Tutorial(release)
Download as PPTX, PDF1 like860 views

Kafka is a distributed publish-subscribe system that is well-suited for building real-time data pipelines and streaming applications. It addresses issues that arise from scaling these applications, such as decoupling data producers and consumers and supporting parallel data processing. Kafka uses topics to organize streams of records called messages, which are partitioned and can be replicated across multiple servers. Producers write data to topics and consumers read from topics in a pull-based fashion coordinated by Zookeeper.


































































Tutorial(release)
- 1. MODERN TECHNOLOGIES IN DATA SCIENCE CHIH-CHIEH HUNG CHU-CHENG HSIEH
- 3. WE WILL COVER… • 9:00-10:40 1. Introduction of Big Data System 2. Brief Introduction of NoSQL 3. Good Practice of Cassandra Modeling 4. Introduction of Kafka • 11:10-12:30 1. Map-Reduce 2. Introduction of Spark 3. Spark Ecosystem
- 4. RAKUTEN INC. • The biggest e-commerce company in Japan • Business model:
- 6. SYSTEM REQUIREMENTS • General system requirements • Handle millions of user • Support collection and storage of complex data • Real-time system requirements • Quickly retrieve subsets of single user’s data • Aggregate/derive new analytics results per user
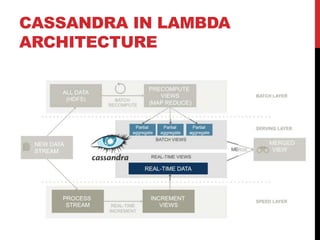
- 7. LAMBDA ARCHITECTURE FOR BIG DATA SYSTEMS
- 8. LAMBDA ARCHITECTURE WITH STATE-OF-ART TECHNOLOGIES
- 9. LET’S START FROM NOSQL
- 11. HELLO! NOSQL! • NoSQL = Not Only SQL • NoSQL = data storage • Schema-less • Dumb in joining data
- 12. CAP DEFINITION (1/3) • Consistency • Data is consistent and the same for all nodes
- 13. CAP DEFINITION (2/3) • Availability • Every request to non-failing node should be processed and receive response
- 14. CAP DEFINITION (3/3) • Partition-Tolerance • If some nodes crash/communication fails, service will performs as expected
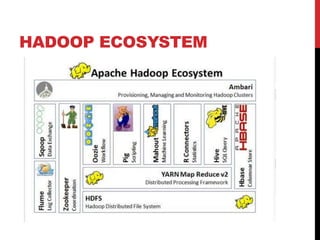
- 16. HADOOP ECOSYSTEM
- 17. YARN ARCHITECTURE (MR V2) Master Node Slave Nodes
- 18. RUNNING AN APPLICATION IN YARN (1/3)
- 19. RUNNING AN APPLICATION IN YARN (2/3)
- 20. RUNNING AN APPLICATION IN YARN (3/3)
- 22. C* ARCHITECTURE • Cluster: Ring • Peer-to-Peer model • Gossip protocol Coordination node DATA
- 23. WRITE IN C*
- 24. READ IN C*
- 25. POWER OF C* • Elastic • R/W throughput increases linearly as new machines are added • Decentralized • Fault tolerant with no single point of failure; no “master” node
- 26. GOOD PRACTICE OF CASSANDRA MODELING *. Some ideas are from: 1. http://www.ebaytechblog.com/2012/07/16/cassandra-data-modeling-best-practices- part-1 2. http://www.ebaytechblog.com/2012/07/16/cassandra-data-modeling-best-practices- part-2
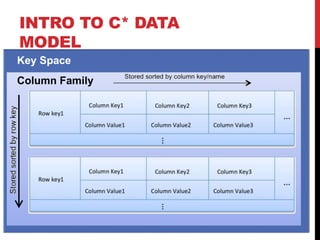
- 28. INTRO TO C* DATA MODEL Column Family Key Space
- 29. FOR NEW COMERS • We could think in the this way: Column Family (Table) Key Space (Database) (Primary Key)
- 30. PRINCIPLE #1: • Sorted map = efficient key lookup • E.g., Getting the employees from id=5~id=10. Age 27 Name Steve State California Age 29 Name Chris State Montana Age 37 Name Ken State California 1 2 150
- 31. PRINCIPLE #2 • Storing value in column name is perfectly ok • Column key maximum: 64KB • Use wide row for ordering, grouping and filtering • e.g.: Items sold per state per city CA|San Diego 3000 CA|San Jose 207 NV|Las Vegas 10000 NV|Reno 3227 9527
- 32. PRINCIPLE #3 • Choose a proper row key • E.g.: Query: date, state # of sales. Which is better? CA|San Diego 3000 UT|Ogden 10000 UT|Salt Lake 3227 San Diego 3000 Sunnyvale 10000 20150409 20150409|CA A B
- 33. PRINCIPLE #4 • Order of composite column name matters • E.g., Two composite namings make two group ways 20150401|Buy 5 20150401|Sell 2 20150409|Buy 0 20150409|Sell 10 123 Buy|20150401 5 Buy|20150409 0 Sell|20150401 2 Sell|20150409 10 123 A B
- 34. PRINCIPLE #5 • Make sure the column key and row key are unique • Otherwise, data could easily get accidentally overwritten.
