Unifying your data management with Hadoop
Download as PPTX, PDF3 likes1,475 views

This document discusses using Hadoop to unify data management. It describes challenges with managing huge volumes of fast-moving machine data and outlines an overall architecture using Hadoop components like HDFS, HBase, Solr, Impala and OpenTSDB to store, search, analyze and build features from different types of data. Key aspects of the architecture include intelligent search, batch and real-time analytics, parsing, time series data and alerts.




![6
Some Log data…
Redhat Linux Server
Mar 7 04:02:08 avas syslogd 1.4.1: restart.
Mar 7 04:02:16 avas clamd[11165]: /var/amavis/amavis-20040307T033734-10329/parts/part-00003: Worm.Mydoom.F FOUND
Mar 7 04:05:55 avas clamd[11240]: /var/amavis/amavis-20040307T035901-10615/parts/part-00002: Worm.SomeFool.Gen-1 FOUND
Mar 7 04:11:15 avas dccifd[11335]: write(MTA socket,4): Broken pipe
Apache
64.242.88.10 - - [07/Mar/2004:16:05:49 -0800] "GET /twiki/bin/edit/Main/Double_bounce_sender?topicparent=Main.ConfigurationVariables HTTP/1.1" 401 12846
64.242.88.10 - - [07/Mar/2004:16:06:51 -0800] "GET /twiki/bin/rdiff/TWiki/NewUserTemplate?rev1=1.3&rev2=1.2 HTTP/1.1" 200 4523
64.242.88.10 - - [07/Mar/2004:16:10:02 -0800] "GET /mailman/listinfo/hsdivision HTTP/1.1" 200 6291
Log4j
0 [main] DEBUG com.vaannila.report.SampleReport - Sample debug message
0 [main] INFO com.vaannila.report.SampleReport - Sample info message
0 [main] WARN com.vaannila.report.SampleReport - Sample warn message
ERROR [2009-09-13 09:56:01,760] [main] (RDFDefaultErrorHandler.java:44) http://www.xfront.com/owl/ontologies/camera/#(line 1 column 1): Content is not allowed in prolog.
[DEBUG] 55:17 (LogExample.java:main:11) Here is some DEBUG
[ INFO] 55:17 (LogExample.java:main:12) Here is some INFO
Cisco PIX Logs
Mar 29 2004 09:54:18: %PIX-6-302005: Built UDP connection for faddr 198.207.223.240/53337 gaddr 10.0.0.187/53 laddr 192.168.0.2/53
Mar 29 2004 09:54:19: %PIX-6-302005: Built UDP connection for faddr 198.207.223.240/3842 gaddr 10.0.0.187/53 laddr 192.168.0.2/53
Mar 29 2004 09:54:19: %PIX-6-302005: Built UDP connection for faddr 198.207.223.240/36205 gaddr 10.0.0.187/53 laddr 192.168.0.2/53](https://image.slidesharecdn.com/unifyingyourdatamanagementwithhadoop-140602164508-phpapp02/85/Unifying-your-data-management-with-Hadoop-6-320.jpg)















![22
Drill Downs, More Queries & Subsearch
Click on ‘Tablets’ from the Top Purchases
This kicks off a new search. Search is updated to include the filter for the field/value pair category=flowers
How many different customers purchased tablets?
dataset=logs1 action=purchase category_id=tablets| stats uniqueuecount(clientip)
How many tablets did each customer buy?
dataset=logs1 action=purchase category_id=tablets| stats count BY clientip
The customer who bought the most items yesterday and what he or she bought?
