Use Your MySQL Knowledge to Become an Instant Cassandra Guru
2 likes2,371 views

This document discusses how to leverage MySQL knowledge when working with Cassandra. It explains that while CQL is similar to SQL, Cassandra does not support features like joins, foreign keys, and complex secondary indexes. It recommends focusing on schema design and modeling data around query patterns. The document provides examples of creating tables, handling relationships, and time series data. It also covers topics like transactions, replication, partitioning, and conflict resolution in Cassandra. The overall recommendation is to rethink data modeling for Cassandra and use this knowledge as a starting point rather than trying to port MySQL applications directly.









































![Summary 1
We liked…
● CQL + “Tables” made it easy to get started
● HA
● Scaling model
Look [out] for…
● Don’t bother trying to “port” your MySQL application
● Query patterns are critical, model around them
● Pay attention to version when reading docs/blogs
○ Cassandra is quickly evolving (0.7, 1.0, 1.2, 2.0, …)](https://image.slidesharecdn.com/plmce2014-useyourmysqlknowledgetobecomeaninstantcassandraguru-140404155531-phpapp01/85/Use-Your-MySQL-Knowledge-to-Become-an-Instant-Cassandra-Guru-44-320.jpg)


Use Your MySQL Knowledge to Become an Instant Cassandra Guru
- 1. Use Your MySQL Knowledge to Become an Instant Cassandra Guru Percona Live Santa Clara 2014 Robert Hodges CEO Continuent Tim Callaghan VP/Engineering Tokutek
- 2. Who are we? Robert Hodges ● CEO at Continuent ● Database nerd since 1982 starting with M204, RDBMS since 1990, NoSQL since 2012; designed Continuent Tungsten ● Continuent offers clustering and replication for MySQL and other fine DBMS types Tim Callaghan ● VP/Engineering at Tokutek ● Long time database consumer (Oracle) and producer (VoltDB, Tokutek) ● Tokutek offers Fractal Tree indexes in MySQL (TokuDB) and MongoDB (TokuMX)
- 3. Cassandra! Cassandra, used by NetFlix, eBay, Twitter, Reddit and many others, is one of today's most popular NoSQL- databases in use. According to the website, the largest known Cassandra setup involves over 300 TB of data on over 400 machines. High Performance Reads and Writes Linear Scalability High Availability
- 4. One Good Thing about Cassandra ● Cassandra makes it easy to scale capacity Existing cluster nodes running out of space Start new nodes and let them join Stored data redistribute automatically
- 5. One Bad Thing about Cassandra cql> create table foo ( id int primary key, customerId int, orderId int, orderValue double); OK! <Me: I think I’m gonna like Cassandra.> cql> create index idx_foo_1 on foo (customerId, orderId); ERROR! - Secondary indexes only support 1 column <Me: I think I just changed my mind. CQL != SQL> <Me: (much later) secondary indexes aren’t that useful>
- 6. Today’s Question How can you use your MySQL knowledge to get up to speed on Cassandra?
- 7. CQL CQL is not SQL!
- 8. What is CQL? ● Cassandra originally used a Thrift RPC-based API ● CQL was added in 0.8 ○ Simplifies access ○ Smaller learning curve for SQL users ● So, you’ll feel right at home ○ Create table ○ Data types ○ Insert, update, select, delete ● But Cassandra isn’t pretending to be relational...
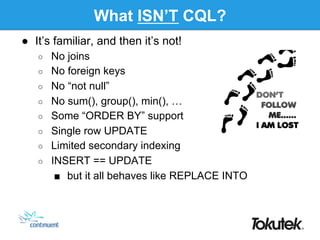
- 9. What ISN’T CQL? ● It’s familiar, and then it’s not! ○ No joins ○ No foreign keys ○ No “not null” ○ No sum(), group(), min(), … ○ Some “ORDER BY” support ○ Single row UPDATE ○ Limited secondary indexing ○ INSERT == UPDATE ■ but it all behaves like REPLACE INTO
- 10. The Bottom Line on CQL ● It’s just a language ● It’s very similar to SQL ● Don’t blame CQL ○ What first appears as a “limitation” in Cassandra can also be a strength ○ CQL enables us to get started quickly ○ Try Cassandra 0.7 for a little while… Commit this to memory... “You do not just throw data into Cassandra and add later indexes to make it fast.”
