': param.kernel_size, 'kernel-x': param.kernel_size, 'pool-method':"max", 'rounding-type':"ceil", }
- 24. 24 Step-2 : integrating code into inference engine InferenceEngine::CNNNetReader net_reader; net_reader.ReadNetwork(model.data(), model.length())); Read model from memory or directly load file // 256 is a size in bytes! InferenceEngine::TBlob<uint8_t> *weights = new InferenceEngine::TBlob<uint8_t>(InferenceEngine::Precision::U8, InferenceEngine::C, {256}); weights->allocate(); fill_data((float *) weights->buffer(), weights->size() / sizeof(float)); // Fill weights from model InferenceEngine::TBlob<uint8_t>::Ptr weights_ptr = InferenceEngine::TBlob<uint8_t>::Ptr(weights); net_reader.SetWeights(weights_ptr); net_reader.getNetwork(); InputsDataMap inputInfo(network.getInputsInfo()); // Stores all input blobs data BlobMap inputBlobs; ExecutableNetwork executable_network = plugin.LoadNetwork(network, {}); InferRequest infer_request = executable_network.CreateInferRequest(); // Fill input image to data buffer data[image_id * image_size * num_channels + ch * image_size + pid] = imagesData.at(image_id).get()[pid*num_channels + ch]; // Start Infer (This can be Async infer too) Infer_request.Infer(); const Blob::Ptr output_blob = infer_request.GetBlob(firstOutputName); const auto output_data = output_blob->buffer().as<float*>();
- 25. 25 How performance looks with openvino™ using cldnn OpenVINO™ SDK enables Intel GPU path without change of API call Free performance boost on millions of PC shipped with integrated GPU Enabled custom kernel through device code FP16 implementation should give up to 1.8x perf boost CPU GPU (FP32) Package (SoC) Power 26.9W 21.9W Performance 2.35 seconds 291msec 22% less power and 8x faster compared to Intel GPU solution with no additional hardware cost 291msec Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors.. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. Configurations: - Intel® 8th Generation 8250U (4C:8T) CPU Processor with Intel HD Graphics. OS : Windows* 10
- 26. 26 How about memory usage? ~700MB used for 320x320 image Default Implementation Using OpenVINO™ OpenVINO™ optimized the model for efficient memory which is important for client based platform Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors.. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. Configurations: - Intel® 8th Generation 8250U (4C:8T) CPU Processor with Intel HD Graphics. OS : Windows* 10
- 27. 27 Examples of Emerging AI Technologies – Federated Learning* Federated learning or Collaborative learning is where multiple devices participate in the machine learning process (training or inferencing). Federated learning decouples storage from the machine learning process * Concept introduced by Google (April 2017) Cloud Device A Device B Device C
- 28. 28 End-to-end deep learning on intel Store Distribute Deliver Proces s Analyze Ingest Proces s Capture Transmit Ingest Store Process Analyze Process Distribute Delivery Consume On-Device Processing Wi-Fi 5G Ethernet Edge Ingest Processing & Storage Ingest Process Distributio n Process Analyze & Manipulate Storage Edge Delivery Processing & Storage Wi-Fi 5G Ethernet On Device Processing
- 29. 29 Using optimized libraries , software stacks and SDK can give 7-10x performance boost on same hardware Intel GPU can give boost in performance with lower power compared to CPU with no additional cost to consumer/developer (depending on topologies) Boost in performance on millions of PC shipped with Intel® Processor Graphics OpenVINO™ makes it simple to start developer on Windows* It provides better performance and efficient memory for deployment Heterogeneous support of running multiple models on different IP Call to developers/communities Re-think about bringing inference offline to Intel GPU Summary *Other names and brands may be claimed as the property of others.
- 31. 31 references • https://software.intel.com/en-us/openvino-toolkit • https://github.com/intel/clDNN • https://github.com/intel/mkl-dnn • https://software.intel.com/en-us/articles/accelerate-deep-learning-inference- with-integrated-intel-processor-graphics-rev-2-0 • https://software.intel.com/en-us/articles/background-on-ai-and-the-move-to- the-edge • https://software.intel.com/sites/default/files/managed/c5/9a/The-Compute- Architecture-of-Intel-Processor-Graphics-Gen9-v1d0.pdf
- 32. 32 Acronyms • Compute Library for Deep Neural Networks (clDNN) • Intel® Math Kernel Library (Intel® MKL) • Intel® Advanced Vector Extensions 2 (Intel® AVX2) • Intel Architecture (IA) • Intermediate Representation (IR) • Independent software vendor (ISV)
- 33. 33 Legal Disclaimers and Optimization NoticesNo license (express or implied, by estoppel or otherwise) to any intellectual property rights is granted by this document. Intel disclaims all express and implied warranties, including without limitation, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement, as well as any warranty arising from course of performance, course of dealing, or usage in trade. This document contains information on products, services and/or processes in development. All information provided here is subject to change without notice. Contact your Intel representative to obtain the latest forecast, schedule, specifications and roadmaps. The products and services described may contain defects or errors known as errata which may cause deviations from published specifications. Current characterized errata are available on request. Intel technologies' features and benefits depend on system configuration and may require enabled hardware, software or service activation. Performance varies depending on system configuration. No computer system can be absolutely secure. Check with your system manufacturer or retailer or learn more at intel.com. Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more information go to www.intel.com/benchmarks Benchmark results were obtained prior to implementation of recent software patches and firmware updates intended to address exploits referred to as "Spectre" and "Meltdown". Implementation of these updates may make these results inapplicable to your device or system. Intel, Openvino, Movidius, Myriad and the Intel logo are trademarks of Intel Corporation or its subsidiaries in the U.S. and/or other countries. *Other names and brands may be claimed as the property of others © Intel Corporation.
Editor's Notes
- #7: MxNet = Amazon .XML – NN topology .bin – weights (array of floats) .nif – topology .data – weights in a .tar file format Currently IR format, moving to NIF Q2 Load, infer = load model and do inference Common API for C++ application Hetro = heterogeneous plug-in – can run part on FPGA, part on GNA, … GNA plug-in was released to Amazon GNA-s will be ready later, TBD Generic Optimization – on model Target Optimization – per inference plug-in Each plug-in – target optimization, compile (in inference engine [e.g., layer descriptors for GNA], per target), and execute
- #29: What it takes to win – End to end etc Ubiquity Xeon footprint + network + dev community reach (optimization)