dataset=logs1 action=purchase [search dataset=logs1 action=purchase | top limit=1 clientip |
table clientip] | stats count, values(product_id) by clientip](https://image.slidesharecdn.com/unifyingyourdatamanagementwithhadoop-140602164508-phpapp02/85/Unifying-your-data-management-with-Hadoop-22-320.jpg)











![Parsing
34
morphlines : [
morphline1
commands : [
readMultiLine
Break up the message text into SOLR fields
Geneate Unique ID
Convert the timestamp field to "yyyy-MM-dd'T'HH:mm:ss.SSSZ"
Sanitize record fields that are unknown to Solr schema.xml
load the record into a SolrServer
]
]
http://cloudera.github.io/cdk/docs/current/cdk-morphlines/morphlinesReferenceGuide.html
https://github.com/cloudera/cdk/tree/master/cdk-morphlines/cdk-morphlines-core/src/test/resources/test-
morphlines](https://image.slidesharecdn.com/unifyingyourdatamanagementwithhadoop-140602164508-phpapp02/85/Unifying-your-data-management-with-Hadoop-34-320.jpg)
![35
SOLR_COLLECTION : "collection1"
SOLR_COLLECTION : ${?ENV_SOLR_COLLECTION}
ZK_HOST : "127.0.0.1:2181/solr"
ZK_HOST : ${?ENV_ZK_HOST}
SOLR_HOME_DIR : "example/solr/collection1"
SOLR_HOME_DIR : ${?ENV_SOLR_HOME_DIR}
SOLR_LOCATOR : {
collection : ${SOLR_COLLECTION}
zkHost : ${ZK_HOST}
solrHomeDir : ${SOLR_HOME_DIR}
# batchSize : 1000
}
SOLR_LOCATOR : ${?ENV_SOLR_LOCATOR}
morphlines : [
{
id : morphline1
importCommands : ["com.cloudera.**", "org.apache.solr.**"]
commands : [
{
sanitizeUnknownSolrFields {
solrLocator : ${SOLR_LOCATOR}
}
}
{
loadSolr {
solrLocator : ${SOLR_LOCATOR}
boosts : {
id : 1.0
}
}
}
{ logDebug { format : "output record: {}", args : ["@{}"] } }
]
}
]](https://image.slidesharecdn.com/unifyingyourdatamanagementwithhadoop-140602164508-phpapp02/85/Unifying-your-data-management-with-Hadoop-35-320.jpg)
![Using Java Code
36
morphlines : [
{
id : morphline1
importCommands : ["com.cloudera.**", "org.apache.solr.**"]
commands : [
{ java
{
code: """
List tags = record.get("tags");
if (!tags.contains("hello")) {
return false;
}
tags.add("world");
return child.process(record);
"""
}
}
]
}
]](https://image.slidesharecdn.com/unifyingyourdatamanagementwithhadoop-140602164508-phpapp02/85/Unifying-your-data-management-with-Hadoop-36-320.jpg)






















Unifying your data management with Hadoop
- 1. CONFIDENTIAL - RESTRICTED Unifying Your Data Management with Hadoop Strata + Hadoop World 2013 Jayant Shekhar Sr. Solutions Architect
- 2. 2 Machine Data • Logs • Diagnostic Bundles • Utility Data • Machine Monitoring Data • User Activity Machine/Streaming Data • Machine data is a critical piece with highest volume and is fast moving • Systems are hardest to build and scale for it • The rest of the data fall naturally into the design. • In a hospital various reading are taken – heart beat, blood pressure, breathing rate • Water companies measure the acidity of the water in their reservoirs • Racing cars : companies want to know every aspect of how their car is performing • Utility meters • Web server • linux/firewall/router : syslogs
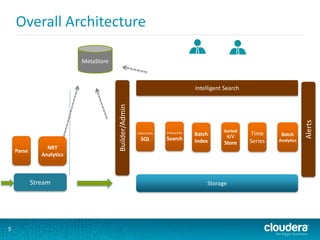
- 3. What you want to do with Machine Data? 3 Store Search NRT Analytics Mix with other data Stream Build Cool Features Time Series Alerts Reports/ ML Parse
- 4. So what’s the CHALLENGE? 4 Huge Fast Moving 1TBx1000=1PB The whole story changes with Scale.