- 11. Schema Design “Easy to learn and difficult to master” - Nolan Bushnell (founder of Atari and Chuck E. Cheese’s Pizza-Time)
- 12. Coming from a Relational World? Tradeoffs are hard Feature RDBMS Cassandra Single Point of Failure Cross Datacenter Linear Scaling Data Modeling *source = Patrick McFadin (@PatrickMcMcFadin)
- 13. How is My Data “Organized”? Relational Model Cassandra Model Database Keyspace Table Column Family Primary Key Row Key Column Name Column Name/Key Column Value Column Value
- 14. What is a BigTable? http://static.googleusercontent.com/media/research.google.com/en/us/archive/bigtable-osdi06.pdf Row Key Column Name Column Value Timestamp TTL Column Name Column Value Timestamp TTL Column Name Column Value Timestamp TTL Column Name Column Value Timestamp TTL Up to 2 billion! ● Cassandra uses it for the data model ● Supports extremely wide rows ● Row lookup is fast and easily distributed ● Columns are sorted by name
- 15. What About Data Types? ● Unlike some other NoSQL databases, types are included via CQL ● Usual suspects ○ ascii, bigint, blob, boolean, decimal, varchar, … ● More interesting ○ uuid - global uniqueness ○ timeuuid - global uniqueness, sorted by time portion ○ inet - IPv4 or IPv6 address ○ varint - variable precision integer
- 16. How Do I Create a Static Table? CREATE TABLE users ( user varchar, email varchar, state varchar, PRIMARY KEY (user) ); ● Primary key is hashed for location/placement (more on that later) ○ Meaning you cannot range scan by PK ● No “not null” or varchar sizing (enforce in applications) ● Reads (on username) and all writes are easily distributed ● Schema flexibility without downtime ○ alter table users add column password varchar; user email timestamp ttl state timestamp ttl These rows look and feel familiar.
- 17. No Auto-Increment? ● Auto-increment is extremely difficult in a distributed system ● Use a natural primary key, if possible ○ Remember, small primary keys aren’t important when denormalizing ● Or, use uuid / timeuuid ○ Generated in your client applications CREATE TABLE payments ( id timeuuid, user varchar, type varchar, amount decimal, PRIMARY KEY (id) );
- 18. What About Secondary Indexes? CREATE TABLE users ( user varchar, email varchar, state varchar, PRIMARY KEY (user)); -- OPTION 1 : create an index CREATE INDEX idxUBS on users (state); -- OPTION 2 : create another table (store data twice) CREATE TABLE usersByState ( state varchar, user varchar, PRIMARY KEY (state, user));
- 19. Why Not Create Secondary Indexes? select * from users where state = ‘CA’; Secondary index ● Pro : Index is automatically maintained ● Con : Above query sent to entire cluster (slows everyone down) Additional table ● Pro : Above query is directed to single node (important for scalability) ● Con : Index is manually maintained (insert data twice, which is OK) General tips ● Low selectivity is bad - (male/female) ● Extremely high selectivity is bad - (unique) ● In general, create additional table and don’t busy entire cluster for reads
- 20. How Do I Create a Dynamic Table? CREATE TABLE payments ( user varchar, id timeuuid, type varchar, amount decimal, PRIMARY KEY (user, id) ); - Compound PK creates wide row - Remainder of columns are “grouped” - Still 1 “row” per user user type timestamp ttl amount timestamp ttl id1 type timestamp ttl amount timestamp ttl id2 ● Affects how data is stored/organized ● Still returned in “row” format to CSQL ● Enables “ORDER BY id” and range query on “id” for “user = ?” queries ● Remember, BigTables support up to 2 billion columns
