Understanding Query Plans and Spark UIs
20 likes5,569 views

The document presented by Xiao Li at the Spark + AI Summit covers key aspects of understanding query plans and Spark UI, focusing on performance optimization and execution tracking. It discusses the differences between various query execution plans, tips for improving Spark queries, and the advantages of using Delta Lake with Apache Spark for better metadata handling and performance. The presentation concludes with resources for further learning and data on Delta Lake's processing statistics.









![Read Plans from
SQL Tab in either
Spark UI or Spark
History Server
11
Spark 3.0: Show the actual SQL statement? [SPARK-27045]](https://image.slidesharecdn.com/042006xiaoli-190510183745/85/Understanding-Query-Plans-and-Spark-UIs-11-320.jpg)





































Understanding Query Plans and Spark UIs
- 1. Understanding Query Plans and Spark UIs Xiao Li @ gatorsmile Spark + AI Summit @ SF | April 2019 1
- 2. About Me • Engineering Manager at Databricks • Apache Spark Committer and PMC Member • Previously, IBM Master Inventor • Spark, Database Replication, Information Integration • Ph.D. in University of Florida • Github: gatorsmile
- 3. Databricks Customers Across Industries Financial Services Healthcare & Pharma Media & Entertainment Technology Public Sector Retail & CPG Consumer Services Energy & Industrial IoTMarketing & AdTech Data & Analytics Services
- 4. DATABRICKS WORKSPACE Databricks Delta ML Frameworks DATABRICKS CLOUD SERVICE DATABRICKS RUNTIME Reliable & Scalable Simple & Integrated Databricks Unified Analytics Platform APIs Jobs Models Notebooks Dashboards End to end ML lifecycle
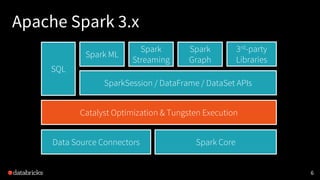
- 5. Apache Spark 3.x 5 Catalyst Optimization & Tungsten Execution SparkSession / DataFrame / DataSet APIs SQL Spark ML Spark Streaming Spark Graph 3rd-party Libraries Spark CoreData Source Connectors
- 6. Apache Spark 3.x 6 Catalyst Optimization & Tungsten Execution SparkSession / DataFrame / DataSet APIs SQL Spark ML Spark Streaming Spark Graph 3rd-party Libraries Spark CoreData Source Connectors
- 7. From declarative queries to RDDs 7 Cypher
- 9. 9 Read Plan. Interpret Plan. Tune Plan. Track Execution.
- 10. 10 Read Plans from SQL Tab in either Spark UI or Spark History Server
- 11. Read Plans from SQL Tab in either Spark UI or Spark History Server 11 Spark 3.0: Show the actual SQL statement? [SPARK-27045]
- 12. Page: In Details for SQL Query 12
- 14. 14 Understand and Tune Plans
- 16. 16 Read the analyzed plan to check the implicit type casting. Tip: Explicitly cast the types in the queries.
- 17. 17 Read the analyzed plan to check the implicit type casting. Tip: Explicitly cast the types in the queries.
- 18. Create Hive Tables 18 Syntax to create a Hive Serde table
- 19. Hive serde reader Read Tables
- 20. 20 filter pushdown Native reader/writer performs faster than Hive serde reader/writer
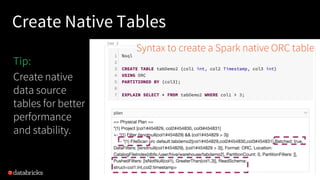
- 21. 21 Create Native Tables Syntax to create a Spark native ORC table Tip: Create native data source tables for better performance and stability.
- 22. 22 Push Down + Implicit Type Casting Not pushed down??? Tip: Cast is needed? Update the constants?
- 23. Nested Schema Pruning 23Not pruned???
- 25. Collapse Projects 25 Call UDF three times!!!
- 27. Cross-session SQL Cache 27 • If a query is cached in the one session, the new queries in all the sessions might be impacted. • Check your query plan!
- 28. 28