- 6. 6 Some Log data… Redhat Linux Server Mar 7 04:02:08 avas syslogd 1.4.1: restart. Mar 7 04:02:16 avas clamd[11165]: /var/amavis/amavis-20040307T033734-10329/parts/part-00003: Worm.Mydoom.F FOUND Mar 7 04:05:55 avas clamd[11240]: /var/amavis/amavis-20040307T035901-10615/parts/part-00002: Worm.SomeFool.Gen-1 FOUND Mar 7 04:11:15 avas dccifd[11335]: write(MTA socket,4): Broken pipe Apache 64.242.88.10 - - [07/Mar/2004:16:05:49 -0800] "GET /twiki/bin/edit/Main/Double_bounce_sender?topicparent=Main.ConfigurationVariables HTTP/1.1" 401 12846 64.242.88.10 - - [07/Mar/2004:16:06:51 -0800] "GET /twiki/bin/rdiff/TWiki/NewUserTemplate?rev1=1.3&rev2=1.2 HTTP/1.1" 200 4523 64.242.88.10 - - [07/Mar/2004:16:10:02 -0800] "GET /mailman/listinfo/hsdivision HTTP/1.1" 200 6291 Log4j 0 [main] DEBUG com.vaannila.report.SampleReport - Sample debug message 0 [main] INFO com.vaannila.report.SampleReport - Sample info message 0 [main] WARN com.vaannila.report.SampleReport - Sample warn message ERROR [2009-09-13 09:56:01,760] [main] (RDFDefaultErrorHandler.java:44) http://www.xfront.com/owl/ontologies/camera/#(line 1 column 1): Content is not allowed in prolog. [DEBUG] 55:17 (LogExample.java:main:11) Here is some DEBUG [ INFO] 55:17 (LogExample.java:main:12) Here is some INFO Cisco PIX Logs Mar 29 2004 09:54:18: %PIX-6-302005: Built UDP connection for faddr 198.207.223.240/53337 gaddr 10.0.0.187/53 laddr 192.168.0.2/53 Mar 29 2004 09:54:19: %PIX-6-302005: Built UDP connection for faddr 198.207.223.240/3842 gaddr 10.0.0.187/53 laddr 192.168.0.2/53 Mar 29 2004 09:54:19: %PIX-6-302005: Built UDP connection for faddr 198.207.223.240/36205 gaddr 10.0.0.187/53 laddr 192.168.0.2/53
- 7. 7 Search
- 8. 8 Storing/Indexing data into the right Stores Impala/HDFS/HIVE All data goes in here and accessible with SQL queries Supports very high write throughputs and very fast scans All Data SolrCloud Data needed for real-time complex search Last X Days HBase Data needed for real-time serving and searching/scanning based on key Supports very high write/read throughputs. Supports filtering. Row Key is indexed and sorted. Limit scanning of huge sets. Result Sets, Configuration OpenTSDB Time Series Data for Monitoring/Alerting Metrics
- 9. 9 Searching Solr Searches are done via HTTP GET on the select URL with the query string in the q parameter. • q=video&fl=name,id (return only name and id fields) • q=video&fl=name,id,score (return relevancy score as well) • q=video&fl=*,score (return all stored fields, as well as relevancy score) • q=video&sort=price desc&fl=name,id,price (add sort specification: sort by price descending) • q=video&wt=json (return response in JSON format) Use the "sort' parameter to specify "field direction" pairs, separated by commas if there's more than one sort field: • q=video&sort=price desc • q=video&sort=price asc • q=video&sort=inStock asc, price desc • "score" can also be used as a field name when specifying a sort
- 10. 10 Searching Solr – Faceted Search Faceted search allows users who’re running searches to see a high-level breakdown of their search results based upon one or more aspects (facets) of their documents, allowing them to select filters to drill into those search results. http://localhost:8983/solr/select?q=*:*&facet=true&facet.field=tags
- 11. Impala 11 • Raises the bar for query performance. Does extensive query optimization. • Uses the same metadata, SQL syntax (Hive SQL), ODBC driver and user interface (Hue Beeswax) as Apache Hive • Impala circumvents MapReduce to directly access the data through a specialized distributed query engine • Queries that require multiple MapReduce phases in Hive or require reduce-side joins will see a higher speedup than, say, simple single-table aggregation queries
- 12. 12 Searching with Impala • Perfect for large data scans • Partitioning will reduce the amount of data scanned • Impala caches the Metadata • Define SQL statements for searching from Impala/HIVE. Use Regex for defining new fields during search time. Partitions • Partition by day: 365 • Partition by hour: 8760 • Partition by minute: 525600
- 13. Impala 13 HDFS DN Query Exec Engine Query Coordinator Query Planner HBase HDFS DN Query Exec Engine Query Coordinator Query Planner HBaseHDFS DN Query Exec Engine Query Coordinator Query Planner HBase Fully MPP Distributed Local Direct Reads ODBC SQL App Common Hive SQL and interface Unified metadata and scheduler HDFS NN Hive Metastore YARN State Store