- 35. PRINCIPLE #6 • Split hot & cold data in separate column families • E.g., Better to split into two cf *. Examples are from: http://www.ebaytechblog.com/2012/07/16/cassandra-data-modeling- best-practices-part-1
- 36. PRINCIPLE #7 • Keep all data in a single column family of the same type • E.g., better to break into multiple cf User|Name Oshin Buy|1234 1 View|1234 4 20150409 User|Email [email protected]
- 37. PRINCIPLE #8 (1/7) • De-normalize and duplicate for read performance • In relational world: PRO CON 1. Less data duplication 2. Fewer data modification anomalies 3. Conceptual clear 4. Easy to maintain 1. Queries might perform slowly if many table are joined. 10x worse in C*
- 38. PRINCIPLE #8 (2/7) • Example: ‘Like’ relationship between User and Item *. Examples are from: http://www.ebaytechblog.com/2012/07/16/cassandra-data-modeling- best-practices-part-1
- 39. PRICIPLE #8 (3/7) • Want to perform 4 queries: 1. Get user info by user ID 2. Get item info by item ID 3. Get all items that a given user likes 4. Get all users who like a given item
- 40. PRINCIPLE #8 (4/7) • Option 1: 1. Get user info by user ID 2. Get item info by item ID 3. Get all items that a given user likes 4. Get all users who like a given item
- 41. PRINCIPLE #8 (5/7) • Option 2: 1. Get user info by user ID 2. Get item info by item ID 3. Get all items that a given user likes 4. Get all users who like a given item
- 42. PRINCIPLE #8 (6/7) • Option 3: 1. Get user info by user ID 2. Get item info by item ID 3. Get all items that a given user likes 4. Get all users who like a given item
- 43. PRINCIPLE #8 (7/7) • Option 4: 1. Get user info by user ID 2. Get item info by item ID 3. Get all items that a given user likes 4. Get all users who like a given item
- 44. SUMMARY • Think about query patterns and indexing from beginning
- 45. APACHE KAFKA
- 47. WHAT IS KAFKA? IN ONE SENTENCE Kafka is a distributed publish-subscribe system designed for web-scale stream processing Created by Linkedin, contributed to Apache in 2011 Written in Scala Multi-language support for Consumer API (Scala, Java, Ruby, Python, C++, Go, php…)
- 48. WHAT IS KAFKA? IN ONE GRAPH
- 49. WHY WE NEED KAFKA? Story starts with just one data pipeline
- 50. WHY WE NEED KAFKA? Reuse of data pipelines for new providers
- 51. WHY WE NEED KAFKA? Reuse of existing providers for new consumers
- 52. WHY WE NEED KAFKA? Eventually the solution becomes the problem
- 53. WHY WE NEED KAFKA? Kafka decouples data-pipelines
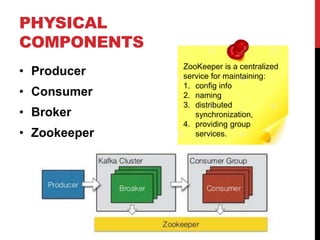
- 54. PHYSICAL COMPONENTS • Producer • Consumer • Broker • Zookeeper ZooKeeper is a centralized service for maintaining: 1. config info 2. naming 3. distributed synchronization, 4. providing group services.