- 21. What About Relationships? Relational table emp (empName text PK, deptId int, ...); index empIdx1 on emp (deptId); table dept (deptId int PK, deptName text); Cassandra table emp (empName text PK, deptId int, deptName text); table dept ( deptId int, deptName text, empName text, PRIMARY KEY ((deptId, deptName), empName)); Store department name with employee Store employee names with department (up to ~2 billion) 1, Accounting FrankJones FredJones SamSmith
- 22. What About Time Series Data? CREATE TABLE dashboard ( dashboardId text, event_time timestamp, event_value double, PRIMARY KEY (dashboardId, event_time)) WITH CLUSTERING ORDER BY (event_time DESC); ● great for “last n”, like dashboards ● “WITH CLUSTERING ORDER BY ()” ○ Data is stored in given order in BigTable row ○ In this case descending by event_time ○ Easy to access most recent data
- 23. How Do I Remove Time Series Data? CREATE TABLE dashboard ( dashboardId text, event_time timestamp, event_value double, PRIMARY KEY (dashboardId, event_time)) WITH CLUSTERING ORDER BY (event_time DESC); insert into dashboard (dashboardId, event_time, event_value) values (25, now(), 500.12) using ttl 86400; ● defined at the “data” level ● data “magically” disappears ● no more cron jobs
- 24. Are There Other Cool Schemas? ● collections : sets, lists, maps ○ an alternative to making the row “wide” ○ set<text> : ordered by CQL Type comparator ○ list<text> : ordered by insertion ○ map<int,text> : unordered ○ support for 64,000 objects per collection (but don’t go crazy) create table users ( user varchar, emails set<text>, PRIMARY KEY (user)); insert into users (user, emails) values (‘tmcallaghan’, {‘[email protected]’,’[email protected]’});
- 26. MySQL Transactions and Isolation mysql> BEGIN; ... mysql> INSERT INTO sample(data) VALUES (“Hello world!”); mysql> INSERT INTO sample(data) VALUES (“Goodbye world!”); ... mysql> COMMIT; InnoDB creates MVCC view of data; locks updated rows, commits atomically MyISAM locks table and commits each row immediately
- 27. Does Cassandra Have Transactions? “Transactions” includes a lot of things so… No: ● Updates on different rows are separate, like MyISAM ● Failed transactions on replicas might create partial writes (Cassandra does not guarantee clean-up) Yes: ● Updates to single rows are atomic and isolated ● Updates to rows are durable (logged) as well (Important: Cassandra rows can be “bigger” than MySQL)
- 28. How Does Cassandra Handle Locks? Cassandra uses timestamps instead create columnfamily sample(id int primary key, data varchar, n int); insert into sample(id, data, n) values(1, 'hello', 25); insert into sample(id, data, n) values(2, 'goodbye', 27); cqlsh:cbench> update sample set data='goodbye!' where id=2; cqlsh:cbench> select id, writetime(data),writetime(n) from sample; id | writetime(data) | writetime(n) ----+------------------+------------------ 1 | 1396326015674000 | 1396326015674000 ⇐ Updated together 2 | 1396326144783000 | 1396326027160000 ⇐ Updated separately Timestamps are the same for columns updated at the same time
- 29. How Does Cassandra Handle Isolation? ● Row updates are completely isolated until they are completed ● Updates can propagate out to replicas at different times
- 31. Review of MySQL Replication
- 32. How Does Cassandra Replication Work? ● Cassandra is fully multi-master ● Updates are allowed at any location ● Updates can happen even when there is a partition db1 db3 db2 db4 Client program issues write Writes proxied to other instances Coordinator
- 33. How Many Replicas Are There? The number of replicas and how they are distributed are properties of keyspaces CREATE KEYSPACE cbench WITH replication = { 'class': 'SimpleStrategy', 'replication_factor': '3' }; Keep 3 copies of data Strategy class to distribute replicas