- 14. 14 Store/Search ImpalaSolrCloud Table Hour Table Day P P P P P P P P Read Alias C C C C C CC Update Alias http://localhost:8983/solr/admin/collections?action=CREATEALIAS &name=readalias&collection=C2,C3 More Optimizations = Faster Performance
- 16. 16 Unified Data Access Impala App Server App Server App Server SolrCloud HS2 OpenTSDBHBase Intelligent Search Server Knows • What data is residing where • How to query the various stores • Stores Intermediate Results • Learns from queries Metastore Intermediate Results Pipes/SQL REST/JSON/JDBC/Thrift
- 17. Builder/Admin 17 Performs all the Background Management & Admin tasks • Create new DataSets • Manage Schemas • Manage Collections : Store last X days of data in Solr. Use Aliases to map to collections/day. • Regenerate Solr Index when needed or requested by the Admin • Manage the Impala Partitions. Last X days vs last Y months vs last Z years
- 18. Intelligent Search Server 18 • Parse Query Requests • Get DataSet definition from the metadata store • Generate the Query Plan • Should I fetch from SolrCloud/Impala? • Is there intermediate result stored that I can use? • If not a power-user, would this query be very long running? • Execute the Query • Store results in HBase if applicable • Support expressions, aggregate functions, expressions, normal functions
- 19. Metastore 19 App. Metastore • User Definitions • Normal/Power user/Admin • DataSets Definitions • Solr Collections • Impala Tables • HBase Tables • Field Definitions • Dashboard/Alerts Definitions HIVE Metastore Impala/HIVE Tables & Partitions Admin/ Builder Flume Intercep Search Server Dashbo ard/Ale rts
- 20. 20 Searching/Querying • SLA requirements • Be able to search last X days of logs within seconds • Be able to search last Y weeks of logs within minutes • Be able to search last Z months of logs within 15 minutes • Searching consists of: • Specifying a dataset and time period • Searching for a regular expression in the dataset • Displaying the matching records • Displaying the count of keywords in various facets (hostname, city, IP) • Further filtering by various facet selections • Allow users to define new fields
- 21. 21 Sample Queries How many times did someone view a page on the website? dataset=logs1 method=GET | stats count AS Views How many resulted in purchases? dataset=logs1 method=GET | stats count AS Views, count(eval(action="purchase")) as Purchases What was purchased and how much was made? dataset=logs1 * action=purchase | stats count AS "# Purchased", values(price) AS Price, sum(price) AS Total by product_name Which items were purchased most? dataset=logs1 action=purchase | top category_id ::You can also save your searches under some label::
- 22. 22 Drill Downs, More Queries & Subsearch Click on ‘Tablets’ from the Top Purchases This kicks off a new search. Search is updated to include the filter for the field/value pair category=flowers How many different customers purchased tablets? dataset=logs1 action=purchase category_id=tablets| stats uniqueuecount(clientip) How many tablets did each customer buy? dataset=logs1 action=purchase category_id=tablets| stats count BY clientip The customer who bought the most items yesterday and what he or she bought? dataset=logs1 action=purchase [search dataset=logs1 action=purchase | top limit=1 clientip | table clientip] | stats count, values(product_id) by clientip
- 23. Querying with SQL & Pipes 23 Query SQL Top 25: business with most of the reviews SELECT name, review_count FROM business ORDER BY review_count DESC LIMIT 25 | chart ... Top 25: coolest restaurants SELECT r.business_id, name, SUM(cool) AS coolness FROM review r JOIN business b ON (r.business_id = b.business_id) WHERE categories LIKE '%Restaurants%' GROUP BY r.business_id, name ORDER BY coolness DESC LIMIT 25
- 24. 24 Index Fields • Index Time • Solr : Will slow down with more indexes • Impala : Relies on Partitioning, Bucketing and Filtering • Define additional indexed fields through the Builder • Search Time field Extraction • Does not affect the index size • Size of data processed gets larger • Storing of results helps
- 25. 25 Adding New Fields & Updating the Index Adding new field • Update the Morphines to parse the new field • Update the Solr Schema. • Update the Impala/HIVE table definitions Indexing Options • Re-index all data on HDFS • Also used when say an index is lost • Can also be run on the data in HBase • Support new fields for new data only
- 26. 26 Speeding Search… • Save the Search Results (HBase) • Search Results can be shared • Searches are speeded by saving previous result and then running an incremental search.