- 55. LOGICAL COMPONENTS • Topics • The feed name where msg are published • Partitions • 1 topic = n partitions • Message • key/value pair
- 56. MESSAGE FROM PRODUCER TO BROKER • Kafka can guarantee messages are handled in FIFO order. • Three modes: • At most once (Async) • At least once (Sync) • Exactly once (not support until v0.9)
- 57. TOPIC • Feed name to which messages are published • Example: zerg.hydra
- 58. PARTITION, CONSUMER (1/3) • Queue model • 1 Topic • 1 Partition • 1 Consumer
- 59. PARTITION, CONSUMER (2/3) • Pub/Sub Model • 1 Topic • 1 Partition • N Consumer
- 60. PARTITION, CONSUMER (3/3) • Pub/Sub Model • 1 Topic • N Partition • N Consumer
- 61. TOPICS, PARTITIONS, REPLICAS *. Thanks: http://www.michael-noll.com/blog/2013/03/13/running-a-multi-broker-apache- kafka-cluster-on-a-single-node/
- 62. PUT IT TOGETHER *. Thanks: http://www.michael-noll.com/blog/2013/03/13/running-a-multi-broker- apache-kafka-cluster-on-a-single-node/ • Partition: 3 • Replica: 2
- 63. CONSUMER GROUP • Multiple high-level consumers can participate in a single consumer group. • Coordinated by zookeeper • Each partition will be consumed by exactly one consumer. • Share offsets
- 64. LOG COMPACTION • Many data system retain a latest state for data by some key • Log compaction:
- 65. CODE PIECES • Create topic $ bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic zerg.hydra --partitions 3 --replication- factor 2
- 66. CODE PIECES • Inspect the config of a topic
- 67. CODE PIECES • Start a producer • After that, type some messages in console: $ bin/kafka-console-producer.sh --broker-list localhost:9092,localhost:9093,localhost:9094 --sync --topic zerg.hydra Hello world! Rock: Nerf Paper. Scissors is fine.
- 68. CODE PIECES • Start a consumer • After starting a consumer, in the end of the output: $ bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic zerg.hydra --from- beginning Hello world! Rock: Nerf Paper. Scissors is fine.
- 69. SUMMARY
Editor's Notes
- #8: The batch layer has two functions: a. Manage the master dataset, an immutable, append-only set of raw data. b. Pre-compute the batch views. 3. The serving layer indexes the batch views so that they can be queried in low-latency, ad-hoc way. 4. The speed layer compensates for the high latency of updates to the serving layer and deals with recent data only, providing real-time views.
- #9: 1. Batch layer: immutable, batch read, append only hadoop/spark 2. Speed layer: mutable, random write/read storm, spark streaming 3. Serving layer: immutable, random read, batch write Cassandra
- #11: 1. Batch layer: immutable, batch read, append only hadoop/spark 2. Speed layer: mutable, random write/read storm, spark streaming 3. Serving layer: immutable, random read, batch write Cassandra
- #18: Resource Manager: Runs on master node Global resource scheduler Manage system resources between competing application Node manager: Runs on slave nodes Communicates with RM Containers Created by RM upon request Allocate resources (now memory only) Applications run in one or more containers Application Master One per application Runs in a container Requests more containers to run application tasks
- #24: The memtable is a write-back cache of data partitions that Cassandra looks up by key. The more a table is used, the larger its memtable needs to be. Cassandra can dynamically allocate the right amount of memory for the memtable or you can manage the amount of memory being utilized yourself. The memtable, unlike a write-through cache, stores writes until reaching a limit, and then is flushed.
- #25: When a read request for a row comes in to a node, the row must be combined from all SSTables on that node that contain columns from the row in question, as well as from any unflushed memtables, to produce the requested data.
- #26: Also talk about C* suitable for serving layer: R/W good No single point failure -> always can response queries
- #28: 1. Batch layer: immutable, batch read, append only hadoop/spark 2. Speed layer: mutable, random write/read storm, spark streaming 3. Serving layer: immutable, random read, batch write Cassandra
- #41: Not easy to do 3 and 4
- #42: Ok,
- #47: 1. Batch layer: immutable, batch read, append only hadoop/spark 2. Speed layer: mutable, random write/read storm, spark streaming 3. Serving layer: immutable, random read, batch write Cassandra
- #70: 1. Batch layer: immutable, batch read, append only hadoop/spark 2. Speed layer: mutable, random write/read storm, spark streaming 3. Serving layer: immutable, random read, batch write Cassandra