- 34. MySQL Partitioning • MySQL partitioning breaks a table into <n> tables o “PARTITION” is actually a storage engine • Tables can be partitioned by hash or range o Hash = random distribution o Range = user controlled distribution (date range) • Helpful in “big data” use-cases • Partitions can usually be dropped efficiently o Unlike “delete from table1 where timeField < ’12/31/2012’;”
- 35. How Does Cassandra Partition Data? Cassandra splits data by key across hosts using a “ring” to assign locations A B F E D C G H db3 EFGHAB db4 GHABCD db2 CDEFGH db1 ABCDEF Virtual node D gets ⅛ of hash range Copy assigned to host db4 by strategy
- 36. Partitioning in Action Replica placement is based on primary key insert into sample(id, data) values (550e8400-e29b-41d4-a716-446655440000, 'hello!'); Primary Key Run hash function on value, assign to virtual node, from there to actual hosts
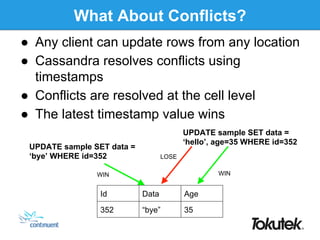
- 37. What About Conflicts? ● Any client can update rows from any location ● Cassandra resolves conflicts using timestamps ● Conflicts are resolved at the cell level ● The latest timestamp value wins Id Data Age 352 “bye” 35 UPDATE sample SET data = ‘hello’, age=35 WHERE id=352 UPDATE sample SET data = ‘bye’ WHERE id=352 WINWIN LOSE
- 38. So Is This Like Galera? ● Galera uses ACID transactions with optimistic locking ● It would accept the first transaction and roll back the second completely Id Data Age 352 “bye” 35 UPDATE sample SET data = ‘hello’, age=35 WHERE id=352 UPDATE sample SET data = ‘bye’ WHERE id=352 WIN WIN LOSE
- 39. How Does “Failover” Work? ● Cassandra does not have failover ● If a node fails or disappears, others continue ● Writes or reads may stop if too many replicas fail db1 db2 db4 Client program issues write Writes proxied to other instances X Coordinator
- 40. Tunable Consistency Clients define the level of consistency cqlsh:cbench> consistency all Consistency level set to ALL. cqlsh:cbench> update rtest set k1=4444 where id=3; Unable to complete request: one or more nodes were unavailable. cqlsh:cbench> select * from cbench.rtest where id=3; Unable to complete request: one or more nodes were unavailable. cqlsh:cbench> consistency quorum Consistency level set to QUORUM. cqlsh:cbench> update rtest set k1=4444 where id=3;
- 41. What Happens To Failed Writes? ● Cassandra has several repair mechanisms for failures ● Hinted Handoff - The coordinator remembers the write and replays it when node returns ● Read Repair - Coordinator for a later read notices that a value is out of sync ● Node Repair - Run an external process (nodetool) to scan for and fix inconsistencies
- 42. What Else is There to Learn? “A lot” would be an understatement, but here are some topics to consider. ● You need to “rethink” your data model, so read up, practice, repeat ● Data consistency is an application problem ● Storage/Internals : LSM, Compaction, Tombstones, Bloom Filters
- 43. What Should You Do?
- 44. Summary 1 We liked… ● CQL + “Tables” made it easy to get started ● HA ● Scaling model Look [out] for… ● Don’t bother trying to “port” your MySQL application ● Query patterns are critical, model around them ● Pay attention to version when reading docs/blogs ○ Cassandra is quickly evolving (0.7, 1.0, 1.2, 2.0, …)
- 45. Summary 2 Highly recommended reading ● Book: “Practical Cassandra: A Developer’s Approach” ● Datastax has great docs, http://www.datastax.com/docs ● Presentations ○ http://www.slideshare.net/jaykumarpatel/cassandra- data-modeling-best-practices ● Blogs ○ http://planetcassandra.org ○ http://ebaytechblog.com
- 46. Questions? Robert Hodges CEO, Continuent [email protected] @continuent Tim Callaghan VP/Engineering, Tokutek [email protected] @tmcallaghan