- 27. 27 Dashboards & Charts • Create New Dashboards and populate them • Add a search you have just run to a new or existing dashboard Chart of purchases and views for each product dataset=ecommerce method=GET | chart count AS views, count(eval(action="purchase")) AS purchases by category_id” • Top Items Sold • Total Number of Exceptions • Total Number of Visits • Map of Visitor Locations • Pages/Visit
- 28. 28 Define the Schema for Incoming Data • Log data comes in different formats : apache logs, syslog, log4j etc. • Define the fields to be extracted from each : Timestamp, IP, Host, Message… • Define Solr Schema • Can create separate collections for different datasets and time ranges • Define Tables for Impala & HIVE • Partition things by date. If needed partition some stuff by hour. • Impala performs great on partitioned data for NRT queries • Define Schema for HBase Tables (Need to optimize for writes and for reads) • Composite Key : DataSet, Application, Component, Some Prefix, Timestamp • Application, User ID, Timestamp
- 29. Unified Data Access with Hue 29
- 30. 30 Streaming, Parsing, Indexing, NRT Analytics, Alerts
- 31. 31 HDFS Raw Logs Flume Flume HDFS Raw Logs Flume Flume Interceptors Serializers Flume Storage TierFlume Collector Tier DC1 Flume Flume DC2 Flume Flume DC3 DC4
- 32. 32 Streaming in data into HDFS/HBase/SolrCloud HDFS HBase Solr Cloud Solr Shard Solr Shard Solr Shard HIVE/Impala Storm Flume Source Channels SolrSink
- 33. 33 Parsing with Morphlines From various processes • Flume • MapReduceIndexerTool • My Application • SolrCloud • HBase • HDFS • … ETL into various Stores Can be embedded into any Application… Morphline
- 34. Parsing 34 morphlines : [ morphline1 commands : [ readMultiLine Break up the message text into SOLR fields Geneate Unique ID Convert the timestamp field to "yyyy-MM-dd'T'HH:mm:ss.SSSZ" Sanitize record fields that are unknown to Solr schema.xml load the record into a SolrServer ] ] http://cloudera.github.io/cdk/docs/current/cdk-morphlines/morphlinesReferenceGuide.html https://github.com/cloudera/cdk/tree/master/cdk-morphlines/cdk-morphlines-core/src/test/resources/test- morphlines
- 35. 35 SOLR_COLLECTION : "collection1" SOLR_COLLECTION : ${?ENV_SOLR_COLLECTION} ZK_HOST : "127.0.0.1:2181/solr" ZK_HOST : ${?ENV_ZK_HOST} SOLR_HOME_DIR : "example/solr/collection1" SOLR_HOME_DIR : ${?ENV_SOLR_HOME_DIR} SOLR_LOCATOR : { collection : ${SOLR_COLLECTION} zkHost : ${ZK_HOST} solrHomeDir : ${SOLR_HOME_DIR} # batchSize : 1000 } SOLR_LOCATOR : ${?ENV_SOLR_LOCATOR} morphlines : [ { id : morphline1 importCommands : ["com.cloudera.**", "org.apache.solr.**"] commands : [ { sanitizeUnknownSolrFields { solrLocator : ${SOLR_LOCATOR} } } { loadSolr { solrLocator : ${SOLR_LOCATOR} boosts : { id : 1.0 } } } { logDebug { format : "output record: {}", args : ["@{}"] } } ] } ]
- 36. Using Java Code 36 morphlines : [ { id : morphline1 importCommands : ["com.cloudera.**", "org.apache.solr.**"] commands : [ { java { code: """ List tags = record.get("tags"); if (!tags.contains("hello")) { return false; } tags.add("world"); return child.process(record); """ } } ] } ]
