Unified batch and stream processing with Flink @ Big Data Beers Berlin May 2015
Download as PPTX, PDF4 likes801 views

Robert Metzger presented on the 1 year growth of the Apache Flink community and an overview of Flink's capabilities. Flink can natively support streaming, batch, machine learning, and graph processing workloads by executing everything as data streams, allowing some iterative and stateful operations, and operating on managed memory. Key aspects of Flink streaming include its pipelined processing, expressive APIs, efficient fault tolerance, and flexible windows and state. Batch pipelines in Flink are also executed as streaming programs with some blocking operations. Flink additionally supports SQL-like queries, machine learning algorithms through iterative data flows, and graph analysis through stateful delta iterations.




![Program compilation
5
case class Path (from: Long, to:
Long)
val tc = edges.iterate(10) {
paths: DataSet[Path] =>
val next = paths
.join(edges)
.where("to")
.equalTo("from") {
(path, edge) =>
Path(path.from, edge.to)
}
.union(paths)
.distinct()
next
}
Optimizer
Type extraction
stack
Task
scheduling
Dataflow
metadata
Pre-flight (Client)
Master
Workers
DataSourc
e
orders.tbl
Filter
Map
DataSourc
e
lineitem.tbl
Join
Hybrid Hash
build
HT
probe
hash-part [0] hash-part [0]
GroupRed
sort
forward
Program
Dataflow
Graph
deploy
operators
track
intermediate
results](https://image.slidesharecdn.com/flinkdatabeersonslideshare-150521081207-lva1-app6892/85/Unified-batch-and-stream-processing-with-Flink-Big-Data-Beers-Berlin-May-2015-5-320.jpg)











![Expressive APIs
17
case class Word (word: String, frequency: Int)
val lines: DataStream[String] = env.fromSocketStream(...)
lines.flatMap {line => line.split(" ")
.map(word => Word(word,1))}
.window(Time.of(5,SECONDS)).every(Time.of(1,SECONDS))
.groupBy("word").sum("frequency")
.print()
val lines: DataSet[String] = env.readTextFile(...)
lines.flatMap {line => line.split(" ")
.map(word => Word(word,1))}
.groupBy("word").sum("frequency")
.print()
DataSet API (batch):
DataStream API (streaming):](https://image.slidesharecdn.com/flinkdatabeersonslideshare-150521081207-lva1-app6892/85/Unified-batch-and-stream-processing-with-Flink-Big-Data-Beers-Berlin-May-2015-17-320.jpg)

