- 29. 29 Join Hints in Spark 3.0 • BROADCAST • Broadcast Hash/Nested-loop Join • MERGE • Shuffle Sort Merge Join • SHUFFLE_HASH • Shuffle Hash Join • SHUFFLE_REPLICATE_NL • Shuffle-and-Replicate Nested Loop Join
- 32. 32 • A SQL query => multiple Spark jobs. • - For example, broadcast exchange, shuffle exchange, Scalar subquery. • - External data sources: Delta Lake. • - New adaptive query execution. • A Spark job => A DAG • A chain of RDD dependencies organized in a directed acyclic graph (DAG)
- 33. 33 The higher level SQL physical operators. Optimized ogical Plan DAGsPhysical Plans Selected Physical Plan CostModel he ger r Planner Query ExecutionQuery Execution The low level Spark RDD primitives.
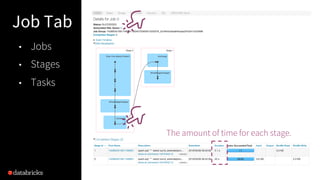
- 34. Job Tab in Spark UI 34 The amount of time for each job. Any stage/task failure?
- 35. Job Tab 35 The amount of time for each stage. • Jobs • Stages • Tasks
- 36. Stages Tab 36 • How the time are spent? • Any outlier in task execution? • Straggler tasks? • Skew in data size, compute time? • Too many/few tasks (partitions)? • Load balanced? Locality? Tasks specific info
- 38. Executors Tab 38 size of data transferred between stages used/available memory All the problematic executors in the same node?
- 39. 39 - Interacting with Hive metastore? - Slow query planning? - Slow file listing?
- 40. 40 Insert Partitioned Hive Table OR “STORED AS PARQUET” 5000 partitions took almost 8 minutes!!!
- 41. 41
- 42. 42 Insert Partitioned Native Table Reduced from almost 8 minutes to less than 1 minute !!!
- 43. 43 Insert Partitioned Delta Table Reduced from almost 8 minutes to 27 seconds!!!
- 44. Typical Spark Performance Issues 44 The table has thousands of partitions • Hive metastore overhead This table can have 100s of thousands to millions of files • File system overhead - listing takes forever! New data is not immediately visible • Need to invoke a command “Refresh Table” with the SQL engine they were using The above issues can add 10s of minutes to the response time!
- 45. Delta Lake + Spark 45 Scalable metadata handling @ Delta Lake Store metadata in transaction log file instead of metastore The table has thousands of partitions • Zero Hive Metastore overhead The table can have 100s of thousands to millions of files • No file listing New data is not immediately visible • Delta table state is computed on read
- 46. How do I use Delta? format(“parquet”) -> format(“delta”)
- 47. Delta Lake + Spark 47 • Full ACID transactions • Schema management • Data versioning and time travel • Unified batch/streaming support • Scalable metadata handling • Record update and deletion • Data expectation Delta Lake: https://delta.io/ For details, refer to the blog https://tinyurl.com/yxhbe2lg
- 48. Delta Usage Statistics More than 1 exabyte processed (1018 bytes) monthly ManufacturingPublic Sector Technology Other Healthcare and Life Sciences Financial Services Media and Entertainment Retail, CPG, and eCommerce
- 49. Additional Resources 49 • Apache Spark document: https://spark.apache.org/docs/latest/sql- programming-guide.html • Blog: https://databricks.com/blog/category/engineering/spark • Previous summit: https://databricks.com/sparkaisummit/north- america/sessions • Delta Lake document: https://docs.delta.io • Databricks document: https://docs.databricks.com/ • Books: https://www.amazon.com/s?k=apache+spark • Databricks academy: https://academy.databricks.com • Databricks ebooks: https://databricks.com/resources/type/ebooks