- 37. 37 Real Time Indexing into Solr agent.sinks.solrSink.type=org.apache.flume.sink.solr.morphline.Morphline SolrSink agent.sinks.solrSink.channel=solrChannel agent.sinks.solrSink.morphlineFile=/tmp/morphline.conf Morphline file, which encodes the transformation logic, is exactly identical in both Real Time and Batch Indexing examples
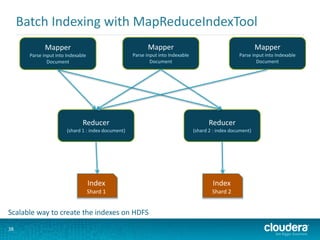
- 38. Batch Indexing with MapReduceIndexTool 38 Mapper Parse input into Indexable Document Mapper Parse input into Indexable Document Mapper Parse input into Indexable Document Reducer (shard 1 : index document) Reducer (shard 2 : index document) Index Shard 1 Index Shard 2 Scalable way to create the indexes on HDFS
- 39. 39 Batch Indexing with MapReduceIndexTool MR Indexer • Read the HDFS directory • Pass them through the Morphline • Merge the indexes into live SOLR servers # hadoop jar /usr/lib/solr/contrib/mr/search-mr-*-job.jar org.apache.solr.hadoop.MapReduceIndexerTool --morphline-file <morphline file> --output-dir <hdfs URI for indexes> --go-live --zk-host clust2:2181/solr –collection logs_collection <HDFS URI with the files to index> MapReduceIndexerTool is a MapReduce batch job driver that creates a set of Solr index shards from a set of input files and writes the indexes into HDFS
- 40. Tagging Data at Source 40 agent.sources.messages-source.interceptors = hostname timestamp zinfo agent.sources.messages-source.interceptors.hostname.type = host agent.sources.messages-source.interceptors.timestamp.type = timestamp agent.sources.messages-source.interceptors.zinfo.type = com.xyz.flume.interceptor.MyInterceptor$Builder agent.sources.messages-source.interceptors.zinfo.headers.store = ecommerce agent.sources.messages-source.interceptors.zinfo.headers.source = /var/log/messages agent.sources.messages-source.interceptors.zinfo.headers.sourcetype = syslog_messages public class MyInterceptor implements Interceptor { Map<String,String> staticHeaders; private MyInterceptor(Map<String,String> staticHeaders) { this.staticHeaders = staticHeaders; } public Event intercept(Event event) { Map<String,String> headers = event.getHeaders(); headers.putAll(staticHeaders); return event; }
- 41. 41 Monitoring/Alerts & Time Series
- 42. 42 NRT Use Cases • Analytics/Aggregations • Total number of page-views of a URL in a given time-period • Reach : Number of unique people exposed to a URL • Generate analytic metrics like Sum,Distinct,Count,Top K etc. • Alert when the number of HTTP Error 500 in the last 60 sec > 2 • Get real-time state information about infrastructure and services. • Understand outages or how complex systems interact together. • Real time intrusion detection • Measure SLAs (availability, latency, etc.) • Tune applications and databases for maximum performance • Do capacity planning
- 43. 43 Monitoring /Alerting Use Cases • Counting: real-time counting analytics such as how many requests per day, how many sign-ups, how many purchases, etc. • Correlation: near-real-time analytics such as desktop vs. mobile users, which devices fail at the same time, etc. • Research: more in-depth analytics that run in batch mode on the historical data such as detecting sentiments, etc.