Unified batch and stream processing with Flink @ Big Data Beers Berlin May 2015
- 2. 1 year of Flink - code April 2014 April 2015
- 3. Community growth 3 0 20 40 60 80 100 120 Aug-10 Feb-11 Sep-11 Apr-12 Oct-12 May-13 Nov-13 Jun-14 Dec-14 Jul-15 #unique contributors by git commits
- 4. What is Flink? 4 Gelly Table ML SAMOA DataSet (Java/Scala/Python) DataStream (Java/Scala) HadoopM/R Local Remote Yarn Tez Embedded Dataflow Dataflow(WiP) MRQL Table Cascading(WiP) Streaming dataflow runtime
- 5. Program compilation 5 case class Path (from: Long, to: Long) val tc = edges.iterate(10) { paths: DataSet[Path] => val next = paths .join(edges) .where("to") .equalTo("from") { (path, edge) => Path(path.from, edge.to) } .union(paths) .distinct() next } Optimizer Type extraction stack Task scheduling Dataflow metadata Pre-flight (Client) Master Workers DataSourc e orders.tbl Filter Map DataSourc e lineitem.tbl Join Hybrid Hash build HT probe hash-part [0] hash-part [0] GroupRed sort forward Program Dataflow Graph deploy operators track intermediate results
- 6. Native workload support 6 Flink Streaming topologies Long batch pipelines Machine Learning at scale How can an engine natively support all these workloads? And what does "native" mean? Graph Analysis
- 7. E.g.: Non-native iterations 7 Step Step Step Step Step Client for (int i = 0; i < maxIterations; i++) { // Execute MapReduce job }
- 8. E.g.: Non-native streaming 8 stream discretizer Job Job Job Job while (true) { // get next few records // issue batch job }
- 9. Native workload support 9 Flink Streaming topologies Heavy batch jobs Machine Learning at scale How can an engine natively support all these workloads? And what does native mean?
- 10. Flink Engine 1. Execute everything as streams 2. Allow some iterative (cyclic) dataflows 3. Allow some mutable state 4. Operate on managed memory 10
- 11. Flink by Use Case 11
- 12. Data Streaming Analysis streaming dataflows 12
- 13. 3 Parts of a Streaming Infrastructure 13 Gathering Broker Analysis Sensors Transaction logs … Server Logs
- 14. 3 Parts of a Streaming Infrastructure 14 Gathering Broker Analysis Sensors Transaction logs … Server Logs Result may be fed back to the broker
- 15. Cornerstones of Flink Streaming Pipelined stream processor (low latency) Expressive APIs Flexible operator state, streaming windows Efficient fault tolerance for streams and state. 15
- 17. Expressive APIs 17 case class Word (word: String, frequency: Int) val lines: DataStream[String] = env.fromSocketStream(...) lines.flatMap {line => line.split(" ") .map(word => Word(word,1))} .window(Time.of(5,SECONDS)).every(Time.of(1,SECONDS)) .groupBy("word").sum("frequency") .print() val lines: DataSet[String] = env.readTextFile(...) lines.flatMap {line => line.split(" ") .map(word => Word(word,1))} .groupBy("word").sum("frequency") .print() DataSet API (batch): DataStream API (streaming):
- 18. Checkpointing / Recovery 18 Chandy-Lamport Algorithm for consistent asynchronous distributed snapshots Pushes checkpoint barriers through the data flow Operator checkpoint starting Checkpoint done Data Stream barrier Before barrier = part of the snapshot After barrier = Not in snapshot Checkpoint done checkpoint in progress (backup till next snapshot)
- 19. Long batch pipelines Batch on Streaming 19
- 21. Batch on Streaming Batch programs are a special kind of streaming program 21 Infinite Streams Finite Streams Stream Windows Global View Pipelined Data Exchange Pipelined or Blocking Exchange Streaming Programs Batch Programs
- 22. Batch Pipelines 22 Data exchange (shuffle / broadcast) is mostly streamed Some operators block (e.g. sorts / hash tables)
- 26. Smooth out-of-core performance 26 More at: http://flink.apache.org/news/2015/03/13/peeking-into-Apache-Flinks-Engine-Room.html Blue bars are in-memory, orange bars (partially) out-of-core
- 27. Table API 27 val customers = envreadCsvFile(…).as('id, 'mktSegment) .filter("mktSegment = AUTOMOBILE") val orders = env.readCsvFile(…) .filter( o => dateFormat.parse(o.orderDate).before(date) ) .as("orderId, custId, orderDate, shipPrio") val items = orders .join(customers).where("custId = id") .join(lineitems).where("orderId = id") .select("orderId, orderDate, shipPrio, extdPrice * (Literal(1.0f) – discount) as revenue") val result = items .groupBy("orderId, orderDate, shipPrio") .select('orderId, revenue.sum, orderDate, shipPrio")
- 28. Machine Learning Algorithms Iterative data flows 28
- 29. Iterate by looping for/while loop in client submits one job per iteration step Data reuse by caching in memory and/or disk Step Step Step Step Step Client 29
- 30. Iterate in the Dataflow 30
- 31. Example: Matrix Factorization 31 Factorizing a matrix with 28 billion ratings for recommendations More at: http://data-artisans.com/computing-recommendations-with-flink.html
- 33. Iterate natively with state/deltas 33
- 34. Effect of delta iterations… 0 5000000 10000000 15000000 20000000 25000000 30000000 35000000 40000000 45000000 1 6 11 16 21 26 31 36 41 46 51 56 61 #ofelementsupdated iteration
- 35. … fast graph analysis 35More at: http://data-artisans.com/data-analysis-with-flink.html
- 36. Closing 36
- 37. Flink Roadmap for 2015 Some examples: More flexible state and state backends in streaming Master Failover Improved monitoring Integration with other Apache projects • SAMOA, Zeppelin, Ignite More additions to the libraries 37
- 38. Flink Forward registration & call for abstracts is open now flink.apache.org 38 • 12. and 13. October 2015 • Kulturbrauerei Berlin • With Flink Workshops/Training!
- 39. 39
- 41. 41
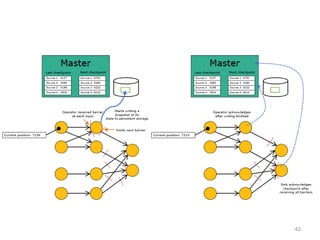
- 42. 42
- 43. Examples of optimization Task chaining • Coalesce map/filter/etc tasks Join optimizations • Broadcast/partition, build/probe side, hash or sort- merge Interesting properties • Re-use partitioning and sorting for later operations Automatic caching • E.g., for iterations 43
Editor's Notes
- #2: Working on Flink since 2012. Implemented YARN support
- #3: Taking a look back: in only one year, a lot has happened. We were accepted in the ASF incubator, graduated quite fast … …. code wise, we are quickly adding new features and functionality (while not forgetting to keep existing users happy with fixes ;) ) I checked a few days ago and found that we’ve doubled the lines of code in one year
- #4: we could have never done this alone without a very strong and amazing community.
- #5: at the very heart, Flink is a streaming dataflow runtime. This means operators are running at the same time, sending data to each other. This allows exploiting parallelism, utilize the hardware etc. To get something out of that runtime, we over programming abstractions. There are DataSet and DataStream for batch and stream processing. On top of these APIs, user have build more: ….
- #6: So how do we turn a simple java / scala program into a robust distributed program? type analysis / extraction (=think of it as “schema creation”) … creation of serializers optimization (data partitioning (global strategy), execution strategy (local strategy)) represented as a dataflow graph (with all the strategies set) -------- local / remote border ---- d) scheduling & job metadata @master e) workers process data
- #7: What makes Flink special? natively supports a very broad range of use cases Common use cases are: - real time stream processing .. you want to process your data as it comes in large batch pipelines, reading data from many sources, joining, cleaning and analyzing. not only data intensive use cases, also work intensive use cases (machine learning, graph analysis) … how to intelligently distribute work through the cluster?
- #8: iterations through loop unrolling: needed for many use cases, for example graph and machine learning explain approach slow because rescheduling & state recreation necessary
- #9: streaming through mini-batches discretize your stream into “small” sets and process them with your batch system. high latency because you need to collect & start the batches
- #10: How do we achieve this?
- #11: everything is treated as data streams. multiple processing steps are happening at the same time. No materialization (=storing the result on disk) between processing steps We allow streams to have loops (feed in the result of earlier computation) flink is aware of iterative processing, no need to redeploy, can automatically optimize Users can keep state between iterations (for example a model you are training). in streaming, we backup your state for you Flink always knows whats going on with its memory (instead of dealing with the “blackbox” GC)
- #25: For batch processing (which is often very data intensive) we need … … explain … .. so this is nice, but now all the user data is just a bunch of bytes in an array?
- #27: the fruits of our hard work
- #28: The last highlight of the batch system: the best of both worlds: sql-style for the simple data lifting, custom functions for the complex / heavy stuff
- #40: Shameless plug