- 44. 44 NRT Alerts & Aggregations Implementation • Rule based alerts in Flume • Aggregations in Flume/HBase • Time-series data in HBase/OpenTSDB HBase • Counters : avoids need to lock a row, read the value, increment it, write it back, and eventually unlock the row hbase(main):001:0> create 'counters', 'daily', 'weekly', 'monthly' 0 row(s) in 1.1930 seconds hbase(main):002:0> incr 'counters', '20110101', 'daily:hits', 1 COUNTER VALUE = 1 hbase(main):003:0> incr 'counters', '20110101', 'daily:hits', 1 COUNTER VALUE = 2 hbase(main):04:0> get_counter 'counters', '20110101', 'daily:hits' COUNTER VALUE = 2 Increment increment1 = new Increment(Bytes.toBytes("20110101")); increment1.addColumn(Bytes.toBytes("daily"), Bytes.toBytes("clicks"), 1); increment1.addColumn(Bytes.toBytes("daily"), Bytes.toBytes("hits"), 1); increment1.addColumn(Bytes.toBytes("weekly"), Bytes.toBytes("clicks"), 10); increment1.addColumn(Bytes.toBytes("weekly"), Bytes.toBytes("hits"), 10); Result result1 = table.increment(increment1); • Allows alerting logic to be at one place in Flume Interceptors • You write your code in simple interfaces in Flume • Backed up by HBase • Easy to define rules over here
- 45. 45 (NRT + Batch) Analytics • Batch Workflow • Does incremental computes of the data and loads the result into say HBase • Is too slow for the needs in many cases. Also the views are out of date • Compensating for last few hours of data is done in Flume • Applications query both real-time view and batch view and merge the results Web Server Web Server NRT Batch
- 46. Alerts 46 Storage / Processing Intelligent Search Batch Index Interactive SQL Interactive Search Batch Analytics Stream NRT Analytics Parse Time Series /Metri cs K/V Store MetaStore Builder/Admin Alerts Alerts
- 47. 47 Time Series with OpenTSDB • OpenTSDB is a time series database. • It is also a data plotting system. • Runs on HBase • Each TSD can handle 2000+ new data points per sec per core Time series is a series of data-points of some particular metric over time.
- 48. Interacting with OpenTSDB 48 put proc.loadavg.1m 1288946927 0.36 host=foo put proc.loadavg.5m 1288946927 0.62 host=foo put proc.loadavg.1m 1288946942 0.43 host=foo put proc.loadavg.5m 1288946942 0.62 host=foo You can communicate with the TSD via a simple telnet-style protocol, and via HTTP In OpenTSDB, a data point is made of: • A metric name : (http.hits) • A UNIX timestamp • A value (64 bit integer or double-precision floating point value). • A set of tags (key-value pairs) that annotate this data point : (to store for all the places where a metric exists) : eg. hostname, customer
- 51. 51 OpenTSDB Graphs & Alerts check_tsd!-d 60 -m rate:apache.stats.hits -t status=500 -w 1 -c 2 (look back upto 60 seconds, warning threshold is 1, critical threshold is 2)
- 52. 52 Overall Architecture… Another View… Logs HDFSFlume ZooKeeper HBase Impala/HI VE SAN/FTP Oozie Mahout Logs Logs Giraph Solr HS2 OpenTSDB Alerts Search Admin Builder Storm
- 54. 54 CSI - Cloudera Support Interface • Components Used • HBase, Solr, Impala, MR • Features • Enables searching & analytics for data from different sources in a single UI • Data Collected • Customer Diagnostics • Hadoop Daemon Logs • Hadoop Daemon Configurations • Host hardware info • Host OS settings and configurations • Support Cases, Public Apache Jiras, Public Mailing Lists, and Salesforce Account Data
- 55. 55 CSI – Log Visualization within Customer Dashboard
- 56. 56 CSI – Ad-hoc Data Analytics
- 57. 57
- 58. Queries Supported 58 • What are the most commonly encountered errors? • How many IOExceptions have we recorded from datanodes in a certain month? • What is the distribution of workloads across Impala, Apache Hive, and HBase? • Which OS versions are most commonly used? • What are the mean and variance of hardware configurations? • How many types of hardware configuration are there at a single customer site? • Does anyone use a specific parameter that we want to deprecate?
- 59. 59 Summary The beauty of this system is it solves a number of core and difficult use cases. It is also open to integrating with various other systems and making the overall solution much better. • Scalability • Flexibility in building new features & products • Low Cost of Ownership • Ease of Managing Big Data
- 60. Jayant Shekhar, Sr. Solutions Architect, Cloudera @jshekhar Thank you! Additional Questions & Discussions : Cloudera Booth : 1:00-1:30pm